

4 HDFS概念及命令
1 HDFS基本思想
1.1 早期文件服务器
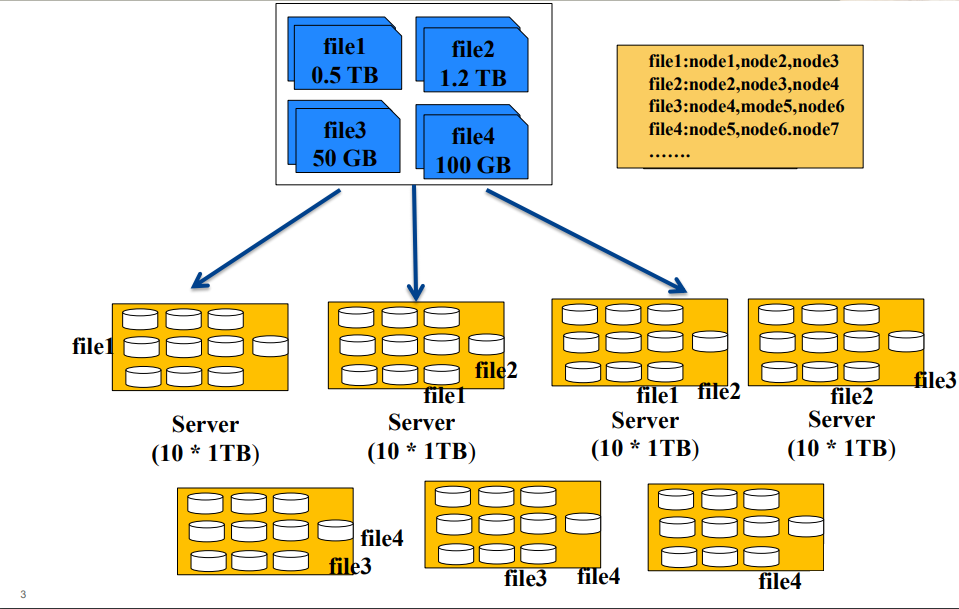
从上图中,我们可以看出,存储一个文件,我们一直往一个机子上面存是不够的,那么我们在储存量不够的时候就会加机子。
但是如果一个文件放在一台机子上,如果该机器挂了,那么文件就丢失了,不安全。
所以我们会把一个文件放在多台机子上,创建一个索引文件来储存文件的指针,如图中的file1存储在node1,node2,node3上面,以此类推。
- 缺点:
- 难以实现负载均衡
- 文件大小不同,负载均衡不易实现
- 用户自己控制文件大小
- 难以并行化处理
- 只能利用一个节点资源处理一个文件
- 无法动用集群资源处理同一个文件
- 难以实现负载均衡
1.2 HDFS文件服务器
为了解决上面的缺点HDFS诞生了。
从上图我们看出,HDFS是把一个大的数据,拆成很多个block块,然后在将block存储在各个机子上。
创建文件对应block的指针文件,和block对应的节点node的指针文件。

- 源自于Google的GFS论文
- 发表于2003年10月
- HDFS是GFS克隆版
- Hadoop Distributed File System
- 易于扩展的分布式文件系统
- 运行在大量普通廉价机器上,提供容错机制
- 为大量用户提供性能不错的文件存取服务
1.3 HDFS优缺点
- 优点
- 高容错性
- 数据自动保存多个副本
- 副本丢失后,自动恢复
- 适合批处理
- 移动计算而非数据
- 数据位置暴露给计算框架
- 适合大数据处理
- GB、TB、甚至PB级数据
- 百万规模以上的文件数量
- 10K+节点规模
- 流式文件访问
- 一次性写入,多次读取
- 保证数据一致性
- 可构建在廉价机器上
- 通过多副本提高可靠性
