【ProxylessNAS】2019-ICLR-ProxylessNAS Direct Neural Architecture Search on Target Task and Hardware-论文阅读
ProxylessNAS
2019-ICLR-ProxylessNAS Direct Neural Architecture Search on Target Task and Hardware
来源:ChenBong 博客园
- Institute:MIT
- Author:Han Cai,Ligeng Zhu,Song Han
- GitHub:https://github.com/mit-han-lab/proxylessnas【1.1k stars】
- Citation:382
Introduction
ProxylessNAS 可以直接在大数据集(ImageNet)上搜索,搜索代价(200个epochs)跟普通训练(120个epochs)是同一 level 的。
ProxylessNAS 的在 CIFAR-10 和 ImageNet 上都是 SOTA (under latency constraints <= 80s)。
在DARTS框架上改的。
Motivation
由于 NAS 的计算代价过高,之前工作都需要依赖 proxy 来做。
PS: 常见的 proxy
- 先在小数据集(CIFAR)上搜索,然后迁移到大数据集(imagenet)。
- 先搜索一个比较浅的网络,然后重复堆叠同样的结构单元来得到更深的网络。
- 只训练少量 epoch (e.g. 5 epoch),然后就 validate。
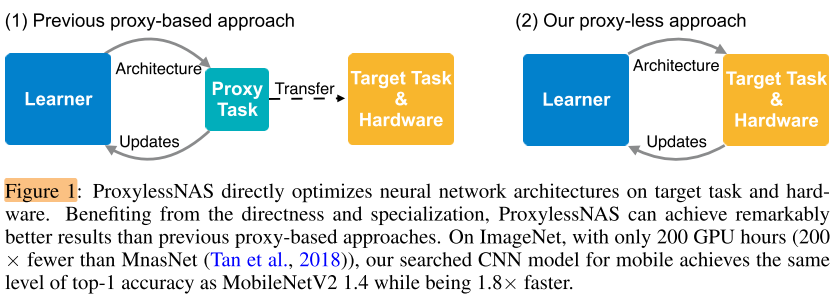
-
无需 proxy 的 NAS
-
针对特定硬件:一个有意思的点是,大家往往为 general CNN 定制硬件(GPU,TPU),却没有人反过来为硬件定制 specific CNN。
Contribution
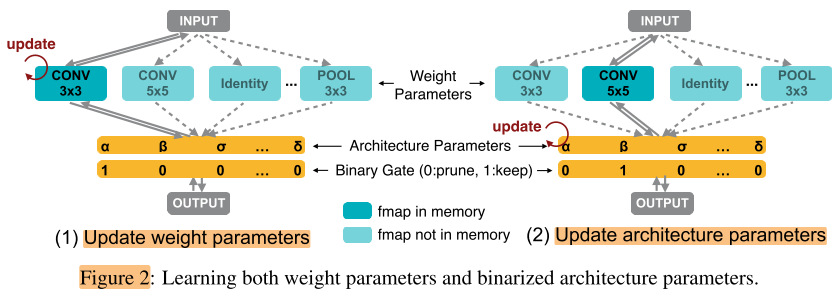
- 只要训练一个网络,GPU Hours 方面的消耗就不再是问题
- 在搜索时仅有一条路径处于激活状态。这样一来 GPU 显存就从 O(N) 降到了 O(1)
- 直接搜索整个Net,并不需要堆叠cell来实现
- search for hardware。主要考虑的硬件指标是延迟 latency。第一个探讨为不同平台自动定制 CNN 结构的研究。
Method
Search Space
Denote a neural network as \(N(e, ... , e_n)\) where \(e_i\) represents a certain edge in the directed acyclic graph (DAG).
网络N表示为DAG(有向无环图): \(N(e_1,\ ... , e_n)\) ,其中 \(e_i\) 表示DAG的某条边,节点代表feature map,边 \(e_i\) 代表计算操作,每条边都有一组输入的feature map和一组输出的feature map,因此一条边可以看作一个类似block的结构,只不过这个block只有一个输入和一个输出(其他文章中典型的block 一般有2个输入,1个输出)。
本文中DAG的 edge:
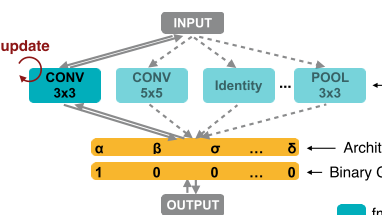
其他文章中的blcok:
Let \(O = \{o_i\}\) be the set of N candidate primitive operations (e.g. convolution, pooling, identity, zero, etc).
