单词统计
用户需求:
英语的26 个字母的频率在一本小说中是如何分布的?
某类型文章中常出现的单词是什么?
某作家最常用的词汇是什么?
《哈利波特》 中最常用的短语是什么,等等。
我们就写一些程序来解决这个问题,满足一下我们的好奇心。
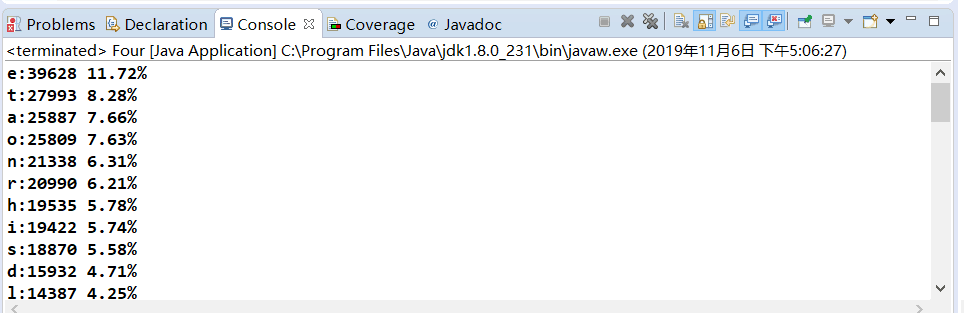
第0步:输出某个英文文本文件中 26 字母出现的频率,由高到低排列,并显示字母出现的百分比,精确到小数点后面两位。
字母频率 = 这个字母出现的次数 / (所有A-Z,a-z字母出现的总数)
如果两个字母出现的频率一样,那么就按照字典序排列。 如果 S 和 T 出现频率都是 10.21%, 那么, S 要排在T 的前面。
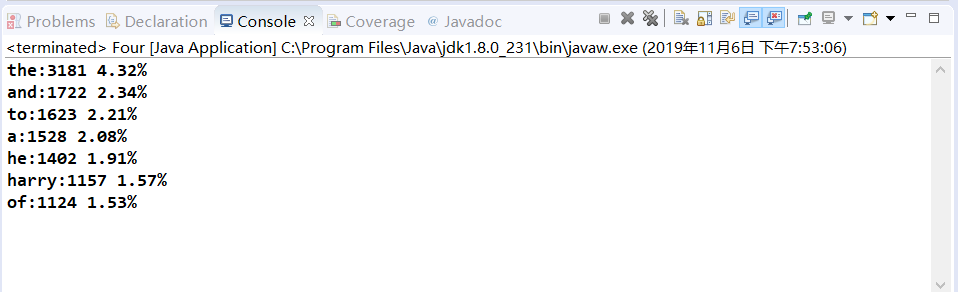
第1步:输出单个文件中的前 N 个最常出现的英语单词。
作用:一个用于统计文本文件中的英语单词出现频率。
单词:以英文字母开头,由英文字母和字母数字符号组成的字符串视为一个单词。单词以分隔符分割且不区分大小写。在输出时,所有单词都用小写字符表示。
英文字母:A-Z,a-z
字母数字符号:A-Z,a-z,0-9


package tesr; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.File; import java.io.FileReader; import java.io.FileWriter; import java.util.ArrayList; import java.util.Comparator; import java.util.HashMap; import java.util.Hashtable; import java.util.List; import java.util.Map; public class Four { private static void mapValueSort(Hashtable<String, Integer> labelsMap) //哈希表排序函数 { List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(labelsMap.entrySet());//创建集合list,并规范集合为哈希表类型,并用labelsMap.entrySet()初始化 list.sort(new Comparator<Map.Entry<String, Integer>>() //定义list排序函数 { public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { int a=o1.getKey().compareTo(o2.getKey()); //比较两者之间字典序大小并其布尔值赋给变量a if(o1.getValue() < o2.getValue()) //比较两者之间次数的大小 { return 1; //若后者大返回1,比较器会将两者调换次序,此为降序 } else if((o1.getValue() == o2.getValue())||((o1.getValue()==1)&&(o2.getValue()==1))) //若次数相同比较字典序 { if(a!=0&&a>0) //字典序在前的在前面 { return 1; } } return -1; } }); int k=0; double sum=0; for (Map.Entry<String, Integer> mapping :list) //遍历排序后的集合 { sum+=mapping.getValue(); //记录总数 } for (Map.Entry<String, Integer> mapping :list) //遍历排序后的集合 { double a=((double)mapping.getValue()/sum)*100; System.out.println(mapping.getKey() + ":" + mapping.getValue()+" "+String.format("%.2f",a)+"%"); } File file1 =new File("C:/Users/香蕉皮/Desktop/wo.txt"); //创建存储数据的文件 try{ FileWriter fw=new FileWriter(file1); BufferedWriter bw=new BufferedWriter(fw); int m=0; for (Map.Entry<String, Integer> mapping :list) //遍历集合 { m++; bw.write(mapping.getKey()); //把关键词写入 bw.write("="); bw.write(toString(mapping.getValue())); //把对象写入 bw.newLine(); //换行 /*if(m>=6) { break; //输入6个后结束 }*/ } bw.close(); fw.close(); }catch(Exception e){ e.printStackTrace(); } } private static String toString(Integer value) { // TODO 自动生成的方法存根 Integer a=new Integer(value); return a.toString(); } public static void main(String[] args) { File file =new File("C:/Users/香蕉皮/Desktop/Harry Potter and the Sorcerer's Stone.txt"); //创建文件(引入飘的文本) try { FileReader fr=new FileReader(file); BufferedReader br=new BufferedReader(fr); //缓冲区 // String tmp=null; String s=null; int i=0; while((s=br.readLine())!=null) //把文本中每行中所有的字符都赋给一个字符串s,若s不为空,则继续循环 { tmp+=s; //把文本所有的字符串都连接起来并赋给tmp } String []str1=tmp.split("[^a-zA-Z\']+"); //用正则表达式和字符串分隔符把文本分割成一个一个的字符串并存到一个字符串数组中 Hashtable<String,Integer> hash = new Hashtable<String,Integer>();//定义一个哈希表并规范关键词key为字符串类型,对象value为Integer类型 for(i=0;i<str1.length;i++) { String s1=str1[i]; for(int j=0;j<s1.length();j++) { if(!hash.containsKey(String.valueOf(s1.charAt(j)))) //判断该关键词是否已经存在哈希表中 { hash.put(String.valueOf(s1.charAt(j)),new Integer(1)); //如果不存在,则把该字符串当作关键词存到哈希表中,并把把该对象value设为1 } else { int a=hash.get(String.valueOf(s1.charAt(j)))+new Integer("1"); //如果存在,则把该关键字对应的对象value加1 hash.put(String.valueOf(s1.charAt(j)),a); } } } mapValueSort((Hashtable<String,Integer>)hash); //把哈希表排序 br.close(); fr.close(); }catch(Exception e){ e.printStackTrace(); } } }
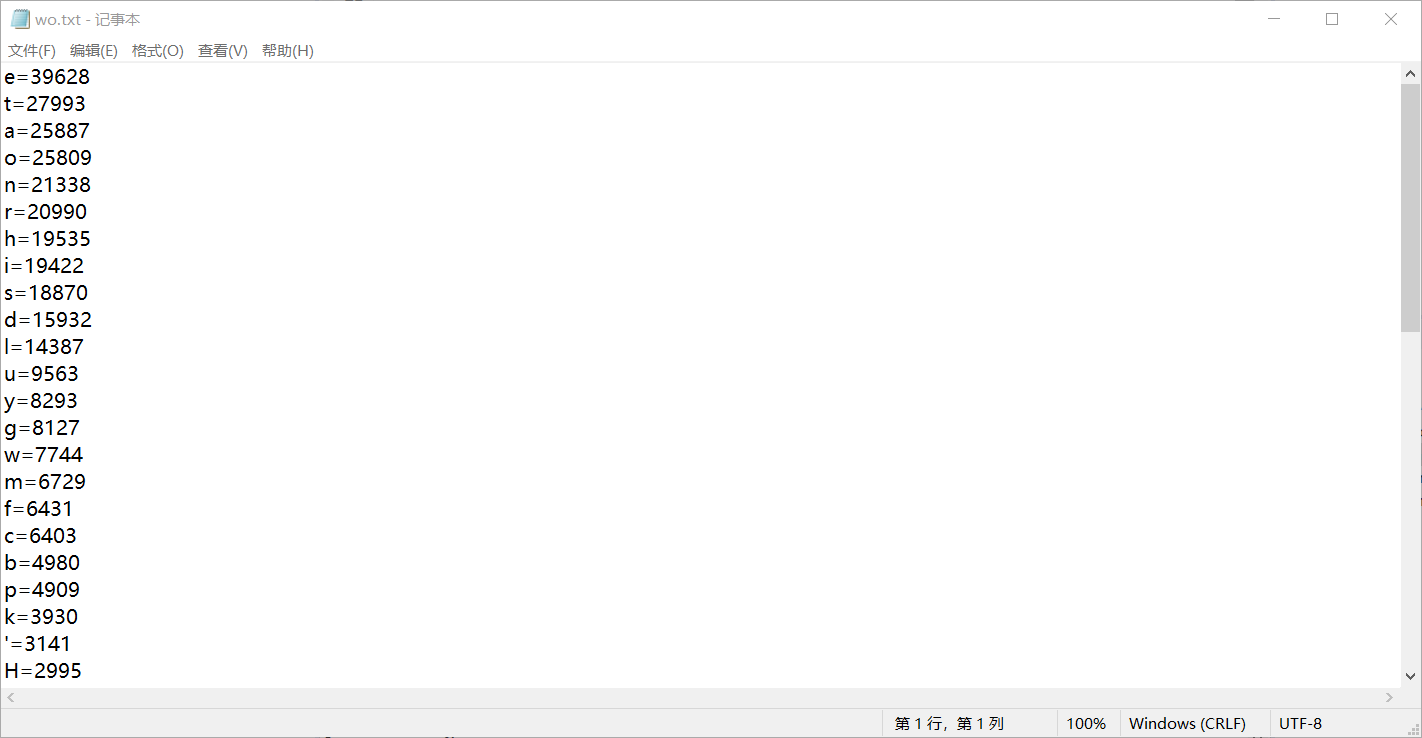
储存数据的文本文件截图:
package tesr; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.File; import java.io.FileReader; import java.io.FileWriter; import java.util.ArrayList; import java.util.Comparator; import java.util.HashMap; import java.util.Hashtable; import java.util.List; import java.util.Map; public class Four { private static void mapValueSort(Hashtable<String, Integer> labelsMap) //哈希表排序函数 { List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String, Integer>>(labelsMap.entrySet());//创建集合list,并规范集合为哈希表类型,并用labelsMap.entrySet()初始化 list.sort(new Comparator<Map.Entry<String, Integer>>() //定义list排序函数 { public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { int a=o1.getKey().compareTo(o2.getKey()); //比较两者之间字典序大小并其布尔值赋给变量a if(o1.getValue() < o2.getValue()) //比较两者之间次数的大小 { return 1; //若后者大返回1,比较器会将两者调换次序,此为降序 } else if((o1.getValue() == o2.getValue())||((o1.getValue()==1)&&(o2.getValue()==1))) //若次数相同比较字典序 { if(a!