- 提供了容错和恢复机制
- 高容错性
- 缺点
- 低延迟数据访问
- 比如毫秒级
- 低延迟与高吞吐率
- 小文件存取
- 占用NameNode大量内存
- 寻道时间超过读取时间
- 并发写入、文件随机修改
- 一个文件只能有一个写者
- 仅支持append(追加)
- 低延迟数据访问
2 HDFS2.0架构
2.1 NameNode HA 和 NameNode Federation
- NameNode HA(High Availability,HA,高可用)
- 基于NFS共享存储解决方案
- 基于Bookeeper解决方案
- 基于Qurom Journal Manager(QJM)解决方案 -
NameNode Federation(联邦)
- 多个NameNode,每个分管一部分目录
- NameNode共用DataNode -
NameNode HA
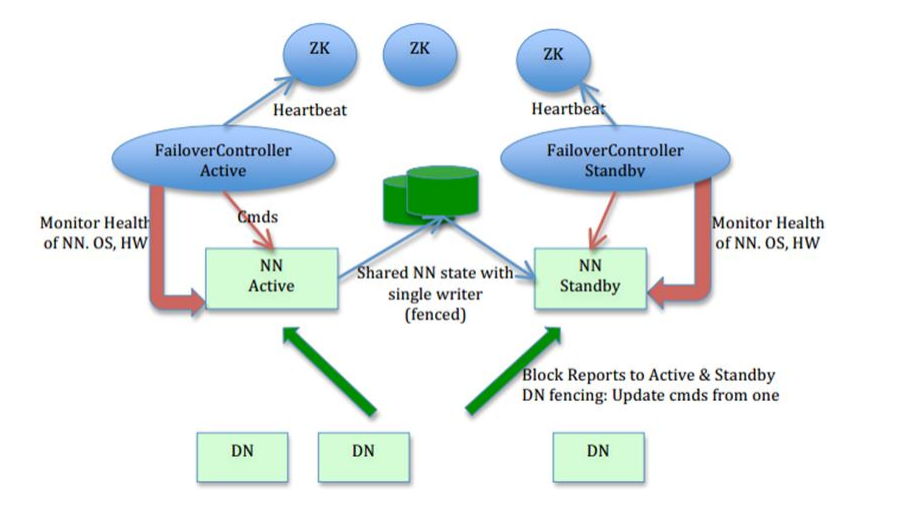
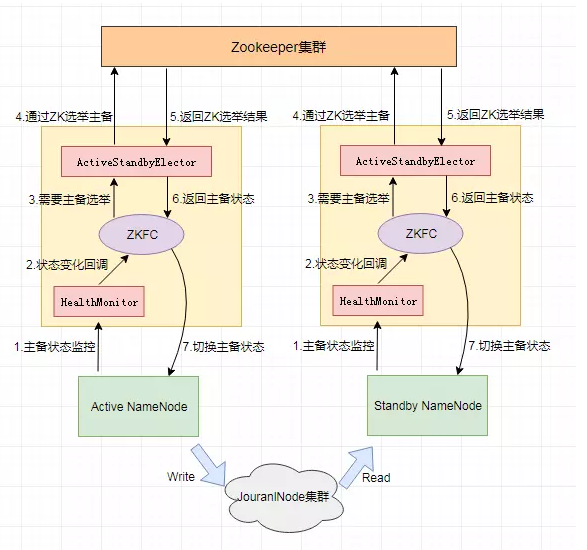
上图是一个主备切换方案图,我们可以看出active一但挂掉,那么FailoverController Standby就会从ZK上抢占一把锁,来让Standby切换为Active
- NameNode Federation
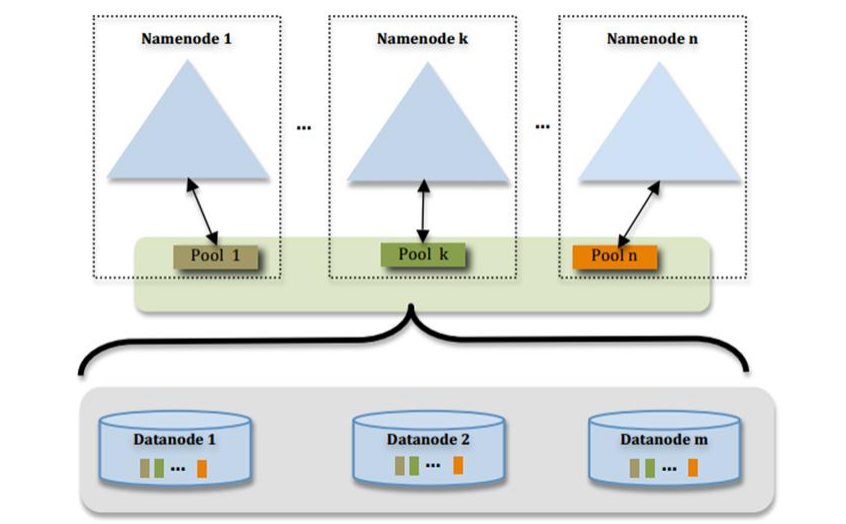
上图就是NN联邦,也就是多个NN(相互独立),图中可以看出每一个DN都存储了3个NN上的一部分数据,DN需要向每一个NN汇报
- NameNode HA + NameNode Federation
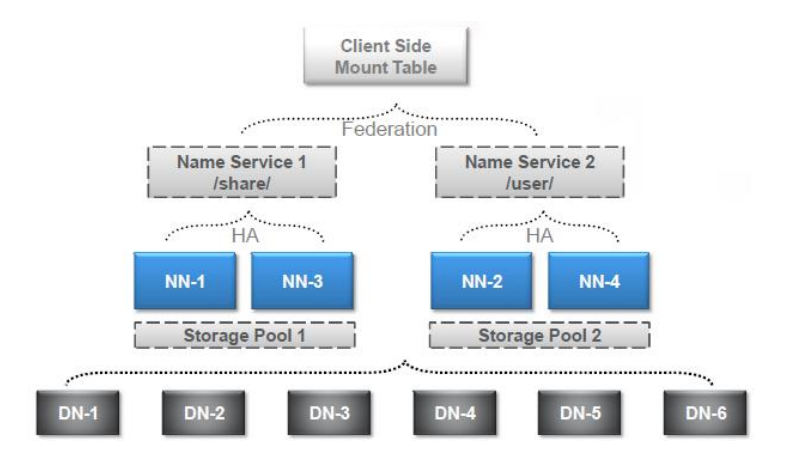
上图是一个集群,有很多个DN,这个集群上有两个对外提供服务的NN,分别是NN-1,NN-2
