关于根据大数据对非正常企业的判断小结
一、题目:
数据组成
增值税发票数据,文件名zzsfp
发票对应货物明细数据,文件名zzsfp_hwmx
企业信息,文件名nsrxx
数据字段说明
zzsfp表
|
字段名称 |
字段含义 |
数据类型 |
备注 |
|
fp_nid |
发票id |
String |
发票唯一标识 |
|
xf_id |
销方识别号 |
String |
企业唯一身份标识 |
|
gf_id |
购方识别号 |
String |
企业唯一身份标识 |
|
je |
金额 |
Double |
|
|
se |
税额 |
Double |
|
|
jshj |
价税合计 |
Double |
|
|
kpyf |
开票月份 |
String |
|
|
kprq |
开票日期 |
String |
|
|
zfbz |
作废标志 |
String |
‘Y’代表作废 |
zzsfp表内容($ less zzsfp)
zzsfp_hwmx表
|
字段名称 |
字段含义 |
数据类型 |
备注 |
|
fp_nid |
发票id |
String |
发票唯一标识 |
|
date_key |
开票月份 |
String |
|
|
hwmc |
货物名称 |
String |
|
|
ggxh |
规格型号 |
String |
|
|
dw |
单位 |
String |
|
|
sl |
数量 |
Double |
|
|
dj |
单价 |
Double |
|
|
je |
金额 |
Double |
|
|
se |
税额 |
Double |
|
|
spbm |
商品编码 |
String |
|
zzsfp_hwmx表内容($ less zzsfp_hwmx)
nsrxx表
|
字段名称 |
字段含义 |
数据类型 |
备注 |
|
hydm |
行业代码 |
String |
|
|
nsr_id |
纳税人id |
String |
企业唯一身份标识 |
|
djzclx_dm |
登记注册类型代码 |
String |
网上可查阅相关代码含义 |
|
kydjrq |
开业登记日期 |
String |
|
|
xgrq |
修改日期 |
String |
给企业打标签的时间 |
|
label |
标签 |
String |
‘0’代表正常企业 ‘1’代表问题企业 |
nsrxx表内容($ less nsrxx)
关联数据的必要说明
(1) zzsfp表可通过fp_nid进行关联
(2) zzsfp表可通过xf_id或者gf_id与nsrxx中的nsr_id进行关联,分离出销项发票表和进项发票表
最终给出的数据情况
企业总数:33,829
非正常企业总数:318
二、第一天解题思路
首先我实在是上课的时候没有注意听到老师说的怎样算是非正常企业,所以下手就很难就想了半天。
1、首先对zzsfp_hwmx表利用MapReduce进行操作,我通过发票id把相同的金额进行叠加统计,但是这个表里有很多垃圾数据,比如说这个表有十个属性列但是数据里有超过10列的数据,还有些是金额属性列上对应的值不是数字类型,因为我没对zzsfp_hwmx表进行清洗。
2、再然后我利用上面得到的叠加金额后的文件和zzsfp文件进行连接,用得是之前学习的MapReduce实验五-Map端join。
得出发票id,叠加金额,销方识别号,购方识别号,金额,税额六个属性的表。

然后把叠加金额和金额做差取绝对值进行排序
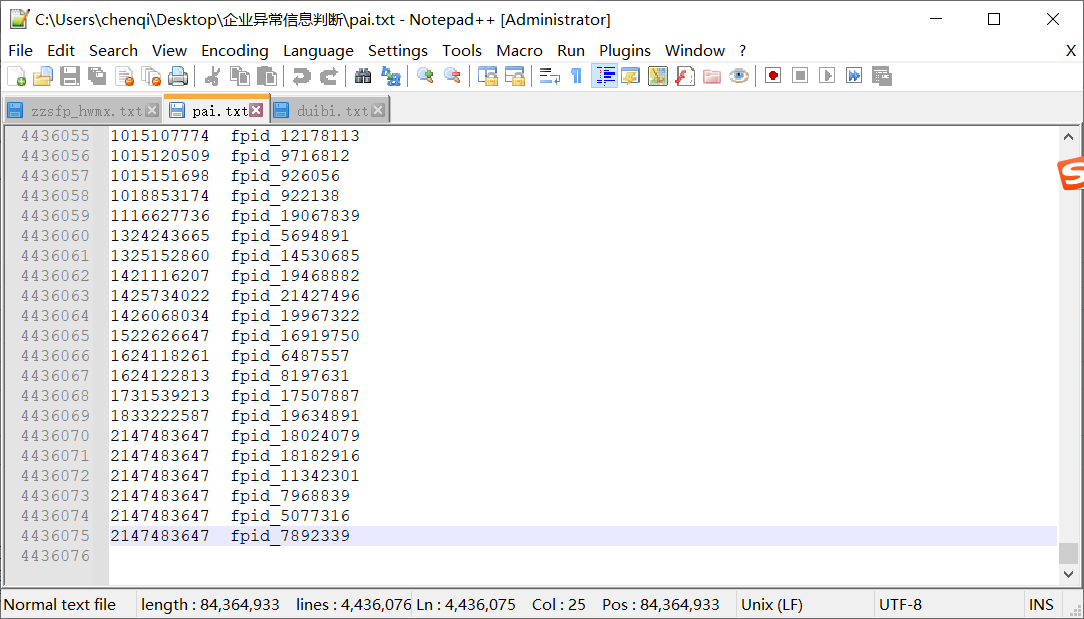
很明显有很多的问题。
1、zzsfp里有很多重复的数据没有清洗
2、zzsfp里有些识别号在nsrxx表里找不到

 浙公网安备 33010602011771号
浙公网安备 33010602011771号