候选操作的集合 \(O = \{o_i\}\) ,集合中有N个元素
To construct the over-parameterized network that includes any architecture in the search space, instead of setting each edge to be a definite primitive operation, we set each edge to be a mixed operation that has N parallel paths (Figure 2), denoted as \(m_O\).
DAG中的每条边代表一个混合操作,记为 \(m_O\) ,每条边可以看做一个block,其中有多条路径
As such, the over-parameterized network can be expressed as \(N(e_1 = m^1_ O, ... , e_n = m^n_O)\) .
例如一个过度参数化的网络可以表示为 \(N(e_1 = m^1_ O,\ ... , e_n = m^n_O)\)
Given input x, the output of a mixed operation \(m_O\) is defined based on the outputs of its N paths.
在一个edge(blcok)内部,给定 input x,输出 \(m_O\) 是由N条路径的输出来定义的。
In One-Shot, \(m_O(x)\) is the sum of \(\{o_i(x)\}\), while in DARTS, \(m_O(x)\) is weighted sum of \(\{o_i(x)\}\) where the weights are calculated by applying softmax to N real-valued architecture parameters \(\{α_i\}\) :
\(m_{\mathcal{O}}^{\text {One-Shot }}(x)=\sum_{i=1}^{N} o_{i}(x)\)
\(m_{\mathcal{O}}^{\mathrm{DARTS}}(x)=\sum_{i=1}^{N} p_{i} o_{i}(x)=\sum_{i=1}^{N} \frac{\exp \left(\alpha_{i}\right)}{\sum_{j} \exp \left(\alpha_{j}\right)} o_{i}(x)\)
在one-shot中,是将多条路径的输出直接求和;在DARTS中是将多条路径的输出按“结构参数的权重”求和。
As shown in Eq. (1), the output feature maps of all N paths are calculated and stored in the memory, while training a compact model only involves one path.
Therefore, One-Shot and DARTS roughly need N times GPU memory and GPU hours compared to training a compact model.
因此要同时存储N(op个数)条路径的结果,最终只会保留一条路径,因此需要(训练一个compact model)N倍的显存和N倍的计算时间。
Specifically, rather than repeating the same mobile inverted bottleneck convolution (MBConv), we allow a set of MBConv layers with various kernel sizes {3, 5, 7} and expansion ratios {3, 6}.
实际上的op set是{MB3/6 Conv3×3 / 5×5 / 7×7},共2*3=6种op。
MB3/6 指的是MobileNet V2中block的expansion ratios分别为3和6
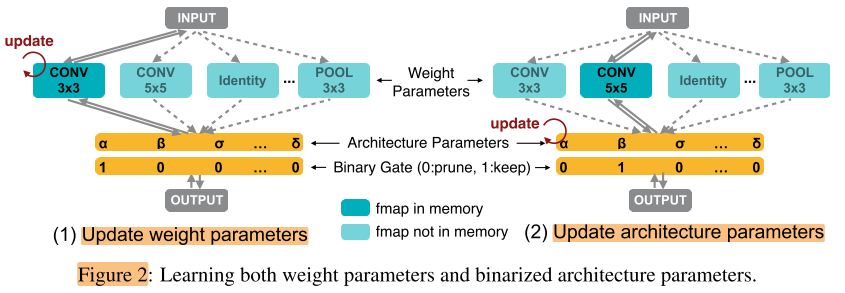
如何直接搜索整个Net?
