词向量-LRWE模型-更好地识别反义词同义词
上一节,我们介绍利用文本和知识库融合训练词向量的方法,如何更好的融合这些结构化知识呢?使得训练得到的词向量更具有泛化能力,能有效识别同义词反义词,又能学习到上下文信息还有不同级别的语义信息。
基于上述目标,我们尝试基于CBOW模型,将知识库中抽取的知识融合共同训练,提出LRWE模型。模型的结构图如下:
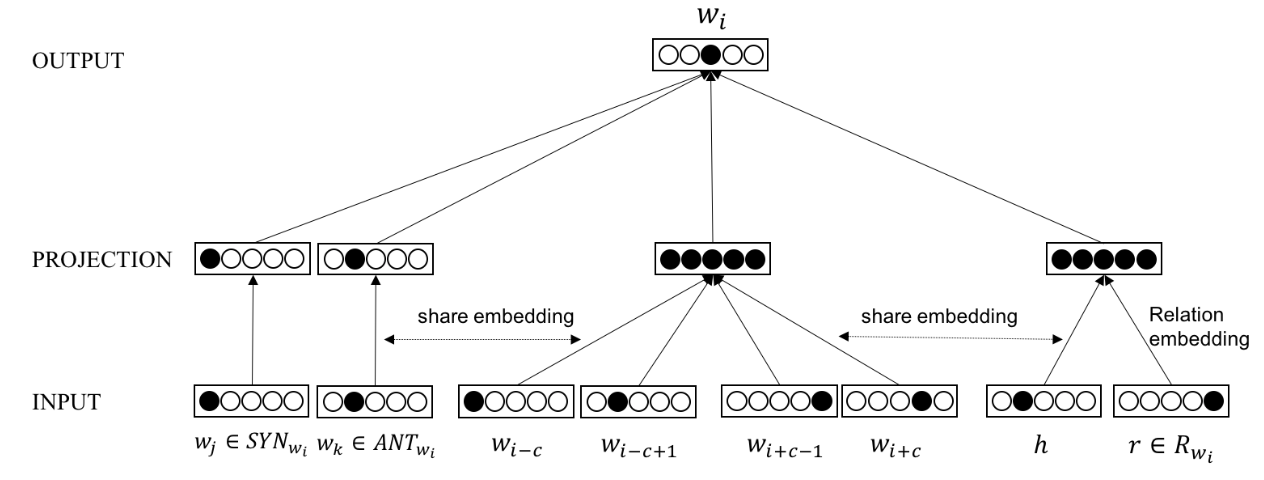
下面详细介绍该模型的思想和求解方法。
1. LWE模型
在Word2vec的CBOW模型中,通过上下文的词预测目标词,目标是让目标词在其给定上下文出现的概率最大,所以词向量训练的结果是与其上下文的词相关联的。然而 CBOW模型只考虑了词语的局部上下文信息,无法很好的表达同义词和反义词等信息。例如下面的几个case:

为了解决上述问题,本文将同义词和反义词等词汇信息以外部知识的形式,作为词向量训练中的监督数据,让训练得到的词向量能学习到同义、反义等词汇信息,从而能更好地区分同义词和反义词。
1.1 模型思想
记 𝑤𝑖 的同义词和反义词集合为( 𝑤𝑖 , 𝑆𝑌𝑁𝑤𝑖 , 𝐴𝑁𝑇𝑤𝑖 ),其中 SYN 表示同义词集合,ANT 表示反义词集合,我们的目标是已知目标词对应的同义词集合和反义词集合,预测目标词,使得目标词和它的同义词距离尽可能相近,与反义词距离尽可能远。
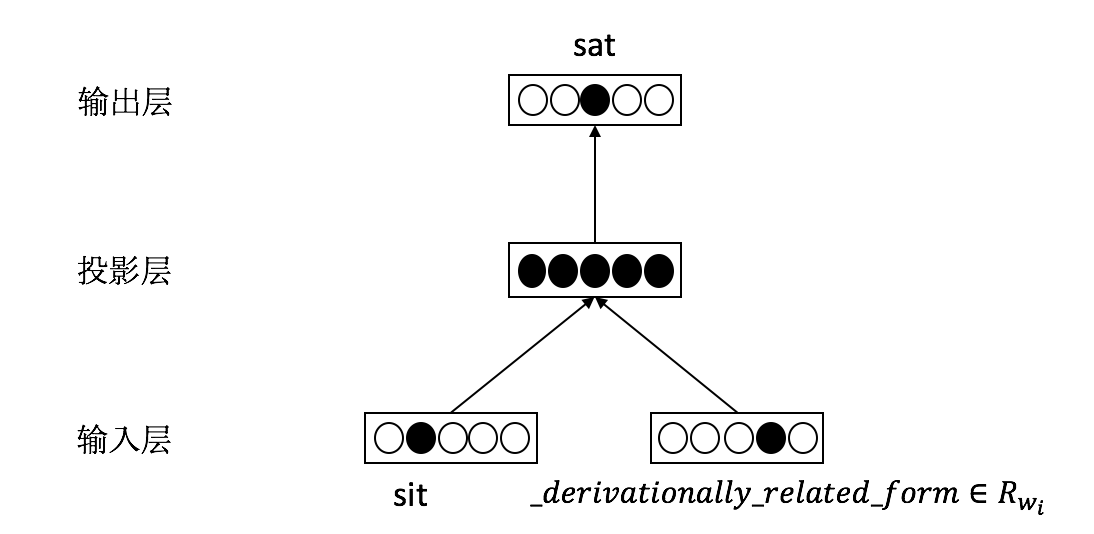
