【DLT】2019-NIPS-Deconstructing Lottery Tickets Zeros, Signs, and the Supermask-论文阅读
DLT
2019-NIPS-Deconstructing Lottery Tickets Zeros, Signs, and the Supermask
来源:ChenBong 博客园
- Institute:Uber AI
- Author:Hattie Zhou、Janice Lan、Rosanne Liu、Jason Yosinski
- GitHub:https://github.com/uber-research/deconstructing-lottery-tickets 90+
- Citation:70+
Introduction
彩票假设提出,大网络随机初始化进行训练后,基于幅值对权重剪枝(剪枝率95%-99.5%),构建稀疏网络,将稀疏网络的权重初始化为大网络的初始值,重新训练稀疏网络,对比原始的大网络无精度损失。但如果稀疏网络权重重新初始化,反而无法达到原始原始大网络的精度。该稀疏网络称为”中奖网络“。彩票假设假说说明,一个大网络,总是存在一个稀疏的子网络,即“中奖网络”,当中奖网络的权重初始化为原始网络的初始化权重后重新训练,精度和原始的大网络相当。
本文是对彩票假设的3个关键部件的进一步分析和实验,说明了
- 对稀疏网络 pruned weight 置零并冻结的重要性
- 稀疏网络初始化时,只要保持原始大网络的权重的正负性不变即可达到很好的效果(正负性比权值更重要)
- mask 的过程类似训练网络的过程
通过训练mask的方法(保持网络权重在随机初始化状态),发现了 Supermasks 的存在,可以在未经随机初始化的网络上达到 MNIST 86%,CIFAR-10 41% 的精度。
Motivation
非结构化剪枝得到的稀疏网络精度通常都很高,但直接训练稀疏网络却很困难。
彩票假设一文用实验证明了“中奖网络”的存在,但有一些问题没有解决,如:
- 剪枝的准则?(基于幅值等)
- 保留的权重的初始化方式?(初始化为原网络的初始值等)
- 剪去的权重的处理方式?(置零,在后续训练中冻结)
Contribution
对彩票假设的有效性的3个可能的原因(剪枝准则,保留的权重的初始化方式,剪去的权重的处理方法)做了实验,分析彩票假设之所以work的原因,并找到了更好或相当的(剪枝准则,保留的权重的初始化方式,剪去的权重的处理方法)。
通过训练mask的方法(保持网络权重在随机初始化状态),发现了 Supermasks 的存在,可以在未经随机初始化的网络上达到 MNIST 86%,CIFAR-10 41% 的精度。
Method

彩票假设使用的是one-shot剪枝,这里用的是迭代剪枝,one-shot剪枝可以看成迭代剪枝的子集。
Mask criteria
问题:彩票假设中对训练后的网络使用的是基于幅值的剪枝,为什么基于幅值的剪枝会work?使用其他剪枝准则会表现如何?
