

3 hadoop集群环境搭建
http://archive.apache.org/dist/
1目前为止

然后为了避免路由网络传输出现问题---->集群机器关闭防火墙
清空系统防火墙
iptables -L
iptables -F
保存防火墙配置
service iptables save
如果上述命令执行失败报出:The service command supports only basic LSB actions (start, stop, restart, try-restart, reload, force-reload, status). For other actions, please try to use systemctl.
解决方法:
systemctl stop firewalld 关闭防火墙
yum install iptables-services 安装或更新服务
再使用systemctl enable iptables 启动iptables
最后 systemctl start iptables 打开iptables
再执行service iptables save查看防火墙状态
firewall-cmd --state停止firewall
systemctl stop firewalld.service禁止firewall开机启动
systemctl disable firewalld.service临时关闭内核防火墙
setenforce 0
getenforce永久关闭内核防火墙
vim /etc/selinux/config
SELINUX=disabled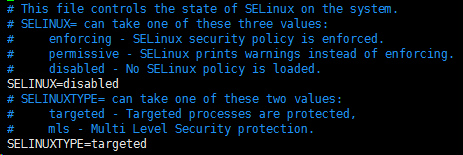
2解压
通过命令
tar -zxvf hadoop-2.6.5.tar.gz
3修改主机名
Execute in Master
-
vim /etc/sysconfig/network
NETWORKING=yes HOSTNAME=master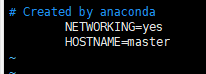
Execute in Slave1
-
vim /etc/sysconfig/network
NETWORKING=yes HOSTNAME=slave1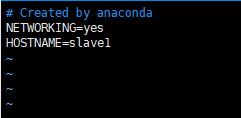
Execute in Slave2
-
vim /etc/sysconfig/network
NETWORKING=yes HOSTNAME=slave2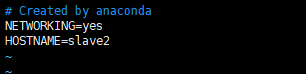
使用reboot命令重启服务器,即可看到hostname被修改了,(还有使用hostname newhostname命令可以临时命名)
5查看及修改IP地址
- vim /etc/sysconfig/network-scripts/ifcfg-ens33
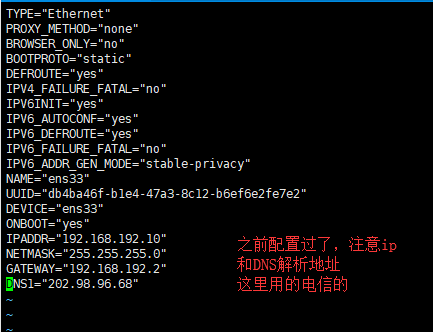
6修改主机文件
Execute in Master、Slave1、Slave2
