【CompOFA】2021-ICLR-CompOFA Compound Once-For-All Networks For Faster Multi-Platform Deployment-论文阅读
CompOFA
2021-ICLR-CompOFA Compound Once-For-All Networks For Faster Multi-Platform Deployment
来源: ChenBong 博客园
- Institute:Georgia Institute of Technology
- Author:Manas Sahni,Alexey Tumanov
- GitHub:https://github.com/gatech-sysml/CompOFA
- Citation: /
Introduction
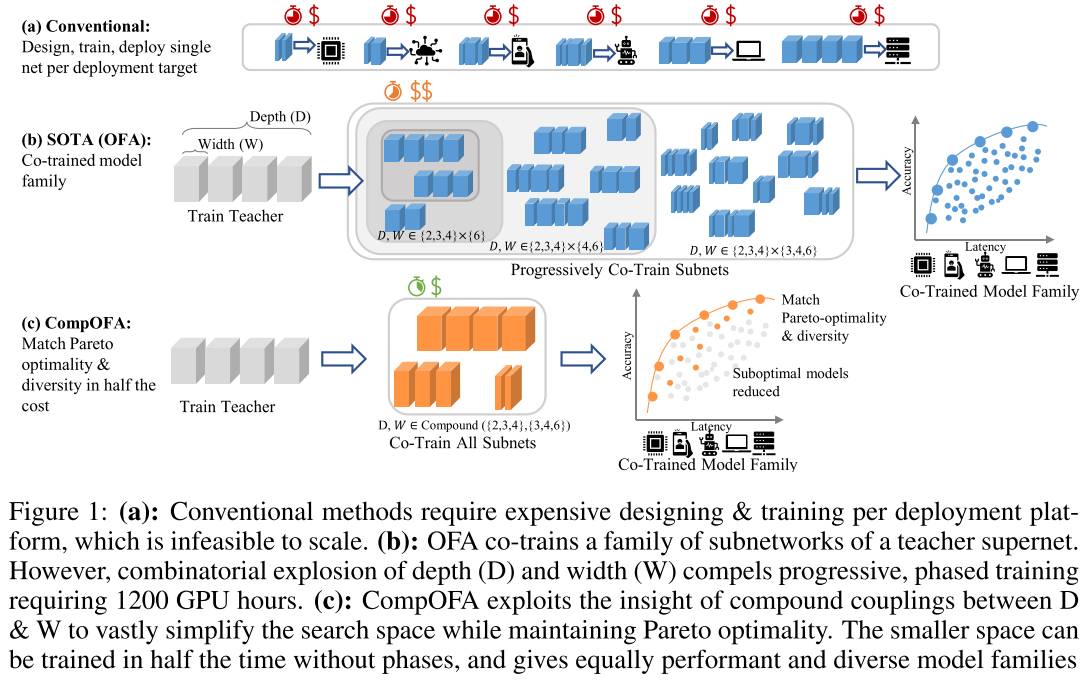
通过对OFA的子网采样空间施加简单的启发式约束来减少子网搜索空间,从而减少超网空间中次优子网的个数,减少子网过多带来的相互干扰,提高每个子网被训练的程度,提高子网群体的性能,在保持 acc-latency tradeoff 的 pareto前沿不下降的同时,减少了超网的训练时间。
Motivation
- 对于不同的目标组合(不同硬件平台)的子网搜索问题,传统NAS(单目标组合)对每个目标组合都需要进行一次完整的搜索过程
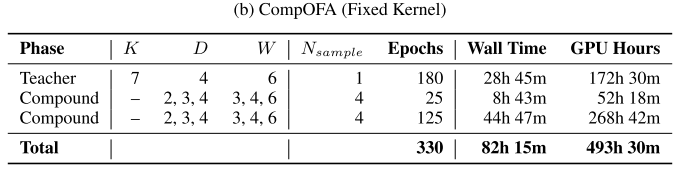
- 已有的一些超网训练方法(e.g. OFA)将训练和搜索过程解耦,不管有几个目标平台,都只需要训练一次,但训练开销依然巨大(40-50 GPU day,1200 GPU hour)
- 训练阶段:
- 通过一些观察,我们发现子网空间中存在很多次优子网,因此我们认为如此大的子网搜索空间(自由度高的空间)是不必要的,反而会增加超网训练过程中的相互干扰
- 一些研究表明perato最优上的网络的不同维度(depth,width,resolution)不是正交的,而是遵循一些约束关系,例如同时增加宽度和深度的效果更好(e.g. D3W3>D4W2,D2W4);即要增加同样的flops,将增加的flops增加在多个维度上(pareo最优)比都增加在同一个维度上要好(Model Scaling)
- 因此可以通过简单的规则将这些次优子网从搜索空间中删去,从而减少子网搜索空间的大小(自由度低的空间),降低超网训练阶段的开销(2x)
