【RANet】2020-CVPR-Resolution Adaptive Networks for Efficient Inference-论文阅读
RANet
2020-CVPR-Resolution Adaptive Networks for Efficient Inference
来源:ChenBong 博客园
- Le Yang、Yizeng Han、Xi Chen,Gao Huang*
- Tsinghua University、HIT、SenseTime
- GitHub:https://github.com/yangle15/RANet-pytorch
Introduction
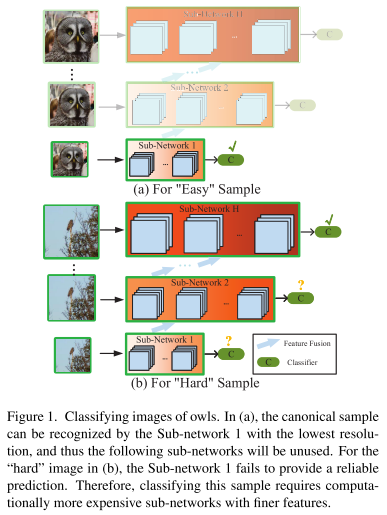
In RANet, the input images are first routed to a lightweight sub-network that efficiently extracts low-resolution representations, and those samples with high prediction confidence will exit early from the network without being further processed.
Meanwhile, high-resolution paths in the network maintain the capability to recognize the “hard” samples.
在RANet中,输入图片会经过一个Initial Network(图1中纵向),提取不同分辨率的图片;
RANet由输入不同分辨率的多个子网组成,分为低级子网(接收低分辨率输入),高级子网(接收高分辨率输入)等;
先使用低分辨率图片通过低级子网,如果分类结果置信度达到给定阈值e,则提前退出;
否则使用更高分辨率的图片输入更高一级的子网;
低级子网每一层的输出特征会融合到更高一级子网的对应层的输入中,确保低级子网的计算信息不会浪费。
Motivation
Existing works mainly exploit architecture redundancy in network depth or width.
现有工作主要关注网络结构在深度和宽度上的冗余
图片输入分辨率一般都设置为统一的(如ImageNet的224*224),分辨率上也存在冗余的可能性,而且降低输入分辨率也可以降低网络计算开销
It has been shown that the intrinsic classification difficulty for different samples varies drastically: some of them can be correctly classified by smaller models with fewer layers or channels, while some may need larger networks [24, 37, 12, 36].
不同样本的分类难度不同,有些样本只需要小网络就可以分类,而有些样本需要大网络才能分类
coarse to fine processing
符合先粗分类再细分类的直觉
From a signal frequency viewpoint [4], “easy” samples could be correctly classified with low-frequency information contained in low-resolution features. High-frequency information is only utilized as complementary for recognizing “hard” samples when we fail to precisely predict the samples with lowresolution features.
从信号频率的角度来看,eazy 样本可以通过包含在低分辨率图像中的低频信息就可以正确分类,hard 样本则需要高分辨率图像中的高频信息
Contribution
The adaptation mechanism of RANet reduces computational budget by avoiding performing unnecessary convolutions on highresolution features when samples can be accurately predicted with low-resolution representations, leading to improved computational efficiency.
使用自适应机制,在低分辨率可以准确预测时,避免了对高分辨率特征的不必要的卷积,提高了计算效率
Method
We set up an adaptive inference model as a network with K classifiers, where these intermediate classifiers are attached at varying depths of the model.
整个RANet共有K个分类器,在不同深度的子网络的末端
A sample will exit the network at the first classifier whose output satisfies a certain criterion.
一个样本的分类过程将在第一个置信度达到阈值的分类器时退出
If the first sub-network makes an unreliable prediction of the sample, the small scale intermediate features will be fused into the next sub-network with a higher resolution.
如果第一个子网络没有给出可靠预测,则这个子网络的中间输出特征会被融合到下一级网络对应层的输入
This procedure is repeated until one sub-network yields a confident prediction, or the last sub-network is utilized.
