【NAT】2021-TPAMI-Neural Architecture Transfer-论文阅读
NAT
2021-TPAMI-Neural Architecture Transfer
来源: Chenbong 博客园
- Institute:Southern University of Science and Technology,Michigan State University
- Author:Zhichao Lu,Kalyanmoy Deb(H123),Wolfgang Banzhaf(H59)
- GitHub:https://github.com/human-analysis/neural-architecture-transfer 90+
- Citation: 10+
Introduction
结构和权重的在线迁移学习和多目标进化搜索
在pre-trained超网的基础上,边搜索满足约束的trade-off子网,边fine-tune这些子网,结束后然后就可以直接获得一系列位于pareto前沿上的子网。
Motivation
对结构和权重的 transfer learning:
- 之前的方法对每个目标约束组合(Latency、FLOPs,Params...)都需要一个完整的搜索过程
- (权重的)迁移学习,即在ImageNet上的预训练模型迁移到下游任务上(fine-tune),比在下游任务(少量数据)上直接train from scratch效果要好
- 然而迁移学习只能fine-tune权重,无法fine-tune网络结构,使得NAS在不同任务上需要大量的数据和搜索时间(NAS没法和经典网络一样做权重的迁移学习,而是在每个任务上都要做一遍结构搜索,但下游任务很可能是数据量不足的,权重都无法充分训练,更不要说做结构搜索)
- 因此,本文的方法基于同一个在ImageNet上预训练好的超网模型,针对不同的任务(数据集)只需要做一个类似transfer的fine-tune过程(150个epoch),就可以在目标数据集上搜索到一个满足目标约束组合(Latency,FLOPs,Params...)的子网架构及对应的权重
Contribution
Method
将超网结构和权重的迁移,以类似超网训练的方式来进行
Pipeline

输入:
- L2:预训练好的supernet(通过随机采样训练)及其Archive,Archive中包含有一些优质子网结构(类似一个优质模型池,一开始是随机采样的):\(\{a_1, a_2, ...a_N\}\)
