7 MapReduce案例
1 java编程步骤
- 导入需要jar包
- 找到一个模板例子复制为我们的word count类
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
//制定生成jar的对应类
job.setJarByClass(WordCount.class);
//指定本业务job要使用的mapper/reducer业务类
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setReducerClass(WordCount.IntSumReducer.class);
//指定合成器使用类
job.setCombinerClass(WordCount.IntSumReducer.class);
//指定最终输出的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn去运行
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
/**
* Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN, VALUEIN和mapper输出的KEYOUT, VALUEOUT类型对应
* KEYOUT, VALUEOUT 是单词和单词出现总次数
*/
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
/**
* 如:Hello 1 World 1 Hello 1
* 入参key就是对上述结果排序后,一组同样的kv对的key
*/
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
/**
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN:默认情况下,是mr框架所读到的一行文本的起始偏移量-Long
* 但是在hadoop中有自己的更为精简的序列化接口,所以不直接使用Long,而用LongWritable
* <p>
* VALUEIN:默认情况下,是mr框架所读取到的一行文本内容,String,同上用Text
* KEYOUT:是用户自定义逻辑处理完成后输出的Key,此处是单词,String,同上用Text
* VALUEOUT:是用户自定义逻辑处理完成后输出的Value,此处是单词出现次数,Integer,同上用IntWritable
*/
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
//给每个单词赋值-如:Hello 1 World 1 Hello 1
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//StringTokenizer(str, " \t\n\r\f", false);会根据\t\n\r\f分成迭代数组
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