论文引入了Gate的概念,门在op的后面,控制路线的通断,而门的选取概率和它的结构参数有关
\(g=\operatorname{binarize}\left(p_{1}, \cdots, p_{N}\right)=\left\{\begin{array}{cl}{[1,0, \cdots, 0]} & \text { with probability } p_{1} \\ \cdots & \\ {[0,0, \cdots, 1]} & \text { with probability } p_{N}\end{array}\right.\) ,其中 \(p_{i}=\frac{\exp \left(\alpha_{i}\right)}{\sum_{k} \exp \left(\alpha_{k}\right)}\)
每条路径对应一个结构参数 \(α_i ∈ R\) (图中写作α,β...),N条路径的结构参数作softmax,得到N个概率 \(p_i ∈ R\) ,按照这组概率进行抽样,得到一组gate向量g=[1, 0, ..., 0]
DARTS是将多个路径的输出按“结构参数”的权重求和。
而ProxylessNAS是将“结构参数”转化为概率分布,按照概率分布抽一条路径计算路径输出,作为该block的输出。
因此ProxylessNAS 一次只需要计算一条路径,而DARTS/one-shot 一次需要计算N条路径,因此所需要的显存/计算量为原来的1/N。
梯度回传?
由于这种采样机制不会显示的包含他的结构参数(而DARTs是包含的,所以他可以直接用求导进行梯度回传),所以他在这里门的选取概率才会与结构参数相关联,这样在求导的时候才可以隐式的回传回去。
在这里ProxylessNAS用之前的BinaryConnect的梯度回传处理方法。其实在这里,你可以认为他们把binaryConnect之前在CNN内部的操作,放大到对Network PATH上,实际上一些操作也是从CNN的内部结构中借鉴过来的,比如,DropPATH 对应 DropOut。
&&最后一步求导过程?
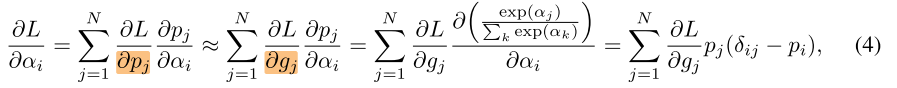
其中 \(δ_{ij}=1\) if \(i=j\) and \(δ_{ij}=0\) if \(i≠j\).
这样看起来就可以进行求导了,但是每次对一个操作进行求导仍然需要对剩余其他的操作求偏导。计算量还是不小,作者提出了一个想法来解决这个问题,选择一个网络一定是因为它比其他的网络更优秀。作者只采样两条路径,然后对两条路径进行梯度回传。
