【Transferable NAS with RL】2018-CVPR-Learning Transferable Architectures for Scalable Image Recognition-论文阅读
Transferable NAS with RL
2018-CVPR-Learning Transferable Architectures for Scalable Image Recognition
来源:ChenBong 博客园
- Author:Barret Zoph(Google Brain)、Quoc V. Le(Google Brain)etc.
- GitHub:
- https://github.com/aussetg/nasnet.pytorch
- https://github.com/MarSaKi/nasnet
- Citation:1475
Introduction
In this paper, we study a method to learn the model architectures directly on the dataset of interest.
本文介绍一种在目标数据集上搜索网络结构的方法。
We also introduce a new regularization technique called ScheduledDropPath that significantly improves generalization in the NASNet models.
介绍了一种新的正则化技术:ScheduledDropPath,有效地提高NASNet model的性能
On CIFAR-10 itself, a NASNet found by our method achieves 2.4% error rate, which is state-of-the-art.
在CIFAR-10上搜索的NASNet模型,达到了2.4% err(97.6% acc)
Although the cell is not searched for directly on ImageNet, a NASNet constructed from the best cell achieves, among the published works, state-of-the-art accuracy of 82.7% top-1 and 96.2% top-5 on ImageNet.
尽管NASNet没有直接在ImageNet上搜索,但依然达到了top1 acc 82.7%(超过所有已发表工作,在未发表的工作中持平), top5 acc 96.2%
Our model is 1.2% better in top-1 accuracy than the best human-invented architectures while having 9 billion fewer FLOPS – a reduction of 28% in computational demand from the previous state-of-the-art model.
我们的模型在top1指标上比手工设计的最好模型高了1.2%,FLOPs少了9 billion
For instance, a small version of NASNet also achieves 74% top-1 accuracy, which is 3.1% better than equivalently-sized, state-of-the-art models for mobile platforms.
此外,小版本的NASNet也达到了74%的top1 acc,比同样大小的网络提高了3.1%,达到了小网络中的SOTA
Finally, the image features learned from image classification are generically useful and can be transferred to other computer vision problems.
最后,从图像分类中学到的特征是有用的,可以迁移到其他视觉任务中。
On the task ofobject detection, the learned features by NASNet used with the Faster-RCNN framework surpass state-of-the-art by 4.0% achieving 43.1% mAP on the COCO dataset.
在目标检测任务中,NASNet使用Faster-RCNN超过sota 4.0%,达到43.1%的mAP
Motivation
As this approach is expensive when the dataset is large, we propose to search for an architectural building block on a small dataset and then transfer the block to a larger dataset.
当目标数据集太大时,直接搜索整个网络的方法计算代价过高,我们提出先在小的数据集上搜索网络构建块,再迁移到大数据集上。
One inspiration for the NASNet search space is the realization that architecture engineering with CNNs often identifies repeated motifs consisting of combinations of convolutional filter banks,
NASNet search space 的一个灵感是发现CNN的结构经常使用重复的模块
Contribution
Transferable 可迁移,小数据集到大数据集迁移,从分类任务迁移到其他视觉任务
Scalable 可扩展,容易从大模型扩展到小模型
The main contribution of this work is the design of a novel search space, such that the best architecture found on the CIFAR-10 dataset would scale to larger, higher resolution image datasets across a range of computational settings.
主要贡献是设计了一个新的搜索空间(NASNet search space),可以在cifar10上搜索最佳结构,并推广到更大,更高分辨率的数据集。
Our approach is inspired by the recently proposed Neural Architecture Search (NAS) framework [71], which uses a reinforcement learning search method to optimize architecture configurations.
搜索最佳的网络结构,简化为搜索最佳的结构块(cell)
Searching for the best cell structure has two main benefits: it is much faster than searching for an entire network architecture and the cell itself is more likely to generalize to other problems.
搜索最佳结构块(cell)有2个好处:更快,泛化能力更强(容易被推广到其他问题)
Additionally, by simply varying the number of the convolutional cells and number of filters in the convolutional cells, we can create different versions of NASNets with different computational demands.
