第四次作业——结对编程
| 作业要求地址 | https://www.cnblogs.com/harry240/p/11524113.html |
|---|---|
| Github地址 | https://github.com/Mretron/WordCount |
| 结对伙伴博客 | https://www.cnblogs.com/etron/p/11652702.html |
一、psp表格
这次作业经过老师同意依然使用的IDEA+Java进行开发
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 300 | 430 |
| Development | 开发 | 90 | 110 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 30 |
| · Design Spec | · 生成设计文档 | 20 | 20 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 0 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 100 | 120 |
| · Code Review | · 代码复审 | 20 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 20 |
| Reporting | 报告 | 30 | 20 |
| · Test Report | · 测试报告 | 10 | 15 |
| · Size Measurement | · 计算工作量 | 0 | 0 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 25 |
| 合计 | 395 | 430 |
二,结对过程
了解完题目后,简单讨论了项目需求以及项目规范,在明确了需求后,开始使用阿里巴巴开发规范进行开发。程序主要分为统计行数,字母数,单词数,分为三个功能。分配任务后,写出了初代版本,然后调试,修改,进行单元测试。最终形成最终版本。
同时我们命名变量统一使用驼峰命名法。
三、解题思路以及接口设计
首先是统计行数,因为在读取数据的过程中,是一行行读取的,所以在读取时便统计了行数,这个功能是最简单的。至于字母数,直接一个正则表达式进行拆分就可以统计。麻烦的还是统计单词数,以及频率。
calMost类处理出现频率最高的10个单词并且按照字典排序;
CharsCount类统计输入数据的字母数;
LinnsCount类统计行数;
WwordsCount类统计单词数

所以通过以下代码现将原文拆分成字符串数组,通过^[a-zA-Z]{4,}.* 筛选出4个单词以上的单词。
String[] temp = content.split("\\s+");
// 根据题意
// 构造正则表达式筛选规则:以字母开头且长度大于4的单词
String reg = "^[a-zA-Z]{4,}.*";
在一个麻烦的是将出现频率相同的单词,优先输出字典序靠前的单词。
说实话,这个功能我们写了很久,我们就在想能不能用一个比较器类就达到效果。最终,两人通过题目的需求和查找相关资料实现了这个功能。
实现了这个功能
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