mask criteria 可以表示为初始化值 \(w_i\) 和 训练后的值 \(w_f\) 的函数: \(M(w_i, w_f)\)

进一步可以提出以下9种 criteria:
final weights:
- large_final (彩票理论使用的)
- small_final
initial weights:
- large_init
- small_init
combination:
- large_init_large_final
- small_init_small_final
weights move:
- magnitude_increase
- movement
2种 weights move 的区别:其中 magnitude_increase 保留的更多是训练前后不变正负号的权重。

criteria > 阈值的剪去(置零,并在后续fine-tune过程中不进行训练)
9种 criteria 实验结果:
FC on MNIST,Conv2/4/6 on CIFAR-10
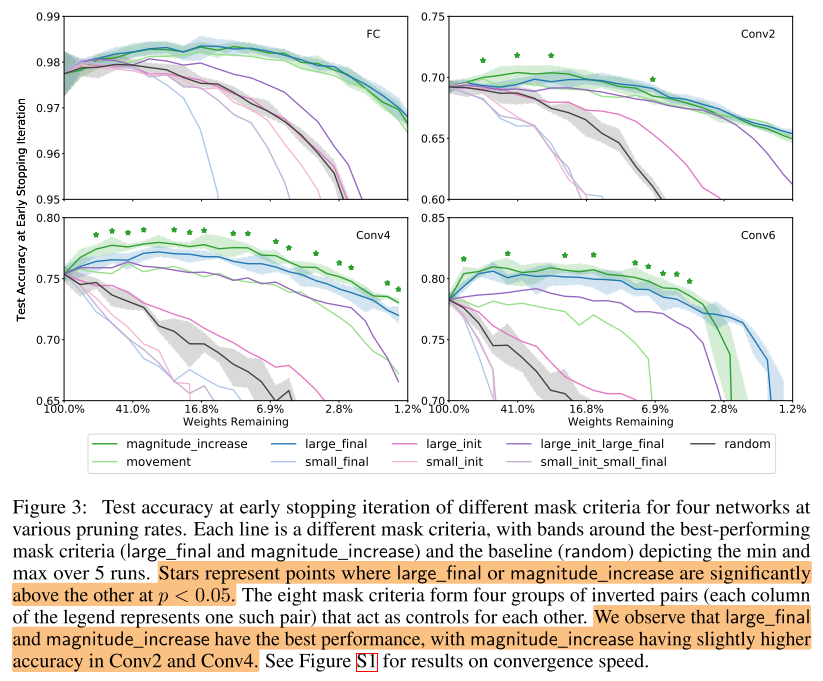
分析:
-
在前3对互为相反的剪枝准则中,一个表现比random好,另一个就会比random差
-
magnitude_increase 与 large_final 相当甚至更好,在适当的剪枝率下都会超过原始网络
问题:为什么这2种准则会work?后面2部分继续解释。
Mask-1 actions: the sign-ificance of initial weights
问题:彩票假设中对保留下来的权重是初始化为原始网络的初始权重,如果重新初始化效果反而不好,为什么初始化为原始网络的初始权重会work?选择其他初始化方式效果如何?
Mask-1 actions 即对mask=1(要保留的权重)如何初始化:
- reinit:重新初始化中奖网络,权重分布和原始大网络相同
- reshuffle:重新初始化中奖网络,权重分布和剪枝后中奖网络相同
- constant:重新初始化中奖网络,初始化为 (-α,0,α),其中α为该层原始初始化权重的标准差
每种初始化方式还可以分为是否保持和原始初始值符号一致(init sign),和符号随机(sign random),组合出6种初始化方式:
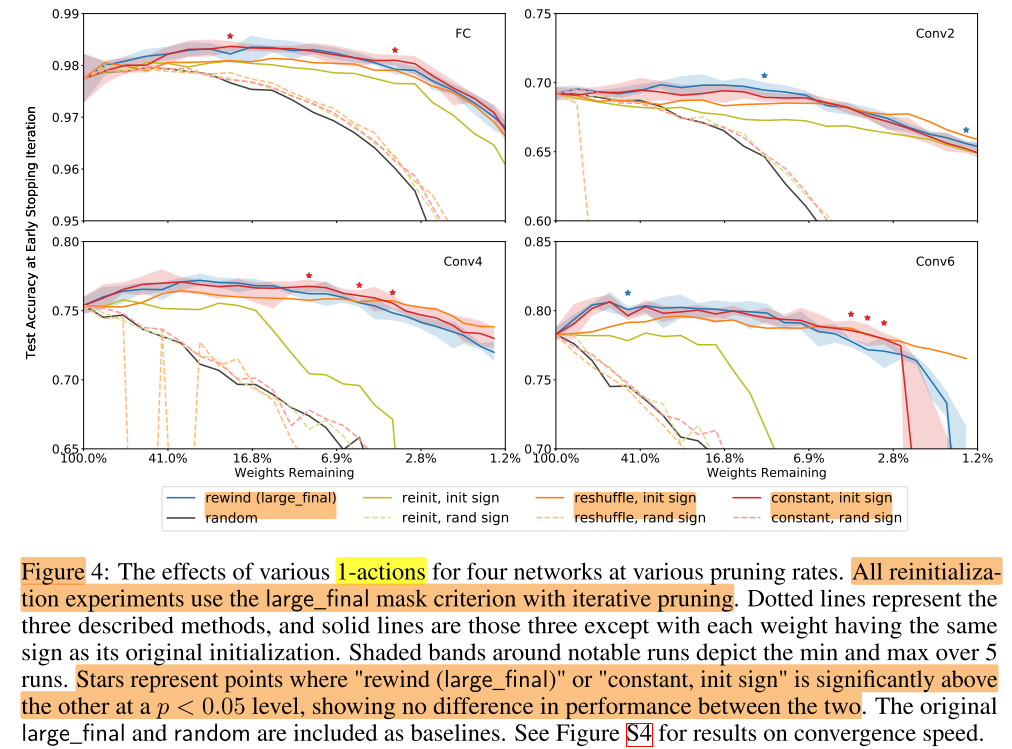
分析:
- 3种初始化方式,当保持符号一致时,表现都较好(超过未剪枝模型)
- 因此彩票假设中初始化为原始网络的初始权重之所以会work的主要原因是保持了符号的一致性,而不是保持权重的大小
Mask-0 actions: masking is training
问题: 彩票假设中对剪掉的权重是置零,冻结(在后续训练中不更新)
However, if the value of zero for the pruned weights is not important to the performance of the network, we should expect that we can set pruned weights to some other value, such as leaving them frozen at their initial values, without hurting the trainability of the network.
对mask=0的权重 在fine-tune前的初始化方式:
- 置零(彩票假设),并冻结
- 置为原始网络的初始值,并冻结
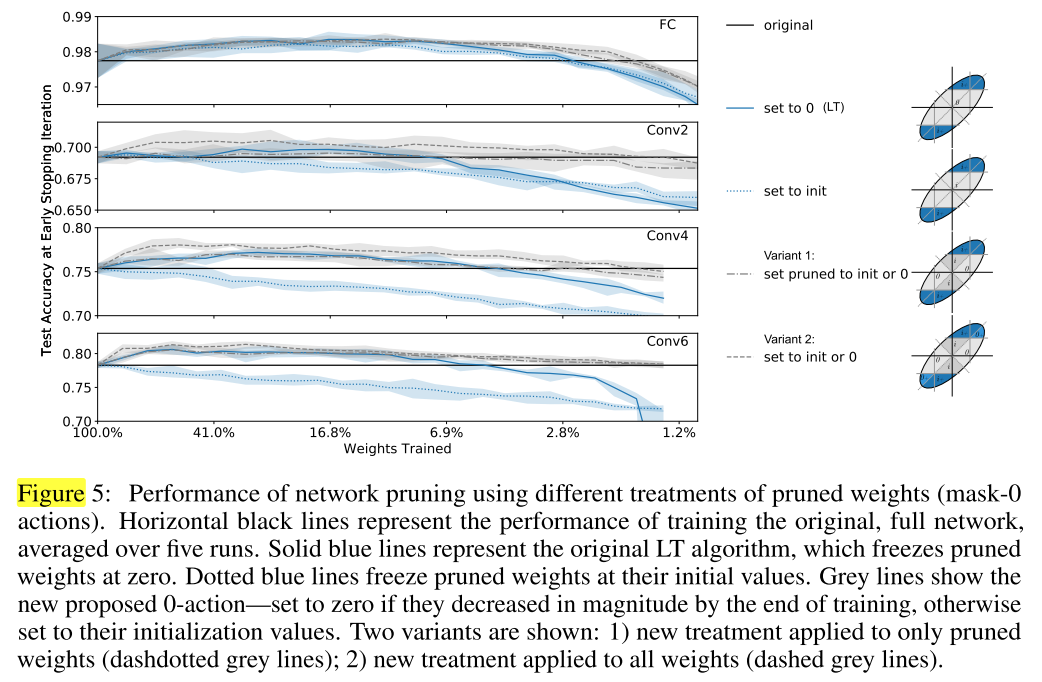
分析:
- 对剪掉的权重置零比置为原始网络的初始值更好
问题:
为什么置零比置为初始值更好?