例如“The cat sat on the mat.”,已知sat有同义词seated,反义词stand,来预测目标词为sat。
该模型称为词汇信息模型,模型结构图如下:
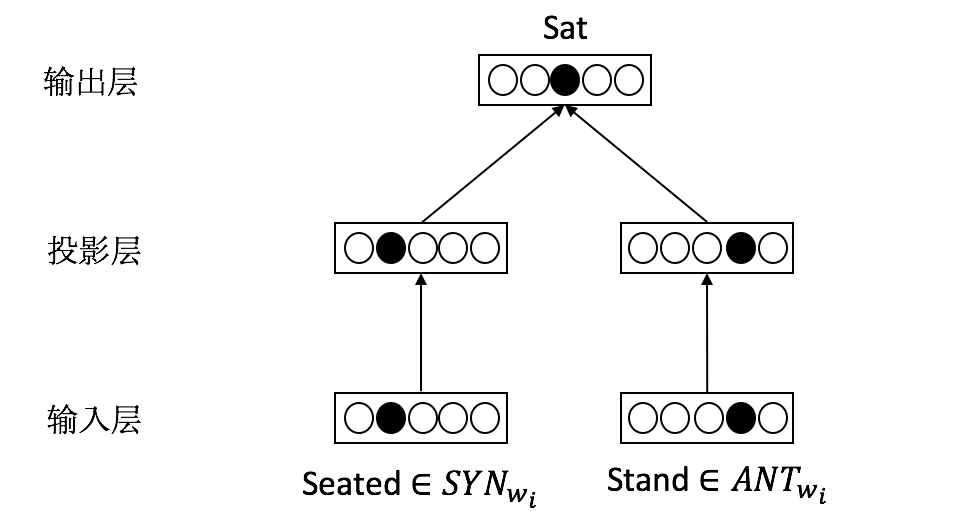
对于一个词语,我们根据它的同义词和反义词预测目标词,最大化词语和它的同义词同时出现的概率, 并降低词语和它反义词同时出现的概率。根据这个目标,定义以下的目标函数:


我们目标是在基于上下文的CBOW语言模型训练过程中,加入同义词反义词信息作为监督,使得训练所得词向量能学习到同义和反义知识。基于该想法,我们提出基于词汇信息的词向量模型(Lexical Information Word Embedding,LWE),目标函数为

模型的结构图如下:
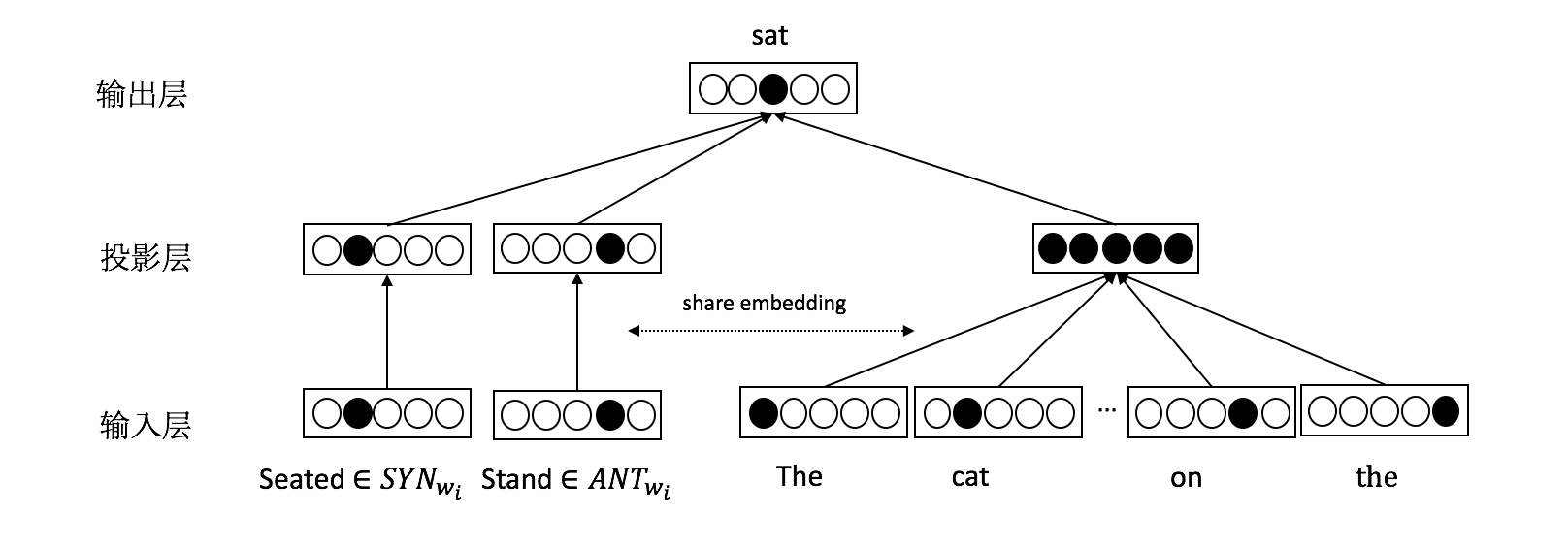
需要注意的是,CBOW模型和词汇信息模型共用同一份词向量,这是为了通过共享表示来获得彼此的知识信息,使得词向量在训练的时候,能综合利用上下文信息和同义词反义词信息,从而得到更高质量的词向量。
1.2 模型求解
从模型结构图中可以看出,LWE可以看成两个CBOW模型的叠加,因此优化求解方法和CBOW模型一样,本文采用的是Negative Sampling进行优化。
使用 Negative Sampling 的方法,目标词视为正样本,通过负采样的其它词称 为负样本,而在我们的模型之中,对于词语的同义词集合来说,目标词是正样本,在同义词集合之外的词语都为负样本,记𝑤𝑖的同义词集合为 𝑆𝑌𝑁𝑤𝑖,对于𝑢∈ 𝑆𝑌𝑁𝑤𝑖则有负样本集合为𝑁𝐸𝐺𝑢 = |𝑉| −𝑆𝑌𝑁𝑤𝑖,记指示函数
