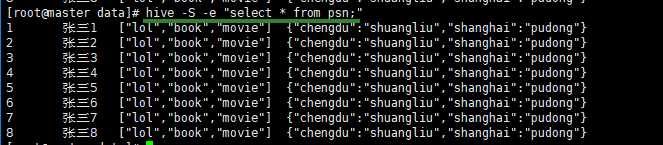
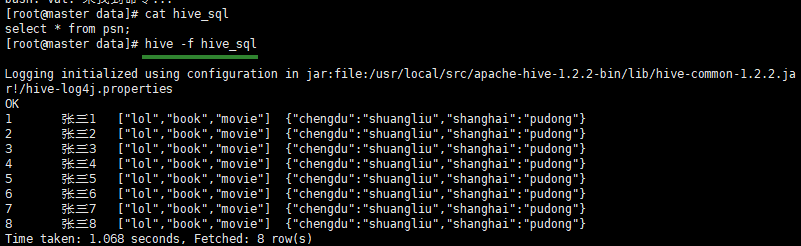
1 DDL数据定义语言
1.1 创建数据库
1.3 查询数据库
- 1.3.1 显示数据库
- 显示数据库
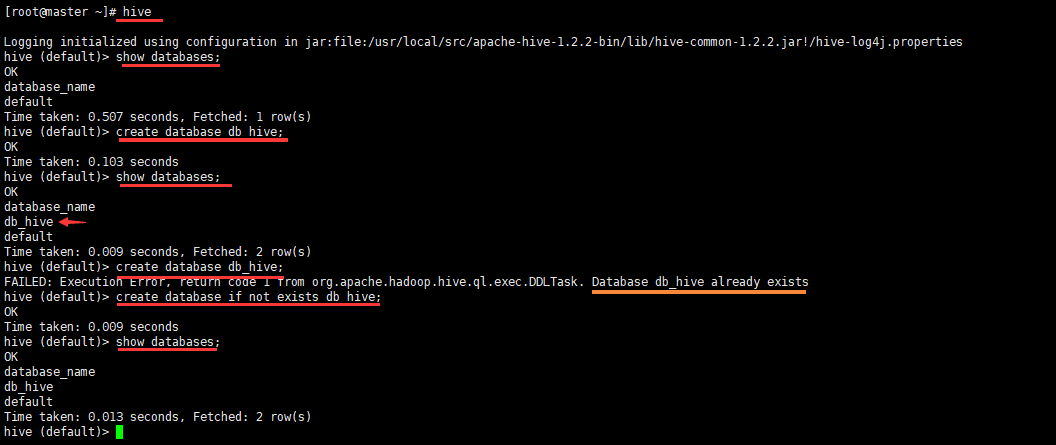
hive> show databases;
- 过滤显示查询的数据库
hive> show databases like 'db_hive*';
- 1.3.2 查看数据库详情1.3.3 使用数据库
hive (default)> use db_hive;
- 1)显示数据库信息
hive> desc database db_hive;
- 2)显示数据库详细信息,extended
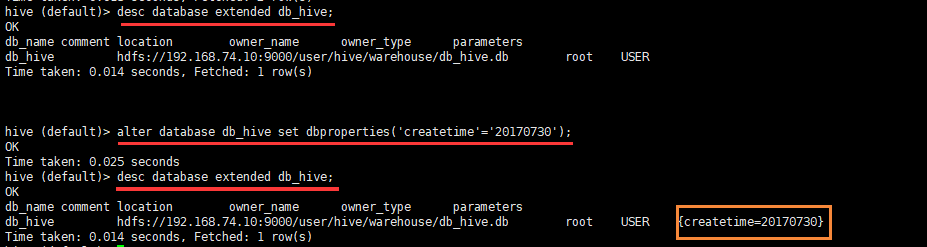
hive> desc database extended db_hive;
1.4 删除数据库
- 1.4.1 删除空数据库
hive>drop database db_hive2;
- 1.4.2 如果删除的数据库不存在,最好采用 if exists判断数据库是否存在
hive> drop database if exists db_hive2;
- 1.4.3 如果数据库不为空,可以采用cascade命令,强制删除
hive> drop database db_hive cascade;
1.5 创建表
- 1.5.1 创建表概念
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
- 字段解释说明:
- (1)CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
- (2)EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),Hive创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
- (3)COMMENT:为表和列添加注释。
- (4)PARTITIONED BY创建分区表
- (5)CLUSTERED BY创建分桶表
- (6)SORTED BY排序不常用
- (7)ROW FORMAT 用户在建表的时候可以自定义SerDe或者使用自带的SerDe(默认是^A分割)。如果没有指定ROW FORMAT 或者ROW FORMAT DELIMITED,将会使用自带的SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。
ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name
[WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
- (8)STORED AS 指定存储文件类型
- 常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)
- 如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
- (9)LOCATION :指定表在HDFS上的存储位置。
- (10)LIKE允许用户复制现有的表结构,但是不复制数据。
- 1.5.2 创建表案例(内部表)
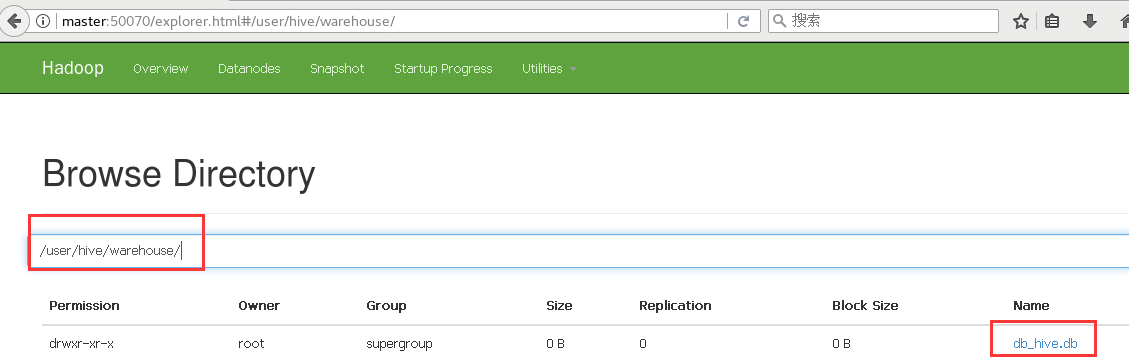
- 默认创建的表都是所谓的管理表,有时也被称为内部表。因为这种表,Hive会(或多或少地)控制着数据的生命周期。Hive默认情况下会将这些表的数据存储在由配置项hive.metastore.warehouse.dir(例如,/user/hive/warehouse)所定义的目录的子目录下。 当我们删除一个管理表时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。
- 准备数据
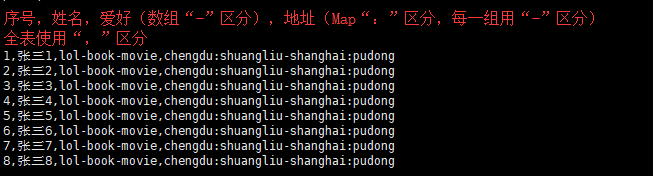
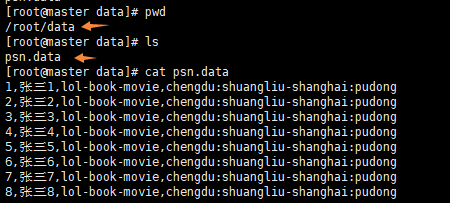
- psn.data
1,张三1,lol-book-movie,chengdu:shuangliu-shanghai:pudong
2,张三2,lol-book-movie,chengdu:shuangliu-shanghai:pudong
3,张三3,lol-book-movie,chengdu:shuangliu-shanghai:pudong
4,张三4,lol-book-movie,chengdu:shuangliu-shanghai:pudong
5,张三5,lol-book-movie,chengdu:shuangliu-shanghai:pudong
6,张三6,lol-book-movie,chengdu:shuangliu-shanghai:pudong
7,张三7,lol-book-movie,chengdu:shuangliu-shanghai:pudong
8,张三8,lol-book-movie,chengdu:shuangliu-shanghai:pudong
create table psn
(
id int,
name string,