另外,通过简单地改变cell的数量和cell中卷积核的个数(缩放),可以构建不同计算开销版本的NASNet
Thanks to this property of the cells, we can generate a family of models that achieve accuracies superior to all human-invented models at equivalent or smaller computational budgets [60, 29].
由于cell的特性,我们可以生成一系列模型
Method
Search Method 搜索方法(强化学习/随机搜索)
Our approach is inspired by the recently proposed Neural Architecture Search (NAS) framework [71], which uses a reinforcement learning search method to optimize architecture configurations.
我们的方法的框架与[71]NAS with RL相同,都使用强化学习来搜索网络结构
The controller weights are updated with policy gradient (see Figure 1).
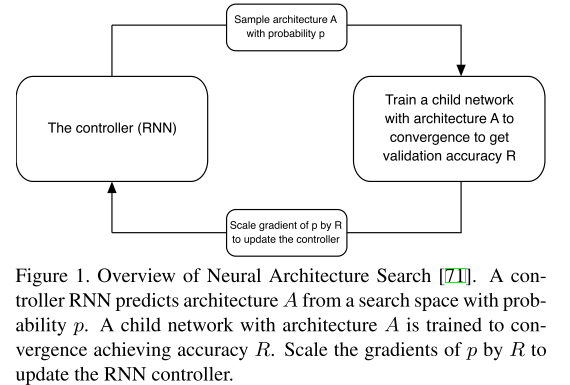
控制器RNN使用梯度策略更新
Network Architecture 网络结构
This cell can then be stacked in series to handle inputs of arbitrary spatial dimensions and filter depth.
这个cell可以被多次堆叠以处理任意分辨率的输入
In our approach, the overall architectures of the convolutional nets are manually predetermined.
我们的方法中,整个网络的总体架构(cell堆叠次数/层数)是事先手动确定的。
They are composed of convolutional cells repeated many times where each convolutional cell has the same architecture, but different weights.
整个网络是由多个卷积cell重复多次得到的,这些cell有相同的结构,但是权重不同
To easily build scalable architectures for images of any size, we need two types of convolutional cells to serve two main functions when taking in a feature map as input:
(1) convolutional cells that return a feature map of the same dimension, and
(2) convolutional cells that return a feature map where the feature map height and width is reduced by a factor of two.
We name the first type and second type of convolutional cells Normal Cell and Reduction Cell respectively.
为了处理不同输入大小的图片,我们需要两种cell
(1)Normal Cell(cell的输入输出长宽大小相同)
(2)Reduction Cell(cell的输入输出长宽减半)
The Reduction and Normal Cell could have the same architecture, but we empirically found it beneficial to learn two separate architectures.
Reduction Cell 和 Normal Cell 结构可以是一样的,但根据经验,学习不同的结构会更好。
All of our operations that we consider for building our convolutional cells have an option of striding.
cell中所有的operation的stride是可变的
Figure 2 shows our placement of Normal and Reduction Cells for CIFAR-10 and ImageNet.
图2是 cifar10 和 ImageNet 的Normal cell 和 Reduction Cell
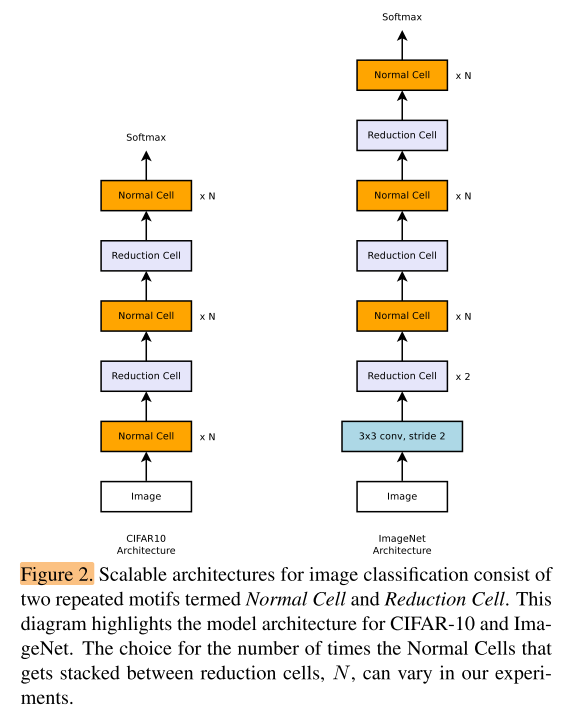
Note on ImageNet we have more Reduction Cells, since the incoming image size is 299x299 compared to 32x32 for CIFAR.