- vim /etc/hosts
192.168.192.10 master
192.168.192.11 slave1
192.168.192.12 slave2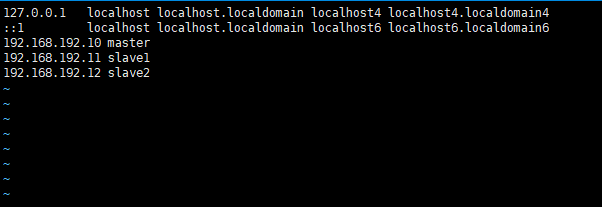
使用ping命令检测
7SSH互信配置
Execute in Master、Slave1、Slave2
生成密钥对(公钥和私钥)
ssh-keygen -t rsa三次回车生成密钥
- cat /root/.ssh/id_rsa.pub
可以查看到
Execute in Maste
将密匙输出到/root/.ssh/authorized_keys
cat /root/.ssh/id_rsa.pub > /root/.ssh/authorized_keys
chmod 600 /root/.ssh/authorized_keys追加密钥到Master
ssh slave1 cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
ssh slave2 cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys注意:这是需要操作及密码验证,追加完后查看一下该文件
- cat /root/.ssh/authorized_keys

复制密钥到从节点
scp /root/.ssh/authorized_keys root@slave1:/root/.ssh/authorized_keys
scp /root/.ssh/authorized_keys root@slave2:/root/.ssh/authorized_keys然后在使用上面的命令查看从节点是否有了该文件
8 修改hadoop配置文件(这时候有主从差别咯,先看master配置)
master
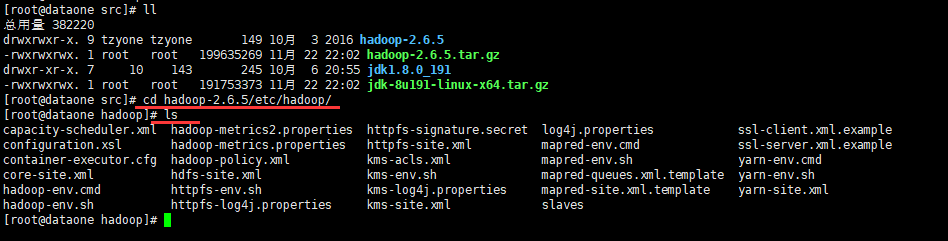
- cd hadoop-2.6.5/etc/hadoop/
- vim hadoop-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_191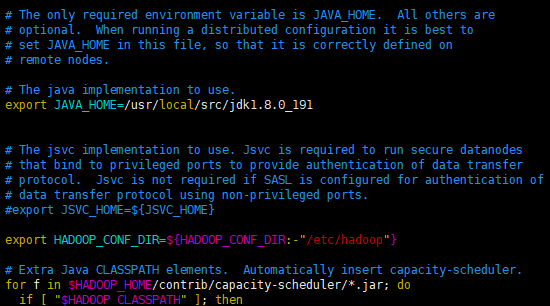
- vim yarn-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_191
- vim masters
master
- vim slaves
slave1
slave2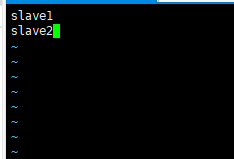
- vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop-2.6.5/tmp</value>
</property>
</configuration>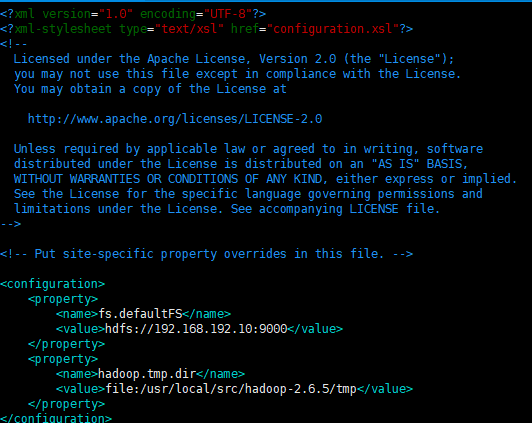
- vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop-2.6.5/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop-2.6.5/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
- vim mapred-site.xml.template
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
复制一下
-
cp mapred-site.xml.template mapred-site.xml

- vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
- 创建临时目录和文件目录
- mkdir /usr/local/src/hadoop-2.6.5/tmp
- mkdir -p /usr/local/src/hadoop-2.6.5/dfs/name
- mkdir -p /usr/local/src/hadoop-2.6.5/dfs/data
-
配置环境变量
Master、Slave1、Slave2
- vim ~/.bashrc
HADOOP_HOME=/usr/local/src/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin
-
刷新环境变量
source ~/.bashrc -
拷贝安装包
Master
scp -r /usr/local/src/hadoop-2.6.5 root@slave1:/usr/local/src/hadoop-2.6.5 scp -r /usr/local/src/hadoop-2.6.5 root@slave2:/usr/local/src/hadoop-2.6.5
9 启动集群
Master
初始化Namenode
hadoop namenode -format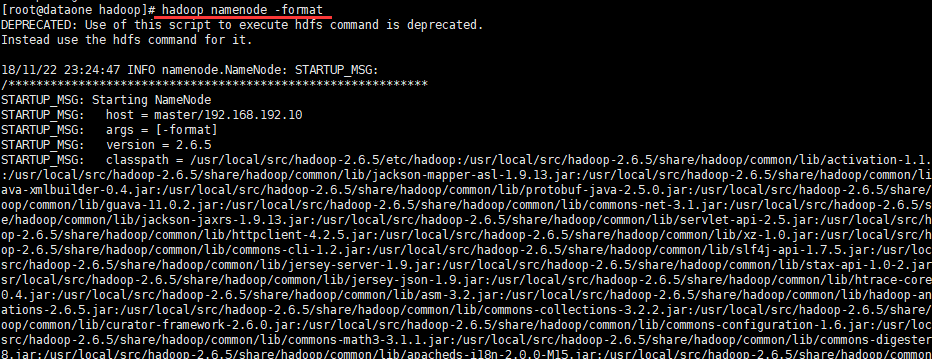
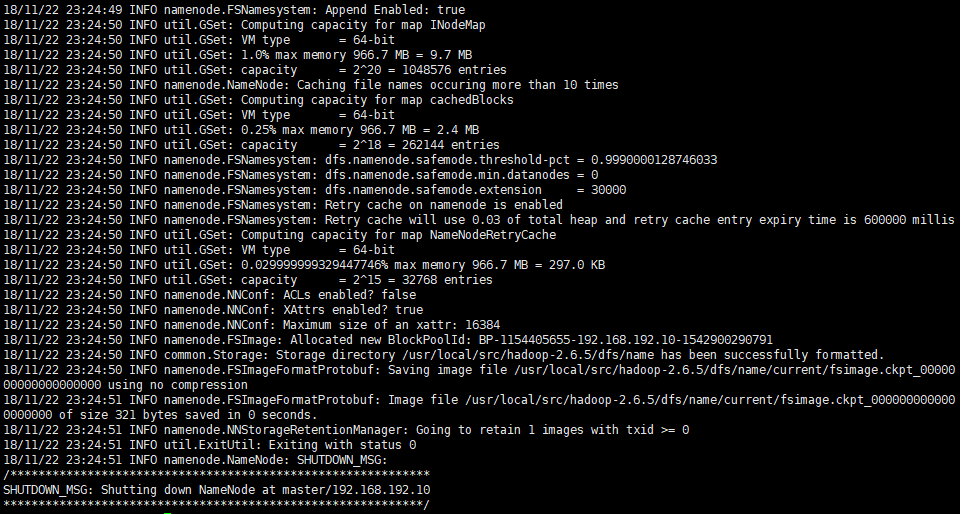
启动集群
在hadoop根目录
./sbin/start-all.sh
10 集群状态
jpsMaster
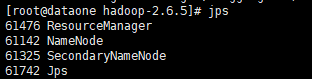
Slave1
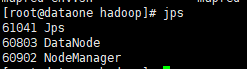
Slave2
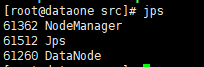
hadoop dfsadmin -report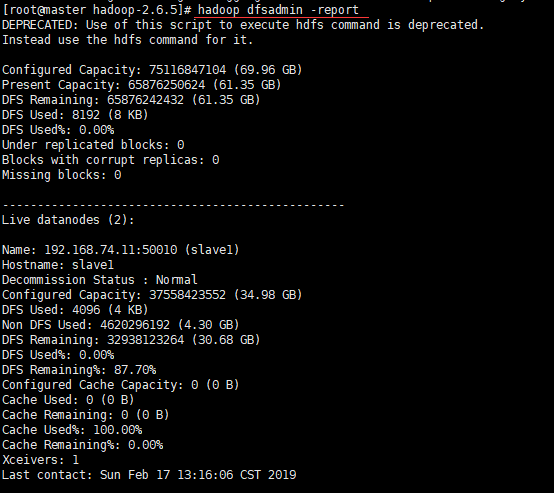
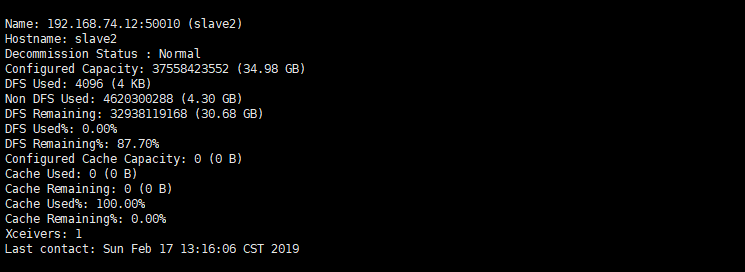
11 监控网页
http://master的ip:50070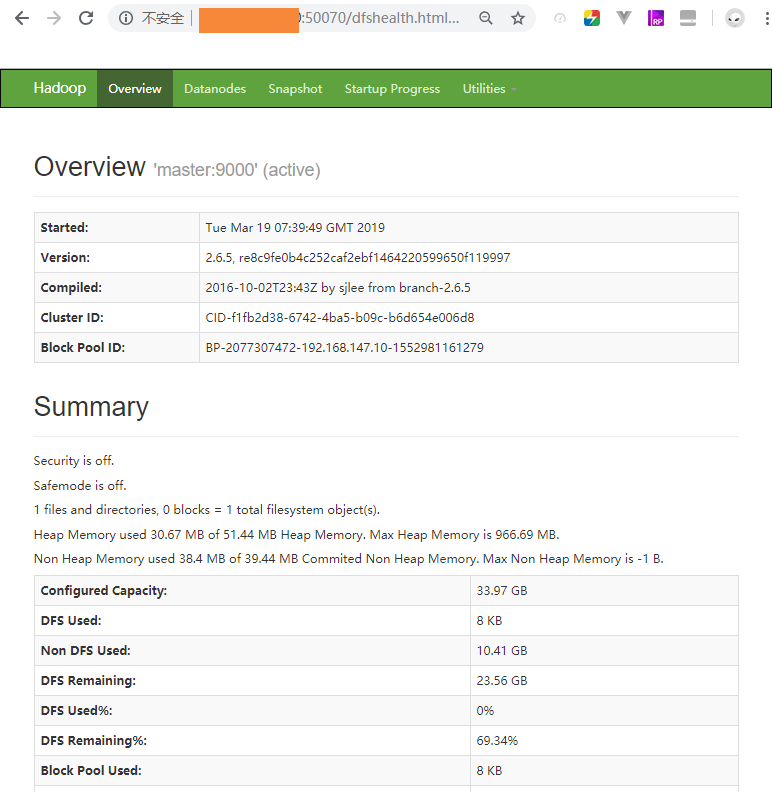
11 关闭集群
在hadoop根目录
./sbin/stop-all.sh