return o1.getValue().compareTo(o2.getValue()) != 0 ? o2.getValue().compareTo(o1.getValue()) : o1.getKey().compareTo(o2.getKey());
}
基本的流程便是:访问Main主类通过IO输入流传入文件,首先利用String,StringBuffer类经过简单的处理后,调用我们写好的类利用正则表达式进行统计各种数据,返回即可。详细过程见源代码及其注释:
大致流程如图
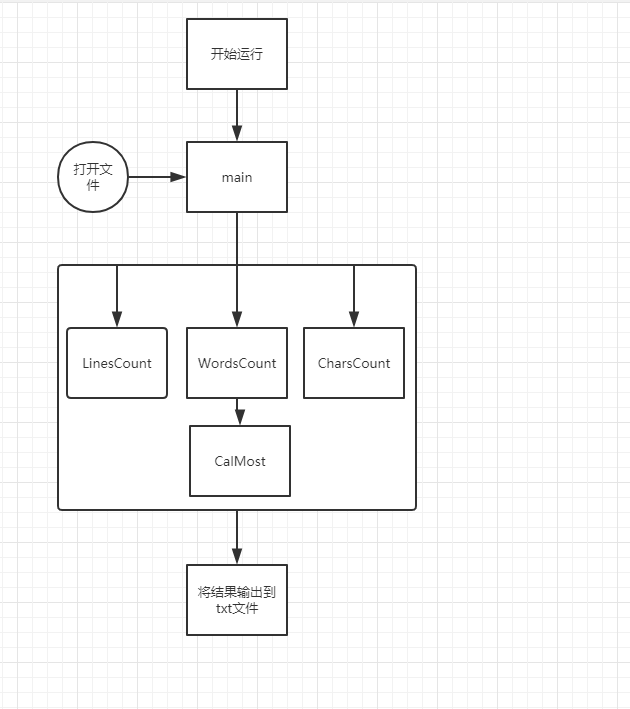
四、代码的复审
1.文本处理BUG
在写完代码进行测试时,发现并没有将紧跟在单词后的标点去除掉,这样造成了that,和that是两个不同单词的错误,在同伴发现错误后,我加了个简单的筛选进行处理。
String content = stringBuilder.toString()
.replace(".", " ")
.replace(",", " ")
