【US-Net】2019-ICCV-Universally Slimmable Networks and Improved Training Techniques-论文阅读
US-Net
2019-ICCV-Universally Slimmable Networks and Improved Training Techniques
来源:ChenBong博客园
- Institute:University of Illinois at Urbana-Champaign
- Author:Jiahui Yu,Thomas Huang
- GitHub:https://github.com/JiahuiYu/slimmable_networks 【600+】
- Citation:60+
Introduction
能不能只训练一个网络,适应不同性能的机器,即在不同资源限制下,自动调整计算开销?
Slimmable Networks 三部曲
2019-ICLR-Slimmable Neural Networks
2019-ICCV-Universally Slimmable Networks and Improved Training Techniques
2019-NIPSw-AutoSlim: Towards One-Shot Architecture Search for Channel Numbers
2019-ICLR-Slimmable Neural Networks
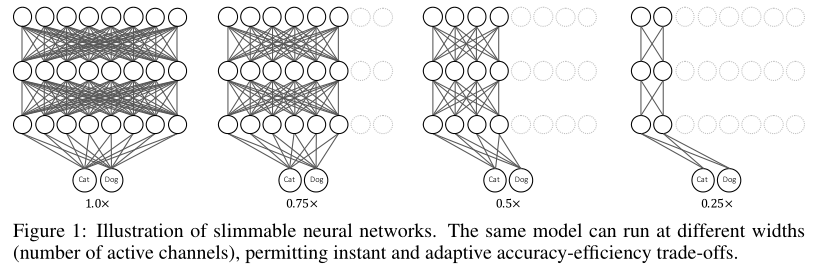
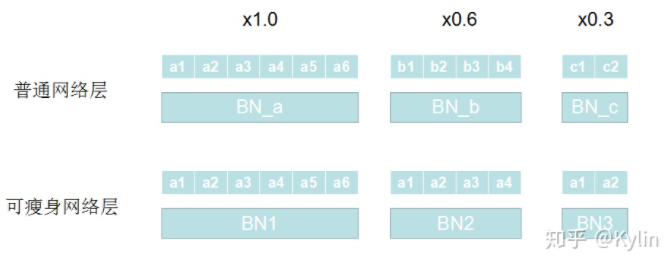

BN层的问题
- naive training 是指不同width的4个结构共用BN层
- S-BN 是指不同width的4个结构有各自的BN
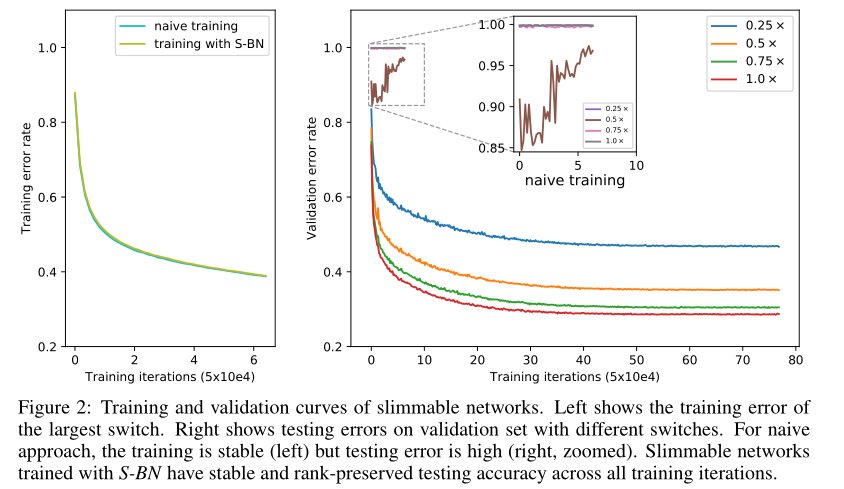
- 左图是最大的网络的训练图像,右图是4个规模的网络的训练图像,可以看出共用BN层的4个规模的网络在测试模式下的性能完全损坏,而使用各自的BN层的方式进行训练的4个网络曲线正常
BN(Batch Normalization)的作用:
- 在训练时,BN中的均值的方差始终是使用当前batch进行计算的
- 在测试时,只需要推理很少的样本,无法像训练时对BN进行重新计算,因此在训练过程中会根据每个batch的统计量更新均值和方差,以供测试模式使用
pytorch BN层 参数:
- training=True, track_running_stats=True, 这是常用的training时期待的行为,running_mean 和running_var会跟踪不同batch数据的mean和variance,但是仍然是用每个batch的mean和variance做normalization。
- training=False, track_running_stats=True, 这是我们期待的test时候的行为,即使用training阶段估计的running_mean 和running_var.
