【PareCO】2020-ICMLw-PareCO: Pareto-aware Channel Optimization for Slimmable Neural Networks-论文阅读
PareCO
2020-ICMLw-PareCO: Pareto-aware Channel Optimization for Slimmable Neural Networks
This paper has been accepted at various non-archival workshops including
来源: Chenbong 博客园
- Institute:CMU, FAIR, UT Austin
- Author:Ting-Wu Chin, Ari S. Morcos, Diana Marculescu (H49)
- GitHub:https://github.com/cmu-enyac/PareCO
- Citation: 3
Introduction
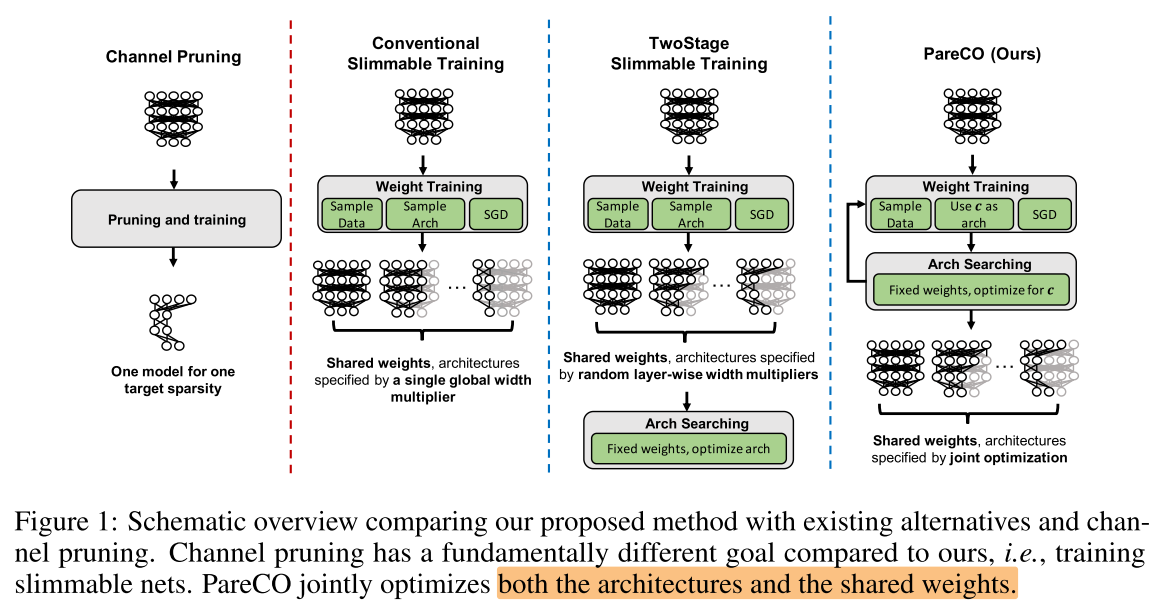
Motivation
Contribution
Method
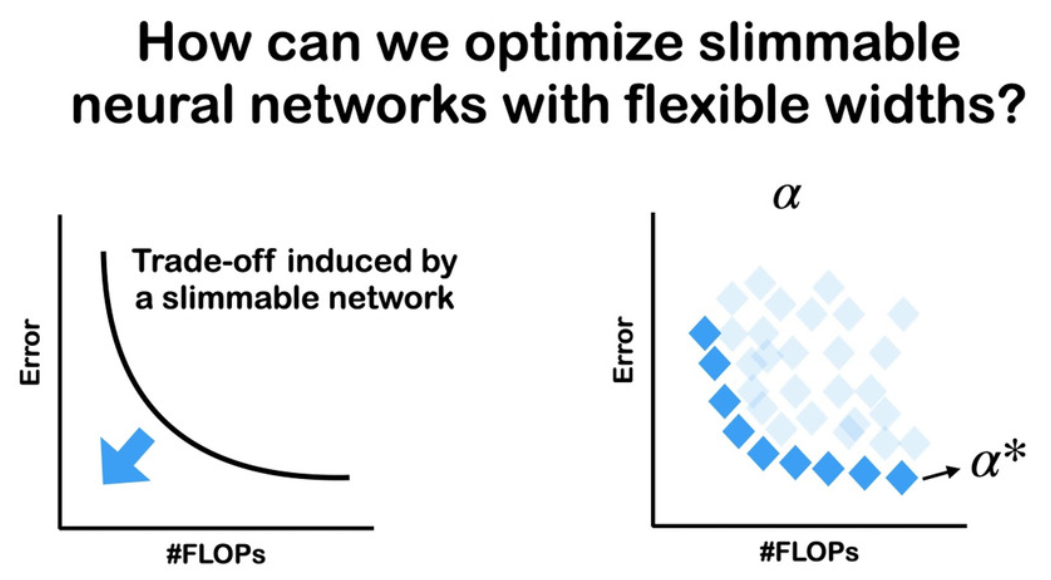
只训练Pareto前沿的子网, 如何采样 pareto前沿的子网?