我们提出一个假说:在 基于幅值的剪枝准则下,权值较小的权重相当于迟早会被更新到0附近,将权值较小的权重置零,相当于加速/提前了这个过程。即对权重加mask的过程,可以看成一个训练的过程。
为了验证这个假说,我们测试了mask-0的其他变体:
- Variant 1:对于所有mask=0的权重,如果它在完整网络训练过程中向0移动(我的理解是 \(w_f < w_i\))则将它的其置为0(并冻结);如果训练过程中远离0则置为原始网络的初始值(并冻结),再对中奖网络进行fine-tune
- Variant 2:不再使用基于幅值的剪枝,而是在训练过程中,如果权重向0移动,则置零(并冻结)
分析:
- 在低剪枝率下,变体1和置零相当,在高剪枝率下变体1表现更好
- 变体2比变体1还要好,验证了我们的假说
Supermasks
根据上面的分析,mask的过程可以看成训练的过程,即mask会提前将权值移向最终要被更新到的值。
那么这个“训练”的能力有多强?为了验证这个想法,我们不对随机初始化的网络进行训练,只进行mask。
结果证明,一个好的mask,可以在随机初始化的网络上获得一个比随机要好得多的性能。我们称比随机性能好的mask为 Supermasks。
如何获得 Supermasks ?
根据上面的分析,我们知道了保持符号一致的重要性,给彩票假设中的 large_final 加上同号的约束:

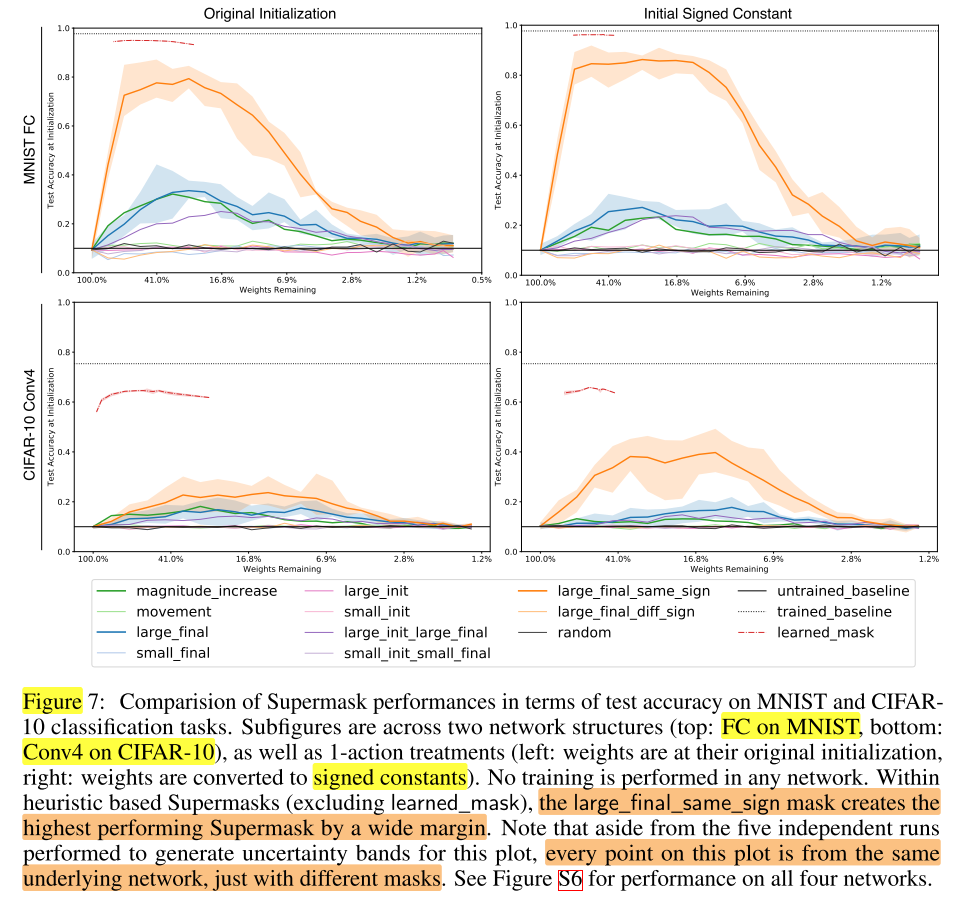
这样的 Supermasks 可以达到:86% on MNIST and 41% on CIFAR-10
