【MSDNet】2018-ICLR-Multi-Scale Dense Networks for Resource Efficient Image Classification-论文阅读
MSDNet
2018-ICLR-Multi-Scale Dense Networks for Resource Efficient Image Classification
来源:ChenBong 博客园
- Institute:Cornell University,Fudan University,THU,Facebook
- Author:Gao Huang,Danlu Chen,Tianhong Li,etc.
- GitHub:
- https://github.com/kalviny/MSDNet-PyTorch 【100+】
- https://github.com/gaohuang/MSDNet 【400+】
- Citation:200+
Introduction
Motivation
样本难度分布不均:数据集中存在极少量hard样本,导致如果需要整体提高准确率需要使用超大的网络来进行分类,如下图中2张马的样本,左边是eazy的马,右边是hard的马;而超大的网络会为了分类极少数hard样本,而在大多数eazy样本数浪费非常多的算力。

样本难度分布不均带来2个问题:
- 用大网络,在大多数eazy样本上浪费计算量
- 用小网络,在少数的hard样本上得不到准确结果
能否让网络自动调整大小,在遇到eazy样本时,使用小网络;遇到hard样本时使用大网络?
即静态网络=>动态网络
Contribution
- 根据样本难度,一个单一的MSDNet网络可以自动调整大小,在遇到eazy样本时(或者计算资源有限时),使用小网络;遇到hard样本时(或者计算资源充足时)使用大网络
Method
网络设计
一个直观的想法是early-exit,即在网络的不同层添加多个分类器,但存在以下问题:
- cnn不同层提取的特征是不同的,前面的层提取细尺度特征,后面的层提取粗尺度特征
-
因此如果在前面的层添加分类器的话,接受的是细尺度特征,使得前面层的分类器难以准确分类
-
在前面的层添加分类器(训练过程中loss的影响)还会迫使网络在前面的层就开始学习粗尺度特征,反而破坏了后面的层的学习,会损坏后面层的分类器的结果
网络结构
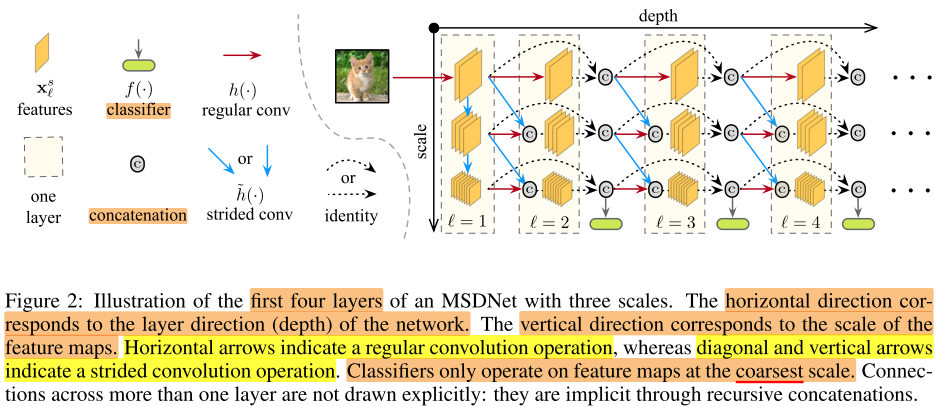
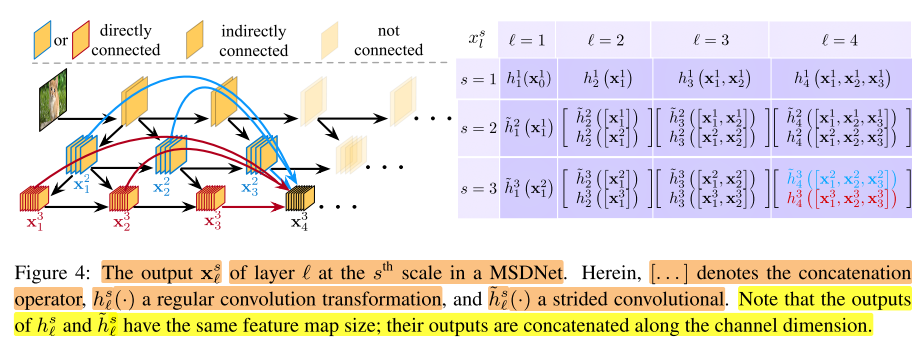
-
图示说明:右图中,红色箭头是普通卷积(feature map维度不变),蓝色箭头是stride 卷积(feature map维度降低),虚线是identity连接,绿色框是分类器
-
纵向是网络的一层,横向是网络不同的深度
-
横向上(深度维度),使用的都是常规卷积,即保持feature map维度不变,s小的时候,分辨率都比较高,即保留了图片的细尺度特征
-
纵向上(尺度维度),使用的都是stride 卷积,feature map维度不断减小,s大的时候,分辨率都比较低,即不断提取高级特征,以便于分类器分类,因此纵向的末尾都连接一个分类器,
-
当 l 较小(层数较低)时,前面层的分类器也可以接收到粗尺度特征,即解决了第1个问题
-
当 l 较大(层数较大)时,即使中间分类器破坏了前面层提取细尺度特征,由于稠密连接和s=1行的存在,依然存在细尺度=>粗尺度的路径,因此不会降低后面层分类器的分类效果,即解决了第2个问题
-
引入稠密连接,即使本应该学习细尺度特征的低层
MSDNet的两个模式
- anytime 模式,即每张图片的分类时间/计算开销是相同的,事先指定的,当时间耗尽/计算开销用完,网络停止,输出离停止的地方最近的分类器的结果
- batch budget 模式,一个batch 的图片的总时间/计算开销 是指定的,我们希望时间耗尽/计算开销用完时,整个batch 的平均分类准确率最高;这样就要求网络对eazy样本施加较少的计算量(在前面层退出),对hard样本施加更多的计算量(在后面层退出),可以通过设置置信度阈值,即某张图片的置信度达到阈值 \(θ_k\) (如0.8)时,就提前退出(early-exit)。
(阈值 \(θ_k\) 可以通过总开销B,和batch大小N,计算出来,详见原文)
网络优化
我们可以感觉到 MSDNet 与传统的CNN相比还是有一些冗余的,比如
- 传统的CNN是逐层抽象的,细尺度的提取只存在与低层,而MSDNet中s小的层(图2,4中上面的行)都是在提取细尺度,能否减少细尺度的提取层,只用1,2个层提取细尺度,然后重复利用这些层的输出?