NN-3,NN-4为Standby_NN,对应NN-1,NN-2,解决主备切换
2套服务对应不同的HDFS目录,通过不同的目录就可以访问不同的NN,而这样如果多了会很不方便。
这个时候就可以通过Client side Mount Table来自动路由到我们需要的NN
1.2 各服务功能
- Active Namenode
- 主Master
- 管理HDFS的名称空间
- 管理数据块映射信息
- 配置副本策略
- 处理客户端读写请求
- Datanode
- Slave
- 存储实际的数据块
- 执行数据块读/写
- Client
- 文件切分
- 与NameNode交互,获取文件位置信息
- 与DataNode交互,读取或者写入数据
- 管理HDFS
- 访问HDFS
- Standby NameNode
- NameNode的热备
- 当Active NameNode出现故障时,快速切换为新的Active NameNode
- 定期合并fsimage和fsedits,推送给NameNode
- NameNode两个重要文件
- fsimage:元数据镜像文件(保存文件系统的目录树)
- edits:元数据操作日志(针对目录树的修改操作),被写入共享存储系统中 ,比如NFS、JournalNode
- 元数据镜像
- 内存中保存一份最新的
- 内存中的镜像(新)=磁盘上的fsimage(老)+edits(更新的操作日志)
- 合并fsimage与edits
- Edits文件过大将导致NameNode重启速度慢
- Standby Namenode负责定期合并它们
- 数据块映射关系
- 文件与数据块映射关系
- DataNode与数据块映射关系
- 保存映射关系占用较多内存
- NameNode启动时,可通过心跳信息重构映射关系
- DataNode运行过程中定时汇报当前block信息