two stage (transfer 的过程):
- search stage:
- L 4 5 6 7:从Archive中抽取多组 subnet \(a_i\) 并计算对应的推理精度 \(f_i\) pair:\((a_i,\ f_i)\) 对精度预测器(predictor model)进行训练(predictor model 的在线学习)
- L 8 9 10 11:使用进化算法(NSGA III 2014)搜索满足目标约束 \(\tilde f\) 的,且性能好(使用predictor model进行快速评估,同时predictor model也利用 adaptation 阶段的推理结果 进行 online learning)的 promising subnets会被加入Archive
- L 12 13:adaptation stage:在Archive中 top-ranked 的 子网会被fine-tune:按照Archive构建 dimension-wise 的经验分布,并按照这个分布采样子网进行训练
交替执行2个阶段,直到预先设定的计算资源(1 days / 8×2080Ti)耗尽
输出:
- 特定任务的超网及对应的Archive(在任务上满足不同目标约束的子网可以从Archive中选取并直接部署)
(11个数据集上的,11个acc↑,MAdds↓,12目标的约束,通用结构)
acc predictor
Motivation:
-
NAS是一个双层优化问题:1.优化子网结构,2.优化子网的权重;
-
第2步中的优化子结构的权重需要对子结构进行完整的训练,非常耗时;因此出现了先训练超网,再直接继承超网权重来直接评估子网的性能,节约了第2步的时间
-
使用acc predictor与直接训练推理来评估子网性能的对比:
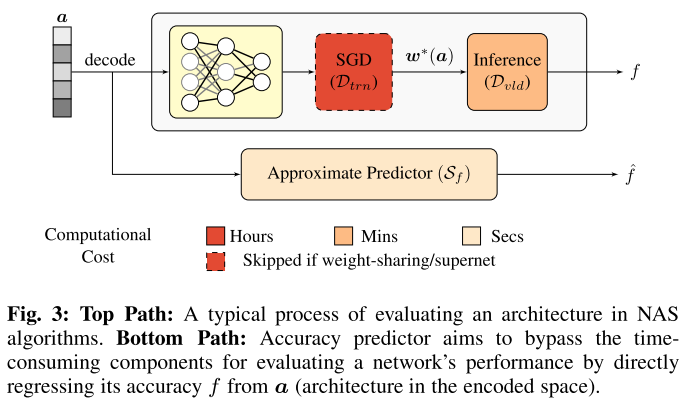
-
-
但即使直接而继承超网权重来评估每个子网性能还是要在验证集上推理(几分钟),对于第1步要评估的几千个不同的子网来说还是太耗时;因此出现了使用 predictor model 来快速预测结构性能的方法
-
-
predictor model 的训练方式:
- 之前的 predictor model 是外插值而不是内插值,导致predictor的预测相关性低(均匀采样)
- 之前的 predictor model 是离线训练(提前训练),而不是在线训练(同步训练)
acc predictor 的 3个要求:
- 相关性高(PNAS 1160个子网 相关性0.476)
- 数据集无关
Consistent prediction: the quality of the prediction should be consistent across different datasets.&&不同结构在不同数据集上的排序应该是一致的? - 训练效率高,即所需的训练样本少(OFA 16000个子网样本来构建predictor,本文的predictor只需要100个训练样本+在线学习)
解决方法:
- 限制在满足目标约束的 trade-off 的子网样本上
- 4种低复杂度的predictor:
- 高斯过程 Gaussian Process (GP)
- 径向基函数Radial Basis Function (RBF)
- 多层感知机 Multilayer Perceptron (MLP)
- 决策树 Decision Tree (DT)
- (Ablation Study)发现训练样本数量超过100以后,RBF的性能优于其他3种方法,RBF ensemble 比单个 RBF model更好:

最终的acc predictor使用K=500个RBF进行ensemble,使用100个样本(arch, acc),整个过程可以在1分钟内完成训练。&&这里的100个样本是从哪里获得的? 在线学习, 应该是从当前超网中采样样本?

search stage(EA & Many-Objective Selection)
进化算法 + NSGA-III 的多目标选择(在子代中选择一部分作为新的种群)


Supernet Adaptation
Motivation:
- 同时训练搜索空间中的所有子网是不可行的,也是不必要的,因为不是所有子网对当前任务都同样重要
- 只专注于训练搜索算法中获得的有潜力的子网,用Archive(类似模型池)来存放到目前为止有潜力的子网结构
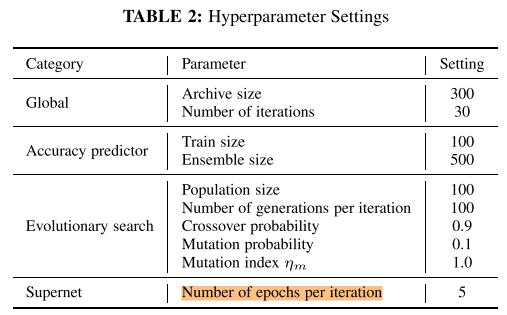
一共30个iteration:
- 每个iteration中的Adaptation有5个epoch:
- 根据Archive中的子网构建每一维的分布Distr(每个iteration更新一次Distr)
- 每个batch采样一个子网,更新子网: \(p\left(X_{i}=j\right)=\frac{\# \text { of architectures with option } j \text { at } i^{t h} \text { integer }}{\text { total } \# \text { of architectures in the archive }}\)