AttentiveNAS 和 GreedyNAS 都是对每个目标flops随机采样k个, 然后将这个k个中性能最好的子网认为属于Pareto前沿集合
这里评估性能可以用子网在验证集(的子集, greedynas)上的acc或直接用 batch loss (attentiveNAS) 代替, 或者使用acc predictor
这篇PareCO用的是数学的方式, 根据历史数据(预测)采样Pareto上的子网: Alg 1. 第8行
- 高斯过程GP
- 贝叶斯优化 Bayesian Optimization(BO)
- acquisition function (Paria et al., 2019)
- Upper Confidence Bound (UCB) (Srinivas et al., 2009)
- Lemma 3.1 多目标优化 (Nakayama et al., 2009)

- |H| = 1000 (pareto前沿的模型池)
- M=2
第8行替换为随机采样一个uniform宽度的子网, 将n=1(第13行), 则算法1退化为US Net的方法
基于历史的pareto采样数据, 使用BO+二分查找, 随机均匀分布的目标 flops:
该算法的作用其实就是给定一个目标flops, 找到一个该flops下的pareto前沿的子网
(其他的文章实现的方式还有: 随机采样 + with reject, 根据先验分布采样+with reject(提高效率)

most 10 binary searches with \(\epsilon\) set to 0.02, average 3.4 binary searches
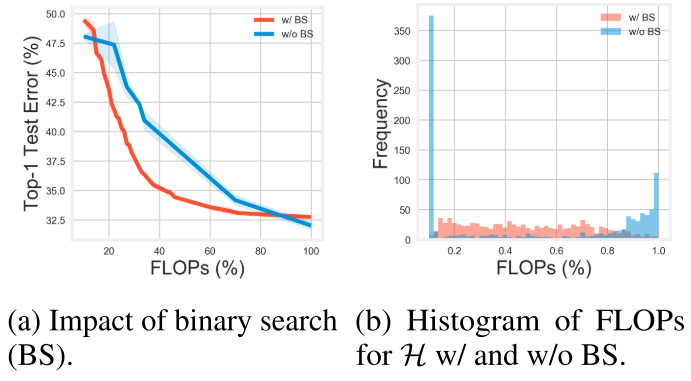
2个目标, 如果不是均匀采样的话, 很容易选中要么flops很小, 要么loss很低(flops很大)的子网
Experiments
C10 / C100 / ImageNet
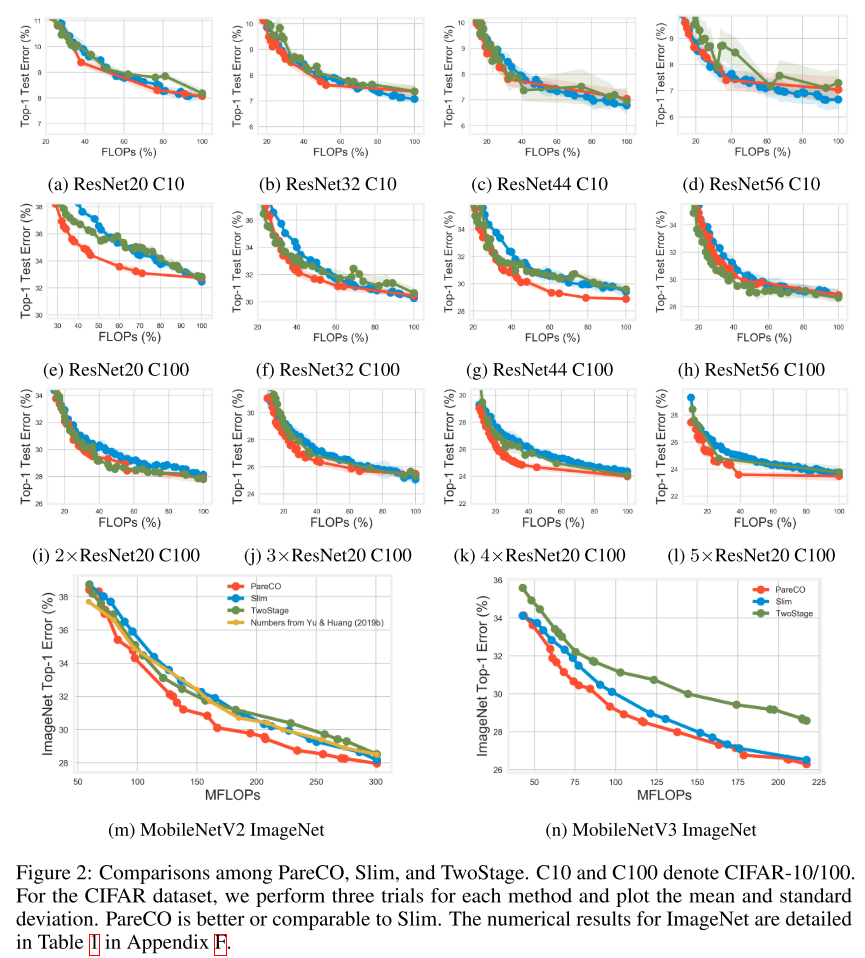
与USNet对比
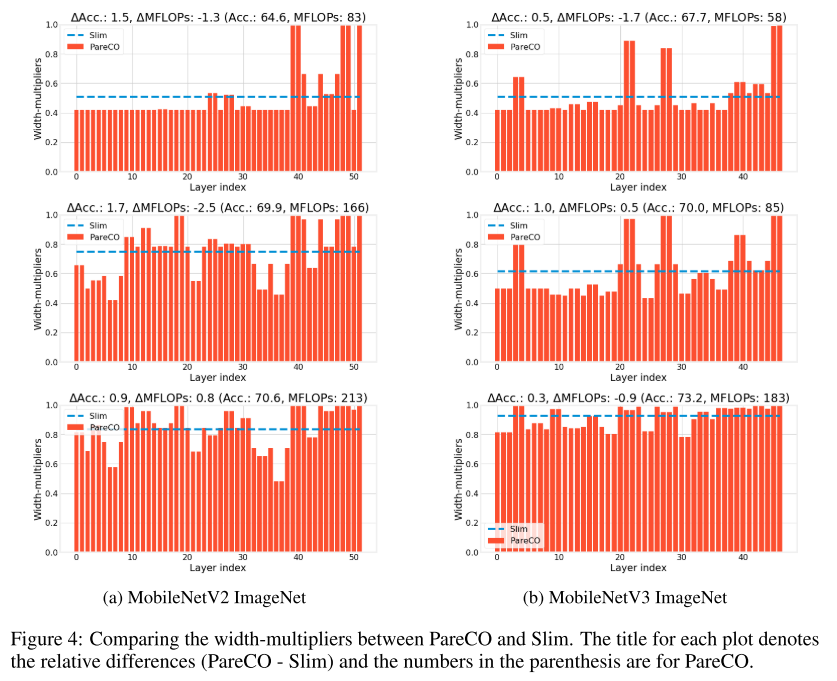
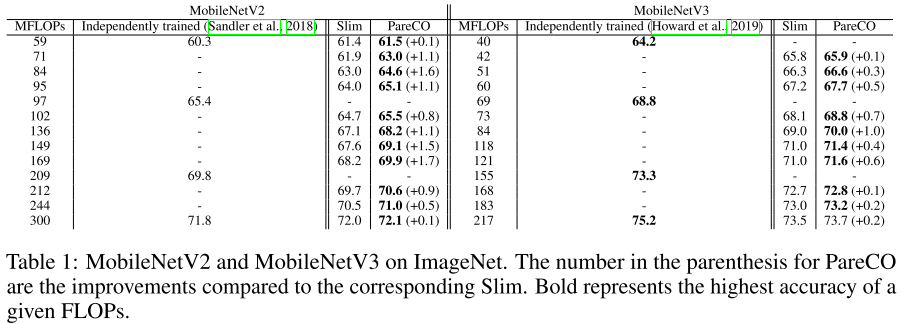
OFARP:
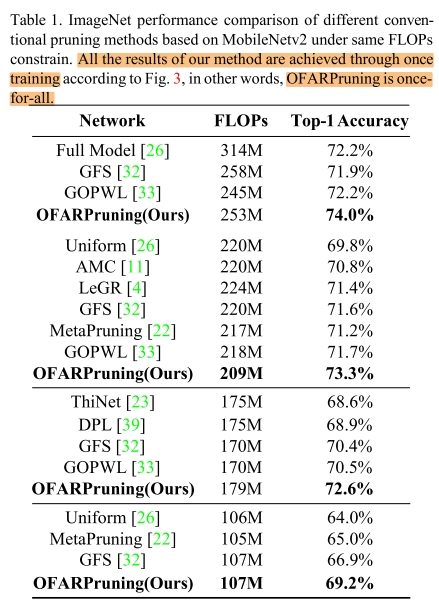
只对搜索宽度的提升有限(比不过剪枝), 加上分辨率可以在特定flops下有更大的提升(可以超越剪枝方法)
Conclusion
Summary
- slimmable network 如果只对宽度搜索, 无法超过剪枝, 要超越剪枝只能增加维度(如分辨率)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号