.replace("!", " ")
.replace("?", " ");
将文章的4种基本标点去除。
2.性能优化
一开始没有使用正则表达式,使用常规处理方法处理数据,造成程序无比庞大,且所需时间和空间很多,不符合开发规范,采用正则表达式后,看起来舒服多了。(正则表达式是好文明)
我本来是使用StringBuffer进行处理数据的,但是后来发现使用单线程的StringBuilder更快。
但是现在存在的问题依然有,几乎都是单线程,处理文本量很大的数据时,处理速度很慢。
五、性能分析&窗体设计
这里有采用13Mb大小的TXT文档做测试

程序在经过大概3S左右的时间后才得出结果,花费时间这么久肯定某个地方耗时超出了预期
接下来我们看运行结果
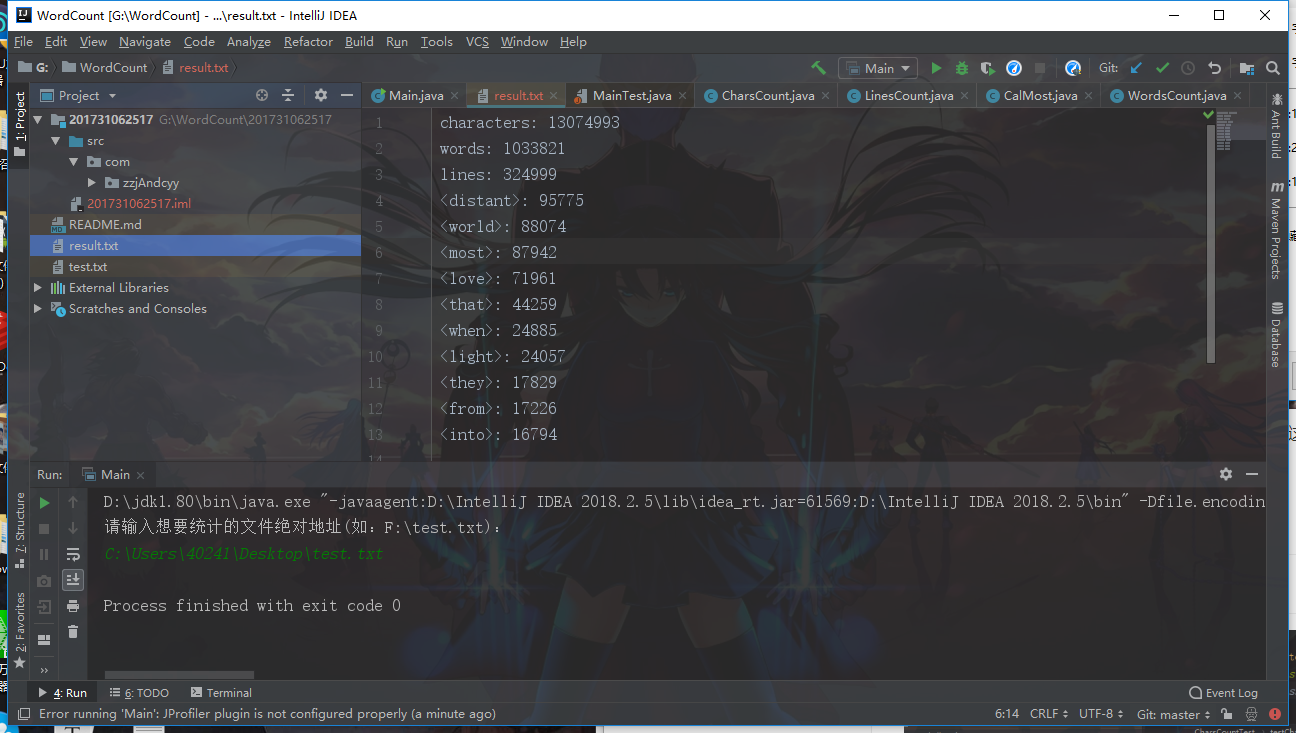
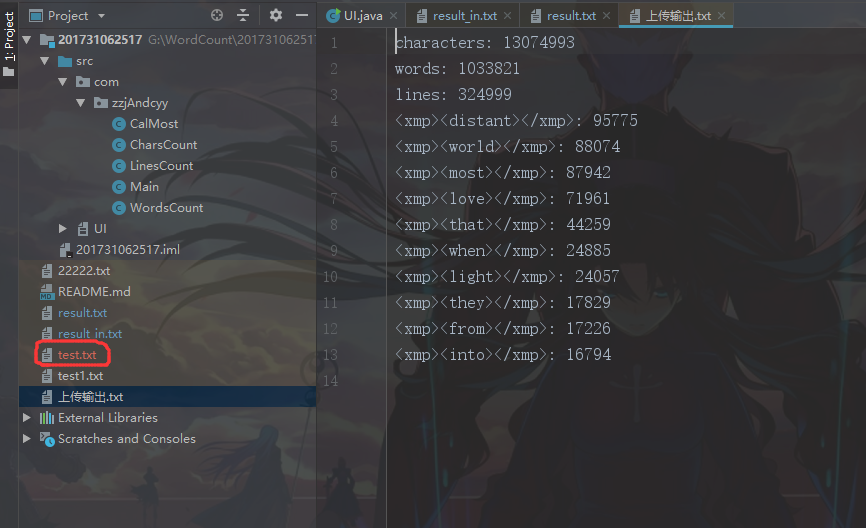
100W个单词1300W个字母。并且选取的是飞鸟集和1984 的混合素材,可以看出距离和爱出现的频率很高(很符合飞鸟集2333)