- NameNode重启速度慢(不配置HA)
- 合并fsimage与edits文件,生成最新的目录树
- 接收DataNode的块信息
- 文件被切分成固定大小的数据块
- 默认数据块大小为64MB
- 可配置
- 为何数据块如此之大
- 数据传输时间超过寻道时间(高吞吐率)
- 一个文件存储方式
- 按大小被切分成若干个block,存储到不同节点上
- 默认情况下每个block有三个副本
3 工作原理
3.1 HDFS文件写入流程

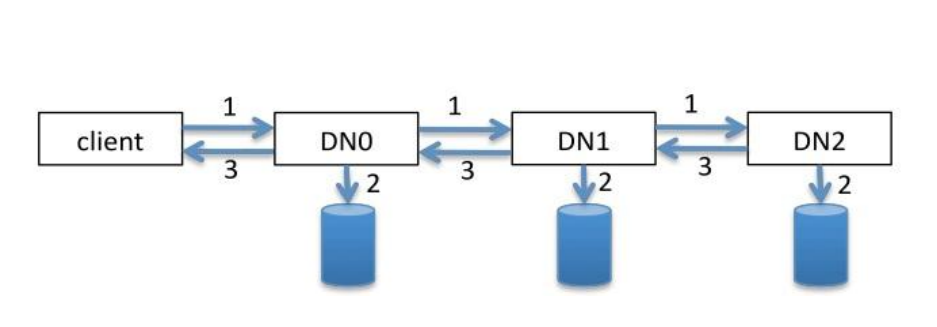
大概的流程是,客户端发送一个写入请求,取NN上领取3个DN指向,然后往DN1写入bloak,然后DN1负责写入DN2,DN2负责写入DN3
像流水线一样写入完成后,会反返回一个ack的包,关闭资源,在修改NN上的指针文件。
3.2 HDFS文件读取流程
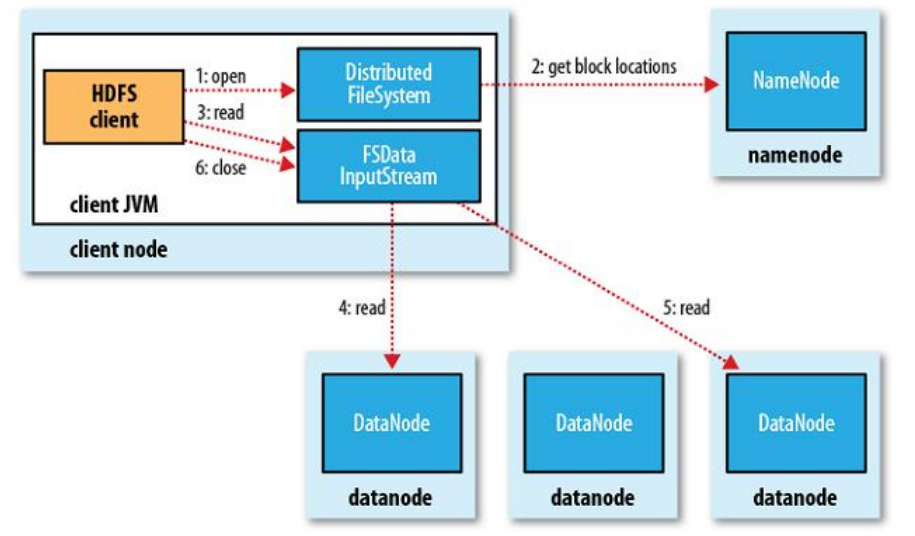
大概的流程是,客户端发送一个读取请求,先去NN上获取对应的DN指向,然后依次读取每个DN上的block文件,读一次返回一次,最后关闭
3.3 HDFS物理网络环境
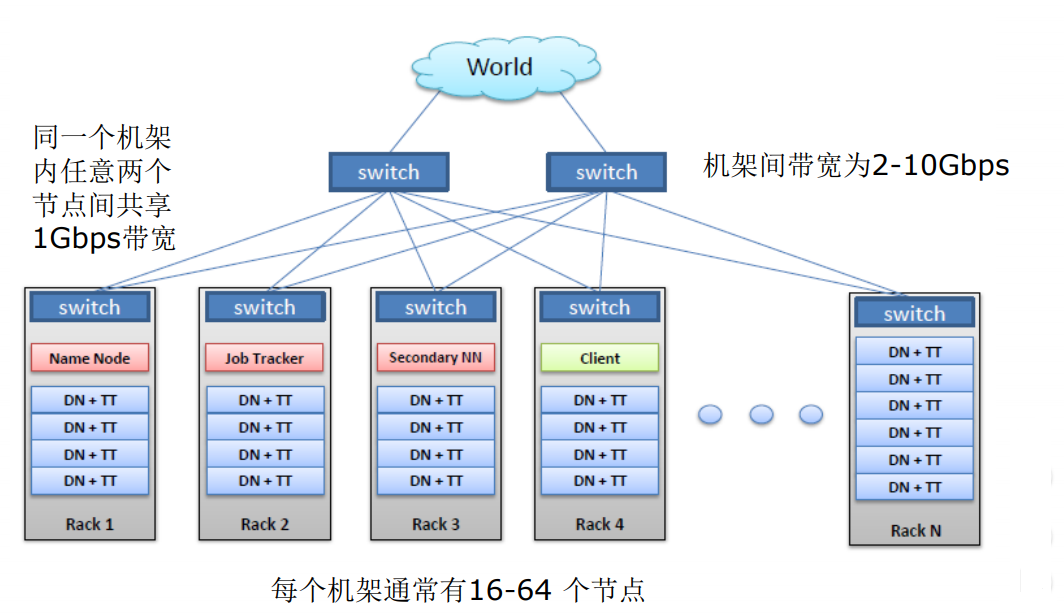
比较重要服务功能最好能部署在不同的节点上,如:NN,不重要的可以在一个节点上,如:DN。
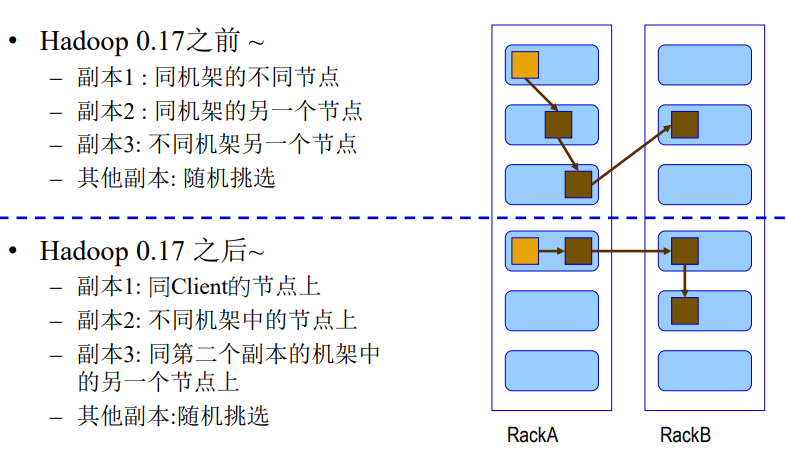
3.4 HDFS副本放置策略
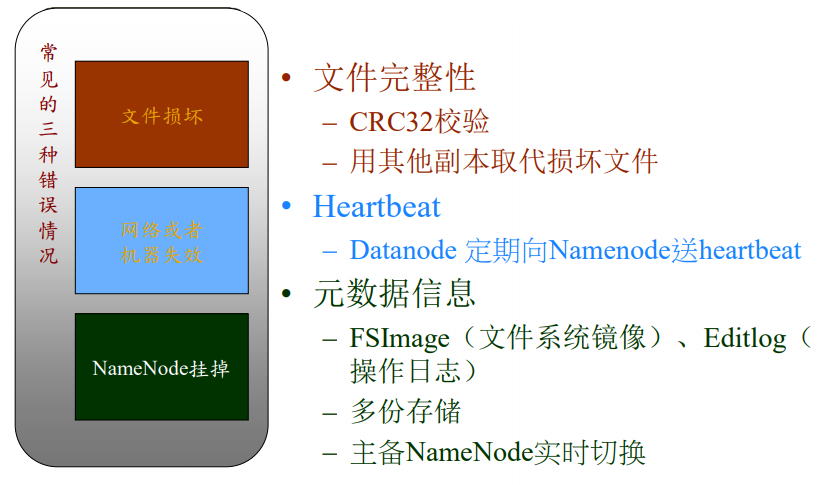
3.5 HDFS可靠性机制
4 HDFS如何与其他系统结合
- HDFS与MapReduce结合
- MapReduce作业的输入数据来自HDFS
- HDFS分块存储数据
- 默认每个Map Task处理一个数据块