注意到 ImageNet 的结构有更多的Reduction Cells,因为输入是299×299,而cifar10是32×32
We use a common heuristic to double the number of filters in the output whenever the spatial activation size is reduced in order to maintain roughly constant hidden state dimension [32, 53].
我们使用了一种常见的方法,即当feature map减小时(减半时),倍增卷积核的个数,以保持hidden state维度大致不变
Importantly, much like Inception and ResNet models [59, 20, 60, 58], we consider the number of motif repetitions N and the number of initial convolutional filters as free parameters that we tailor to the scale of an image classification problem.
就像 Inception 和 ResNet,我们将cell重复的次数N和 &&初始化的卷积核数量&& 设置为可变的超参数,可以后期设置以适应不同的图片分类问题
Search Space 搜索空间
The structures of the cells can be searched within a search space defined as follows (see Appendix, Figure 7 for schematic).
cell的搜索空间定义如图7所示
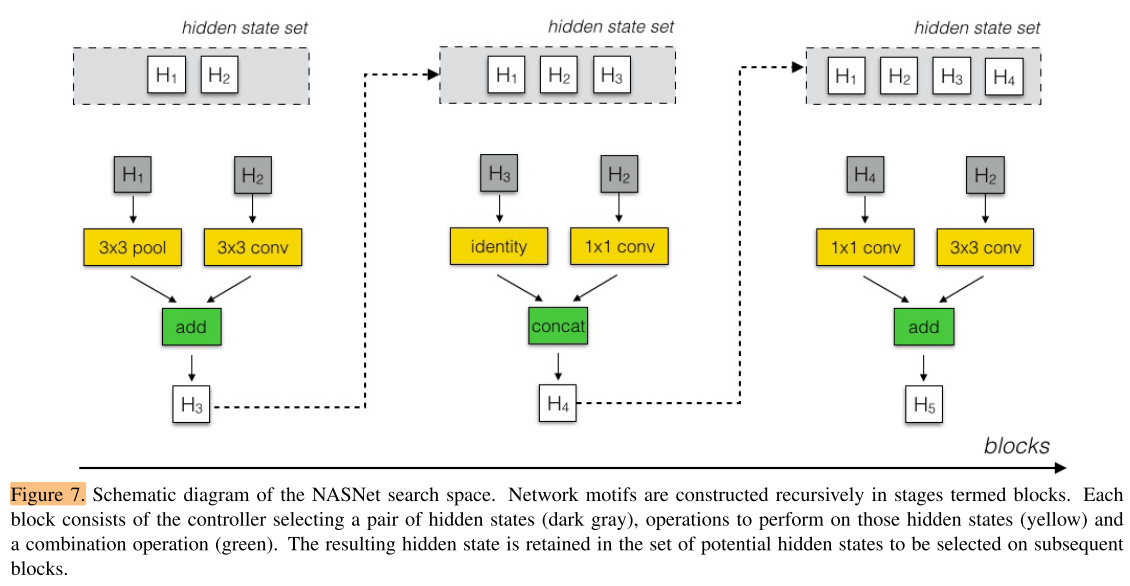
In our search space, each cell receives as input two initial hidden states hi and hi−1 which are the outputs of two cells in previous two lower layers or the input image.
在我们的搜索空间中,每个cell输入2个hidden state hi 和 hi-1,这2个hidden state 分别是先前cell的输出,或者输入图像本身。
The controller RNN recursively predicts the rest of the structure of the convolutional cell, given these two initial hidden states (Figure 3).