重复这个过程直到某一级的子网络的分类器输出足够高的置信度
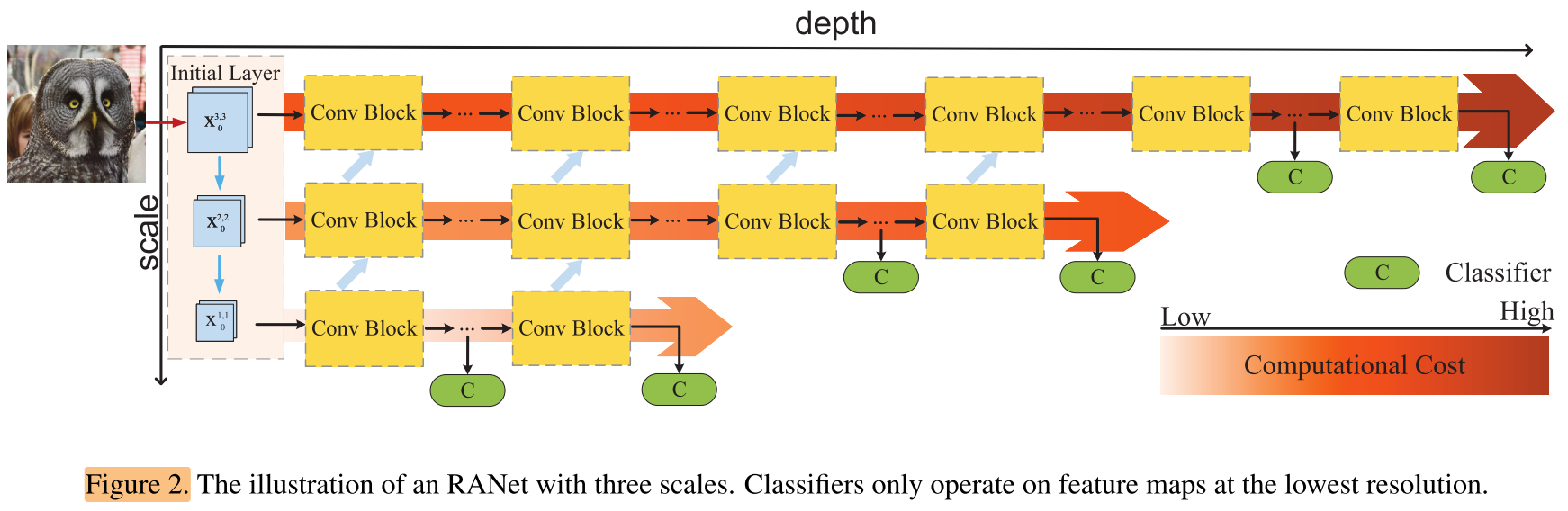
One could view its vertical layout as a miniature “H-layers” convolutional network (H is the number of base features in the network).
图2左侧纵向是一个H层的卷积网络,H是子网络的个数。
The first base features with the largest scale is derived from a Regular-Conv layer2, and the coarse features are obtained via a Strided-Conv layer3 from the former higher-resolution features.
纵向的卷积网络中不是downsample来获得低分辨率图片,而是通过正常的卷积或者stride 卷积来获得低分辨率的feature map
It is worth noting that the scales of these base features can be the same. For instance, one could have an RANet with 4 base features in 3 scales, where the scales of the last two base features are of the same resolution.
纵向卷积网络中各层的feature map大小可以是相同的,比如有4层,但只有3种大小的feature map,如最后2层的feature map大小相同。
Sub-network 1 with input \(x_0^{1,1}\) processes the lowest-resolution features.
\(x_0^{1,1}\) 表示最低级子网络的输入
\(x^{s,h}\) 表示一个子网络对应的一组feature map,该子网络的feature map规模(从小到大)排第s,是第h个子网络,如:
\(x^{3,4}\)
\(x^{2,3}\)
\(x^{1,2}\)
\(x^{1,1}\)
Moreover, the i-th layer’s output \(x_i^{1,1}\) , i=1, 2, ...l in each Dense Block is also propagated to Sub-network 2 to reuse the early features.
\(x_i^{1,1}\) 表示第一个子网络的第i层的输出feature map
Sub-network h (h>1) with scale s processes the base features \(x^{s,h}\) ,and fuses the features from Sub-network (h−1).
