【RS-Net】2020-ECCV-Resolution Switchable Networks for Runtime Efficient Image Recognition-论文阅读
RS-Net
2020-ECCV-Resolution Switchable Networks for Runtime Efficient Image Recognition
来源:ChenBong 博客园
- Institute:Ttsinghua,Intel
- Author:Yikai Wang,Fuchun Sun,Duo Li,Anbang Yao
- GitHub:https://github.com/yikaiw/RS-Nets 【30+】
- Citation: 3
Introduction
分辨率大小可切换网络
Motivation
- balancing between accuracy and efficiency
Contribution
- parallel training framework within a single model
- shared network parameters but privatized Batch Normalization layers (BNs)
- ensemble distillation
Method
Multi-Resolution Parallel Training
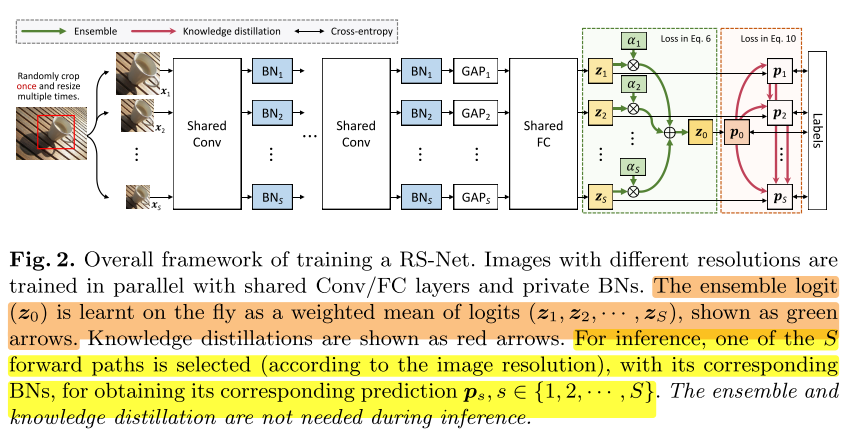

Multi-Resolution 分类Loss

Multi-Resolution 对不同Resolution的影响
compared with individually trained models, how does parallel training affect test accuracies at different resolutions?
现象:和单一分辨率训练的模型比起来,同时使用2种分辨率进行训练的模型,会提高对大分辨率的性能,降低对小分辨率的性能。
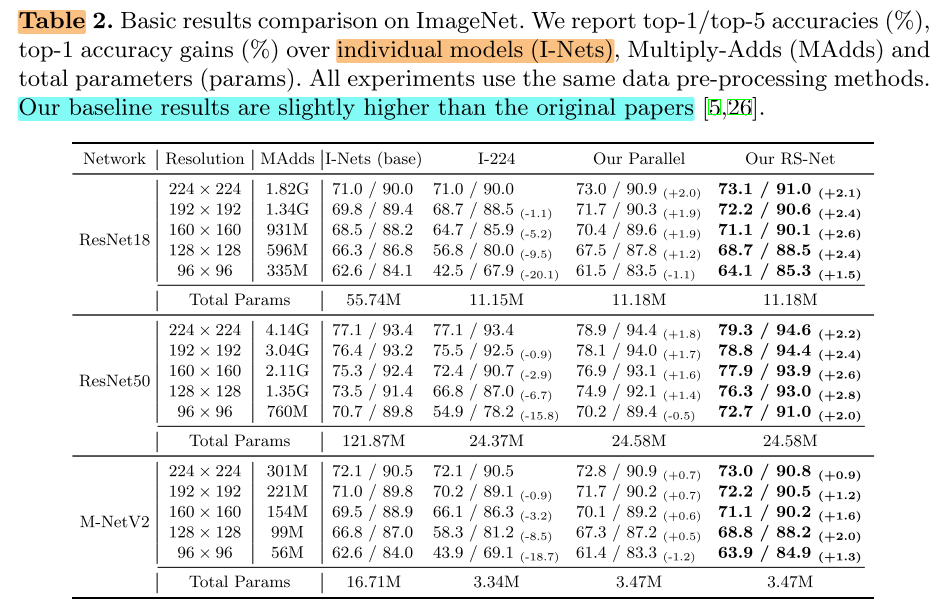
Results in Table 2 show that for the parallel training with five resolutions, accuracies only decrease at 96 × 96 but increase at the other four resolutions.
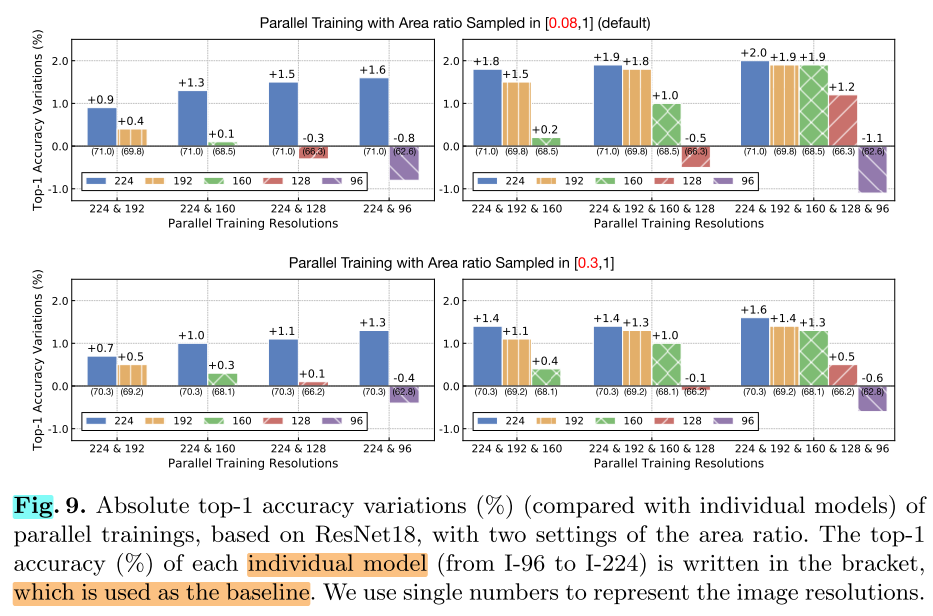
原因,2个角度:
- wide range of image resolutions => improves the generalization and reduces over-fitting
- there exists a train-test discrepancy that the average “apparent object size” at testing is smaller than that at training(Table 2,Fig. 9)