//设置单词
this.word.set(itr.nextToken());
//设置单词,和出现次数1
context.write(this.word, one);
}
}
}
}- 导出项目为jar包

- 创建测试文件aa.txt
hello world hello
hello java python
hello python
hello java- 测试

2 python编程步骤
- 创建测试文件aa.txt
hello world hello
hello java python
hello python
hello java- 编写mymap.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
'''
通过标准输入读入每一行数据,用空格分隔划分出每一个词,
给每一个词做一个出现1词的标记
'''
for line in sys.stdin:
ss = line.strip().split(' ')
for word in ss:
print('\t'.join([word.strip(),'1']))- 编写myred.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
cur_word = None
sum = 0
for line in sys.stdin:
'''
通过标准输入读入每一个词的,以制表符分隔
'''
ss = line.strip().split('\t')
if len(ss) != 2:
continue
word,count = ss
'''
统计每一个词的出现次数
'''
if cur_word == None:
cur_word = word
if cur_word != word:
print('\t'.join([cur_word,str(sum)]))
cur_word = word
sum = 0
sum += int(count)
print('\t'.join([cur_word,str(sum)]))- windows下测试
type aa.txttype aa.txt | python mymap.pytype aa.txt | python mymap.py | sorttype aa.txt | python mymap.py | sort | python myred.py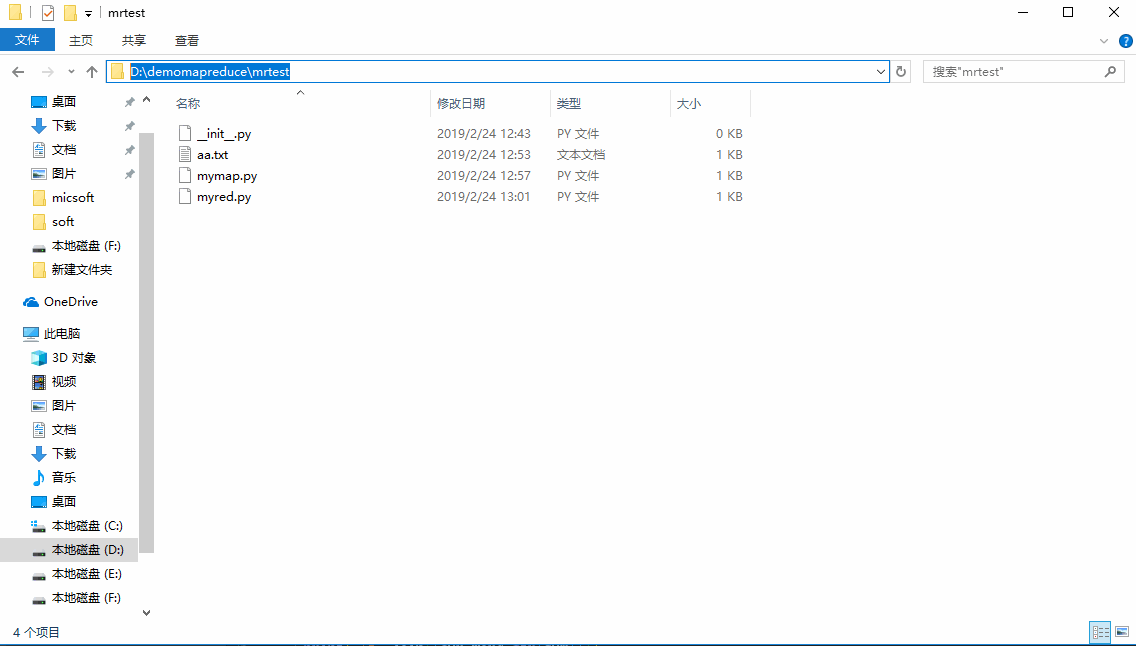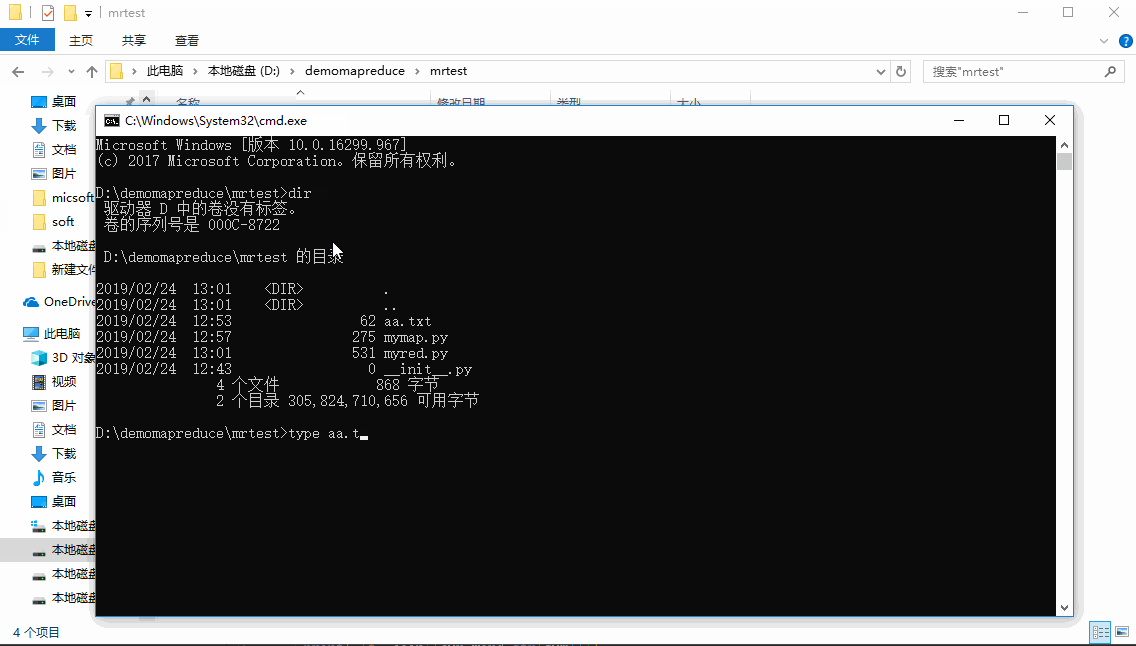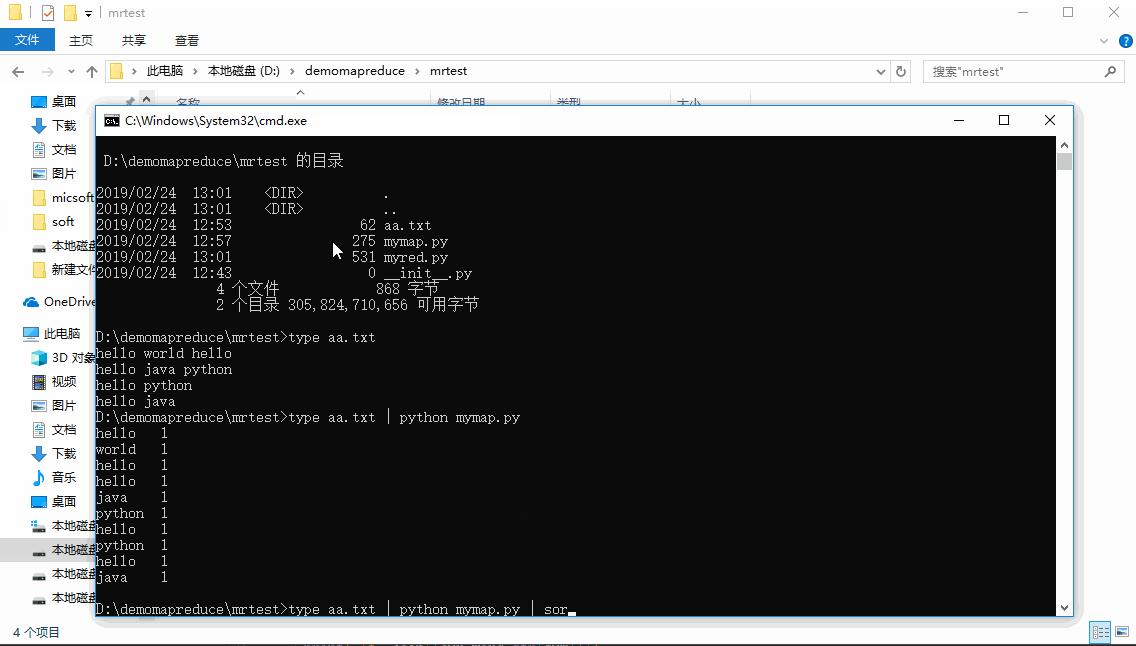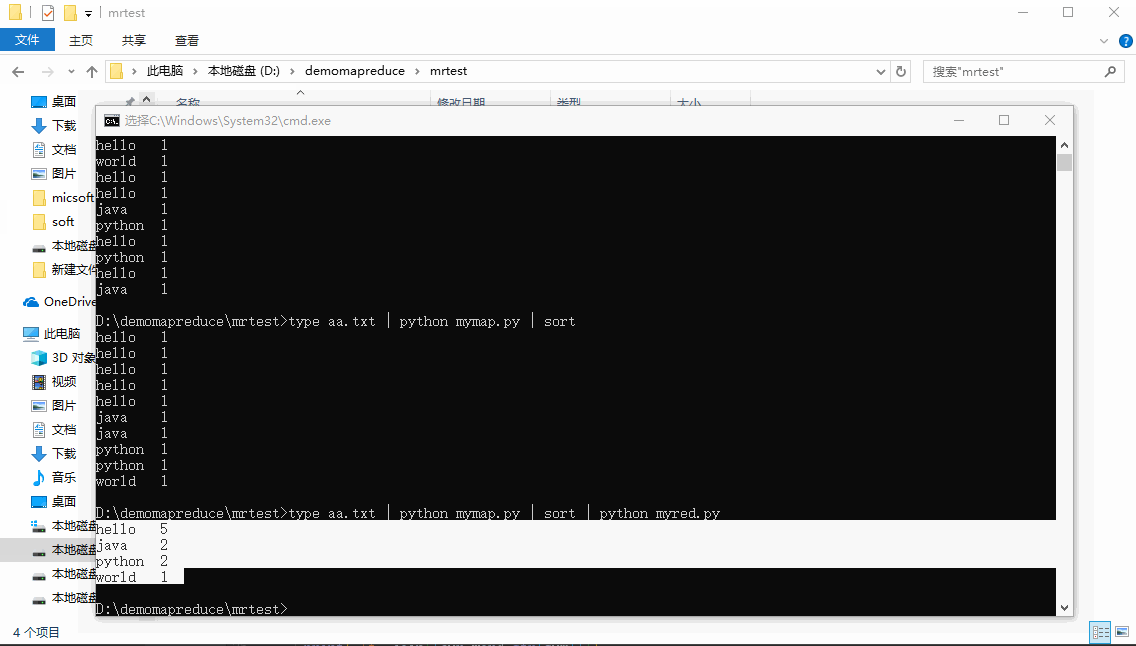
- linux下测试
cat aa.txtcat aa.txt | python mymap.pycat aa.txt | python mymap.py | sortcat aa.txt | python mymap.py | sort | python myred.py
- 集群测试
- 需要streaming来提交我们的作业