Experiments
Setup
Supernet Preparation
- 8×V100 / 6 days
- ImageNet
- 使用Once for All相同的方式,对超网进行收缩式完整训练
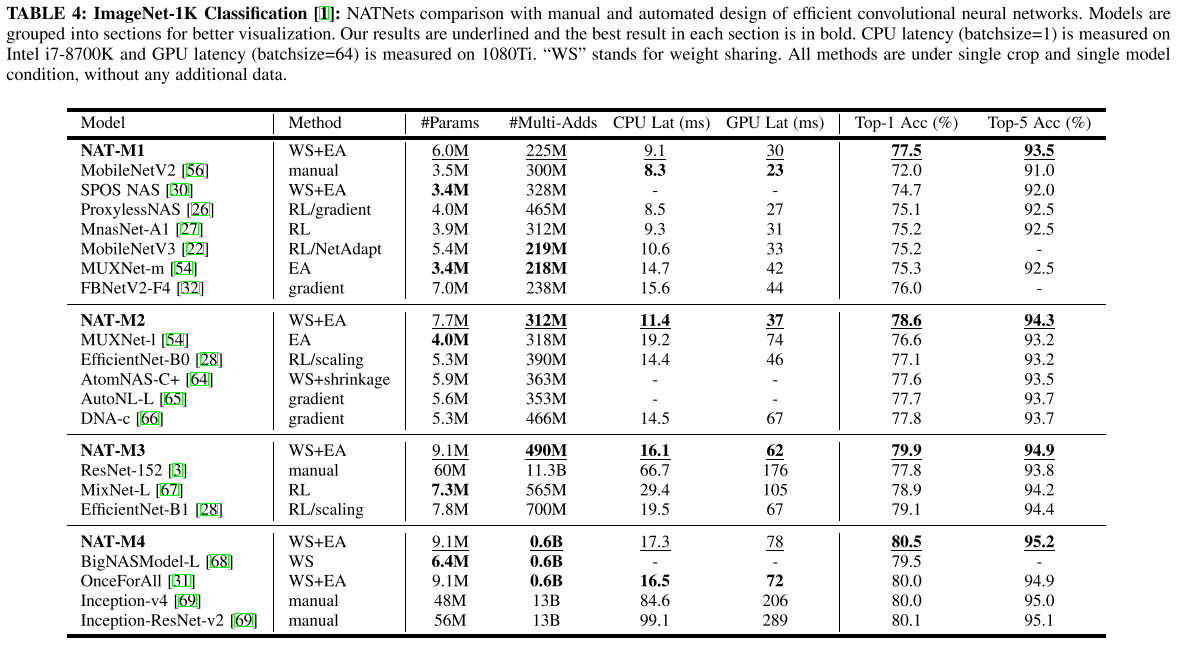
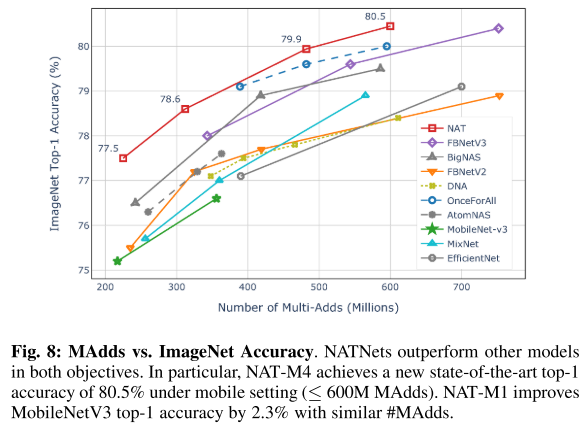
ImageNet
搜索目标:min #MAdds (200M-600M) & max #Acc
run NAT 30 iterations (5 epoch/iter, total 150 epochs)
fine-tune each model
Scalability to Datasets
现有的NAS方法很少应用在非标准数据集(标准数据集CIFAR10,ImageNet etc.)上,往往是在标准数据集上搜索,再通过(权重)迁移学习到下游数据集上,但从标准数据集上搜索的结构,在下游数据集上的精度/效率往往都是次优的;且与NAS的目标(在特定数据集上找到最合适的结构)是矛盾的。
而NAT可以为每个数据集定制子网结构。在10个图像分类数据集上执行NAT:
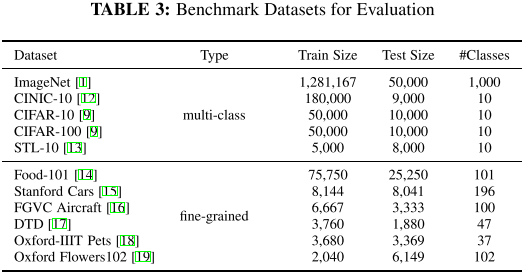
10个数据集,每个数据集
- 搜索目标: min #MAdds & max #Acc
- run NAT 30 iterations (5 epoch/iter, total 150 epochs)
- 注意这里不再需要fine-tune搜索到的结构,而是在NAT运行结束后,即可获得满足目标约束的子网
- 每个数据集所需的transfer时间略低于一天: <1day 8×2080Ti GPU
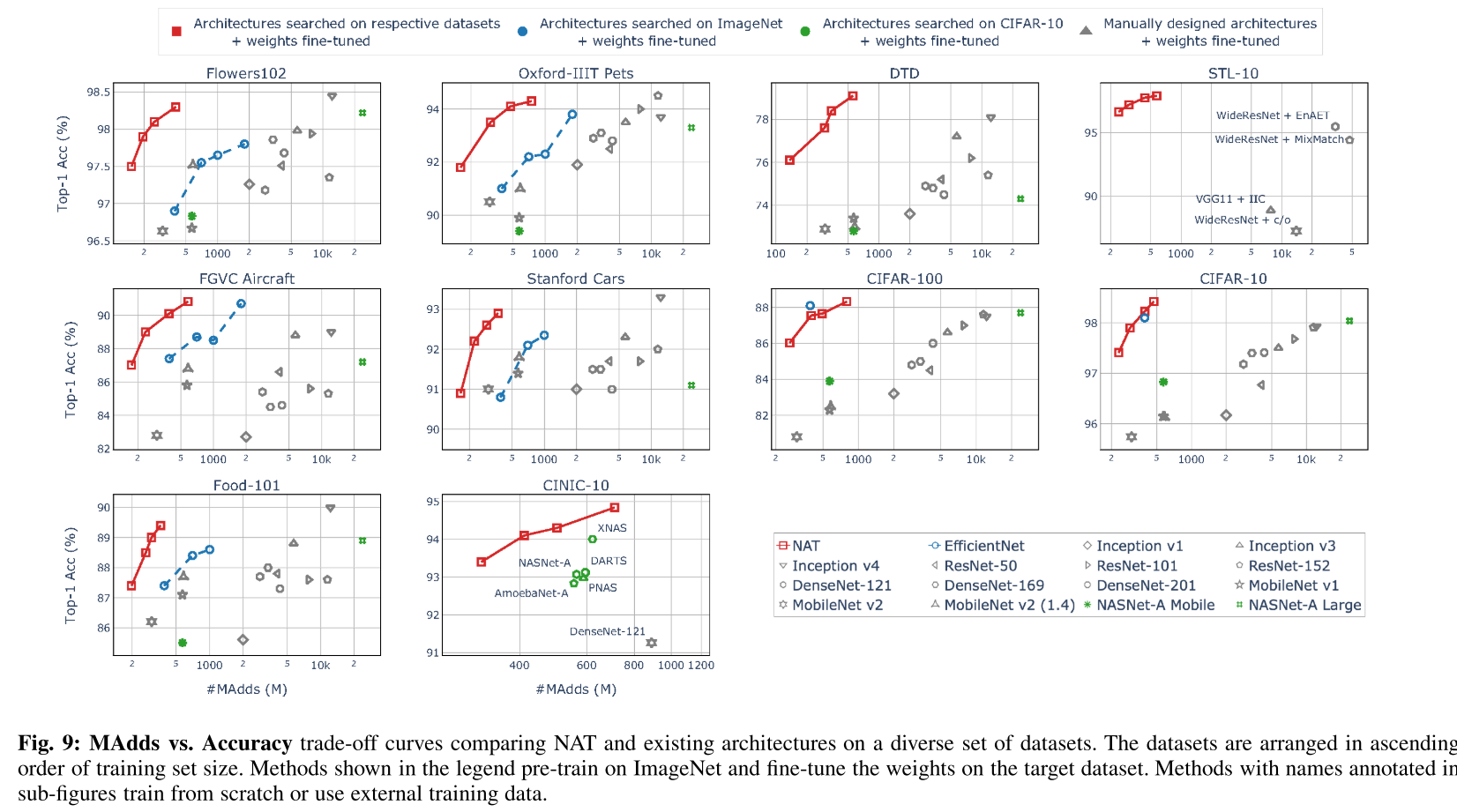
图9:
- 在所有数据集中,NATNets基本上都有最好的trade-off,同时效率(#MAdds)比现有手工设计的模型高出一个数量级,说明直接在目标数据集上搜索子网结构效果最好,比在标准数据集(CIFAR10/ImageNet)上搜索结构,再对(权重)迁移学习(fine-tune)的效率更高。
- 按照数据集大小排序, 可以看出, 尤其是在小数据集上, NATNets的 trade-off 比传统的迁移学习/手工设计网络高得多.