控制器RNN根据这2个hidden stages,递归地预测 && cell的剩余结构 &&
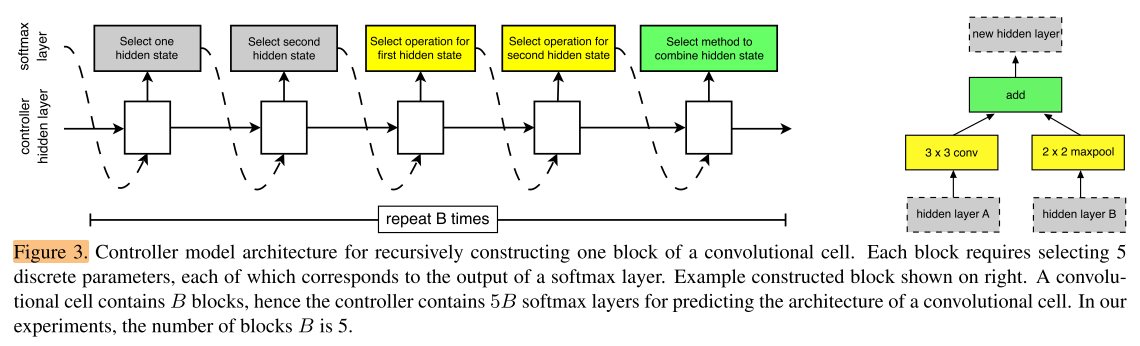
The predictions of the controller for each cell are grouped into B blocks, where each block has 5 prediction steps made by 5 distinct softmax classifiers corresponding to discrete choices of the elements of a block:
控制器RNN对每个cell的预测分为B个blocks(每个cell中有B个节点,即每个block预测每个节点的操作),每组由5个softmax分类器进行5个预测步骤
Step 1. Select a hidden state from hi, hi−1 or from the set of hidden states created in previous blocks.
Step 2. Select a second hidden state from the same options as in Step 1.
Step 3. Select an operation to apply to the hidden state selected in Step 1.
Step 4. Select an operation to apply to the hidden state selected in Step 2.
Step 5. Select a method to combine the outputs of Step 3 and 4 to create a new hidden state.
-
Step 1. 从hidden state set中选择一个,作为该组的第一个input hidden state
-
Step 2. 从hidden state set中再选择一个,作为该组的第二个input hidden state
-
Step 3. 选择要对第一个input执行的operation,得到output 1
-
Step 4. 选择要对第二个input执行的operation,得到output 2
-
Step 5. 选择结合output 1 和 output 2的方法,得到当前cell的输出(新的hidden state)
The algorithm appends the newly-created hidden state to the set of existing hidden states as a potential input in subsequent blocks.
该算法每次都将新的hidden state加入已有的hidden states set,作为后续cell 的输入的选择空间
The controller RNN repeats the above 5 prediction steps B times corresponding to the B blocks in a convolutional cell.
控制器RNN重复上述5个步骤B次,即对应cell中的B个节点
In our experiments, selecting B = 5 provides good results, although we have not exhaustively searched this space due to computational limitations.
我们实验中选择B=5,由于算力限制,我们没有彻底地搜索整个空间。
In steps 3 and 4, the controller RNN selects an operation to apply to the hidden states.
We collected the following set of operations based on their prevalence in the CNN literature:
step 3/4中的对input hidden state执行的operation,从以下集合中选择:

In step 5 the controller RNN selects a method to combine the two hidden states either
(1) element-wise addition between two hidden states or
(2) concatenation between two hidden states along the filter dimension.
Step 5 中控制器RNN选择结合两个output的操作从以下2种操作中选择;
(1)两个output 对应元素相加
(2)两个output在filter维度上堆叠&& (通道堆叠?)
Finally, all of the unused hidden states generated in the convolutional cell are concatenated together in depth to provide the final cell output.
最后,stage set中所有没有被后续cell使用(作为输入)过的hidden stages,在深度上堆叠,作为最后一个cell的输出
To allow the controller RNN to predict both Normal Cell and Reduction Cell, we simply make the controller have 2 × 5B predictions in total, where the first 5B predictions are for the Normal Cell and the second 5B predictions are for the Reduction Cell.
为了让控制器RNN预测 Normal Cell 和 Reduction Cell,我们将控制器有2×5B个预测(Normal Cell 有B节点,Reduction Cell有B个节点,2种Cell都各有5个节点)
Search Process 搜索过程
Finally, our work makes use of the reinforcement learning proposal in NAS [71]
最后,我们使用[71]中的强化学习对搜索空间进行搜索
however, it is also possible to use random search to search for architectures in the NASNet search space.