- 编写run.sh脚本
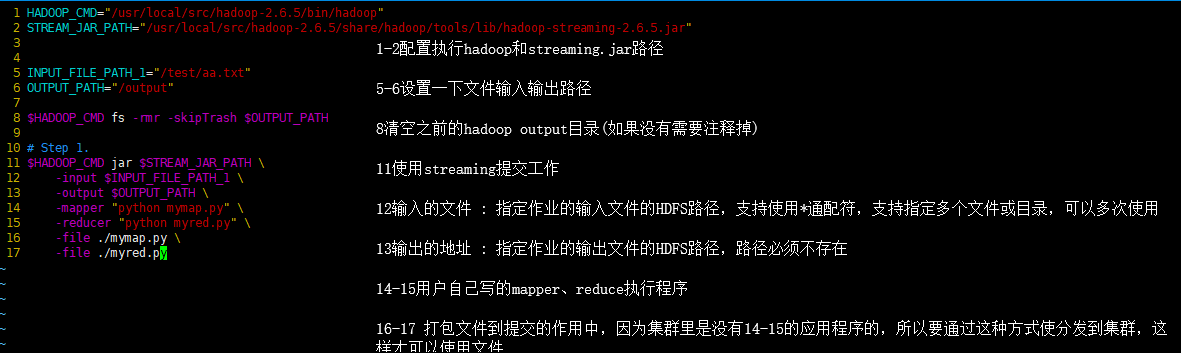
HADOOP_CMD="/usr/local/src/hadoop-2.6.5/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar"
INPUT_FILE_PATH_1="/test/aa.txt"
OUTPUT_PATH="/output"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_1 \
-output $OUTPUT_PATH \
-mapper "python mymap.py" \
-reducer "python myred.py" \
-file ./mymap.py \
-file ./myred.py
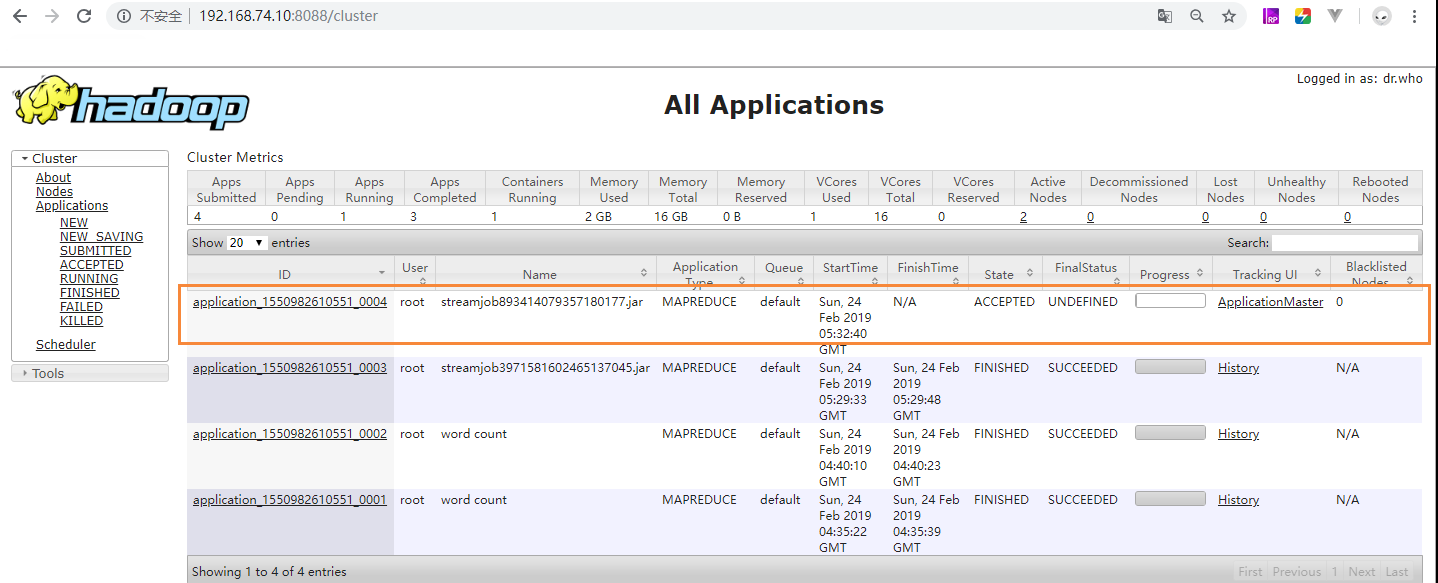
还可以通过8088端口进行任务查看,日志查看
3 demo
- 准备aa.txt数据
2 hello
4 hello
6 hello
8 hello
10 hello
12 hello
14 hello
16 hello
18 hello
20 hello
22 hello
24 hello- 准备bb.txt数据
1 hello
3 hello
5 hello
7 hello
9 hello
11 hello
13 hello
15 hello
17 hello
19 hello
21 hello
23 hello- 一起查看
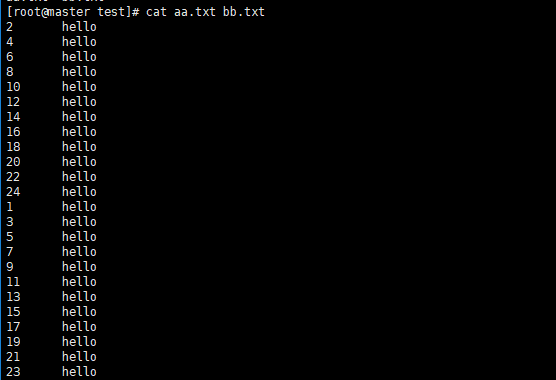
- 排序查看
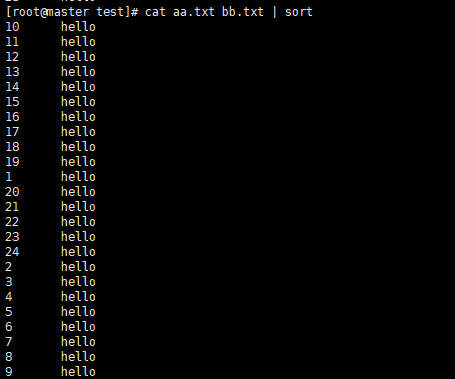
- 指定数字排序查看
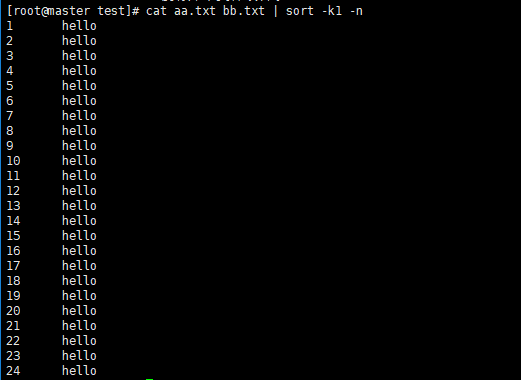
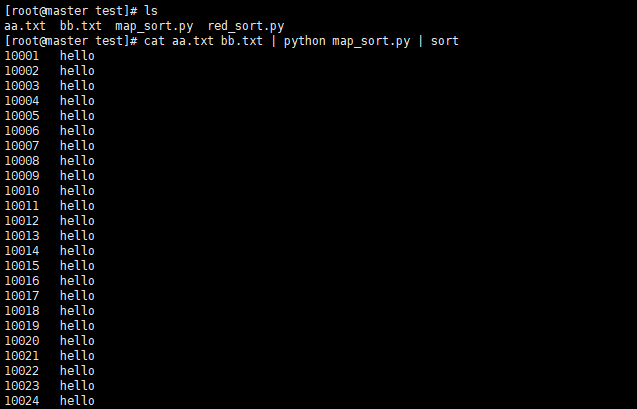
3.1 案例解决多文件排序问题
- map_sort.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
#mapper利用基数+key对齐key,这样如果在利用单个reducer就可以利用框架对key进行排序
base_count = 10000
for line in sys.stdin:
ss = line.strip().split('\t')
key = ss[0]
val = ss[1]
new_key = base_count + int(key)
print("%s\t%s" % (new_key, val))- red_sort.py
#!/usr/local/bin/python
# -*- coding: utf-8 -*-
import sys
#reduce利用 key - 基数 还原key
base_value = 10000
for line in sys.stdin:
key, val = line.strip().split('\t')