图10对10个数据集上350M MAdds 的模型进行可视化,可以发现这些相同大小的网络结构之间并没有相似性,进一步说明为不同数据集定制不同结构的重要性:

Scalability to Objectives
多目标的优化,主要靠搜索阶段的 NSGA-III多目标选择 算法来实现
实例:3目标优化(Acc↑,Params↓,MAdds↓),(Acc↑,Params↓,GPU Latency↓),(Acc↑,Params↓,CPU Latency↓)
图11上 展示了3目标优化的Pareto曲面,说明多个目标之间存在trade-off,例如模型大小(Params)和模型效率(MAdds/GPU Latency/CPU Latency)之间存在trade-off,即模型大小和效率之间并不是完全相关的(Params小并不意味这效率高);可以在多个目标之间搜索trade-off也是NAT的优势之一。
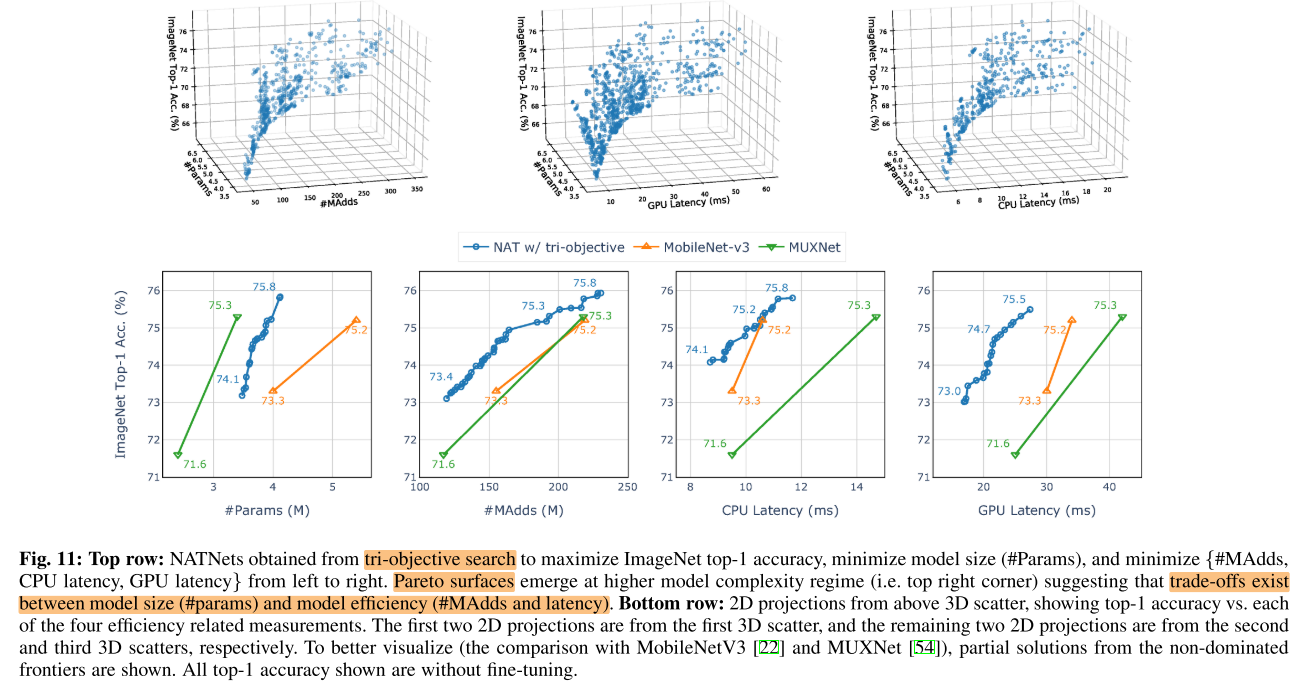
图11下 展示了3目标优化的Pareto曲面在二维的投影,除了在(Acc,Params)上的trade-off比MUXNet差之外(MUXNets是一个专门对 Acc,Params,MAdds 进行三目标优化NAS中获得的),在其余3个2D trade-off 上都表现优异。在附录F中,我们还对一个12目标的约束做了优化。