不过也可以用随机搜索对搜索空间进行搜索
In random search, instead of sampling the decisions from the softmax classifiers in the controller RNN, we can sample the decisions from the uniform distribution.
在随机搜索中,可以不使用控制器RNN中的softmax对搜索空间进行采样,而是使用均匀分布采样
In our experiments, we find that random search is slightly worse than reinforcement learning on the CIFAR10 dataset.Although there is value in using reinforcement learning, the gap is smaller than what is found in the original work of [71].
实验中我们发现随机搜索比强化学习搜索效果略差,但差距小于原始论文[71]中提到的。
This result suggests that
the NASNet search space is well-constructed such that random search can perform reasonably well and
random search is a difficult baseline to beat.
We will compare reinforcement learning against random search in Section 4.4.
这个结果说明,
(1)NASNet search space 是一个构建的较好的搜索空间,使得随机搜索也表现得很好
(2)随机搜索也是一个强力的baseline
我们将在Section 4.4中对比强化学习搜索和随机搜索
Sec 4. Experiments
Hardware
In our experiments, the pool of workers in the workqueue consisted of 500 GPUs.
实验中使用了500个GPU
The result of this search process over 4 days yields several candidate convolutional cells.
搜索过程进行了4天,得到了几个候选cell
We note that this search procedure is almost 7× faster than previous approaches [71] that took 28 days.*1
我们的搜索过程比之前的工作(28天)[71]快了7倍
*1.we note that previous architecture search [71] used 800 GPUs for 28 days resulting in 22,400 GPU-hours.
[71]使用800个gpu计算28天,总计22400个gpu hours
The method in this paper uses 500 GPUs across 4 days resulting in 2,000 GPU-hours.
本文的方法使用了500个gpu计算4天,总计2000个gpu hours
The former effort used Nvidia K40 GPUs, whereas the current efforts used faster NVidia P100s. Discounting the fact that the we use faster hardware, we estimate that the current procedure is roughly about 7× more efficient.
之前的工作使用了K40 GPU,我们使用P100,考虑到硬件性能的差距,我们大致认为有7倍的加速
Best Cell
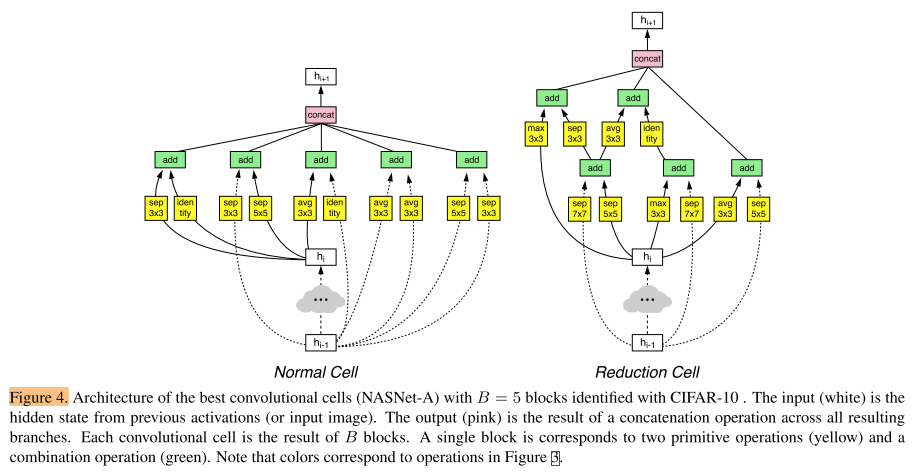
Figure 4 shows a diagram of the top performing Normal Cell and Reduction Cell.
图4展示了性能最佳的Normal Cell 和 Reduction Cell
Sec 4.1 Results on CIFAR-10 Image Classification
For the task of image classification with CIFAR-10, we set N = 4 or 6 (Figure 2).
对于cifar10分类任务,我们将N设置为4或6
The test accuracies of the best architectures are reported in Table 1 along with other state-of-the-art models.