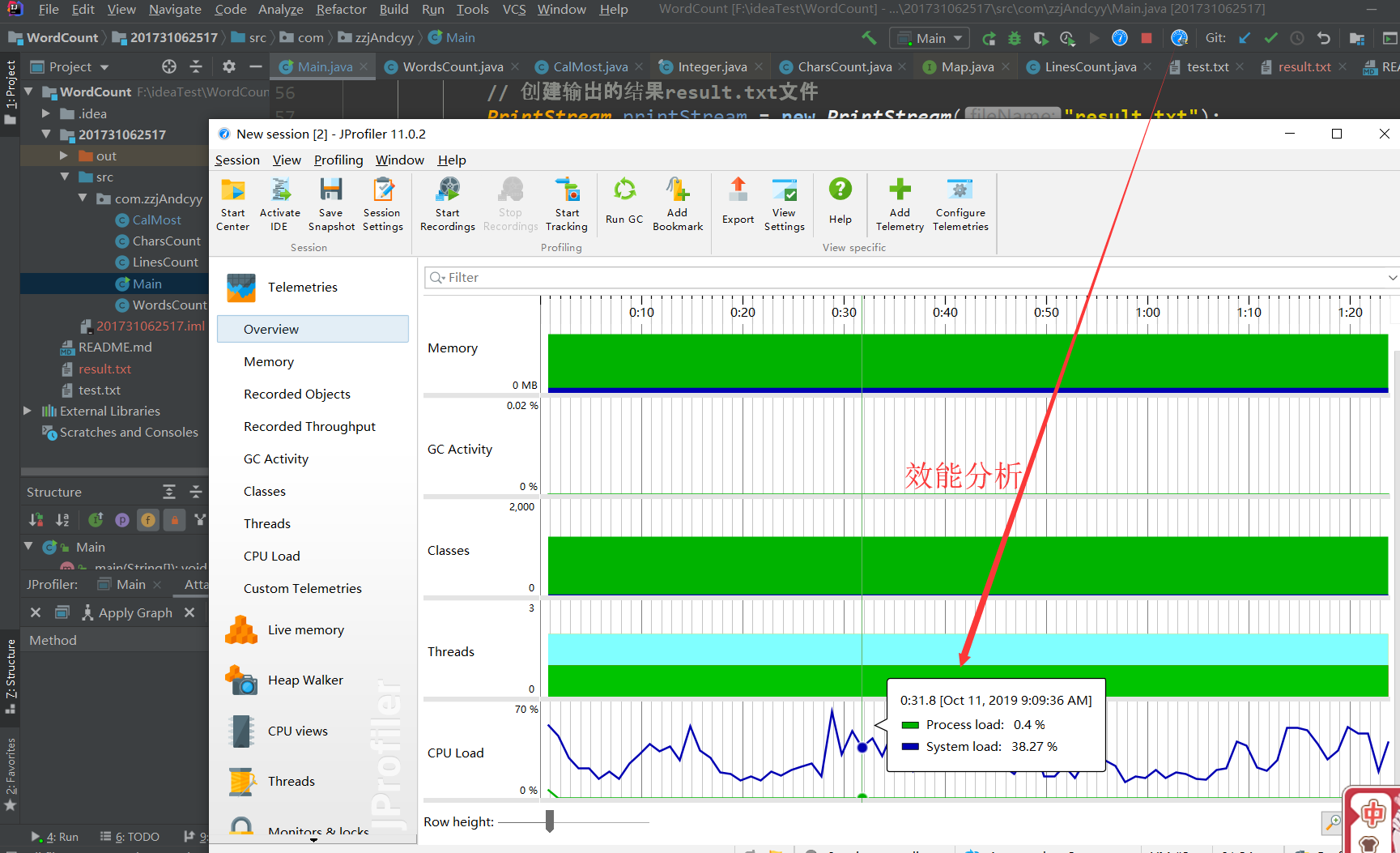
性能分析如下。。。。。
JProfiler是用于分析J2EE软件性能瓶颈并能准确定位到Java类或者方法有效解决性能问题的主流工具,它通常需要与性能测试工具如:LoadRunner配合使用,因为往往只有当系统处于压力状态下才能反映出性能问题。
所以采用JProfiler进行性能测试。
以看到性能的影响并不大,毕竟只是一个单线程程序
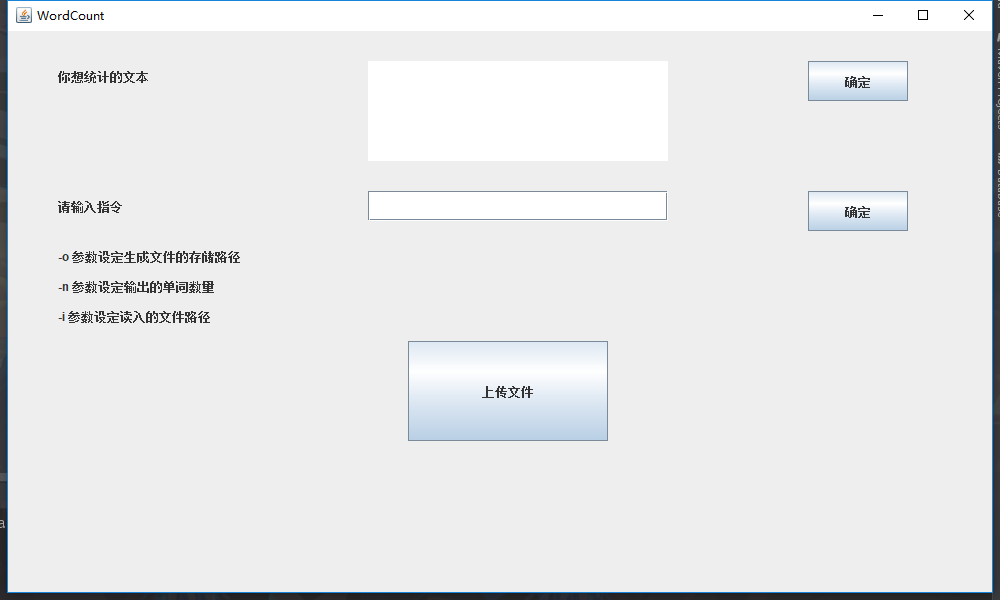
窗体设计
本来是不想用JAVA写窗体的,但是想了想还是写了。由于IDEA没有VS那么强大的可视化开发工具,一切都只能设置数据。所以窗体比较丑。。
(能用就行了嘛,要什么自行车~~)
这是主界面
测试手动输入文本
我们在文本区域手动输入这些然后点击确定

首先程序会在当前项目的根目录下生成一个名叫result_in.txt的本文文档,输出就在那里。
然后会生成一个窗体展示这些数据
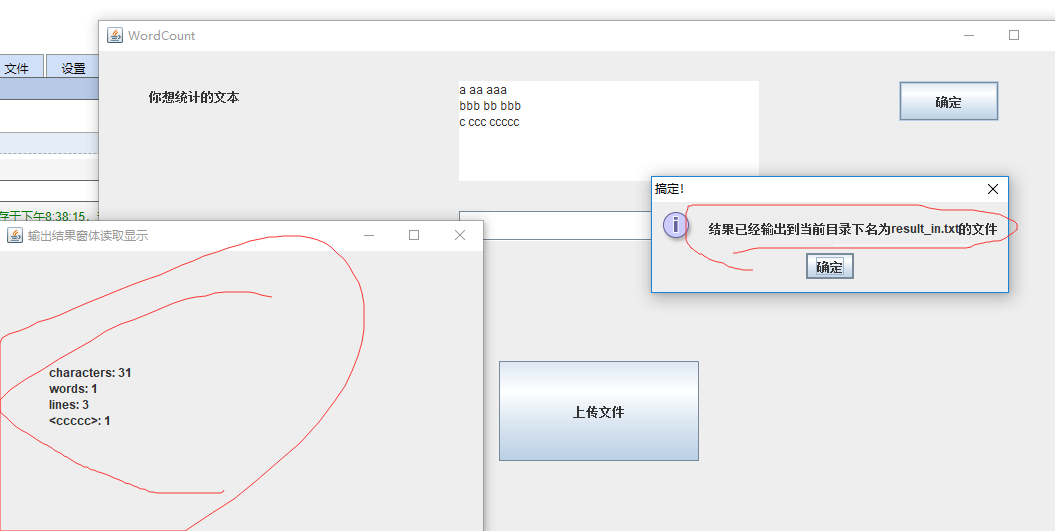
我们可以看到完全正确