- 有一部分细尺度提取层是冗余的,其输出没有被当成其他层的输入(图2,4中右上角)
我们采取一些,不断复用细尺度的提取层:
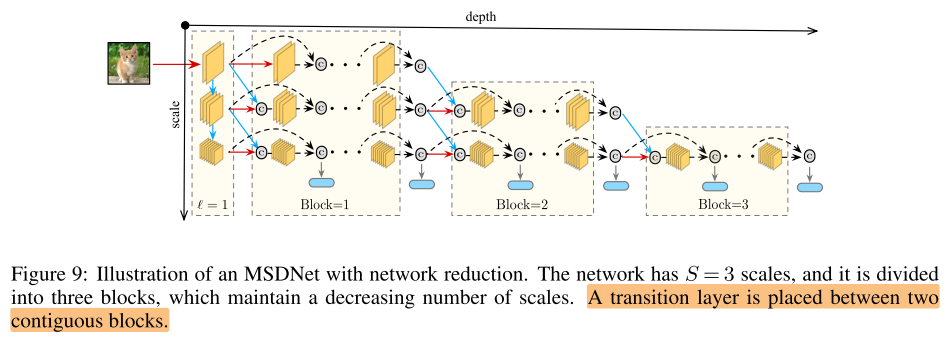
感觉上有点像砍掉网络的右上角部分,减少冗余
以下的实验用的还是原始的MSDNet。
Experiments
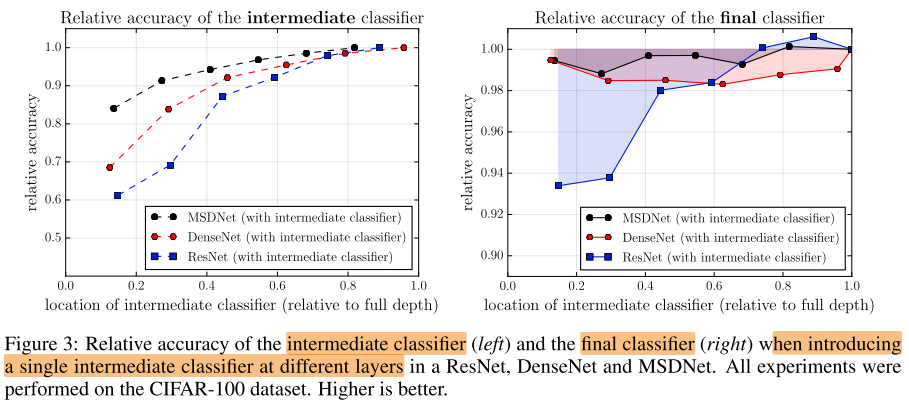
在不同网络中间层等距地加入分类器,对 中间分类器的影响 和 对最终分类器的影响
左图,中间层插入分类器,对中间分类器的影响:
- 横坐标,中间分类器插入的位置
- 纵坐标,中间分类器 相对(未修改的原始网络)最终分类器的精度
- 从左图可以看出,插入的中间分类器的位置越靠后,该中间分类器的精度越高,即后面的层的特征(粗尺度特征)更适合做分类
右图,中间层插入分类器,对最终分类器的影响:
- 横坐标同上
- 纵坐标,最终分类器 相对(未修改的原始网络)最终分类器的精度
- 从右图可以看出,对于ResNet来说,插入的中间分类器越靠前,对最终分类器的精度损害越大;对于DenseNet来说,中间插入分类器会导致最终分类器精度下降
原因,在中间层引入分类器,会导致低层网络被迫学习用于分类的粗尺度(高级)的特征,由于DenseNet 和 MSDNet 引入的稠密连接,低层没有学到的细尺度特征,会在后面层继续学习,可以缓解低层特征被破坏的影响。
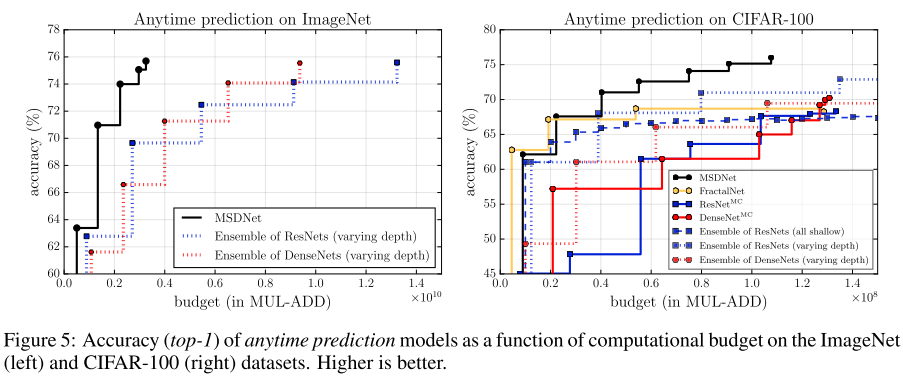
图5说明:
- 左图:anytime 模式
- 横坐标为anytime模式中的每张图片的计算开销限制,即当给定的计算开销用完时,输出分类结果;纵坐标为分类精度,图中的数据点表示不同开销下的网络精度
- Ensemble of ResNet/DenseNet (varying depth),指的是集成多个深度的ResNet/DenseNet,如ResNet-18/34/56/110...,先将图片输入到层数少的网络,如果置信度高于阈值则退出,否则将图片输入到更大一点的网络...(Ensemble有个缺点是会重复计算低尺度特征,浪费计算开销)
- 可以看出,在不同的单张开销下,MSDNet的精度都远胜于 多个网络的集成
- && 疑问,多个网络集成会浪费很多计算开销,和集成网络做比较似乎不太公平?