第h-1个子网络的第i层的输出feature map会被融合到第h个子网络第i层的输入feature map中
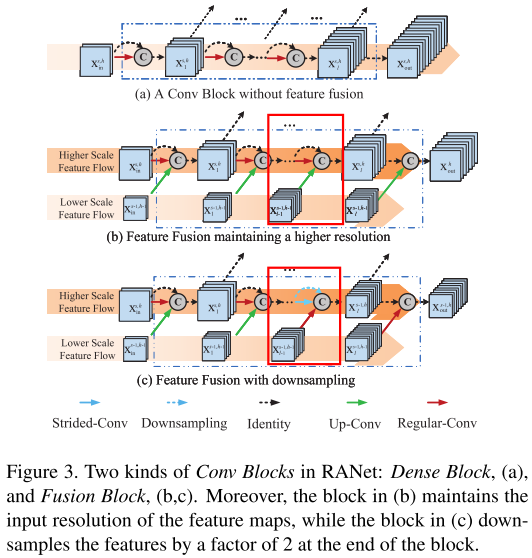
We call Conv Blocks with feature fusion as Fusion Blocks (shown in Figure 3 (b, c)).
Suppose that Sub-network (h−1) has \(b_{h−1}\) blocks, then the first \(b_{h−1}\) blocks in Sub-network h will all be Fusion Blocks.
我们将融合上级网络feature map的Conv Blocks 称为 Fusion Blocks(融合block)(图3 b,c)
设第h-1个子网络有 \(b_{h-1}\) 个blcoks,那么第h个子网络的前 \(b_{h-1}\) 个blocks都是 Fusion Blocks
We design two different ways of feature fusion.
我们设计了2种特征融合方法。
因为融合的2组特征大小可能不同,可以将将小的feature map进行up-conv,或者将大的feature map进行down sample / stride conv,如图3 b,c
Experiments
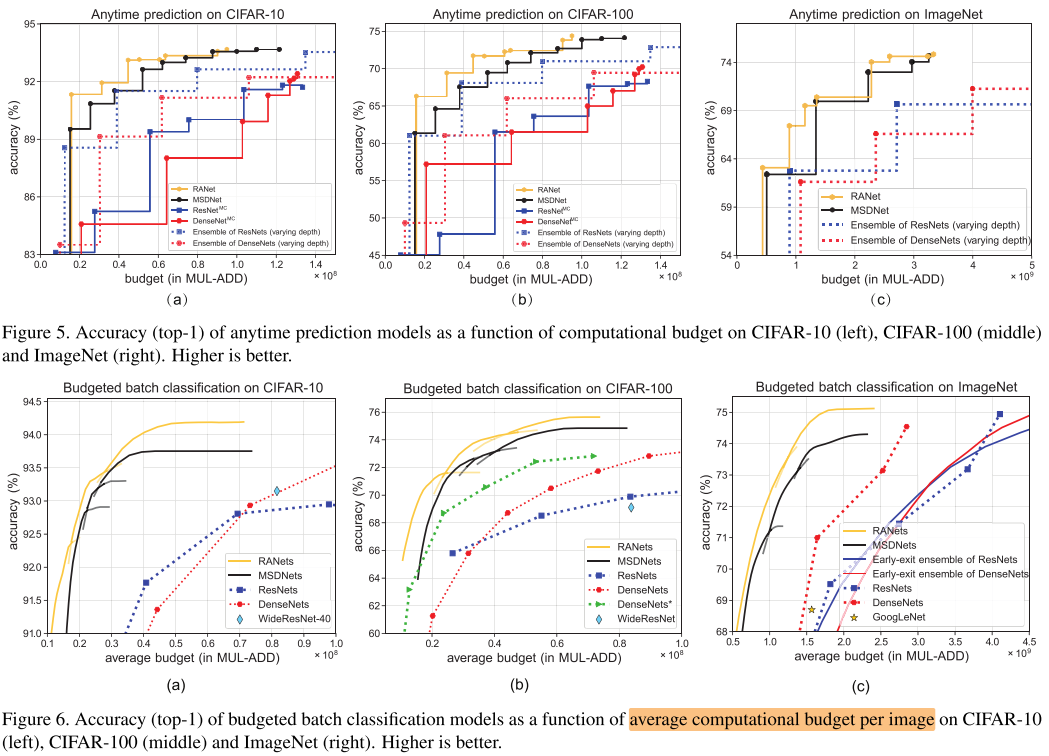
Anytime Classification / Anytime Prediction
对于一张图片的预测,随时停下来也应该有个输出的分类结果,不过运行时间越久得到的精度应该要越高。为了实现这个目的,就是在网络中加入多个输出层(classifier),随时停止的时候,输出最新的输出层(classifier)的结果。
而不同深度的网络有不同的计算开销,要衡量不同时间停止时网络的性能,可以转化为花费了不同的计算开销时停止时的性能。(对于同一个设备,已花费的时间和已花费的计算开销近似正比)
对于每一张输入图像x都有一个计算资源限制条件(computational budget)B>0,相当于每次给模型输入一张图像,然后根据计算资源限制来给出预测结果
Budget Batch Classification
对于一个batch的图片,在给定的总计算开销下,我们希望对这批图片的识别结果越高越好。这个batch的图片有的简单有的困难,我们希望简单的图片用前面的分类器,困难的图片再用后面的分类器。因此设定一个置信度阈值,如0.8,即当某个分类器的结果中某个类别置信度大于0.8即退出。阈值设置越高,最后的准确率应该就越高。