- training=True, track_running_stats=False, 这时候running_mean 和running_var不跟踪跨batch数据的statistics了,但仍然用每个batch的mean和variance做normalization。这个模式进行test的话,如果batch不够大,测试精度会很差
所以图2中 naive training 遇到的问题就是,在训练模式下分别前向4个规模的网络时,4个网络使用的BN都是使用当前batch重新计算的(这时候会更新 running_mean 和 running_var);但是在测试模式下,前向4个网络时,用的是共享的running_mean 和 running_var,在每次迭代中,这个统计量被4个规模的网络分别更新过一次,导致不适合任何一个规模的网络。
因此三部曲里的第一部:2019-ICLR-Slimmable Neural Networks 这篇文章使用了简单的每个规模的网络使用各自的BN层的方法,来实现一个网络,同时拥有4个规模的计算开销的目的。
Motivation
三部曲中的第一部 2019-ICLR-Slimmable Neural Networks 对权重共享参数,BN层每个规模的模型私有的方法,实现一个网络,同时拥有4个规模的计算开销的目的。
但还存在一个问题,4个规模的开销是离散的(如设备的资源限制是70M,但模型只能提供40/60/80/100M,只能选择60M的模型),能否训练一个模型,使得FLOPs的调整可以是连续的(任意宽度的)?
Contribution
Method
Rethinking Feature Aggregation

增加网络宽度 和 在ResNet中增加网络深度 类似:
- ResNet中,因为有跳跃连接的存在,使得更深的网络的表达能力一定是大于等于更浅的网络(只要增加的层输出为0,就等价于浅的网络)
- 在全连接/卷积网络中,更宽的网络的表达能力一定是大于等于更浅的网络(只要增加的神经元输出为0,就相当于窄的网络)
不同宽度网络的误差不等式:
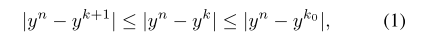
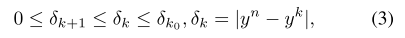
在给定了 \(k_0(eg. k_0=0.25n)\) 后,网络的性能就确定了上下界。从理论上说明了连续宽度的网络的性能曲线是存在的,且上下界也是确定的。
如何训练?
BN层的问题
采样和第1部当中一样的方式,每个宽度都分配一个BN层?在训练过程中,每个 batch 都要更新 \((n-0.25n)\) 个BN层,计算开销太大。
回到第一部中的图2:
公共BN层在测试模式下崩溃其实只是因为公共BN层的统计量不适用于任何一个规模的子网,但训练其实是不受影响的。且公共BN和私有BN在训练的全程使用的BN其实是完全一致的。因此加不加入私有BN,都不影响训练!
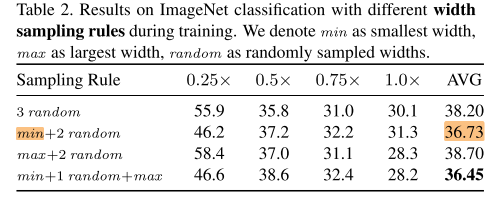
因此作者提出:先进行模型训练,等到模型收敛后,再固定模型参数,重新计算 \((n-0.25n)\) 个子网的BN,称为 Post-Statistics of Batch Normalization,即训练后统计,该过程可以一次性快速完成,且甚至不用使用整个训练集的样本进行统计,只要少量(1-2k)样本进行统计即可。
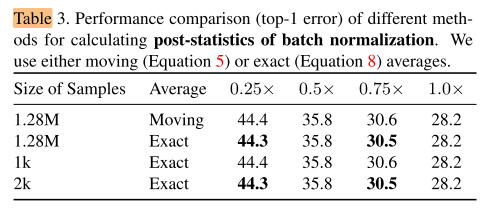
训练过程中,每轮训练几个子结构?Sandwich Rule
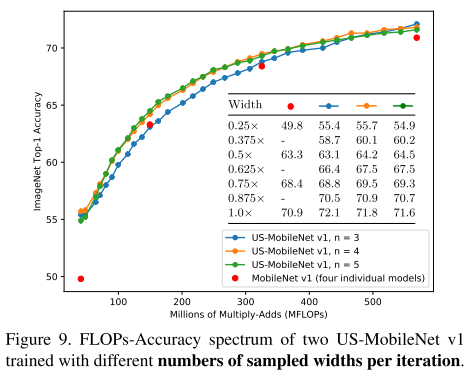
按照第一部中的做法,每轮迭代都会训练4个规模的子网,然后梯度累积一起更新。这里的子网个数太多,显然不能每轮更新所有子网。
作者设计一种训练方式叫做The Sandwich Rule。The Sandwich Rule 训练方式就是说,先训练没有任何裁剪的网络,这里称为max model, 然后再训练随机采样的模型,称为random model,最后训练min model。
训练max model和min model是非常有必要的。因为基本观点里面告诉我们,模型性能是被界定了的,训练max model和min model实际上是在提高整个模型界定区间的性能。同时使用随机采样的方式训练其他子模型可以在保证收敛的前提下,大大减少计算量。
训练的子结构是否要使用 max 和min:
训练几个?