print(str(int(key) - base_value) + "\t" + val)- linux测试
cat aa.txt bb.txt | python map_sort.py | sort
cat aa.txt bb.txt | python map_sort.py | sort | python red_sort.py
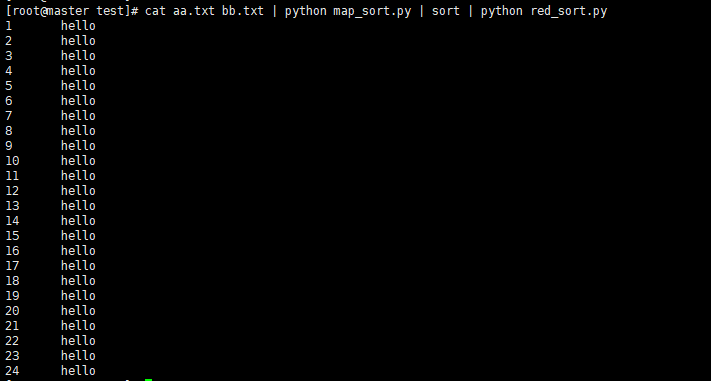
-集群测试
- 编写run.sh
set -e -x
HADOOP_CMD="/usr/local/src/hadoop-2.6.5/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar"
INPUT_FILE_PATH_A="/aa.txt"
INPUT_FILE_PATH_B="/bb.txt"
OUTPUT_SORT_PATH="/output_sort"
# $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_SORT_PATH
# Step jobconf只使用一个reduce,input2个文件用逗号隔开
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_A,$INPUT_FILE_PATH_B\
-output $OUTPUT_SORT_PATH \
-mapper "python map_sort.py" \
-reducer "python red_sort.py" \
-jobconf "mapred.reduce.tasks=1" \
-file ./map_sort.py \
-file ./red_sort.py \
3.2 单reduce编程
- map_sort.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
#利用配置来做单reduce,因为Demo3.1中base_count到底取多少我们并没有一个好的数字。
for line in sys.stdin:
ss = line.strip().split('\t')
key = ss[0]
val = ss[1]
print("%s\t%s" % (key, val))- red_sort.py
#!/usr/local/bin/python
# -*- coding: utf-8 -*-
import sys
for line in sys.stdin:
print(line.strip())- run.sh
set -e -x
HADOOP_CMD="/usr/local/src/hadoop-2.6.5/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar"
INPUT_FILE_PATH_A="/aa.txt"
INPUT_FILE_PATH_B="/bb.txt"
OUTPUT_SORT_PATH="/output_sort"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_SORT_PATH