看到输出里面每个单词被
<xmp></xmp>标签包围的原因是,在swing窗体输出的数据和前端一样 采用<html><body>标签包围 如果不加<xmp>标签,<单词>就会被解析
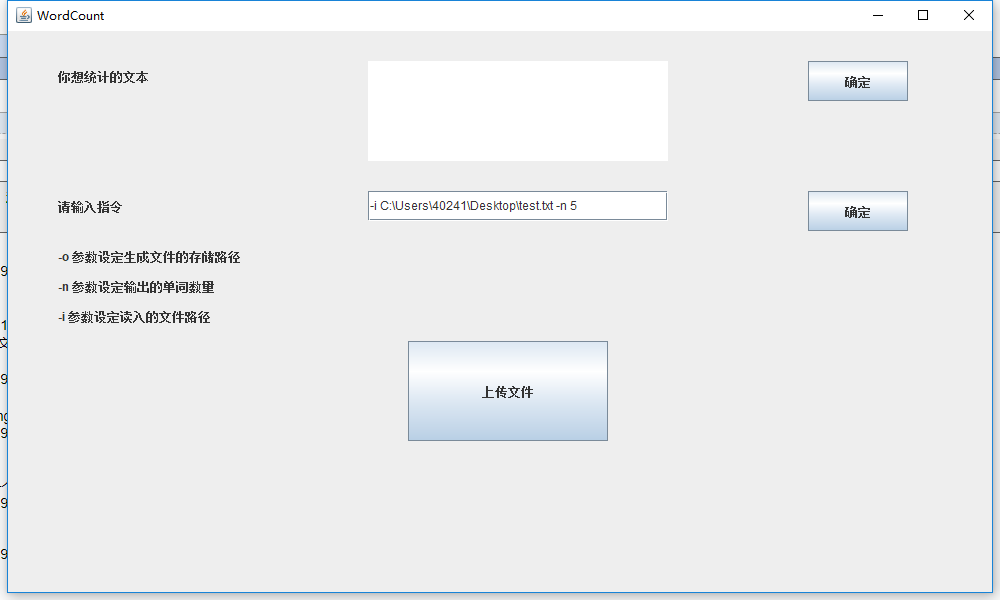
测试指令添加
这里需要说一下,如果直接复制地址黏贴可能会在你的url地址前多一个符号,这个时候就会报出以下错误
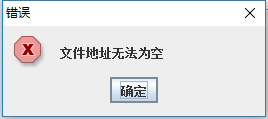
所以需要在-i指令后重新手动添加空格
现在我们来测试-i 和-n 指令的混合
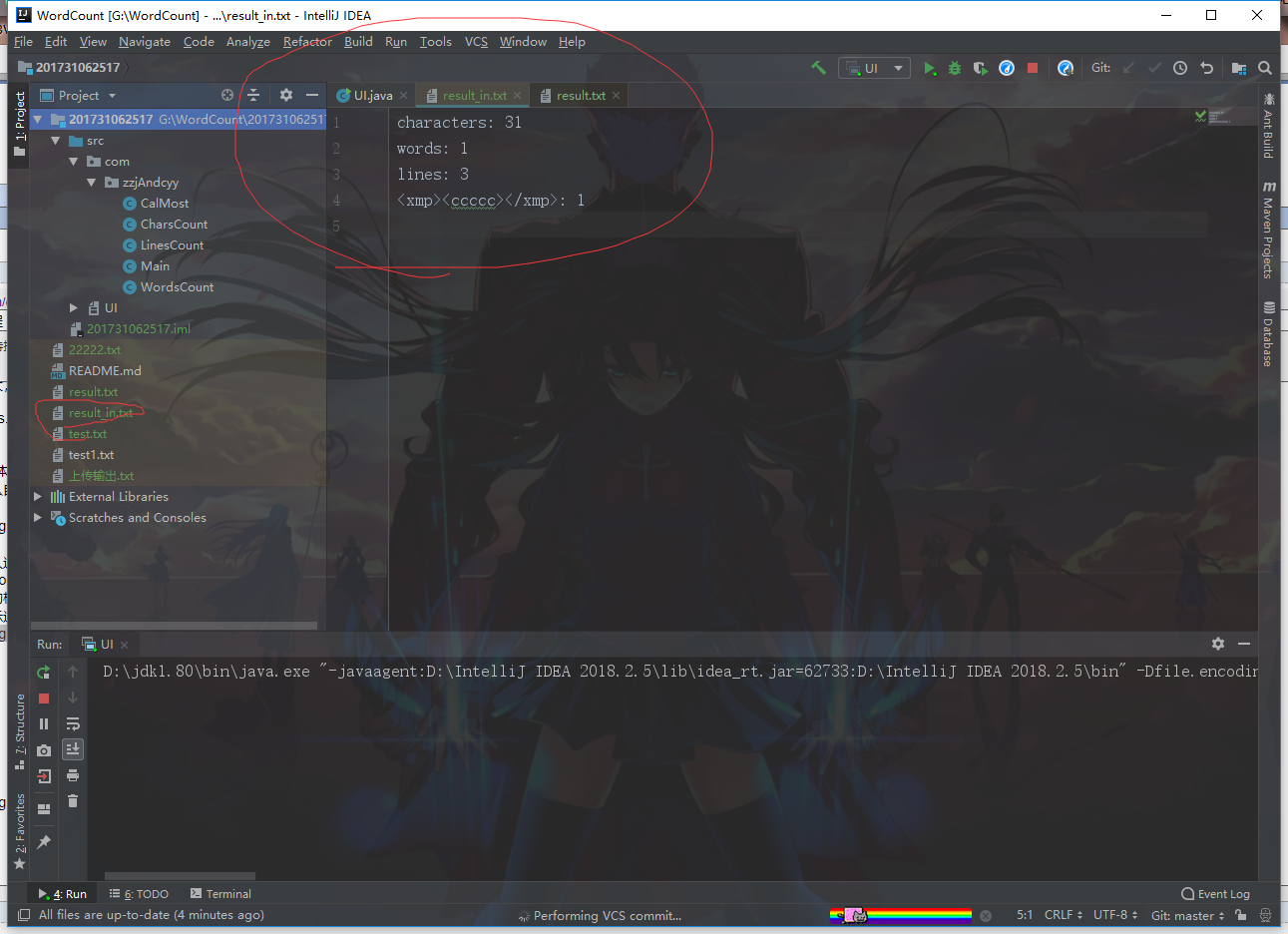
结果为

默认输出地址在项目目录下的result.txt文件中
测试上传文件
点击上传文件后,我们选择桌面的test.txt文件(12MB大小)
因为会把文件上传到项目下,再次上传就会弹窗
可以选择删除,或者换一个,重新测试。
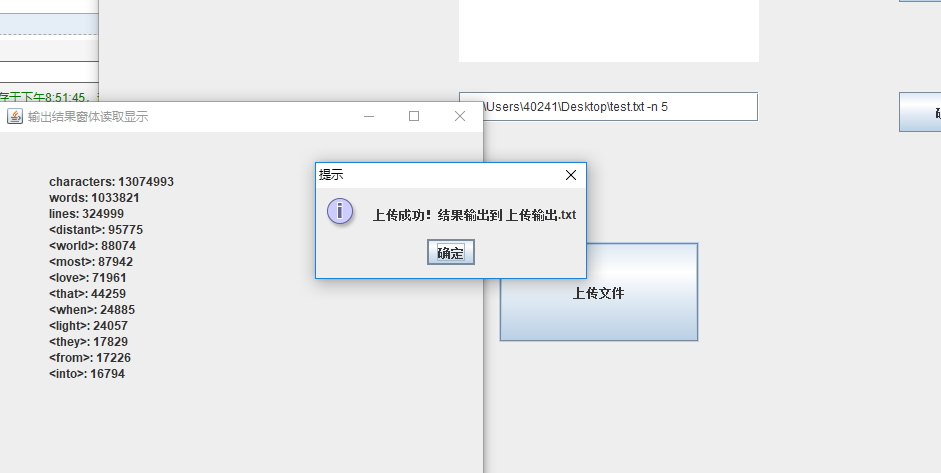
删除后刚上传的
六、单元测试
测试charsCount类