&& 增强/衰减?
这样,在每个更新步骤中,一个采样路径被增强(路径权重增加),另一个采样路径被衰减(路径权重减小),而所有其他路径保持不变。
在某种意义上,网络会偏向于采样结构参数大的网路,意味着这些网络也更容易得到训练。类比就是,穷人越来越穷,富人越来越富,然后最终的网络选取最富的那一条。如果只选取一条路径,这样没办法在比较中差异化网络,选取两条应该是在计算消耗以及精确度之间的一个Trade-off.
详细的训练过程。
step1: 初始化各项参数(网络参数指CNN的卷积参数,结构参数指各个op的选择系数)
step2: 固定结构参数,与此同时对路径随机采样(每个edge采样2条路径),然后训练网络参数。
step3: 固定网络参数,按照上述的方法来采样两条路径,对结构参数进行更新。
循环2,3直到网络收敛或迭代固定次数,出现差异化大的网络,在每一步选取结构参数最大的op
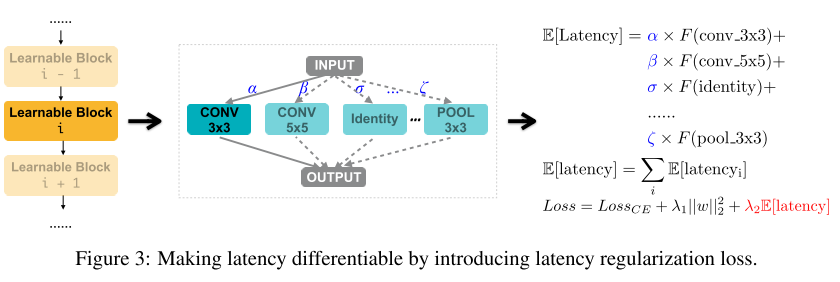
加入硬件延时约束-可微的方法
图中F(·)代表latency预测函数, α,β,σ等为结构参数

加入硬件延时约束-强化学习方法
&&

Experiments
cifar10
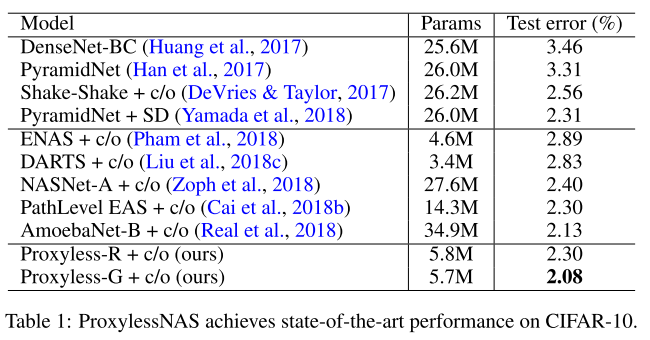
在 CIFAR-10,ProxylessNAS 达到了新的 the state-of-the-art 2.08%。而且值得一提的是,对比之前的最好模型 AmoebaNet,我们模型仅用了 1/6 的参数就达到了更好的性能(5.7M v.s. 34.9M)。
ImageNet
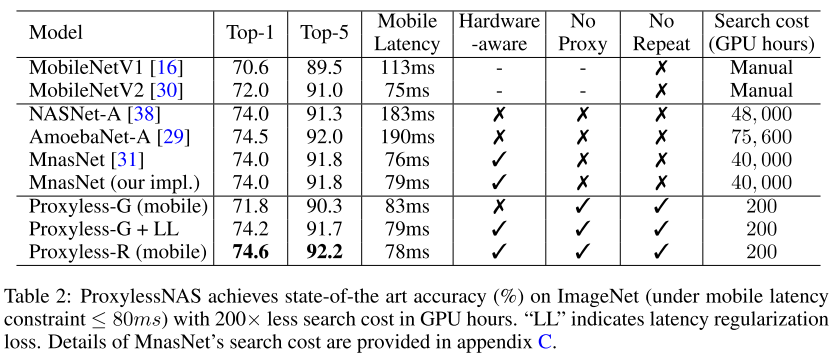
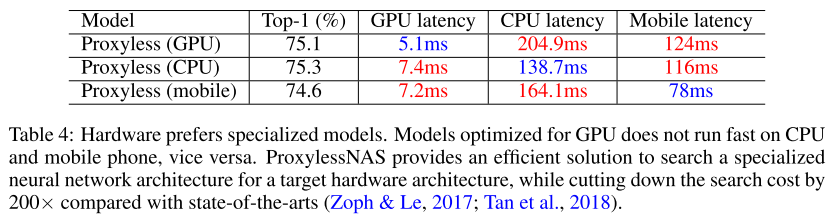
在 ImageNet 上,ProxylessNAS 在维持同等的 latency 的前提下,TOP-1准确率提升了 2.6%。此外,在各个 width setting下,我们的模型始终大幅优于 MobilenetV2:为了达到 74.6% 的精度,MobilenetV2 需要 143ms的 inference time,而我们模型仅需要 78ms(1.83x 倍)。与 MnasNet 相比,我们所消耗的搜索资源要得多 (1/200),但模型却在提升 0.6% Top-1 的略微提升了速度。在 target GPU 时,ProxylessNAS 更是到了 75.1% 的 accuracy,且运行速度比 Mobilenet 快 20%