Utility on Dense Image Prediction
密集预测:标注每个像素的类别(语义分割)
Ablation Study
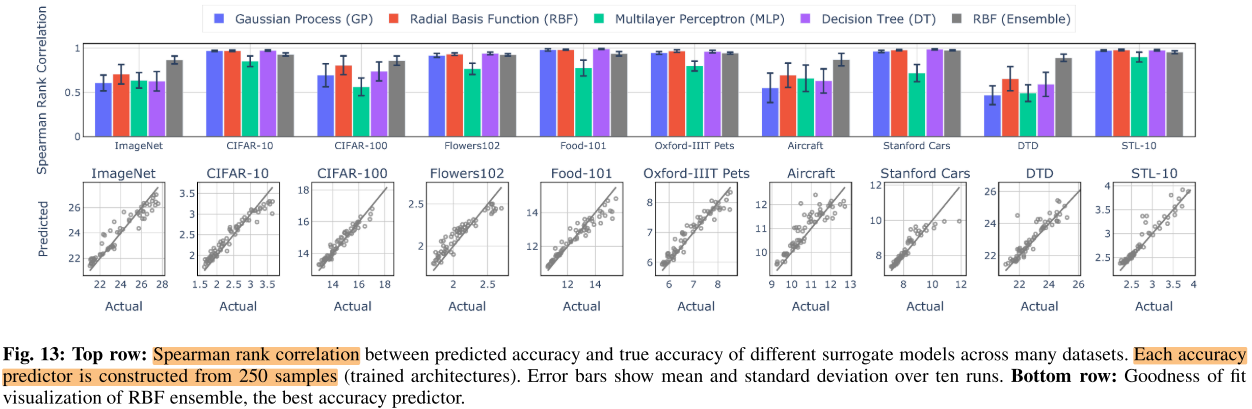
Acc Predictor
在搜索空间中均匀采样350个子网结构:
- 每个子网都在ImageNet上训练150个epoch:350 × (arch,Acc) 350×150epoch
- 每个子网都在其他10个数据集上微调50个epoch:10 × 350 × (arch,Acc) 10×350×50epoch
每个数据集有350 pair训练数据,按300/50随机划分为训练集和测试集,用于训练 Acc Predictor,训练样本从50-300变化,11个数据集上的平均相关系数的变化:
实验中选择训练规模为100,使用RBF ensemble作为Acc Predictor。
Search Efficiency
开销对比
NAS算法的开销可以分为3部分:
- 准备阶段:
- One-shot类:超网的训练,Acc Predictor的训练
- 搜索阶段:
- 搜索采样(EA)
- 直接推理/使用Acc Predictor预测
- 耦合训练(如NAT)
- 搜索后阶段:
- 对搜索到的子网fine-tune,train from scratch
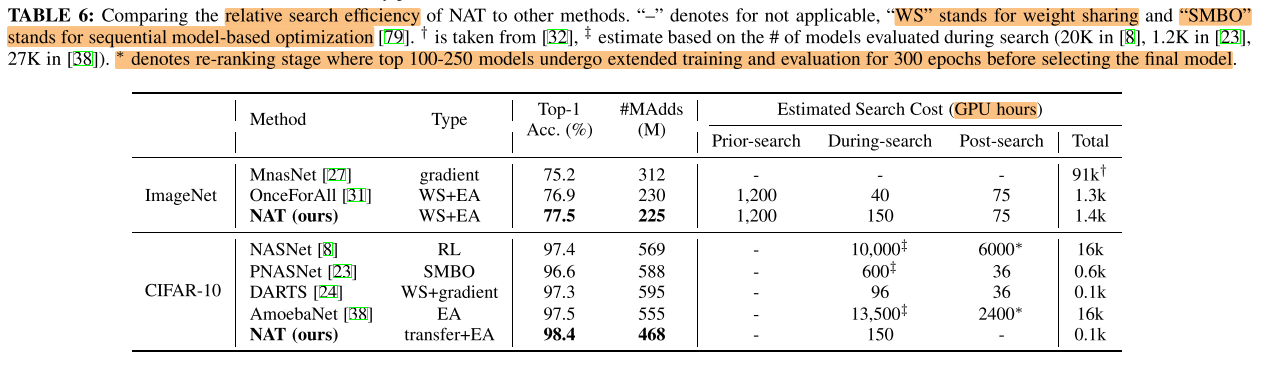