- 右图:batch budget 模式
- 横坐标为每张图片的平均开销(平均开销 = 总batch开销限制 / batch size,batch size相同时,平均开销相同等价于总 batch 开销相同);纵坐标为分类精度,图中数据点表示不同平均开销下,网络的精度
- Ensemble of ResNet/DenseNet (all shallow),集成多个浅的ResNet/DenseNet,最终的分类取多个网络的平均
- \(ResNet^{MC}/DenseNet^{MC}\) ,指的是在一个ResNet/DenseNet 的中间层加入多个分类器(multiple classifiers)
- 可以看出,在不同的总 batch 开销下,MSDNet表现都较好
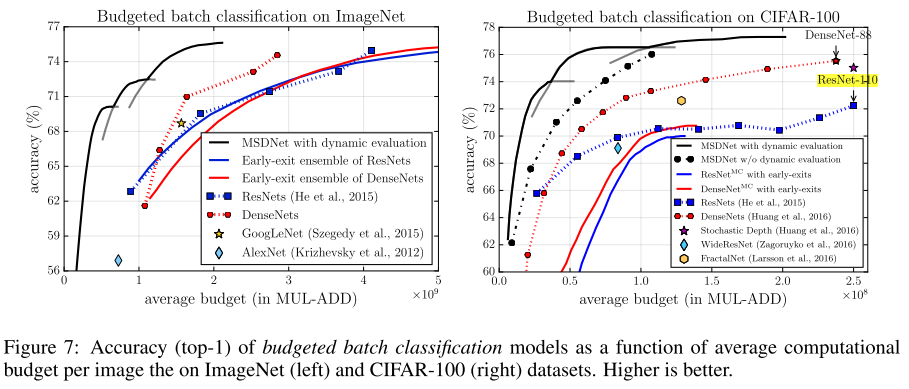
图7说明:
-
左图:batch budget模式在ImageNet数据集上的表现
- 左边三条黑色实线表示三种不同深度的MSDNet
- (&& 图中可以看出,足够深的MSDNet在低开销限制下的精度没有浅的MSDNet高,是否说明无法训练一个足够深的网络,满足所有计算要求?)
- 蓝色/红色实线:Early-exit ensemble of ResNet/DenseNet应该就是图5中的 Ensemble of ResNet/DenseNet (varing depth)
- 蓝色/红色虚线:不同规模的ResNets/DenseNet(因此是离散的点)
-
右图:batch budget模式在CIFAR-100数据集上的表现

图6说明:
- 上:eazy样本
- 下:hard样本
Conclusion
两个设计原则
- 在网络全程生成和维护粗尺度特征 => 可以在浅层引入中间分类器
- 密集连接 => 多个分类器不会互相干扰(中间分类器不会影响后面的分类器)
一个网络开销可变,并且在不同开销下的表现都超越传统网络
Summary
Reference
https://www.shuzhiduo.com/A/qVdeWkb8JP/#%E7%BD%91%E7%BB%9C%E4%BC%98%E5%8C%96

 浙公网安备 33010602011771号
浙公网安备 33010602011771号