ps.
For image recognition, although testing at a high resolution already tends to achieve a good accuracy, using the parallel training makes it even better.
Multi-Resolution Ensemble Distillation
为什么要做 Ensemble和KD?
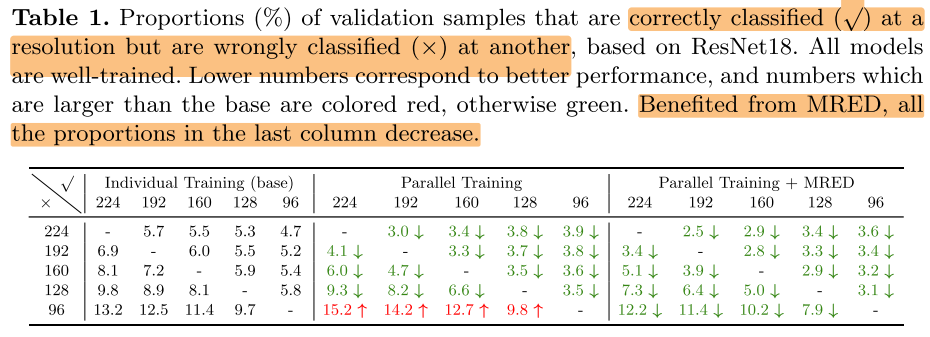
there always exists a proportion of samples which are correctly classified at a low resolution but wrongly classified at another higher resolution.
Such results indicate that model predictions at different image resolutions are complementary, and not always the higher resolution is better for each image sample.
MultiResolution Ensemble Distillation (MRED)
Ensemble Loss

ensemble 后的输出和 ground truth 做 CE:

KD Loss
- vanilla version:
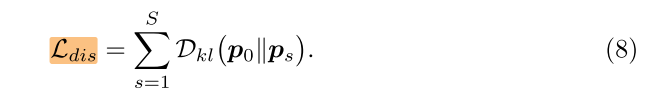
- full version:
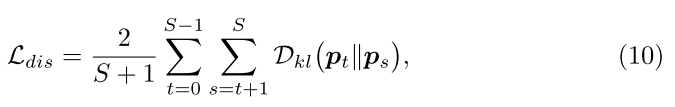
Total Loss
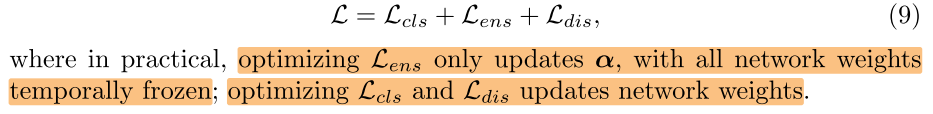
Experiments
Setup
- S =
- Training(RandomResizedCrop):
- area ratio:[0.08, 1.0]
- aspect ratio:[3/4, 4/3]
- Valid:
- resize images with the bilinear interpolation to every resolution in S divided by 0.875
- feed central regions to models.
Result
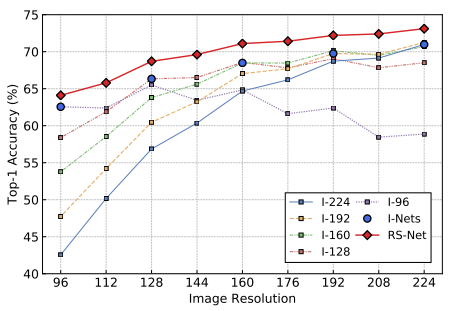
Basic Results:Individual / Full / Parallel-train / RS-Net 对比
- parallel training brings accuracy improvements at the four larger resolutions, while accuracies at 96 × 96 decrease.
- Compared with I-Nets, our RS-Net achieves large improvements at all resolutions with only 1/5 parameters.
- ResNet18 and ResNet50, accuracies at 160 × 160 of our RS-Nets even surpass the accuracies of I-Nets at 224 × 224, significantly reducing about 49% FLOPs at runtime.
Fig. 4. right:
Switchable (Width / Resolution)
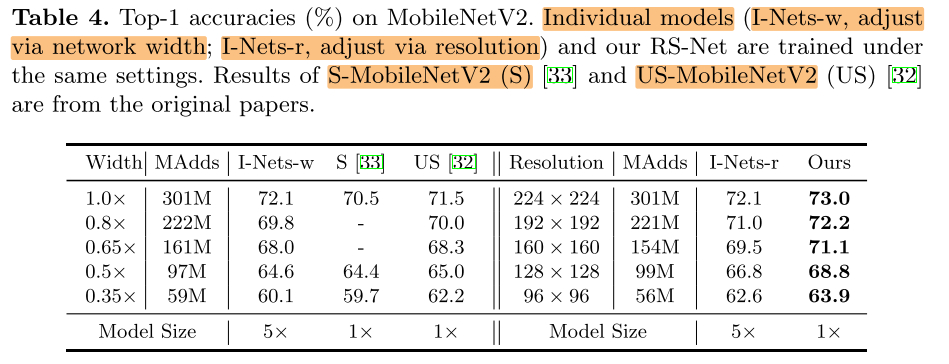
调整width / resolution 达到相同的flops,调整 resolution 方法达到的精度更高。
Ablation Study
Private BNs
Fig. 4 left:
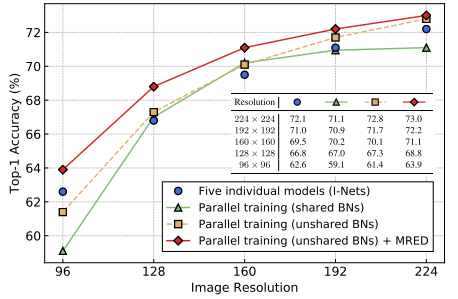
When BNs are shared, activation statistics of different image resolutions are averaged, which differ from the real statistics especially at two ends of resolutions.
Tested at New Resolutions
Fig. 4 right:
Verification of Ensemble Distillation
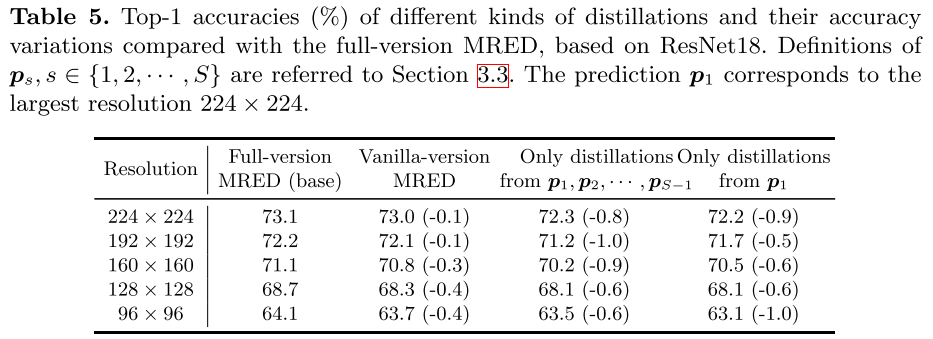
- vanilla version:
ensemble \((p_0)\)教 所有分辨率的 student \((p_1-p_{s-1})\)
- full version:
ground truth 教ensemble (p0),ensemble (p0)教最大分辨率(p1),大分辨率教小分辨率(p1教p2,p2教p3...),逐级学习
resolution / crop

不同分辨率要来自同一个crop,效果比较好
后面2列应该是指用5个相同分辨率的模型做ensemble
Conclusion
- 分辨率可切换网络,只改变了网络的输入分辨率,想法很简单
- 加入了KD,ensemble等方法
- 对分辨率的各种影响,以及方法本身做了很充分的实验

 浙公网安备 33010602011771号
浙公网安备 33010602011771号