搜索算法
3x-5x more efficient than baseline
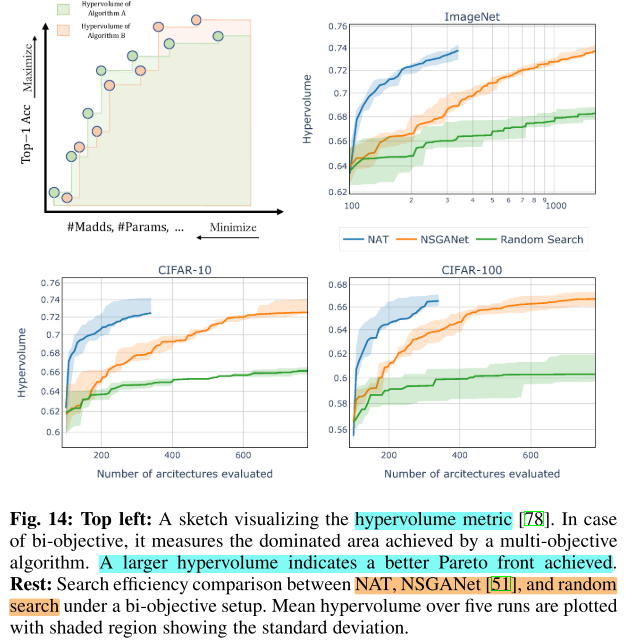
Crossover & Mutation Hyperparameters
对进化算法中的交叉互换的超参数做消融
Effectiveness of Supernet Adaptation
Supernet Adaptation
NAT使用的方式:在pre-trained超网的基础上,边搜索满足约束的trade-off子网,边fine-tune这些子网。(用这种方式进行超网训练)
30个iteration,每个iteration 5个epoch,每个batch采样并更新一个子网。
Subnet Adaptation
在pre-trained超网的基础上,搜索满足约束的 trade-off 1个子网,每个子网 fine-tune 5个epoch。
选几个子网进一步 fine-tune 150个epoch。

结论:
- Supernet Adaptation的方式会更好
- 在每个类别样本较多的数据集(样本量够大 CIFAR10/100)上,fine-tune的效果比较好(样本量够大,train from scratch效果就很好,不够大的话就需要transfer)。
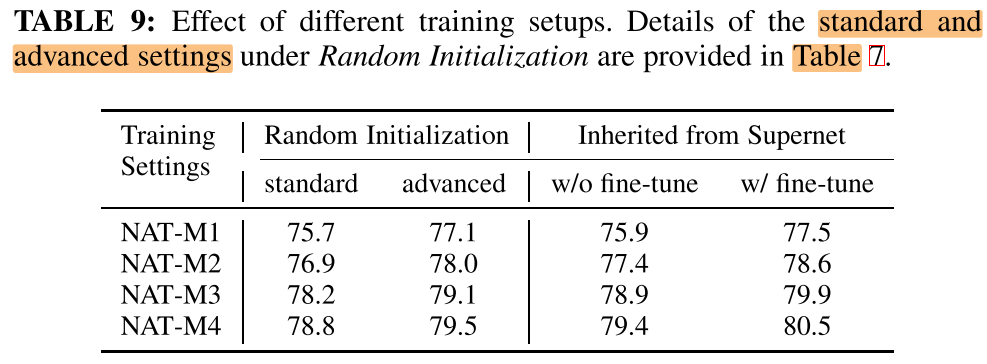