测试结果满足。
LinesCount类

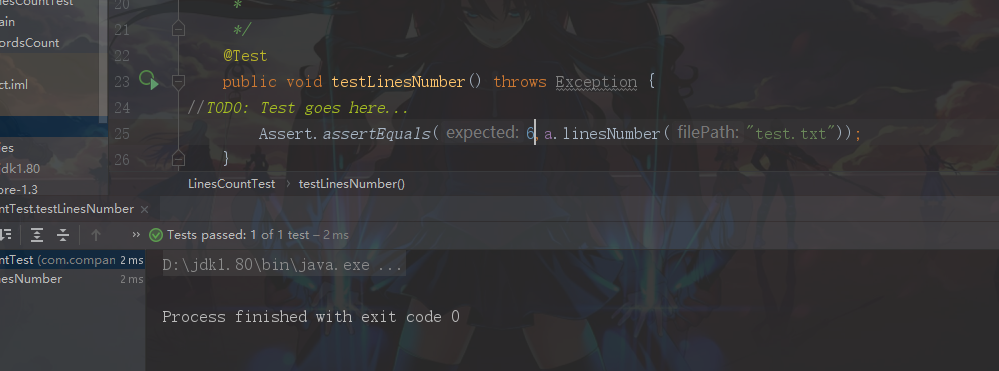
测试通过
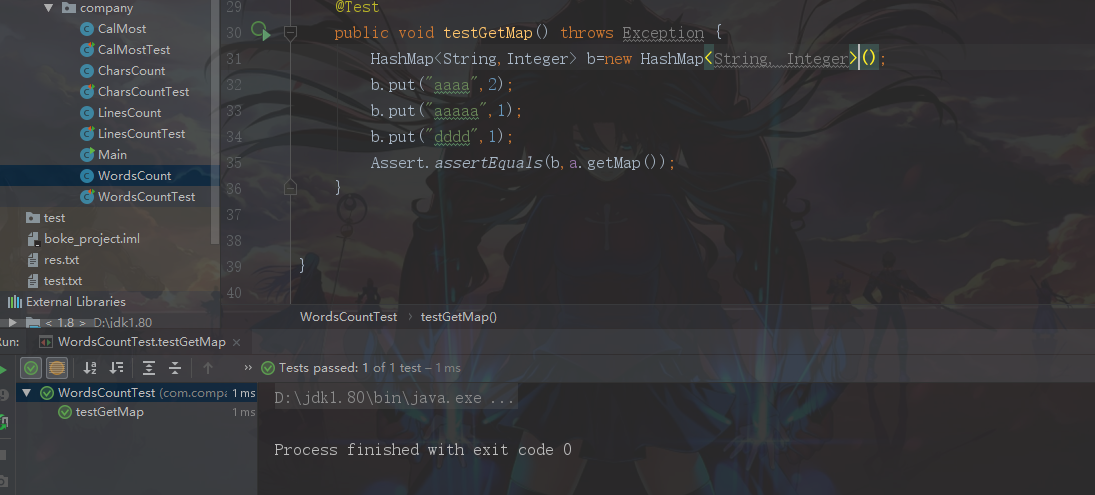
测试WordCount类
测试返回的Hashmap是否正确
测试返回的单词数是否正确
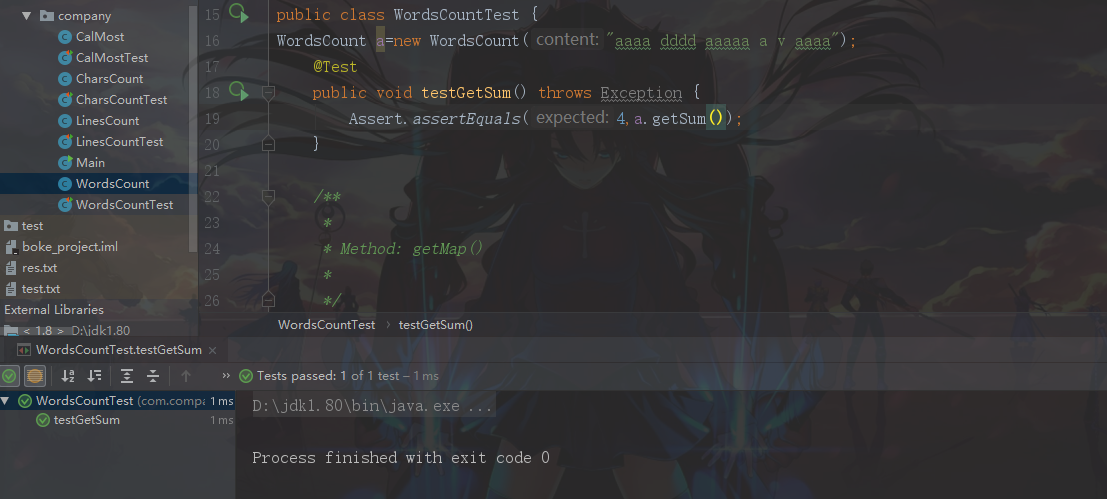
全部通过
七、总结
感觉结对编程对这种不是很大项目,效率反而会变慢。并且如果双方是学习新的知识,结对编程会综合双方的感受促进共同学习。并且结对编程如果编码规范和命名规范没有得到统一的话,速度会大大下降。正如这次作业,如果是个人来写速度肯定会快一些的。但是不可否认的是,结对编程能够更快发现自己以前没有注意到的错误,纠错能力有很大提升,这有利于后期的维护。并且在处理大量数据时,最好使用多线程进行操作,这次的项目在处理上千万的数据时,只是使用单线程,速度明显达不到预期。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号