- MapReduce作业的最终结果写入HDFS
- 确保数据安全可靠
- 可作为下一个作业的输入
- MapReduce与HDFS关系
- 低耦合,MapReduce可以与其他分布式文件系统结合;
- HDFS之上可以是其他计算框架
- MapReduce作业的输入数据来自HDFS
- HDFS与Hbase结合
- Hbase中的文件
- 操作日志文件WAL
- 数据索引文件HFile(storefile)
- HDFS为Hbase提供可靠的数据存放服务
- 数据三副本,安全可靠
- HDFS为Hbase提供数据共享服务
- Hbase不同服务可从HDFS上存取数据
- Hbase中的文件
- HDFS与开源日志系统结合
- Flume:http://flume.apache.org/
- Scribe:https://github.com/facebook/scribe
- Kafka:http://kafka.apache.org/
5 HDFS常用命令(集群50070端口就是hdfs)
-help:输出这个命令参数。如:hadoop fs -help ls (输出ls命令的参数)-ls:显示目录信息。如:hadoop fs -ls / (查询hdfs上根目录的目录,,递归创建加 -R参数)-mkdir:在hdfs上创建目录。如:hadoop fs -mkdir /haha (根目录下创建haha文件夹,递归创建加 -p参数)-moveFromLocal:从本地剪切粘贴到hdfs。如:hadoop fs -moveFromLocal /haha/xixi.txt / (将本地haha文件夹下的xixi.txt文件剪切粘贴到hdfs的根目录下)-copyFromLocal:从本地拷贝到hdfs上。如:用法同上-copyToLocal:从hdfs上拷贝到本地。