Towards Quantifying Architectural Advancement
standard 和 Advance 的训练设置:

超网是否在pre-trained的基础上的区别:
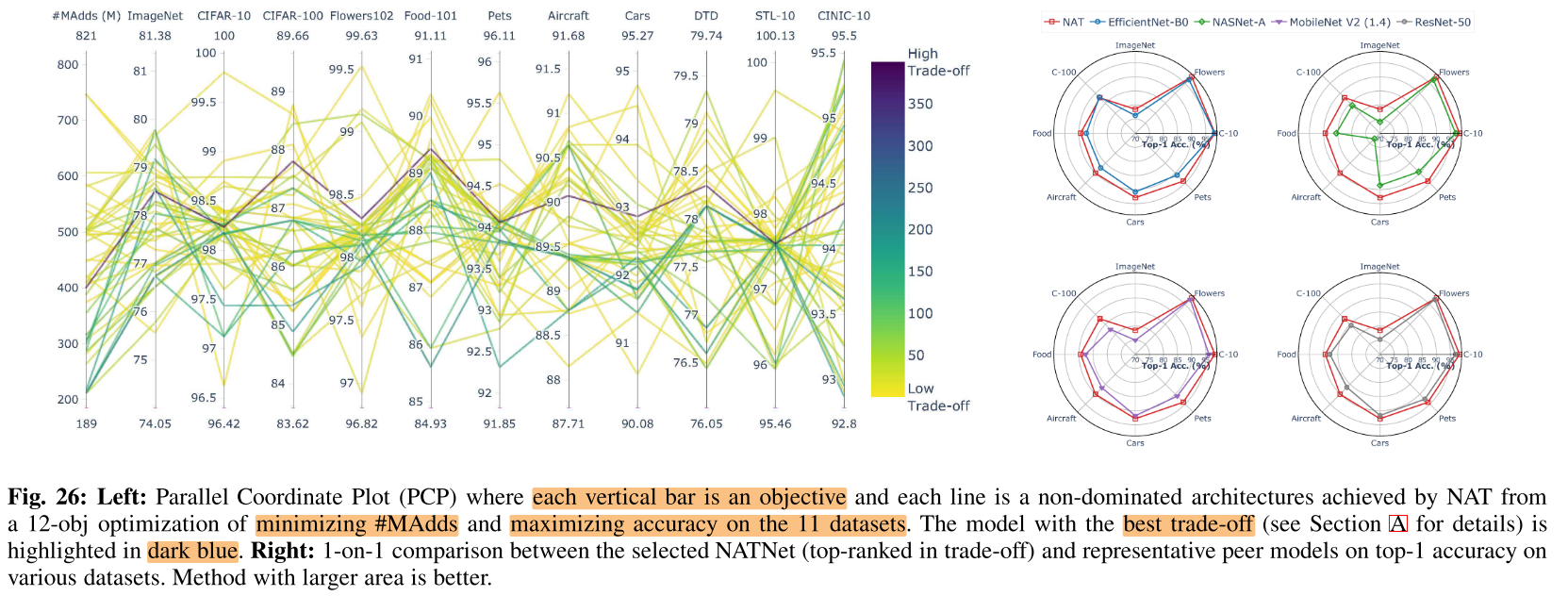
12-objective optimization
11个数据集的top 1 acc + #MAdds
在11个数据集上搜索到1个400M的子结构,同时在11个数据集上取得了很好的trade-off
图26右:获得的一个子网模型 与 不同baseline在不同数据集上fine-tune后的性能的对比
Conclusion
Summary
核心思想:在pre-trained超网的基础上,边搜索满足约束的trade-off子网,边fine-tune这些子网,结束后然后就可以直接获得满足需求的子网。
pros:
- 边搜优质子网边训的想法还是比较容易想到的
- 多目标的优化,主要靠搜索阶段的 NSGA-III多目标选择 算法来实现
cons:
- 所需计算资源巨大
- 进化算法用了其他文章的方法, 略复杂
To Read
Reference
https://blog.csdn.net/qq_26269815/article/details/106728909

 浙公网安备 33010602011771号
浙公网安备 33010602011771号