- 搜索阶段:OFA由于子网搜索空间过大,在评估子网的latency时,无法直接评估,需要花一定时间预先训练 latency predictor
Contribution
- 使用简单的启发式规则将OFA子网个数从 \(10^{19}\) 个减少到243个,但依然保持了和OFA相同的acc-latency tradeoff
- 减少了超网训练开销 2x
- 减少了搜索开销 216x
- 虽然子网空间减少了十几个数量级,但latency的粒度依然覆盖和OFA同样的范围
- 泛化性好,证明了本文的 insights
Method
子网空间
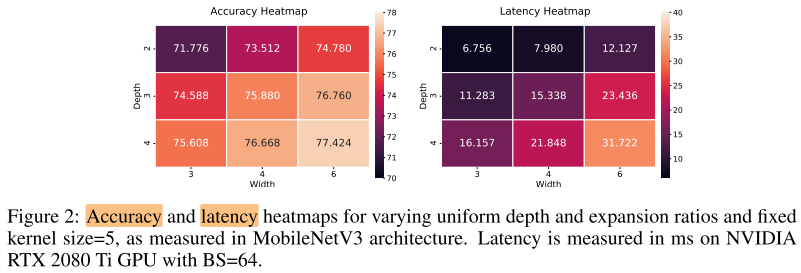
OFA:
- 5个block,\(B_1, B_2, B_3, B_4, B_5\)
- 每个block: \(B_i(d_i, W_i, K_i)\) ,分别表示该block的 depth,width list,kernel_size list
- \(d_i, w_{ij}, k_{ij}\) 分别采样自集合 \(D=[2,3,4], W=[3,4,6], K=[3,5,7]\) ,每一维都是独立采样
- 子网空间大小为 \(O(10^{19})\)
- 25种分辨率,多种分辨率不增加超网训练开销
CompOFA:
- 启发式规则:
- 深度和宽度需要同时增加或减少
- 同一个block的不同层使用相同的w和k
- 整个网络的kernel_size都相同,固定为3/5
- 5个block,\(B_1, B_2, B_3, B_4, B_5\)
- 每个block: \(B_i(d_i, w_i, k_i)\) ,分别表示该block的 depth,width,kernel_size
- \((d_i, w_i)\) 采样自集合 \(DW=[(2,3),(3,4),(4,6)]\) ,dw不是独立采样
- 子网空间大小为 \(3^5=243\) 个
- 25种分辨率,多种分辨率不增加超网训练开销
训练阶段设置
OFA由于子网空间过大,无法直接在同一个阶段训练所有子网,因此采用 progressive shrinking 的训练策略,逐渐减小子网空间的粒度:
- 先单独训练超网
- 再用超网作为teacher,在不同阶段训练粒度越来越小的子网
CompOFA的子网空间很小,可以在同一个阶段训练所有的子网:
- 先单独训练超网
- 再用超网作为teacher,训练所有子网
Experiments