最佳结构和其他sota模型的性能如表1所示:
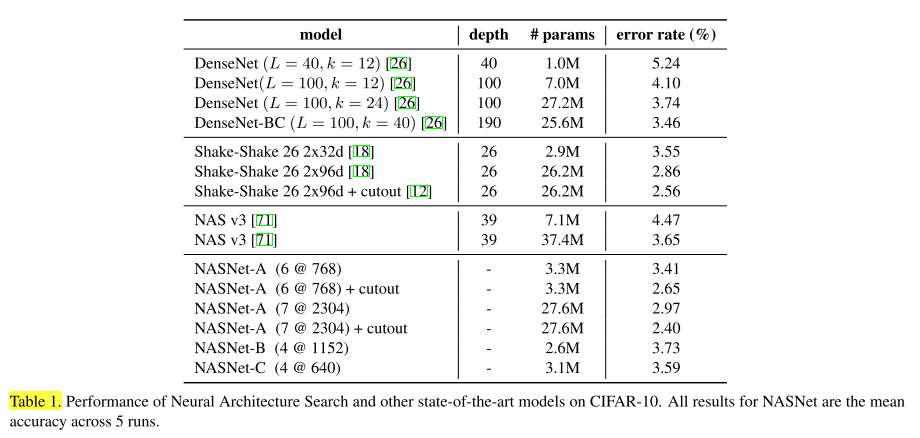
As can be seen from the Table, a large NASNet-A model with cutout data augmentation [12] achieves a state-of-the-art error rate of 2.40% (averaged across 5 runs), which is slightly better than the previous best record of 2.56% by [12].
The best single run from our model achieves 2.19% error rate.
从表中可以看出,含有cotout数据增强的NASNet-A模型达到了sota 2.40% err(5次平均),比之前的2.56% err更好,单次运行可以达到2.19% err
Sec 4.2. Results on ImageNet Image Classification
We emphasize that we merely transfer the architectures from CIFAR-10 but train all ImageNet models weights from scratch.
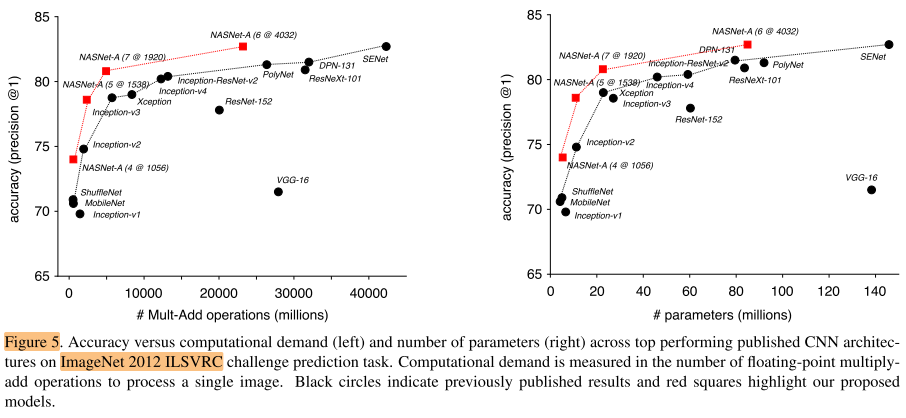
Results are summarized in Table 2 and 3 and Figure 5.
在ImageNet上使用和cifar10相同的cell结构,但权重是重新训练的
We show that this family of models achieve state-of-the-art performance with fewer floating point operations and parameters than comparable architectures
搜素到的model family达到了stoa性能且使用了更少的FLOPs和参数量
Second, we demonstrate that by adjusting the scale of the model we can achieve state-of-the-art performance at smaller computational budgets
通过调整模型大小,我们可以在小计算代价上达到sota
Note we do not have residual connections between convolutional cells as the models learn skip connections on their own. We empirically found manually inserting residual connections between cells to not help performance
注意我们没有在cell之间手动设置residual connection,而是模型自己学习skip connection,经验表明在cell之间手动插入resdual connection没有帮助
Our training setup on ImageNet is similar to [60], but please see Appendix A for details.
我们在ImageNet上的训练设置类似[60],具体细节参考附录A
Table 2 shows that the convolutional cells discovered with CIFAR-10 generalize well to ImageNet problems.