![]()
其中正样本标签为 1,负样本标签为 0。则对于样本 (𝑢, 𝑤𝑖 ),训练目标函数(3-1)中

反义词同理,所以对于整个词表 V 来说,整体的目标函数是:
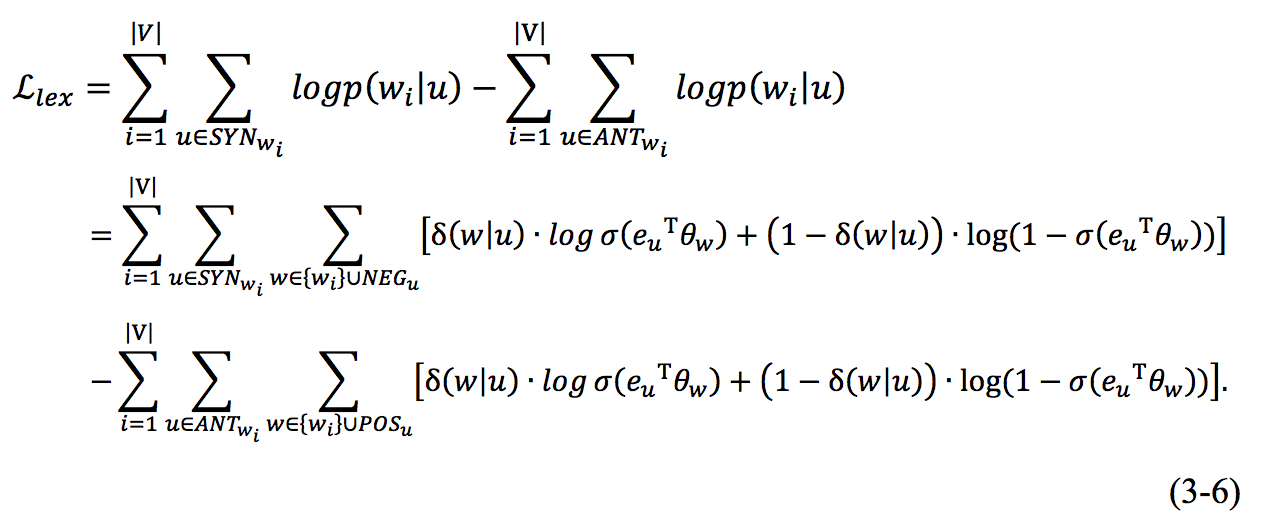
1.3 参数更新
要最大化目标函数(3-6),我们使用随机梯度上升法。用随机梯度上升方法求解时,需要分别求目标函数关于 eu 和 θw 的导数,为了方便推导,记
![]() 从上式可看出同义词和反义词的目标函数除了定义域不同,其函数表达式是一样的,因此只需对函数 Ψ 进行求导。 函数 Ψ 对 𝜃𝑤求导,可得:
从上式可看出同义词和反义词的目标函数除了定义域不同,其函数表达式是一样的,因此只需对函数 Ψ 进行求导。 函数 Ψ 对 𝜃𝑤求导,可得:
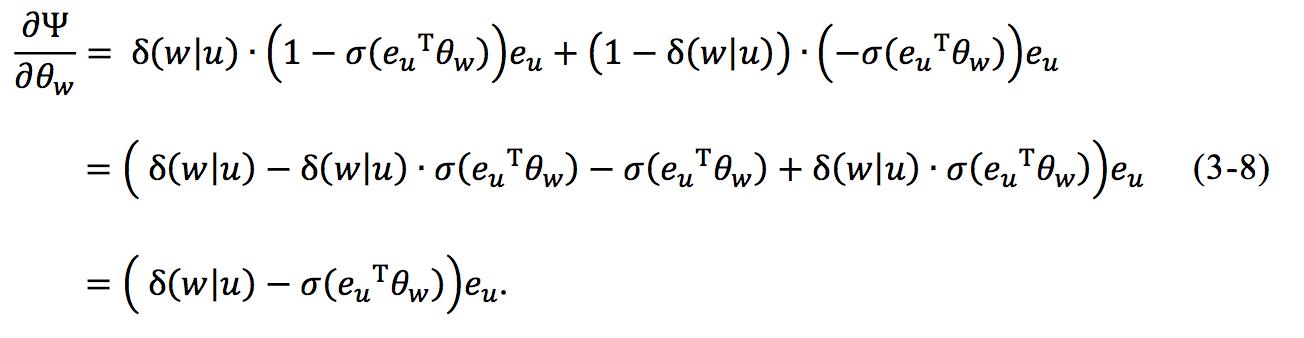
所以 𝜃𝑤 的更新公式为:

2. RWE模型
词语之间具有很多复杂的语义关系,例如上下位关系,“music”是“mp3” 的上位词,“bird”是“animal”的下位词,这里“animal”的下位词除了“bird” 外,还有有“fish”、“insect”等,具有相同上位词 “fish”、“insect” 和“bird”,某种意义上应该是相似或者说相关的,但 Word2vec 只利用大规模语料中的词语共现信息进行训练,所得的词向量只能学习到文本上下文信息,就无法学习到这种词语间的关系,所以其它复杂的语义关系也很难表达充分。
