树链剖分
树链剖分是一种对树进行划分的算法,它将树分为多条链,保证每个点只属于一条链,然后再通过数据结构(树状数组、BST、SPLAY、线段树等)来维护每一条链。
树链剖分可以用来解决如下问题:
1.将树从x到y结点最短路径上所有节点的值都加上z
2.求树从x到y结点最短路径上所有节点的值之和
3.将以x为根节点的子树内所有节点值都加上z
4.求以x为根节点的子树内所有节点值之和
树链剖分有以下几个概念:
重儿子:在该结点的儿子中,子树数量最多的结点(如果存在两个最大的,选其一即可)(叶子节点无重儿子)
轻儿子:在该结点的儿子中,除重儿子之外的结点
重边:结点和其重儿子连成的边
轻边:结点和其轻儿子连成的边
重链:多条重边连成的路径
轻链:多条轻边连成的路径
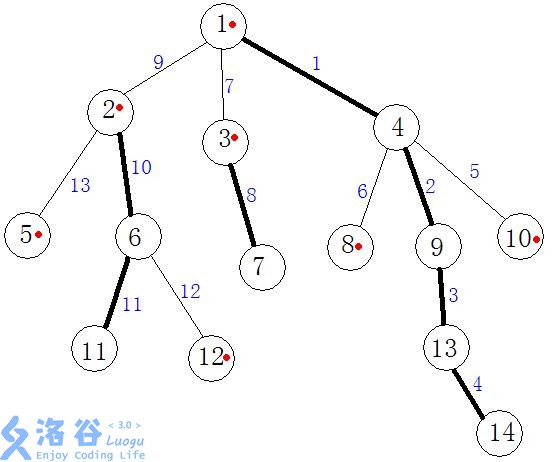
对于上图来说,1的重儿子是4,2的重儿子是6,3的重儿子是7,6的重儿子是11。
1->4->9->13->14,2->6->11,3->7是重链。
1->2->5,1->3,4->8,4->10,6->12是轻链。
怎么把树分成一条一条的链并用数据结构去维护?
1.在把所有点连成树后我们先计算出每个点的父亲结点、深度、子树数量、重儿子
2.完成第一步后我们将结点及其重儿子、重儿子的重儿子(重重儿子)、重重重儿子等等连成一条重链。通过这样的操作将树分成一条一条的重链
3.在重链上或重链与重链之间进行具体的操作
一二两步可以用两遍dfs来完成
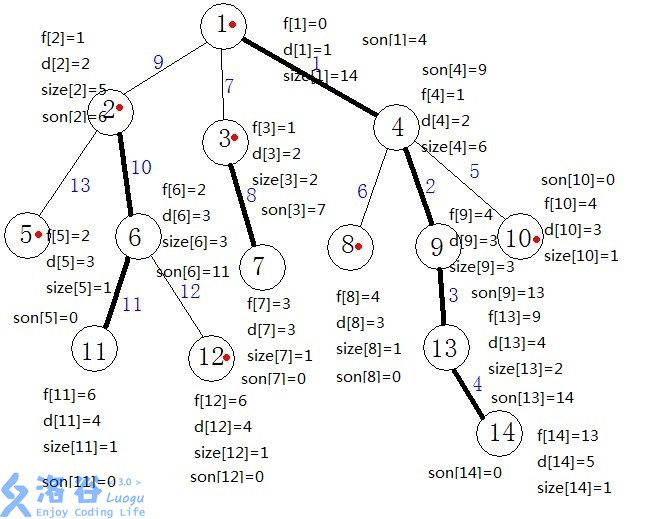
第一次遍dfs求出结点的子树数量,结点在树中的深度,结点的父亲结点,结点的重儿子。
int size[maxn],deep[maxn],fa[maxn],son[maxn]; //size 结点的子树数量 //deep 结点在树上的深度 //fa 结点的父亲 //son 结点的重儿子 void dfs1(int u,int f,int dep) {//第一次遍历,求size、deep、fa、son的值 size[u]=1; deep[u]=dep; fa[u]=f; for(int i=head[u];i;i=e[i].next) { int v=e[i].to;//u的儿子 if(v==fa[u])continue; dfs1(v,u,dep+1);//遍历儿子 //dfs1(v,u,dep+1)之后就可以得到v的子树数量 size[u]+=size[e[i].to]; if(size[e[i].to]>size[son[u]]) //如果v的子树数量大于u的原来重儿子的子树数量就把v当作u的重儿子,否则不改变 son[u]=e[i].to; } }
第一次dfs之后各个结点的情况(直接用别人的图,懒得改了,相信你们看得懂)
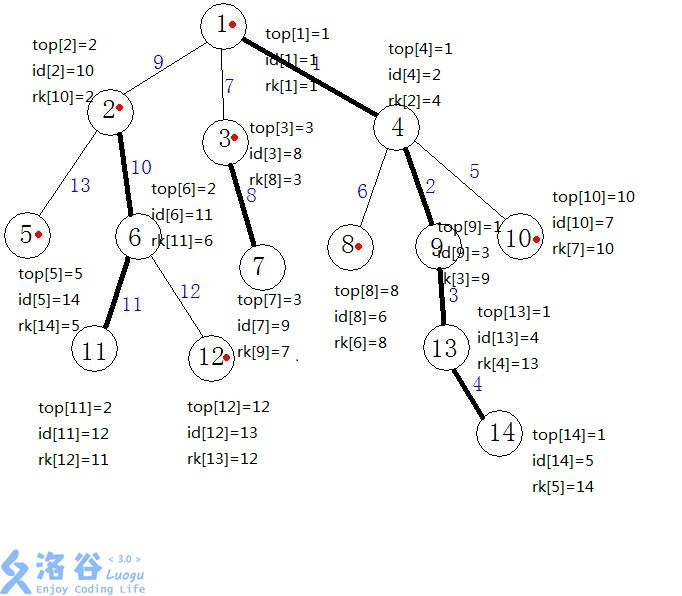
第二次dfs则是求出每个结点所在重链上的起始重儿子是谁,结点是第几次dfs到的(dfs序),dfs序对应的结点。
int tim,top[maxn],tid[maxn],rank[maxn]; //top 结点所在重链上的起始重儿子 //tid 结点的dfs序 //rank dfs序对应的结点 void dfs2(int u,int t) {//第二次遍历,求top、tid、rank的值 top[u]=t; tid[u]=++tim; rank[tim]=u; if(son[u]==-1)return ; dfs2(son[u],t);//将该点的重儿子、重儿子的重儿子、重儿子的重儿子的重儿子等等连成一条重链 for(int i=head[u];i;i=e[i].next) { int v=e[i].to; if(v!=fa[u]&&v!=son[u])//如果v不是u的重儿子就构造新的重链 dfs2(v,v); } }
第二次dfs之后每个结点的情况
两次dfs后我们根据第二次dfs求出的新编号建立线段树,其他的基本更新、查询不用变。