如:用法同上-cp:从hdfs的一个路径拷贝到hdfs的另一个路径。如:方法同上-mv:从hdfs上的一个路径移动到hdfs的另一个路径。如:方法同上-appendToFile:追加一个文件到已经存在的文件末尾。如:hadoop fs -appendToFile /haha/lala.txt /xixi.txt (将本地lala.txt文件内容追加到hdfs上xixi.txt里)-cat:显示文件内容。如:hadoop fs -cat /xixi.txt (查看xixi.txt)-tail:显示一个文件的末尾。-chmod:修改文件权限。如:hadoop fs -chmod 777 /xixi.txt (修改xixi.txt文件的权限)-get:等同于copyToLocal,就是从hdfs下载文件到本地。如:hadoop fs -get /xixi.txt ./ (下载到当前本地路径)-getmerge:合并下载多个文件,如:hadoop fs -getmerge /log/*.txt ./sum.txt (将hdfs上log文件夹下的所有.txt文件整合在一起,下载到本地,名字为sum.txt)-put:等同于copyFromLocal,就是上传文件到hdfs。如:hadoop fs -put /xixi.txt / (上传到hdfs的根路径)-rmr:删除文件或目录-df:统计文件系统的可用空间信息。如:hadoop fs -df -h /-du:统计文件夹的大小信息。如:-s总大小、-h单位-count:统计一个指定目录下的文件节点数。如:结果2 2 199 (第一个参数说的是最多有几级目录,第二个参数说的是一共有多少文件)
- hadoop1.0杀死任务的方式
- hadoop job -kill 任务进程号
- hadoop2.0杀死任务的方式
- yarn application -kill 任务进程号