=0&&a>0) //字典序在前的在前面 { return 1; } } return -1; } }); int k=0; double sum=0; for (Map.Entry<String, Integer> mapping :list) //遍历排序后的集合 { sum+=mapping.getValue(); //记录总数 } for (Map.Entry<String, Integer> mapping :list) //遍历排序后的集合 { double a=((double)mapping.getValue()/sum)*100; System.out.println(mapping.getKey() + ":" + mapping.getValue()+" "+String.format("%.2f",a)+"%"); if(k>=6) { break; //输入6个后结束 } k++; } File file1 =new File("C:/Users/香蕉皮/Desktop/wo.txt"); //创建存储数据的文件 try{ FileWriter fw=new FileWriter(file1); BufferedWriter bw=new BufferedWriter(fw); int m=0; for (Map.Entry<String, Integer> mapping :list) //遍历集合 { m++; bw.write(mapping.getKey()); //把关键词写入 bw.write("="); bw.write(toString(mapping.getValue())); //把对象写入 bw.newLine(); //换行 if(m>=6) { break; //输入6个后结束 } } bw.close(); fw.close(); }catch(Exception e){ e.printStackTrace(); } } private static String toString(Integer value) { // TODO 自动生成的方法存根 Integer a=new Integer(value); return a.toString(); } public static void main(String[] args) { File file =new File("C:/Users/香蕉皮/Desktop/Harry Potter and the Sorcerer's Stone.txt"); //创建文件(引入飘的文本) try { FileReader fr=new FileReader(file); BufferedReader br=new BufferedReader(fr); //缓冲区 // String tmp=null; String s=null; int i=0; while((s=br.readLine())!=null) //把文本中每行中所有的字符都赋给一个字符串s,若s不为空,则继续循环 { tmp+=s; //把文本所有的字符串都连接起来并赋给tmp } tmp=tmp.toLowerCase(); String []str1=tmp.split("[^a-zA-Z\']+"); //用正则表达式和字符串分隔符把文本分割成一个一个的字符串并存到一个字符串数组中 Hashtable<String,Integer> hash = new Hashtable<String,Integer>();//定义一个哈希表并规范关键词key为字符串类型,对象value为Integer类型 for(i=0;i<str1.length;i++) //遍历字符串数组 { if(!hash.containsKey(str1[i])) //判断该关键词是否已经存在哈希表中 { hash.put(str1[i],new Integer(1)); //如果不存在,则把该字符串当作关键词存到哈希表中,并把把该对象value设为1 } else { int a=hash.get(str1[i])+new Integer("1"); //如果存在,则把该关键字对应的对象value加1 hash.put(str1[i],a); } } mapValueSort((Hashtable<String,Integer>)hash); //把哈希表排序 br.close(); fr.close(); }catch(Exception e){ e.printStackTrace(); } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号