而知识图谱中含有实体词语丰富的关系信息,所以,本文提出基于关系信息的词向量模型,将语言模型和知识表示学习模型进行共同训练,在训练语言模型的时候,加入从知识图谱抽取的多种关系知识, 使得词向量训练过程不仅仅根据上下文词语共现的信息,还学习到对应的关系知识,从而提升词向量的质量。
2.1 模型思想
知识图谱中的知识,一般以三元组 (h, 𝑟, 𝑡) 的形式进行组织,根据CBOW的训练过程,我们可以构造样本 (h, 𝑟, 𝑤𝑖),其中 𝑟 表示 𝑤𝑖 关联的多种不同的关系, 例如(animal, _hyponymy, bird)。
在提取三元组数据后,需要对词语的关系建立表示,如TransE 模型,便是最方便有效的表示方法。基本思想是对于三元组 (h, 𝑟, 𝑡),若三元组是事实信息,则有 𝒉 + 𝒓 ≈ 𝒕,即 𝒉 + 𝒓 对应向量应与 𝒕 更相近。
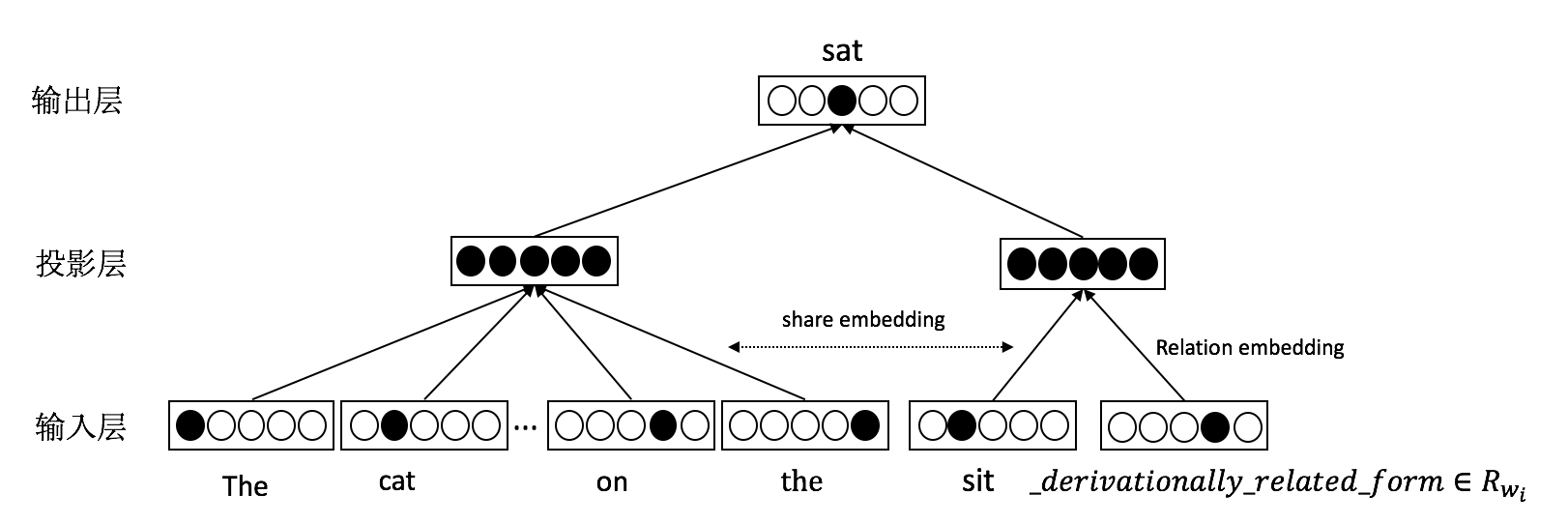
该模型称为关系信息模型,模型结构图如下,模型的输入层是目标词 𝑤𝑖 的对应的三元组集合(h, 𝑟, 𝑤𝑖 ),投影层做了恒等投影,输出层是在字典中预测目标词。
对一个词语 𝑤𝑖,利用知识图谱中的关系三元组这种有监督的数据,我们希望能让词语学习到丰富的关系语义信息,根据这个目标,定义以下的目标函数:

那么在基于上下文的 CBOW 语言模型训练过程中,加入丰富的关系信息作为监督,使得训练所得词向量能学习词与词之间的复杂语义关系。基于该想法,我们提出基于 关系信息的词向量模型(Relational Information Word Embedding,RWE),目标函数为:
 模型结构图如下:两个模型共享同一套词向量,同时本文为三元组中的关系设置分配新的向量空间,也就是说关系向量和词向量独立表示,原因是为了避免与词向量产生冲突。
模型结构图如下:两个模型共享同一套词向量,同时本文为三元组中的关系设置分配新的向量空间,也就是说关系向量和词向量独立表示,原因是为了避免与词向量产生冲突。
2.2 求解方法
同样,我们采用Negative Sampling进行优化。化简过程和1.2相似,这里给出整体的目标函数
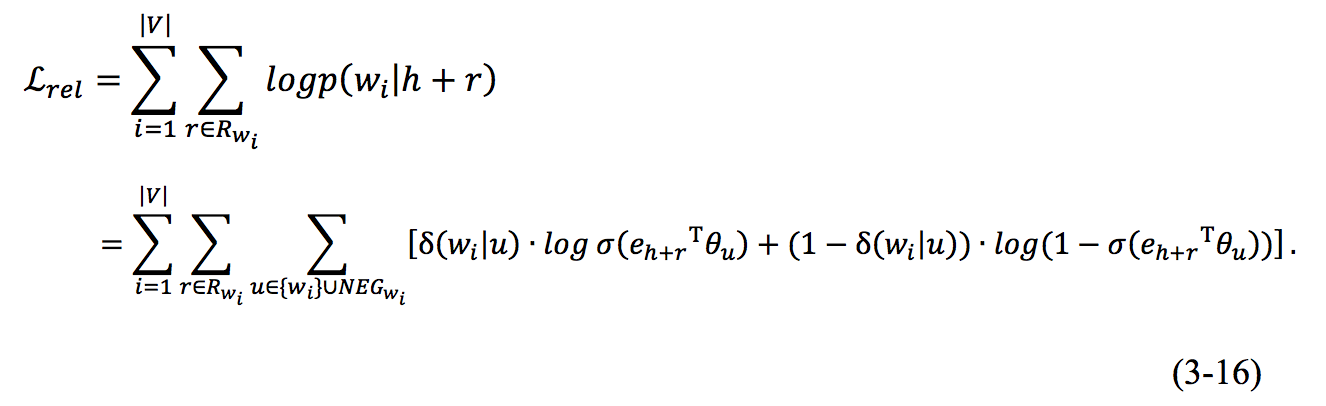
2.3 参数更新
同样,采用随机梯度上升方法进行更新。求解时,需要分别求目标函数关于 eh+r 和 θw 的导数,为了方便推导,记
![]()
函数 Ψ 对 θu 求导,可得:

θu 的更新公式为:

3. LRWE模型
前两节介绍了两个模型,分别是基于词汇信息的词向量模型和基于关系信息的词向量模型,两模型分别适合特定情景下的问题。 本文尝试将两个模型进行联合,让词向量在训练的时候,既能学习到同义词反义词等词汇信息,又能学习到复杂的关系语义信息,基于该目标,得到联合模型LRWE。
联合的词向量模型目标函数如下:
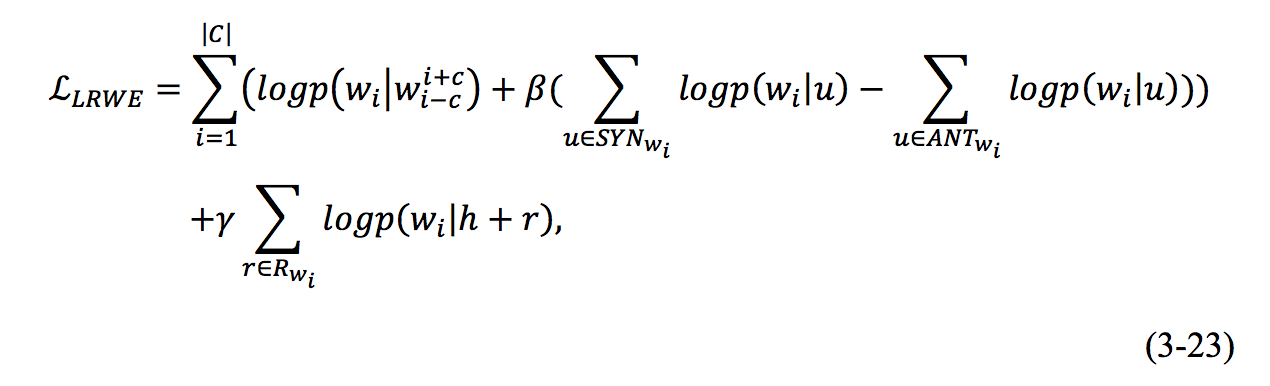
模型的结构图如下:
3.1 模型特点
- 通过共享词向量,同时学习多种信息
- 不同模块具有独立的参数,保持任务差异性