void build(int l,int r,int rt) { lazy[rt]=0; if(l==r) { sum[rt]=a[rank[l]];//根据dfs序来建树而不是sum[rt]=a[l] return ; } int mid=(l+r)/2; build(ls); build(rs); pushup(rt); }
因为dfs遍历后每条重链在线段树上是连续的,对于改变x到y最短路径上的值,我们只需将两个结点移动到同一重链上并更新每次移动。在每次移动中都是移动起始重儿子深度更深的结点。
将x到结点y最短路径上所有结点的值增加z。
假设x=7,y=13
我们先比较deep[top[7]]与deep[top[13]]的大小,7的更大,所以先更新区间(tid[top[7]],tid[7]),再令x=fa[top[7]],这时x就是结点1。
这时x=1,y=13,x和y便处于同一重链,我们进行最后一次更新,更新区间(tid[1],tid[13])。
void update1(int x,int y,int C) { while(top[x]!=top[y]) { if(deep[top[x]]<deep[top[y]])swap(x,y);//深度大的先修改 update(tid[top[x]],tid[x],C,1,N,1); x=fa[top[x]]; } if(deep[x]<deep[y])swap(x,y); update(tid[y],tid[x],C,1,N,1); }
由第二次dfs可知以x为根节点的子树中,所有结点的dfs序是连续的,所以对子树的修改只需修改区间(tid[x],tid[x]+size[x]-1)的值,也就是
update(tid[x],tid[x]+size[x]-1,c,1,n,1);
树链剖分有两个性质:
1.轻边(U,V),size(V)<=size(U)/2。
2.从根到某一点的路径上,不超过logN条轻边,不超过logN条重路径。
时间复杂度O(nlog2n)
#include<iostream> #include<stdio.h> using namespace std; #define ll long long #define maxn 100005 #define ls l,mid,rt<<1 #define rs mid+1,r,rt<<1|1 int N,M,R,P,cnt,head[maxn<<1]; struct edge{ int to,next; }e[maxn<<1]; void add(int x,int y) { e[++cnt].to=y; e[cnt].next=head[x]; head[x]=cnt; } int size[maxn],deep[maxn],fa[maxn],son[maxn]; void dfs1(int u,int f,int dep) { size[u]=1; deep[u]=dep; fa[u]=f; for(int i=head[u];i;i=e[i].next) { if(e[i].to==fa[u])continue; dfs1(e[i].to,u,dep+1); size[u]+=size[e[i].to]; if(size[e[i].to]>size[son[u]]) son[u]=e[i].to; } } int tim,top[maxn],tid[maxn],rank[maxn]; void dfs2(int u,int t) { top[u]=t; tid[u]=++tim; rank[tim]=u; if(son[u]==-1)return ; dfs2(son[u],t); for(int i=head[u];i;i=e[i].next) { if(e[i].to!=fa[u]&&e[i].to!