Acc-Latency tradeoff
每个目标下 best model 的比较:
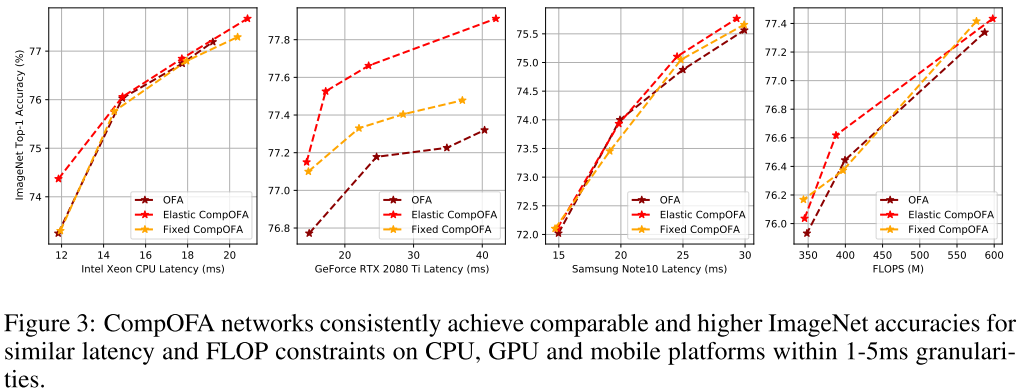
Design Space Comparison
每个目标下的随机采样的模型群体性能的比较:

整个空间随机采样的模型性能比较:
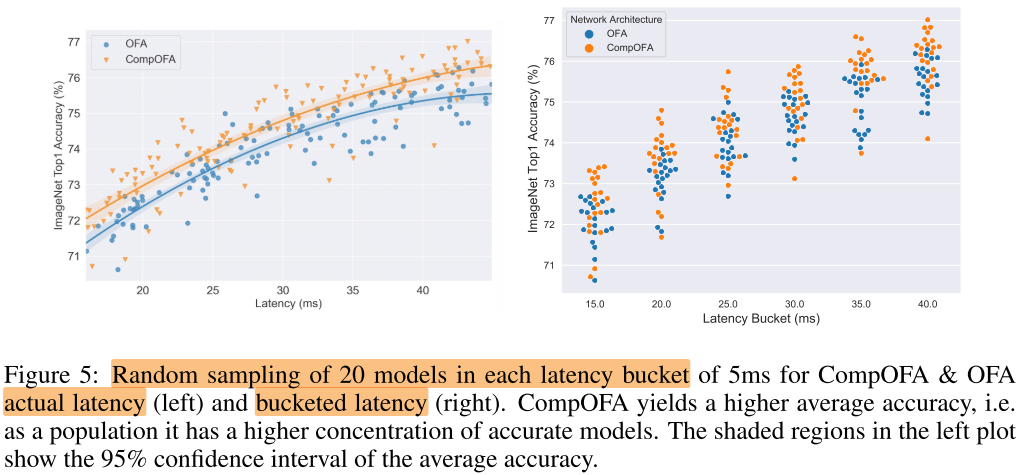
相同子网结构在2个空间中的性能比较
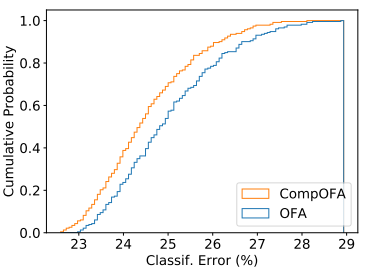
相同的子网结构,在CompOFA的超网中的性能更好(被训练得更充分/子网少干扰小)
5.2-5.3借鉴了RegNet文章中比较不同模型空间的思想(CDF曲线)
- 相同点:
- RegNet 和 CompOFA 都是添加约束对模型空间/子网空间做稀疏化(保持了空间的表达能力的同时,减小了空间可行域的大小),稀疏后的空间是原始空间的子集
- 不同点:
- RegNet 中的子网是各自独立训练的,CompOFA 中的子网是以权重共享方式训练的
- RegNet 是稀疏后的模型空间中的子网群体质量高
- CompOFA 是用稀疏后的子网空间采样训练出来的超网,得到的超网中的子网群体质量高
- e.g. 同一个结构,如果在RegNet中的不同级别的空间中的性能是相同的;同一个结构在OFA空间和CompOFA空间中的性能是不同的
PS的必要性
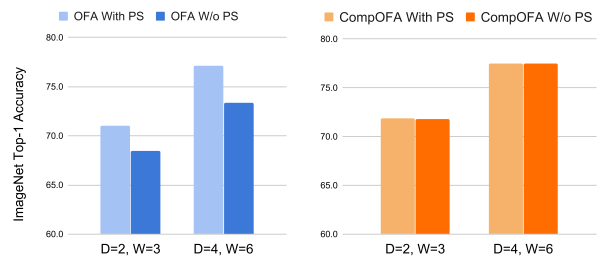
PS对OFA的影响很大(3.7 drop),对CompOFA影响不大,可能由于子网个数少
Conclusion
Summary
pros:
- 不是专门做nas sota的文章,核心在于探究超网训练方法中子网采样空间的设计,因此不用与nas sota方法作比较,写作角度找的很好
与剪枝的关系:
nas先是一股脑地一直扩大搜索空间,虽然效果好了,但是计算开销也大了;然后就有人开始研究如何在保持搜索性能的同时对搜索空间进行稀疏化,减小搜索空间;
模型剪枝也是因为因为不断地堆层数,宽度,导致模型计算开销大,再进行稀疏化
两者有点类似,不过剪枝是在权重层面,本文这一类nas工作是在搜索空间层面。
发展顺序:表示空间小+密集 => 表示空间大+密集 => 表示空间大+稀疏
稀疏:在保持空间表达能力高的情况下,减少可行域(参数量少/子网个数少)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号