Optimizing the Supermask
保持权重为随机初始化的状态,对mask做优化/训练:
\(w^{\prime}=w_{i} \odot g(m)\)
\(g(m) = Bern(S(m))\) , where Bern(p) is the bernoulli sampler with probability p, and S(m) is the sigmoid function.
经过训练后的mask可以达到:95.3% on MNIST,65.4% on CIFAR-10
Dynamic Weight Rescaling
在训练mask过程中的一个trick:
每轮剪枝后,对每一层剩余的初始化权重做一个放大:\(×\frac{该层的权重数}{保留的权重数}\)
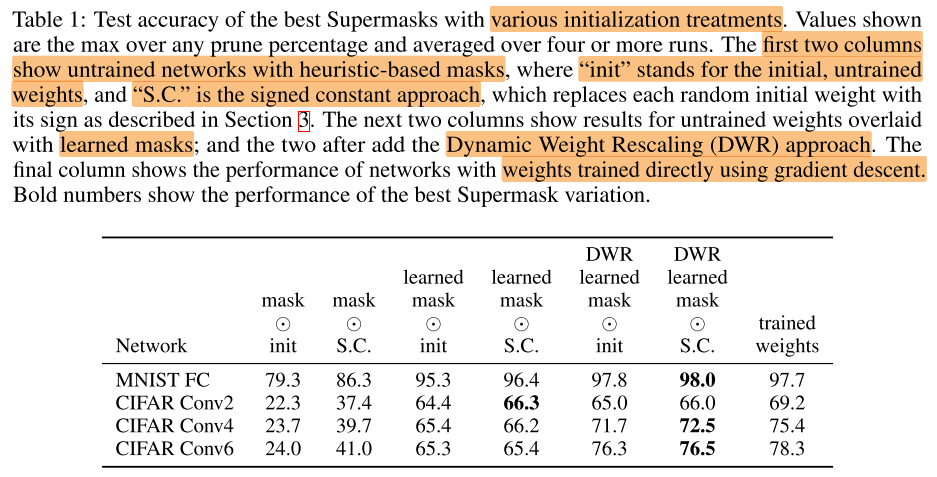
最后一列是原始网络的精度,可以看出,经过优化后的mask(权重还是随机初始化的状态)已经达到甚至超过完整网络的性能了。
Experiments
Conclusion
Summary
- 证明了直接mask一个随机初始化的网络,得到的非结构化稀疏网络,可以达到pre-train网络的精度
- mask函数 \(M(w_i, w_f)\) 比较简单,基本上是基于幅值的变形,能否进一步考虑其它因素,如权重分布,梯度,泰勒等
- 对彩票假设 work 的原因做了探究,有点像彩票假设的补充,消融实验

 浙公网安备 33010602011771号
浙公网安备 33010602011771号