# Step .
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_A,$INPUT_FILE_PATH_B\
-output $OUTPUT_SORT_PATH \
-mapper "python map_sort.py" \
-reducer "python red_sort.py" \
-file ./map_sort.py \
-file ./red_sort.py \
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner \
-jobconf mapred.output.key.comparator.class=org.apache.hadoop.mapred.lib.KeyFieldBasedComparator \
-jobconf stream.num.map.output.key.fields=1 \
-jobconf mapred.text.key.partitioner.options="-k1,1" \
-jobconf mapred.text.key.comparator.options="-k1,1n" \
-jobconf mapred.reduce.tasks=1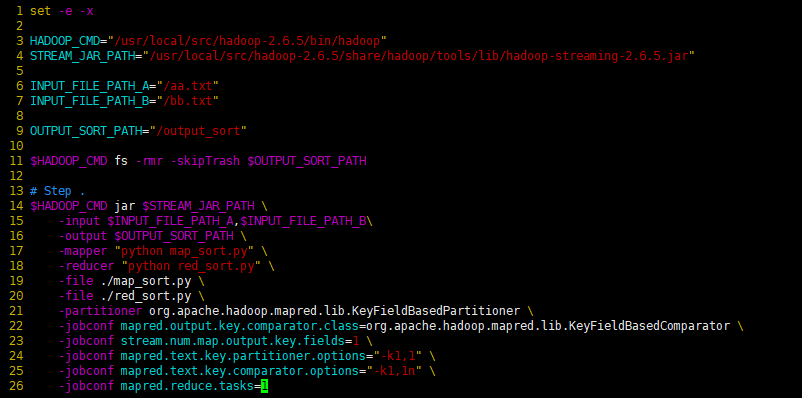
21 行partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner - 利用该配置可以完成二次排序
22 行jobconf org.apache.hadoop.mapred.lib.KeyFieldBasedComparator - 利用该配置可以完成key排序
23 行jobconf stream.num.map.output.key.fields=1 - 设置map分隔符的位置,该位置前的为key,之后的为value
24 行jobconf mapred.text.key.partitioner.options="-k1,1" - 选择哪一部分做partition
25 行jobconf mapred.text.key.comparator.options="-k1,1n" - 设置key中需要比较的字段或字节范围
26 行jobconf mapred.reduce.tasks=1 - 设置只开启一个单reduce
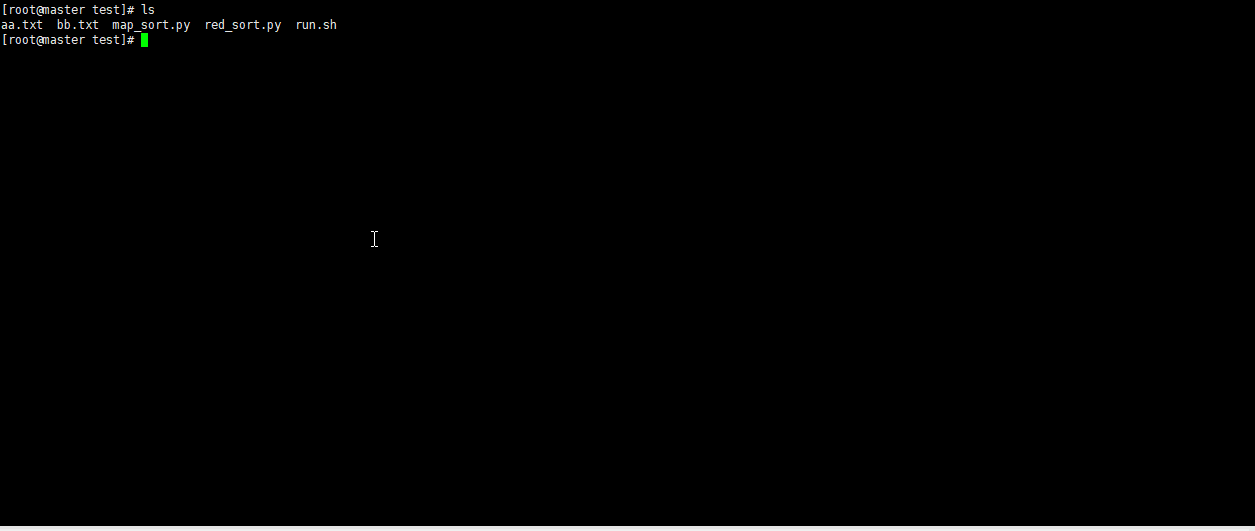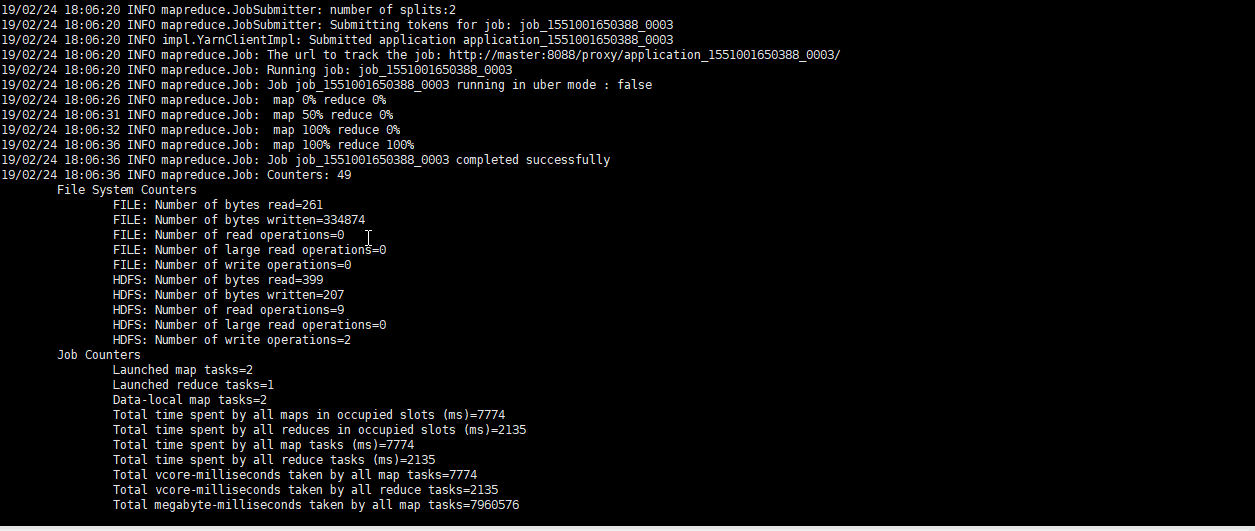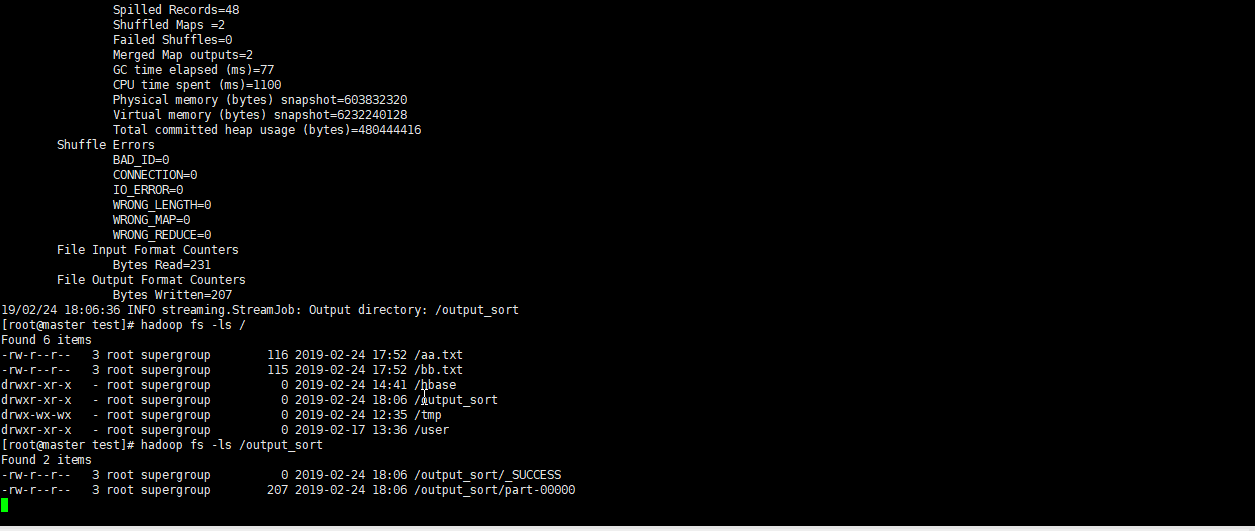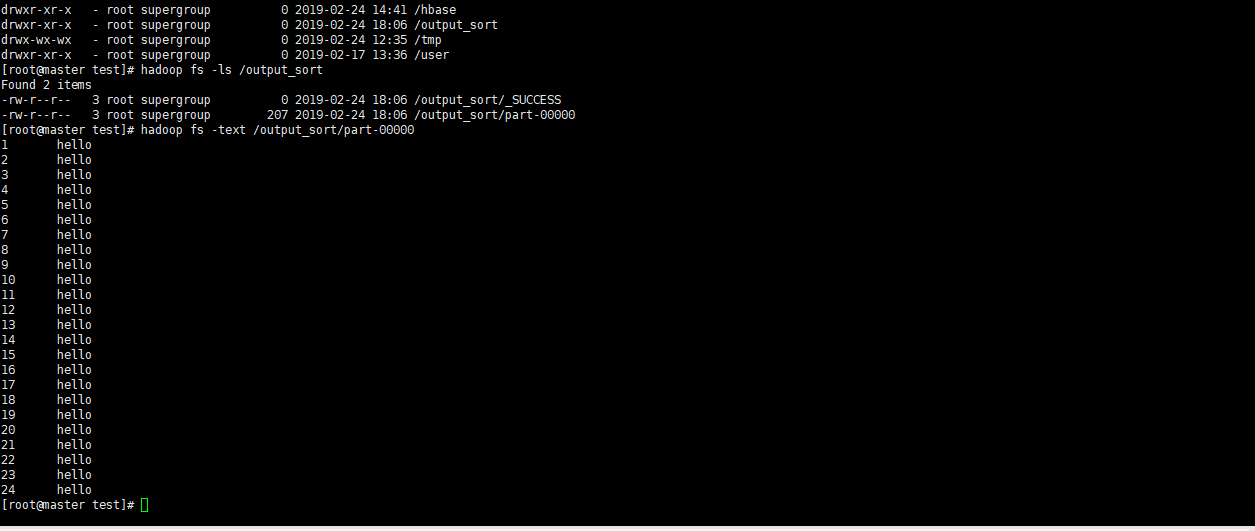
3.3 多reduce编程
- map_sort.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
base_count = 10000
for line in sys.stdin:
ss = line.strip().split('\t')
key = ss[0]
val = ss[1]
new_key = base_count + int(key)
red_idx = 1
#10010的数据放在1桶里,100010以后的放在2桶里,对应run.sh里的桶个数配置
if new_key < (10020 + 10000) / 2:
red_idx = 0
print("%s\t%s\t%s" % (red_idx, new_key, val))- red_sort.py
#!/usr/local/bin/python
# -*- coding: utf-8 -*-
import sys
for line in sys.stdin:
idx_id, key, val = line.strip().split('\t')