=son[u]) dfs2(e[i].to,e[i].to); } } ll sum[maxn<<2],lazy[maxn<<2],a[maxn]; void pushup(int rt) { sum[rt]=(sum[rt<<1]+sum[rt<<1|1])%P; } void build(int l,int r,int rt) { if(l==r) { sum[rt]=a[rank[l]]%P; return ; } int mid=(l+r)/2; build(ls); build(rs); pushup(rt); } void pushdown(int rt,int ln,int rn) { if(lazy[rt]) { lazy[rt<<1]=(lazy[rt<<1]+lazy[rt])%P; lazy[rt<<1|1]=(lazy[rt<<1|1]+lazy[rt])%P; sum[rt<<1]=(sum[rt<<1]+lazy[rt]*ln%P)%P; sum[rt<<1|1]=(sum[rt<<1|1]+lazy[rt]*rn%P)%P; lazy[rt]=0; } } void update(int L,int R,int C,int l,int r,int rt) { if(L<=l&&R>=r) { sum[rt]+=C*(r-l+1); lazy[rt]+=C; return ; } int mid=(l+r)/2; pushdown(rt,mid-l+1,r-mid); if(L<=mid)update(L,R,C,l,mid,rt<<1); if(R>mid)update(L,R,C,mid+1,r,rt<<1|1); pushup(rt); } ll query(int L,int R,int l,int r,int rt) { if(L<=l&&R>=r)return sum[rt]; int mid=(l+r)/2; pushdown(rt,mid-l+1,r-mid); ll ans=0; if(L<=mid)ans=(ans+query(L,R,ls)%P)%P; if(R>mid)ans=(ans+query(L,R,rs)%P)%P; return ans%P; } void update1(int x,int y,int C) { while(top[x]!=top[y]) { if(deep[top[x]]<deep[top[y]])swap(x,y); update(tid[top[x]],tid[x],C,1,N,1); x=fa[top[x]]; } if(deep[x]<deep[y])swap(x,y); update(tid[y],tid[x],C,1,N,1); } ll query1(int x,int y) { int ans=0; while(top[x]!=top[y]) { if(deep[top[x]]<deep[top[y]])swap(x,y); ans=(ans+query(tid[top[x]],tid[x],1,N,1)%P)%P; x=fa[top[x]]; } if(deep[x]<deep[y])swap(x,y); ans+=query(tid[y],tid[x],1,N,1)%P; return ans%P; } int main() { scanf("%d%d%d%d",&N,&M,&R,&P); for(int i=0;i<=N;i++) son[i]=-1; for(int i=1;i<=N;i++) scanf("%lld",&a[i]); int x,y; for(int i=1;i<N;i++) { scanf("%d%d",&x,&y); add(x,y);add(y,x); } dfs1(R,0,1); dfs2(R,R); build(1,N,1); int op,z; for(int i=1;i<=M;i++) { scanf("%d",&op); if(op==1) { scanf("%d%d%d",&x,&y,&z); update1(x,y,z); } else if(op==2) { scanf("%d%d",&x,&y); printf("%lld\n",query1(x,y)); } else if(op==3) { scanf("%d%d",&x,&z); update(tid[x],tid[x]+size[x]-1,z,1,N,1); } else { scanf("%d",&x); printf("%lld\n",query(tid[x],tid[x]+size[x]-1,1,N,1)%P); } } return 0; }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号