而在budgeted batch classification中是对每一个batch的输入图像都有一个computational budget B>0,假设这个batch里面包含M张图像,那么可能简单图像的计算开销要小于B/M,而复杂图像的计算开销要大于B/M。

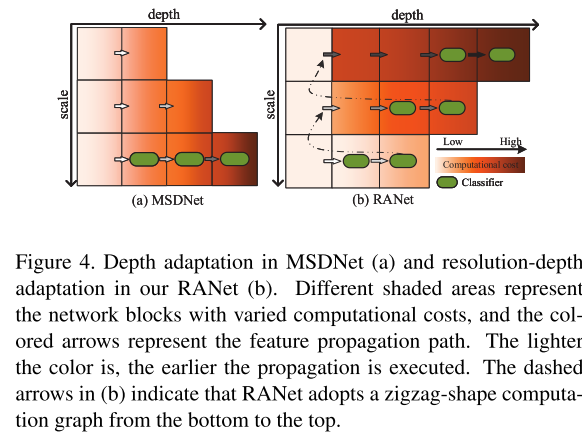
我们提出的RANet可以同时实现 MSDNet[12]中采用的深度适配和分辨率适配的思想。图4说明了MSDNet(左)和我们的RANet(右)的主要区别。在MSDNet中,分类器位于最低的分辨率尺度,一旦一个中间预测器不能产生有把握的预测,下面所有尺度的层将被执行。然而,在我们的RANet中,首先依次激活具有最小尺度输入的Dense Blocks,并在单一尺度内进行深度适应。如果上一个子网络不能做出有把握的预测,输入样本将被传播到下一个子网络,并重复深度适应过程,直到预测置信度达到标准,或者达到整个网络的最后一个分类器。这样的推理方案很自然地将分辨率和深度适应结合起来,实现了对MSDNet的显著改进。
Conclusion
- 自适应推理:设计了一种对不同分辨率图片使用计算量不同的子网进行推理的自适应网络RANet
- 分辨率/难度自适应:先对低分辨率图片使用轻量网络,置信度达到阈值直接退出,轻量网络无法分类的图片才会继续使用更大的网络进行预测,间接实现了对难度的自适应
- 低级特征融合/复用:复用了低级轻量网络的中间特征,避免浪费之前的计算
Summary
- 关于自适应推理,文中引用了很多相关paper,回头有时间认真看一下
Reference
【RANet】2020-CVPR-Resolution Adaptive Networks for Efficient Inference-论文阅读 https://www.cnblogs.com/chenbong/p/13306083.html
MSDNet(Multi-Scale Dense Convolutional Networks)算法笔记 https://blog.csdn.net/u014380165/article/details/78006893
MSDNet 介绍— Multi-Scale Dense Networks for Resource Efficient Image Classification https://medium.com/@xiaosean5408/msdnet-介紹-multi-scale-dense-networks-for-resource-efficient-image-classification-dc20f61f53d7

 浙公网安备 33010602011771号
浙公网安备 33010602011771号