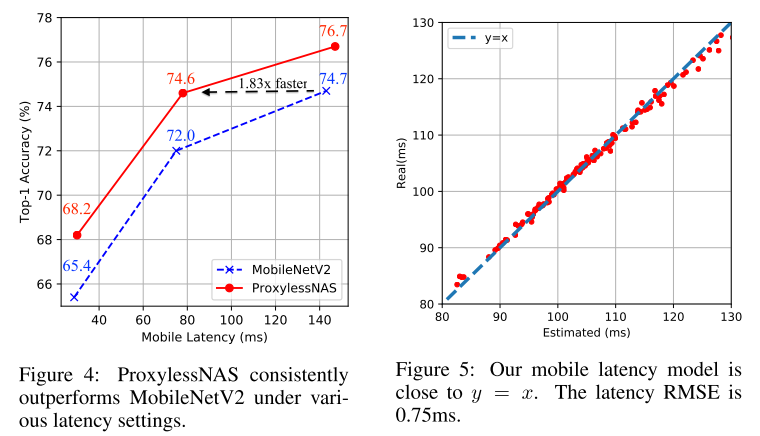
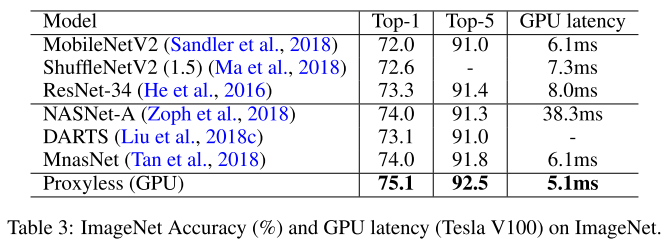
Hardware
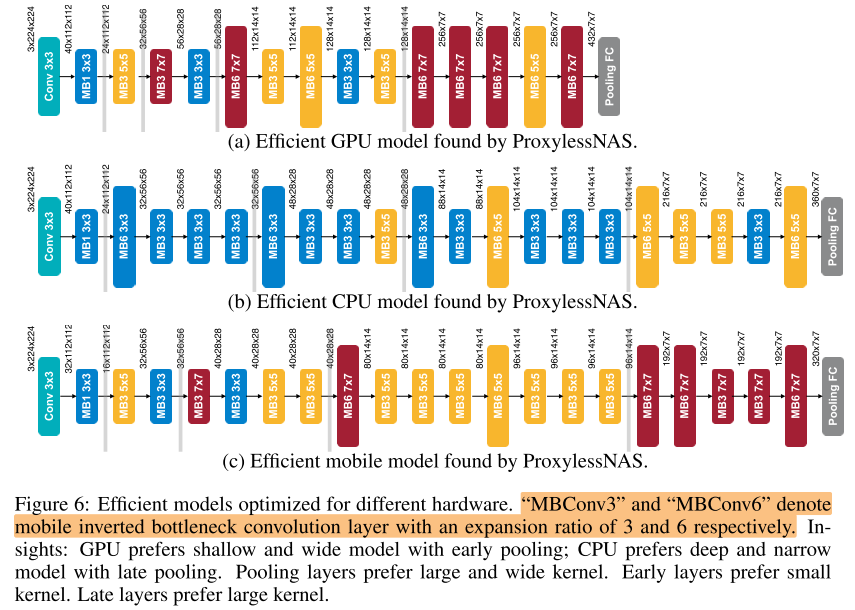
下图展示了三个硬件平台上搜索到的 CNN 结构:GPU / CPU / Mobile。
总的来说,GPU 模型短而宽,CPU / Mobile 长而瘦,feature map downsample 时大家都喜欢 larger kernel / more channels 更多的操作。希望这个能给之后设计高效 CNN 带来一些灵感。
GPU延时和深度关系较强,和宽度关系较弱,因此短而宽。
同时我们观察到一些有趣现象:针对GPU优化的模型在CPU和移动端上运行速度并不快,反之亦然。之前将一种 CNN deploy 到多个平台上的做法并不是最优的。
Conclusion
Summary
- 搜索空间的op很少,只限制在MobileNet V2的6种block里进行搜索,搜索空间越小,搜索越快
- latency 预测函数F(·),应该是用查表的方法
- Dropout => Drop Path,权重二值化=>路径二值化
Reference
ProxylessNAS论文笔记: https://licharyuan.github.io/2019/04/17/ProxylessNAS论文笔记/
作者知乎回答:https://www.zhihu.com/question/296404213/answer/547163236
ProxylessNAS:http://www.fenggangliu.top/2020/04/10/ProxylessNAS/
【论文阅读】—— MobileNetV2, Inverted Residuals and Linear Bottlenecks:http://vincentho.name/2018/12/11/【论文阅读】——-MobileNetV2-Inverted-Residuals-and-Linear-Bottlenecks/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号