- 重新分配关系向量空间,避免冲突
3.2 模型的理论比较
从参数个数角度,LWE 是在 CBOW 基础上使用词汇信息进行监督,共享一份词向量,同时需要多一份辅助参数向量,故参数个数为 2|𝑒| × |𝑉| + |𝑒| × |𝑉| = 3|𝑒| × |𝑉|; 同理,基于关系信息的词向量模型 RWE,与 CBOW 共享一份词向量,以及拥有独立的辅助参数向量,此外还有一份关系向量,故参数个数为3|𝑒| × |𝑉| + |𝑒| × |𝑅|; 联合的词向量模型 LRWE 是上述两模型的联合,故参数个数为 4|𝑒| × |𝑉| + |𝑒| × |𝑅|。
|
model |
参数个数 |
|
CBOW |
2|𝑒| × |𝑉| |
|
LWE |
3|𝑒| × |𝑉| |
|
RWE |
3|𝑒|×|𝑉|+|𝑒|×|𝑅| |
|
LRWE |
4|𝑒|×|𝑉|+|𝑒|×|𝑅| |
从时间复杂度角度,CBOW 模型通过扫描语料的每一个词,取该词及其上下文作为一个样本,因此接下来对比模型时,只分析训练一个样本的时间复杂度。
CBOW 模型只有输出层 Softmax 预测需要大量的计算,其训练的复杂度为 𝛰(|𝑒| × |𝑉|),如果采用 Hierarchical Softmax 对输出层的 Softmax 做优化,可以加速到𝛰(|𝑒| × 𝑙𝑜𝑔|𝑉|),而采用Negative Sampling,可进一步将复杂度优化到𝛰(|𝑒|)。而 LWE 和 RWE 可以认为是两个CBOW模型的叠加,时间复杂度为𝛰(2|𝑒|) ,虽然相比 CBOW 模型较复杂,但在线性时间内能学习到更多的语义信息,使得词向量表达更充分。