完整的算法流程

训练技巧,加入 Inplace Distillation
Sandwich Rule的训练方式天然地适合知识蒸馏,max model作为 teachet,其余规模子网络都作为 student。
max model 使用 ground truth 作为 label 学习,random和min都使用 max model的输出作为label进行学习。
作者也尝试了将 ground truth 也作为所有子网的 label 来学习,但效果都更差。
是否使用 Inplace Distillation 效果对比:
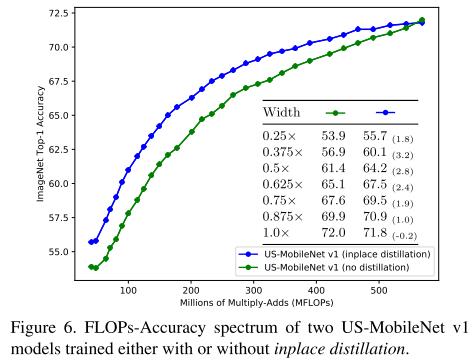
Experiments
ImageNet
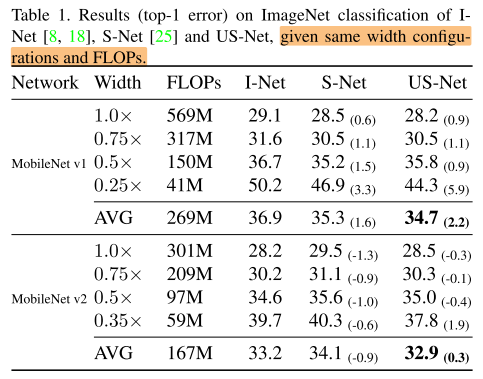
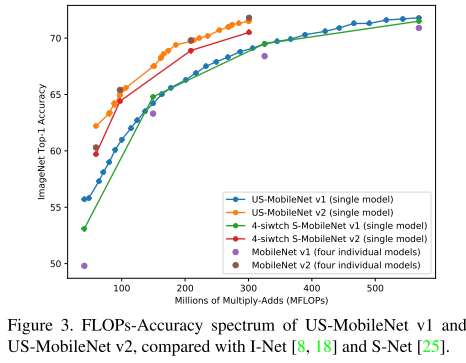
Discussion
Nonuniform Universally Slimmable Networks 非统一的宽度
在训练后,对某个层(stage)施加额外的放缩(x0.6),得到非同一的宽度的子网:
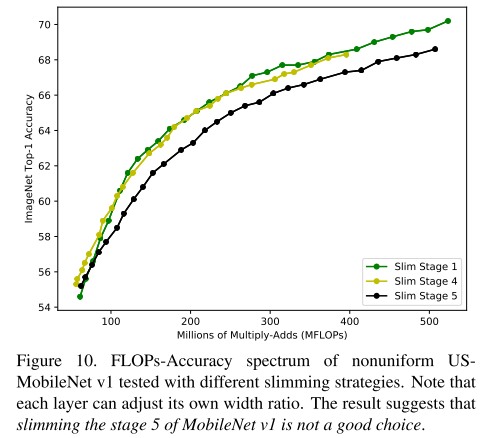
Naturally Slimmable
是否不同宽度的子络重新计算BN后都可以达到很好的效果?不是。
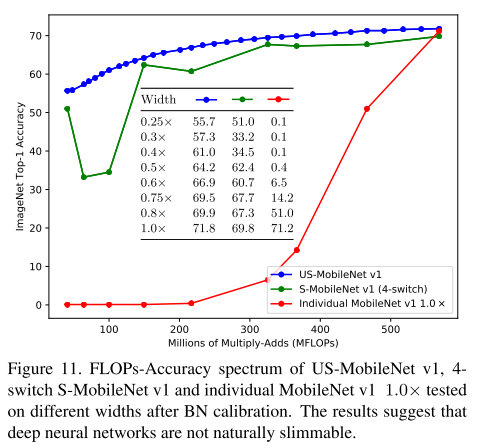
Conclusion
Summary
To Read
Reference
https://zhuanlan.zhihu.com/p/34879333
https://www.zhihu.com/question/282672547
https://www.zhihu.com/question/306865592
https://zhuanlan.zhihu.com/p/105064255
https://www.cnblogs.com/wyboooo/p/13563822.html
http://www.wildz.cn/algorithm/universal-slimmable-network.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号