【GreedyNAS】2020-CVPR-GreedyNAS: Towards Fast One-Shot NAS with Greedy Supernet-论文阅读
GreedyNAS
2020-CVPR-GreedyNAS: Towards Fast One-Shot NAS with Greedy Supernet
来源:ChenBong 博客园
- Institute:Sensetime,Tsinghua,Huazhong University
- Author:Shan You,Tao Huang,Mingmin Yang
- GitHub:/
- Citation: 21
Introduction
之前的超网训练都是均匀采样,本文采用贪心采样,更多地采样good path,从而多训练good path,使得评估阶段超网对 good path 群体的相对性能的评估更准确。
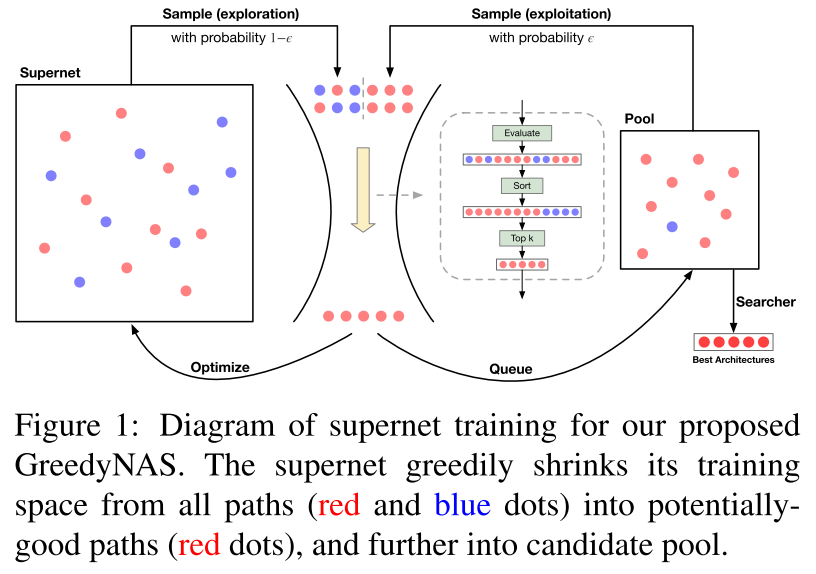
Motivation
不同的子网的潜力是不同的,有的子网潜力高(即good path,可以被训练到较高的精度),有些子网潜力低(即bad path,再怎么训练也无法达到较高的精度)。
超网作为一个性能评估器,在之前的工作中,超网是用来评估所有的子网,而实际上我们需要的是评估 good path,即我们希望超网对good path的群体的相对性能评估越准确越好,而不是希望超网对所有子网的相对性能评估都很准确。而由于good path 和 bad path 是共享参数的,在超网训练过程中,训练 bad path 反而可能对 good path 的性能造成损害,因此在训练阶段应该减少对 bad path 的训练,多训练 good path。
Contribution
Method
sampling
均匀采样/训练
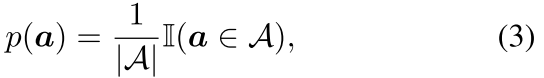
只采样/训练 good path
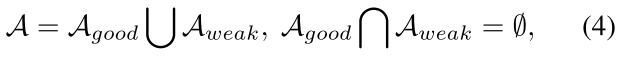
假设存在先验的超网 \(\mathcal{N}_{o}\) ,可以判断一个子网是否是good path:
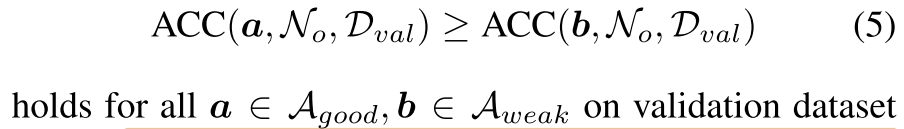
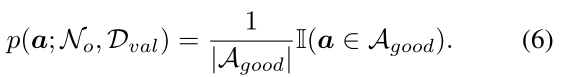
Greedy path filtering
实际上先验的超网 \(\mathcal{N}_{o}\) 并不存在,如何实现只训练/采样 good path?
很简单的想法是每次随机采样m个子网,验证一下m个子网的acc,只训练 m 个中的 top-k 个子网,作者实际上也是这么做的,但加入了一些数学的包装。
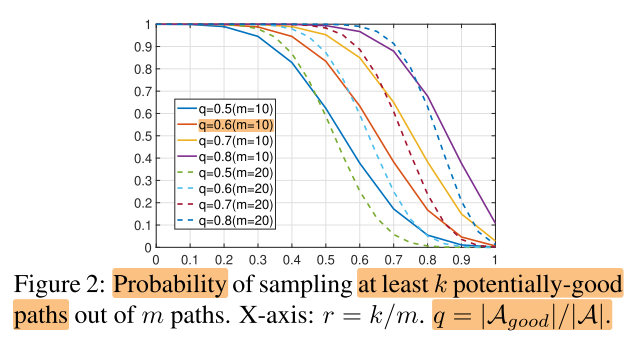
例如,good path 的比例 q=0.6,从超网中随机采样m=10个子网,其中至少有k=5个是 good path 的概率是83.38%。
即定理1:

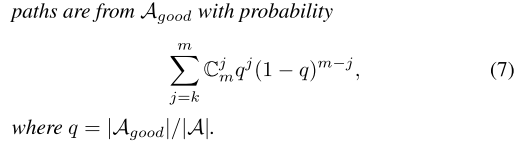
根据定理1,假设 good path 的比例q后,每次采样m个子网,评估这m个子网,只训练top-k个子网,即可实现每次都训练 good path
另外,在评估m个子网时,为了减少计算开销,用的是验证集的子集(1k)
Training with exploration and exploitation
引入一个优质模型池 P 来保存采样中获得的优质模型,每次采样时,一部分 \(\epsilon\) 从模型池中采样(local sample),一部分从超网中采样(global sample)
保持稳定性(local sample)和随机性(global sample)
采样概率分布变为:
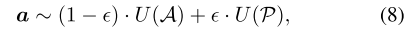

训练后更新模型池
Stopping principle via candidate pool
不手动设置超网训练的epoch数,当模型池的变化不大时,自动停止
定义模型池的变化比例 \(\pi\) ,引入超参 \(\alpha\) ,当变化比例小于 \(\alpha\) 时自动停止超网训练
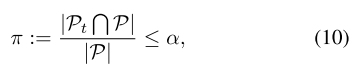
Searching with candidate pool
超网训练完毕后,使用 NSGA-II(进化算法的一种)对超网进行搜索,使用模型池中的 good path 作为初始化种群
retrain
重训找到的最佳结构
Experiments
Searching on same search space
w/o SE
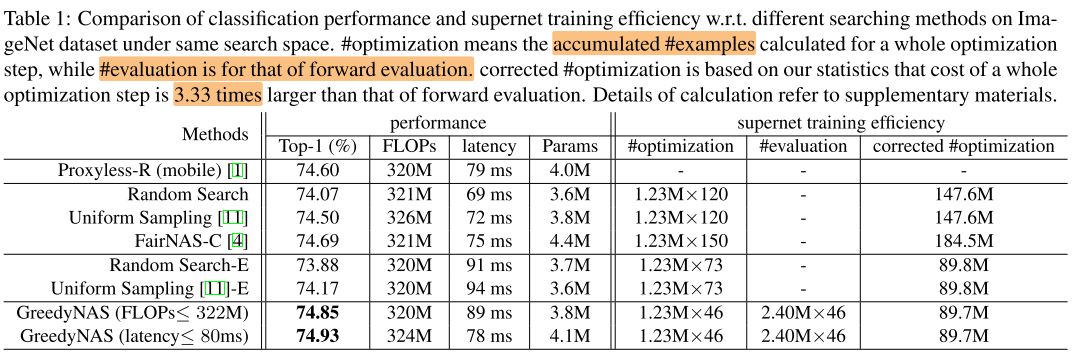
为了统一训练开销,使用样本数作为训练开销的评价指标
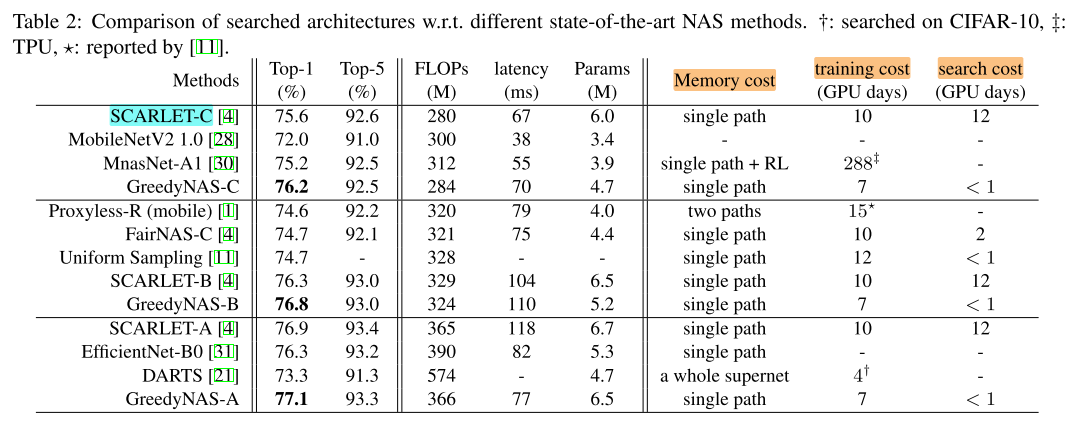
Searching on augmented search space
w/ SE
To comprehensively illustrate our superiority to various state-of-theart NAS methods, we implement searching by augmenting the current space with an SE option.
Ablation
超网训练中,使用的验证集的大小
1k vs 50k的相关性

各个部分的作用

path filtering does contribute to the supernet training
full training with candidate pool (Net5) seems to drop the accuracy a bit
extreme greedy exploitation on the candidate pool harms the supernet training instead
Conclusion
Summary
To Read
Reference
https://bbs.cvmart.net/topics/2294

 浙公网安备 33010602011771号
浙公网安备 33010602011771号