print ('\t'.join([key, val]))- run.sh
set -e -x
HADOOP_CMD="/usr/local/src/hadoop-2.6.5/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar"
INPUT_FILE_PATH_A="/aa.txt"
INPUT_FILE_PATH_B="/bb.txt"
OUTPUT_SORT_PATH="/output_sort"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_SORT_PATH
# Step .
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_A,$INPUT_FILE_PATH_B\
-output $OUTPUT_SORT_PATH \
-mapper "python map_sort.py" \
-reducer "python red_sort.py" \
-file ./map_sort.py \
-file ./red_sort.py \
-jobconf mapred.reduce.tasks=2 \
-jobconf stream.num.map.output.key.fields=2 \
-jobconf num.key.fields.for.partition=1 \
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner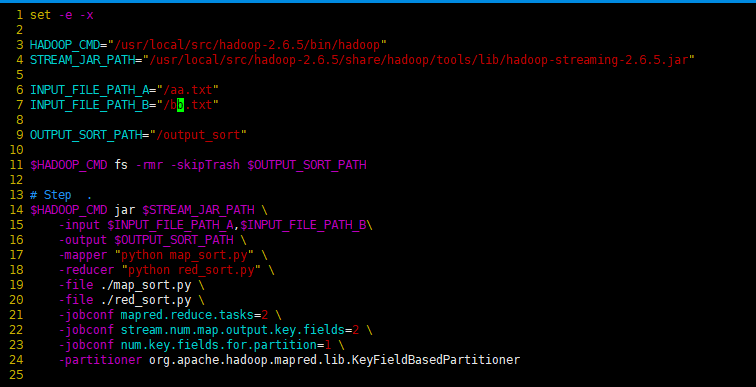
21 行jobconf mapred.reduce.tasks=2 - 桶的数量,和mapper里的桶数量对应
22 行jobconf stream.num.map.output.key.fields=2 - 设置map分隔符的位置,该位置前的为key,之后的为value
23 行jobconf num.key.fields.for.partition=1 - partition key的的位置,用于分发(map执行时的桶的位置对应的第几列)如下图
24 行partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner - 利用该配置可以完成二次排序
-
linux下测试
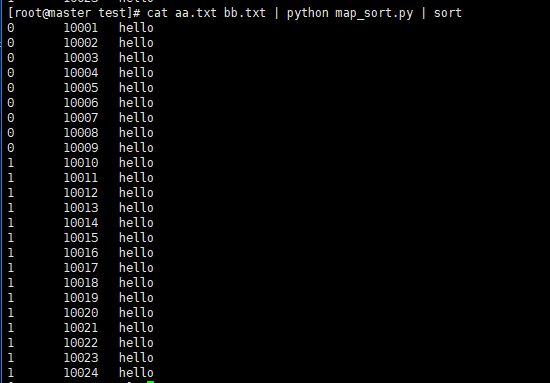
-
集群测试

3.4 检索推荐系统
-
1下载web python包
http://webpy.org/install - 2 file.test
zhangsan 港台经典歌曲^A港台畅销曲大全
lisi 世界杯十大主题曲^A中国十大景点
wangwu 华语金曲100首^A上海金曲信息技术有限公司- 3 mian.py
import web
import sys
urls = (
'/', 'index',
'/test', 'test',
)
app = web.application(urls, globals())
userid_rec_dict = {}
with open('file.test', 'r') as fd:
for line in fd:
ss = line.strip().split('\t')
if len(ss) != 2:
continue
userid = ss[0].strip()
items = ss[1].strip()
userid_rec_dict[userid] = items
class index:
def GET(self):
params = web.input()
userid = params.get('userid', '')
if userid not in userid_rec_dict:
return 'no rec!'