表2说明在cifar10上发现的cell很好的推广到ImageNet上
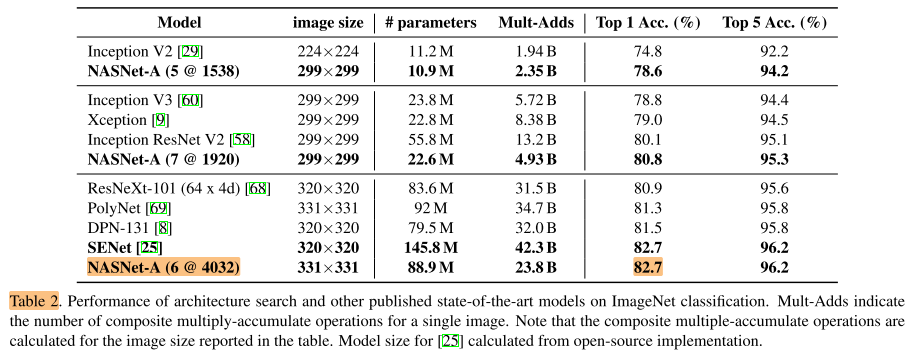
Importantly, the largest model achieves a new state-of-the-art performance for ImageNet (82.7%) based on single, non-ensembled predictions, surpassing previous best published result by ∼1.2% [8].
很重要的一点,搜素到的最大的模型达到了ImageNet上新的sota 82.7% acc,超过了已发表的论文1.2%
Among the unpublished works, our model is on par with the best reported result of 82.7% [25], while having significantly fewer floating point operations.
在未发表的论文中,我们达到了相同的精度82.7 acc,但是有着更少的FLOPs
Figure 5 shows a complete summary of our results in comparison with other published results.
图5是其他模型的对比
Finally, we test how well the best convolutional cells may perform in a resource-constrained setting, e.g., mobile devices (Table 3).
最后我们在性能约束的条件下测试最佳cell的表现
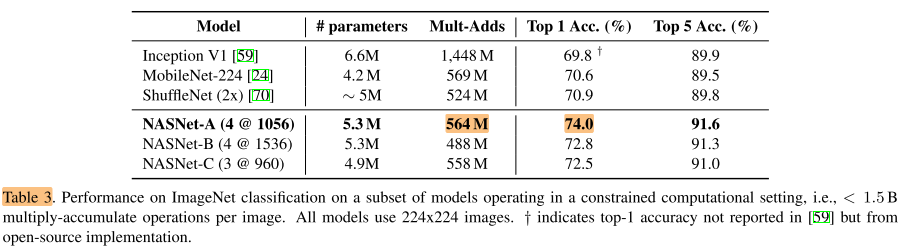
An architecture constructed from the best convolutional cells achieves superior predictive performance (74.0% accuracy) surpassing previous models but with comparable computational demand.
我们的架构在相当计算开销下,超过了之前的模型
In summary, we find that the learned convolutional cells are flexible across model scales achieving state-of-the-art performance across almost 2 orders of magnitude in computational budget.
总之,学习cell是一种灵活地调整模型规模(可以调整超过2个数量级),并达到sota的方法
Sec 4.3. Improved features for object detection
To address this question, we plug in the family of NASNet-A networks pretrained on ImageNet into the Faster-RCNN object detection pipeline [47] using an opensource software platform [28].
我们将在ImageNet上得到的NASNet-A网络应用到目标检测上
For the mobile-optimized network, our resulting system achieves a mAP of 29.6% – exceeding previous mobile-optimized networks that employ Faster-RCNN by over 5.0% (Table 4).