4. 实验结果
这一节我们设计实现一系列实验任务,来验证和评估本文所提出模型的合理性和有效性,实验包括语义相关性、反义词同义词识别等自然语言处理任务,并给出实验结果与分析。
4.1 训练语料
文本语料来自维基百科前十亿字节enwiki9,同义词和反义词语料是从WordNet中抽取,三元组语料从Freebase中抽取。具体条目如下:

4.2 实验任务及结果
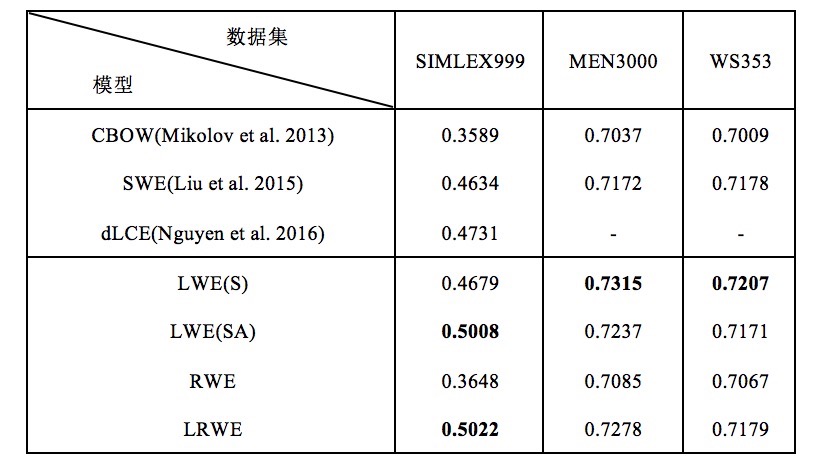
(1)wordsim任务
该任务主要评估词向量的语义相似性和语义相关性,数据集包括Wordsim353(2002) ,MEN3000(2012) ,SIMLEX999(2014), 评估方法是皮尔逊相关系数。实验结果如下
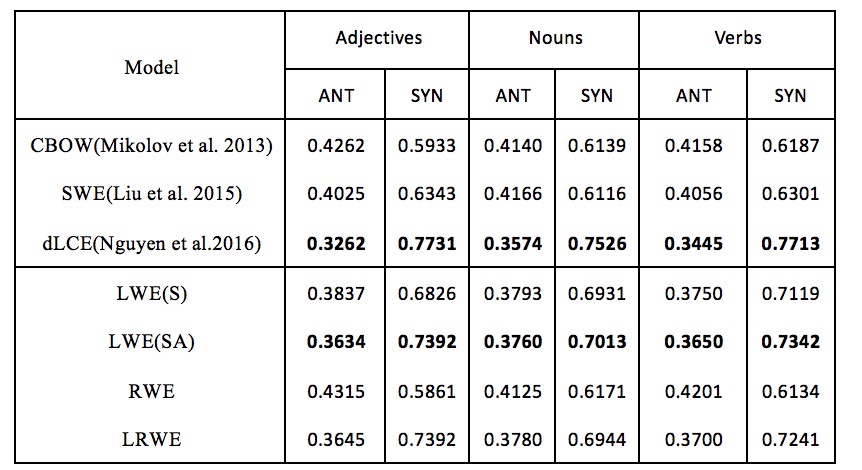
(2)反义词同义词识别任务
该任务由Roth[1]等人提出,包含600个形容词词对,700个名词词对,800个动词词对,其中同义词词对和反义词词对各占一半。评估方法是平均精确率(Average Precision,AP)
此外,我们还在单词类比推理,同义词检测,文本分类等任务上进行实验,下面是经PCA降维后的部分词向量,如图:
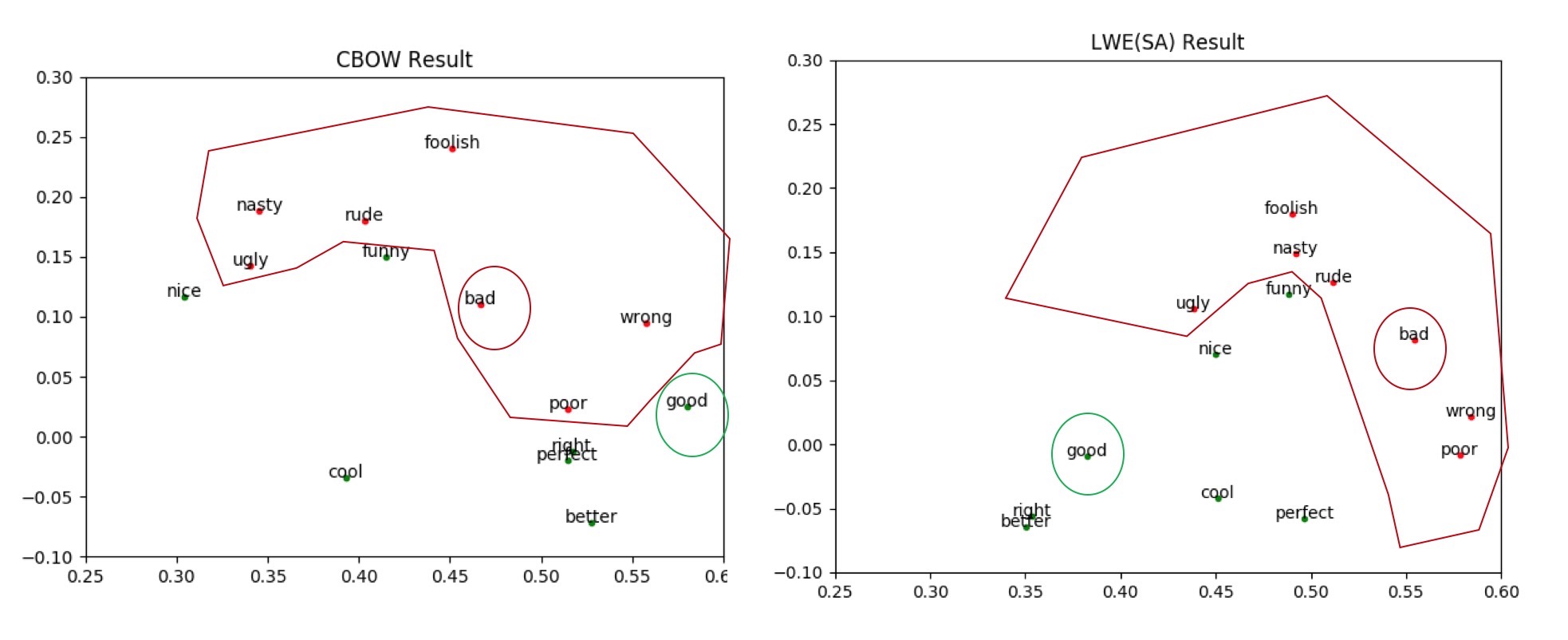
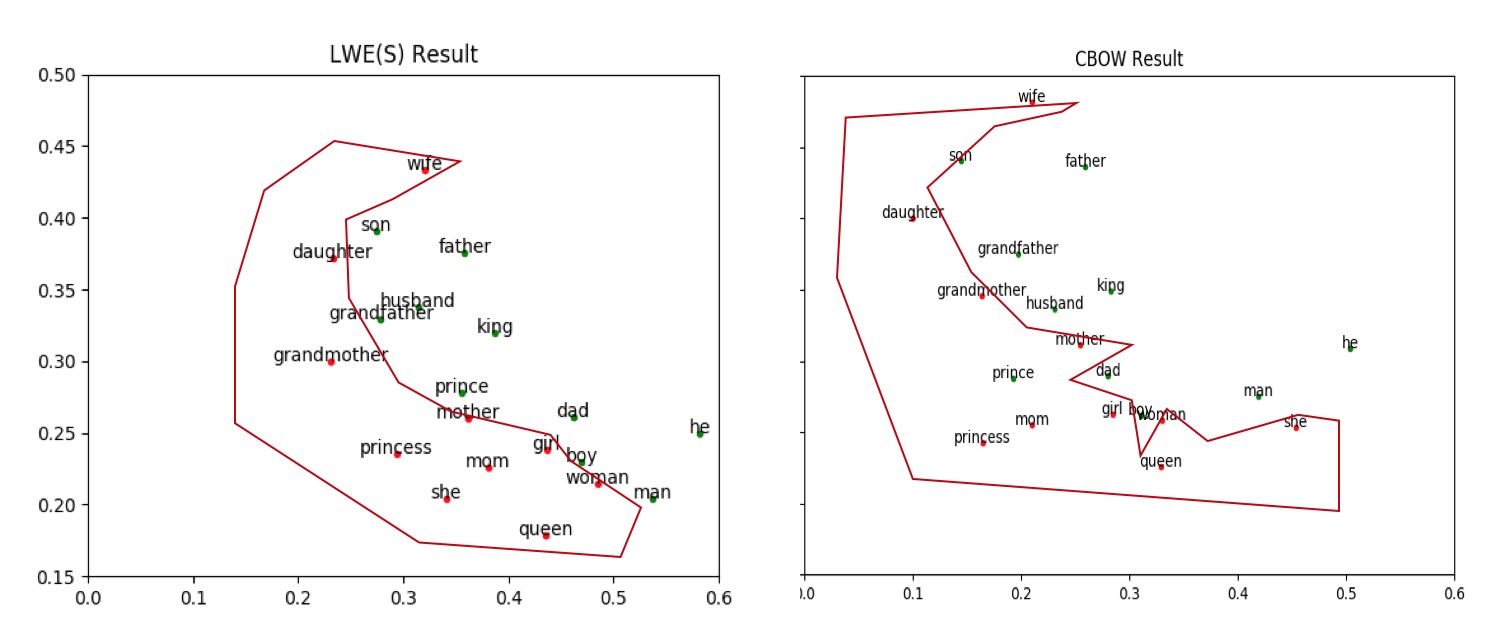
整体来说,LWE模型能更好的识别同义词和反义词,RWE模型能学习到一定的关系信息,但受限于freebase数据,因为本文主要训练的是词向量,在freebase中的覆盖率相对较少,相关的三元组的关系类型不多。
因此有兴趣的同学可以尝试LWE模型,加入同义词和反义词信息,使得训练所得的词向量能更好识别反义词和同义词。
本文地址:http://www.cnblogs.com/chenbjin/p/7106139.html
github: https://github.com/chenbjin/LRCWE
参考:
[1] Roth M, Walde S S I. Combining Word Patterns and Discourse Markers for Paradigmatic Relation Classification. ACL 2014.
[2] Liu Q, Jiang H, Wei S, et al. Learning Semantic Word Embeddings based on Ordinal Knowledge Constraints. ACL 2015.
[3] Nguyen K A, Walde S S I, Vu N T. Integrating Distributional Lexical Contrast into Word Embeddings for Antonym-Synonym Distinction. ACL 2016.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号