else:
return '\n'.join(userid_rec_dict[userid].strip().split('^A'))
class test:
def GET(self):
print web.input()
return '222'
if __name__ == "__main__":
app.run()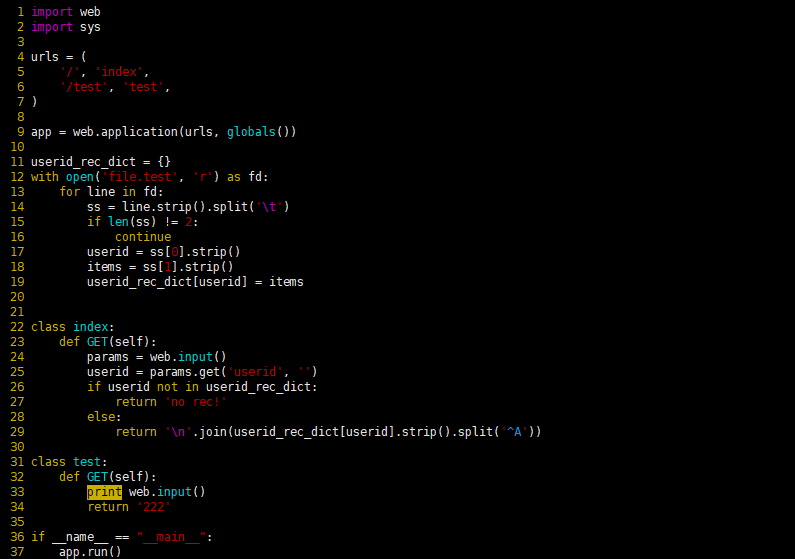
这里面的class就是一个对应的请求url域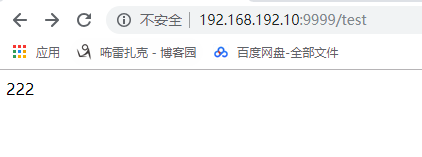
代码解释
1------导入我们下载的web.py包
2------导入标准库
4-7----元组设置几个路径
9-------基本来说就是用web.py创建一个应用
11------定义一个dict(键值对)
12------读取一个文件别名 fd
13-19--从file.test文件中读取键值对放入11定义的键值对中
22-29--设置初始页面或/index页面,从请求中读取userid在11键值对中找是否有
31-34---设置/test请求,和22-29共同理解
36-37启动应用程序
使用命令 在9999端口启动应用
python main.py 9999
http://192.168.192.10:9999/test
http://192.168.192.10:9999/?userid=zhangsan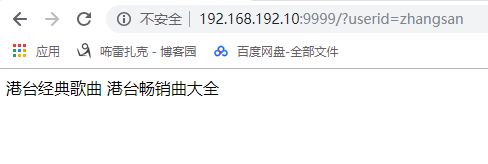
需求案例:
需求1:
找出每个月气温最高的2天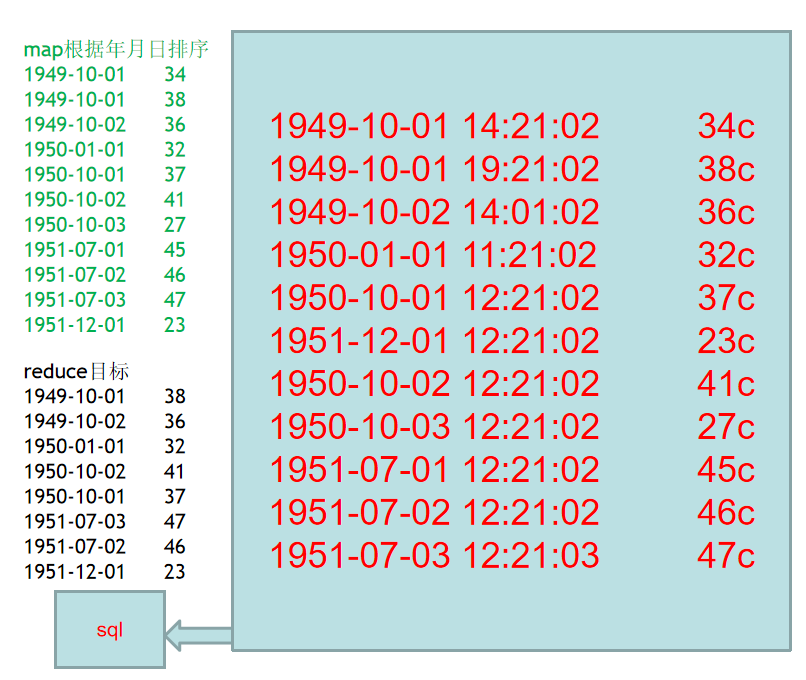
- 数据tq.csv
1949-10-01,14:21:02,34c
1949-10-01,19:21:02,38c
1949-10-02,14:01:02,36c
1950-01-01,11:21:02,32c
1950-10-01,12:21:02,37c
1951-12-01,12:21:02,23c
1950-10-02,12:21:02,41c
1950-10-03,12:21:02,27c
1951-07-01,12:21:02,45c
1951-07-02,12:21:02,46c
1951-07-03,12:21:03,47c- 业务分析mymap.py
- map拿到所有数据,按照年月日排序
- red根据排序后的数据,取出当月最高的2个温度输出
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
#日期温度对象
class Tq(object):
# 1949-10-01,14:21:02,34c 原始数据对象
def __init__(self, year, month, day, wd):
self.year = year
self.month = month
self.day = day
self.wd = wd
#对于小于10的数,前补0
def format_num(num):
a = num
if a < 10:
a = "0" + str(num)
return str(a)
def main():
resource_list = []
resource_list
for line in sys.stdin:
s_ymd = line.split(",")
if len(s_ymd) !=3:
continue
l_ymd, l_time, l_wd = s_ymd
y, m, d = l_ymd.split("-")
a = Tq(int(y), int(m), int(d), int(l_wd[:-2]))
resource_list.append(a)
s_list = sorted(resource_list,key=lambda tq: (tq.year,tq.month,tq.day))
for tq in s_list:
print("\t".join(["-".join([str(tq.year), format_num(tq.month), format_num(tq.day)]),str(tq.wd)]))
if __name__ == '__main__':
main()- myred.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
#打印集合的top2信息
def print_top2(arrlist):
if len(arrlist) == 1:
print("\t".join(arrlist[0]))
elif len(arrlist) == 2:
print("\t".join(arrlist[0]))
print("\t".join(arrlist[1]))
def main():
cur_ymd = None
ymdw_list = []
for line in sys.stdin:
'''
map输出的数据格式
1949-10-01 38
1949-10-02 36
1950-01-01 32
'''
ss = line.strip().split('\t')
if len(ss) != 2:
continue
ymd, wd = ss
if cur_ymd == None:
cur_ymd = ymd[:-3]
if cur_ymd != ymd[:-3]:
s_list = sorted(ymdw_list, key=lambda x: x[1], reverse=True)
print_top2(s_list[:2])