在移动优化的网络上,比之前的工作提高了5.0%
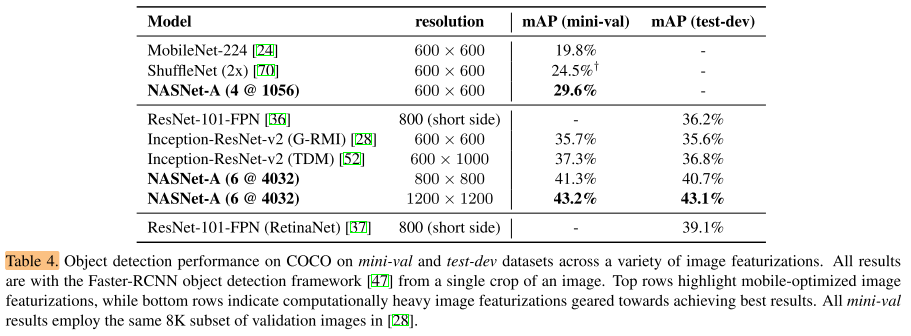
These results provide further evidence that NASNet provides superior, generic image features that may be transferred across other computer vision tasks.
这个结果表明NASNet的优越性,图像特征可以在不同的视觉任务中迁移
Figure 10 and Figure 11 in Appendix C show four examples of object detection results produced by NASNet-A with the Faster-RCNN framework.


Sec 4.4. Efficiency of architecture search methods
Though what search method to use is not the focus of the paper, an open question is how effective is the reinforcement learning search method.
什么样的搜索方法不是本文的重点,一个开放的问题是,强化学习有多有效?
Figure 6 shows the performance of reinforcement learning (RL) and random search (RS) as more model architectures are sampled.
图6展示了强化学习和随机搜索的结果
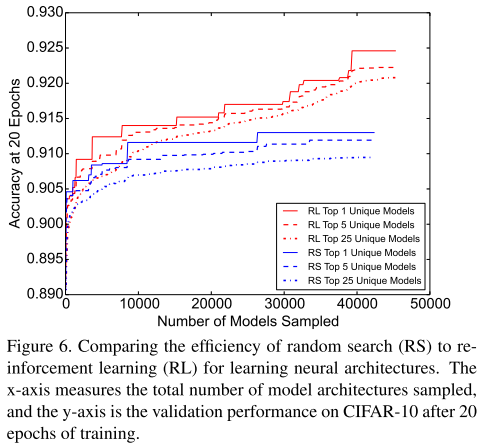
Note that the best model identified with RL is significantly better than the best model found by RS by over 1% as measured by on CIFAR-10.
注意到强化学习比随机搜索在cifar10上高出1%
Conclusion
In this work, we demonstrate how to learn scalable, convolutional cells from data that transfer to multiple image classification tasks.
本文我们提出了一种可以在不同分类任务中迁移的可缩放的卷积cell搜索方法
The learned architecture is quite flexible as it may be scaled in terms of computational cost and parameters to easily address a variety of problems.
学到的结构非常灵活,可以根据计算限制,参数量限制进行缩放
In all cases, the accuracy of the resulting model exceeds all human-designed models – ranging from models designed for mobile applications to computationally-heavy models designed to achieve the most accurate results.
在本文提到的领域,搜索到的模型精度都超过了手工设计的模型(不论是计算限制的移动模型还是追求精度的大模型)
The key insight in our approach is to design a search space that decouples the complexity of an architecture from the depth of a network.
本文方法的关键在于设计一个搜索空间,将结构的复杂度和深度解耦(即 将搜索整个网络,简化为搜索cell再堆叠cell)。
This resulting search space permits identifying good architectures on a small dataset (i.e., CIFAR-10) and transferring the learned architecture to image classifications across a range of data and computational scales.
由此产生的搜索空间,可以在小数据集上搜索好的结构并迁移到大的数据集上
Finally, we demonstrate that we can use the resulting learned architecture to perform ImageNet classification with reduced computational budgets that outperform streamlined architectures targeted to mobile and embedded platforms [24, 70].
最后,使用我们学到的模型在计算开销限制的条件下的性能比之前的小模型结果更好。
Summary
- 搜索空间简化:受到resnet-like结构启发,将直接搜索大型CNN简化为 搜索cell再堆叠cell,使得网络的搜索空间简化为cell的搜索空间;进而获得了结构的迁移性(不同规模数据集之间迁移,不同CV任务之间迁移)
- 不同分辨率适应:设计了Normal Cell 和 Reduction Cell,使得堆叠后的网络可以处理任意分辨率
- 每个cell内的节点结构部分固定(都有一个终节点进行contact)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号