ymdw_list = []
cur_ymd = ymd[:-3]
ymdw_list.append([ymd, wd])
s_list = sorted(ymdw_list, key=lambda x: x[1], reverse=True)
print_top2(s_list[:2])
if __name__ == '__main__':
main()- run.sh
HADOOP_CMD="/usr/local/src/hadoop-2.6.5/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar"
INPUT_FILE_PATH_1="/tq/tq.csv"
OUTPUT_PATH="/output"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_1 \
-output $OUTPUT_PATH \
-mapper "python mymap.py" \
-reducer "python myred.py" \
-file ./mymap.py \
-file ./myred.py单机测试:
集群测试: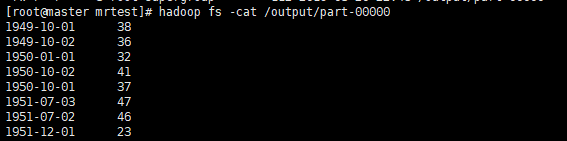
需求2:
- 推荐好友(好友的好友)
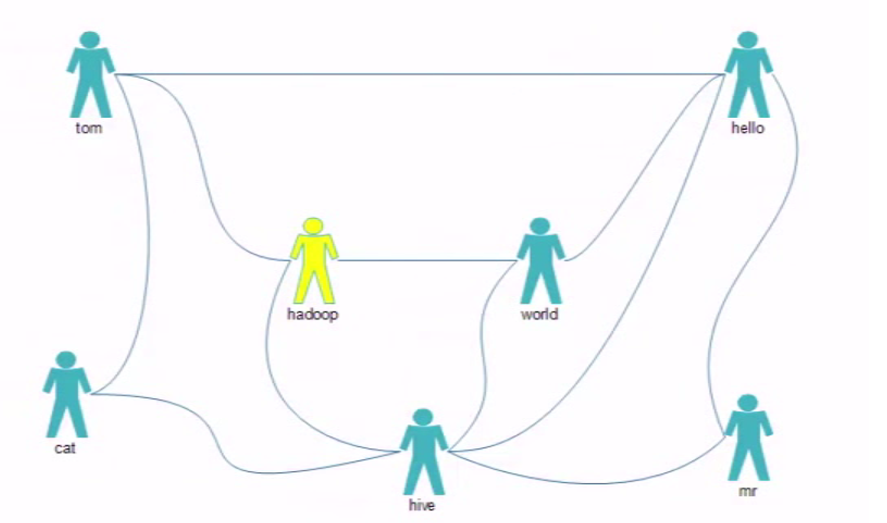
- hy.csv
tom,hello,hadoop,cat
world,hadoop,hello,hive
cat,tom,hive
mr,hive,hello
hive,cat,hadoop,world,hello,mr
hadoop,tom,hive,world
hello,tom,world,hive,mr- 业务分析mymap.py
- 推荐者与被推荐者一定有一个或多个相同的好友
- 全局去寻找好友列表中两两关系
- 去除直接好友
- 统计两两关系出现次数
- map:按好友列表输出两俩关系
- reduce:sum两两关系
- 再设计一个MR生成详细报表
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
import re
import operator as op
#按字符串大小进行key,value组装
def getHy(a,b):
if op.gt(b,a):
return (b,a)
return(a,b)
# 直接好友
directFriend=[]
# 间接好友
indirectFriend=[]
for line in sys.stdin:
worlds = re.sub('\n','',line).split(",")
for i in range(1,len(worlds)):
#用数组第一个元素和后面所有的元素一一匹配,输出他们的直接好友关系,值记为0
directFriend = getHy(worlds[0],worlds[i])
print("\t".join([":".join(directFriend),"0"]))
for j in range(i+1,len(worlds)):
#输出间接好友关系,因他们共同拥有0位的好友
indirectFriend=getHy(worlds[i],worlds[j])
print("\t".join([":".join(indirectFriend),"1"]))- myred.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys
'''
mr:hive 0
mr:hive 0
mr:hive 1
tom:cat 0
tom:cat 0
排序后的结果,全为 1 才是间接好友
有一个为 0 那么为直接好友
因间接好友出现的条件是拥有共同的好友,
所以间接好友出现次数的和,就是共同好友数
'''
cur_worlds = None
values = []
for line in sys.stdin:
worlds, count = line.split("\t")
if cur_worlds == None:
cur_worlds = worlds
if cur_worlds != worlds:
if 0 not in values:
print(cur_worlds, sum(values))
values = []
cur_worlds = worlds
values.append(int(count))
if 0 not in values:
print(cur_worlds, sum(values))- run.sh
HADOOP_CMD="/usr/local/src/hadoop-2.6.5/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar"
INPUT_FILE_PATH_1="/hy/hy.csv"
OUTPUT_PATH="/output"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_1 \
-output $OUTPUT_PATH \
-mapper "python mymap.py" \
-reducer "python myred.py" \
-file ./mymap.py \
-file ./myred.py单机测试:
集群测试: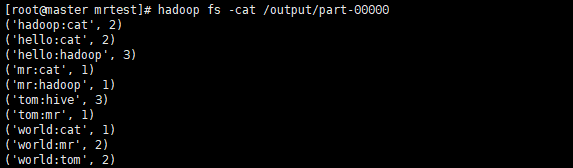

 浙公网安备 33010602011771号
浙公网安备 33010602011771号