likes array<string>,
address map<string,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
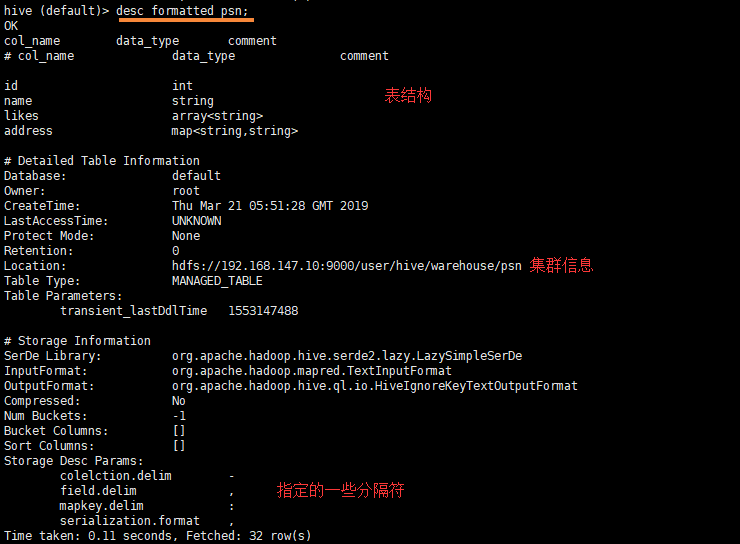
- 查看表结构
desc formatted psn;
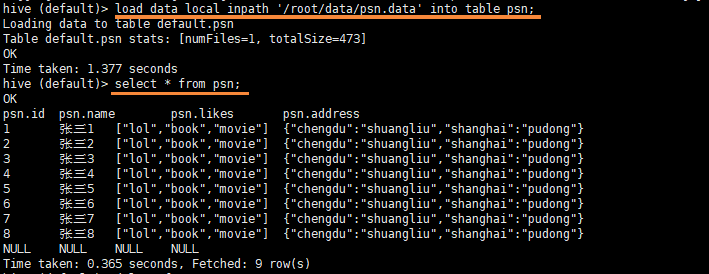
- 灌库
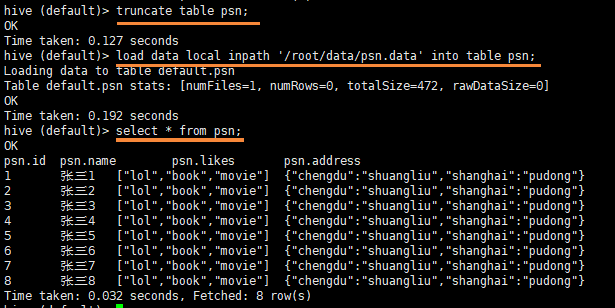
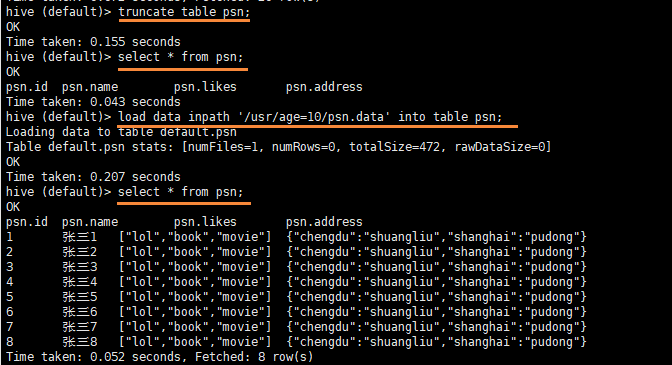
load data local inpath '/root/data/psn.data' into table psn;
- 注意:分隔符可以使用默认的或者写成下面这种。(\001,\002,\003分别代表^A,^B,^C)
row format delimited
fields terminated by '\001'
collection items terminated by '\002'
map keys terminated by '\003';
- 1.5.3 创建表案例(外部表)
- 因为表是外部表,所有Hive并非认为其完全拥有这份数据。删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。
- 准备数据提交到集群
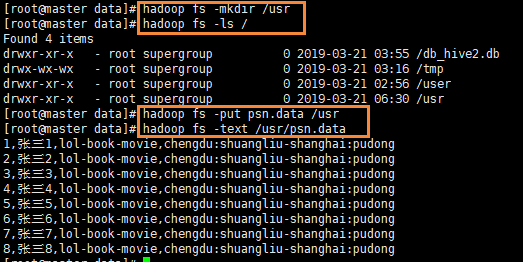
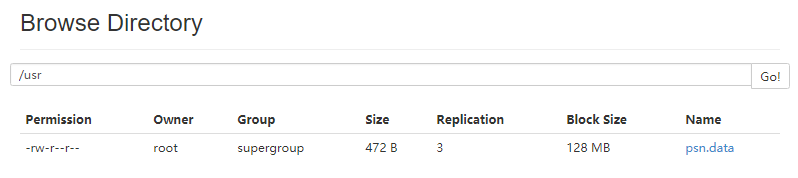
- 建表语句
create external table psn2
(
id int,
name string,
likes array<string>,
address map<string,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/usr/';
- 直接加载了hdfs上的数据
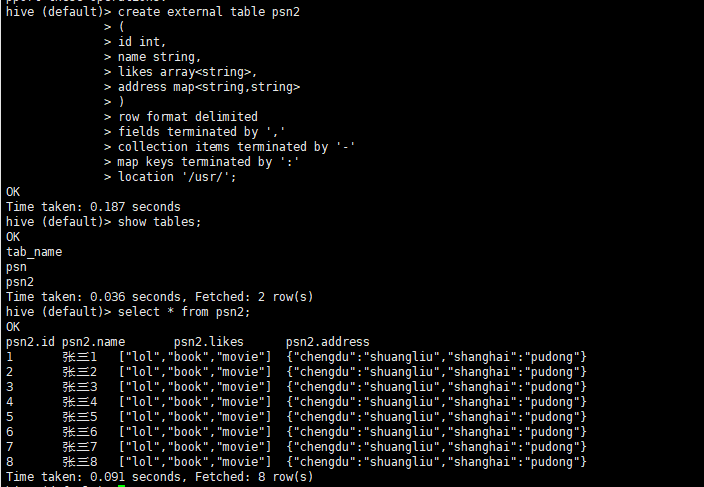
- 1.5.4 内部表和外部表的区别:
- 1、创建表的时候,内部表直接存储再默认的hdfs路径,外部表需要自己指定路径
- 2、删除表的时候,内部表会将数据和元数据全部删除,外部表只删除元数据,数据不删除
- 3、基本使用需要根据业务区分,一般先有表后有数据-->建立内部表,一般先有数据后有表-->建立外部表
- 1.5.5 hive和关系型数据库区别:
- 1、如果我们使用格式不符合的数据进行hive灌库操作,是可以成功的,但是会查出很多NULL数据
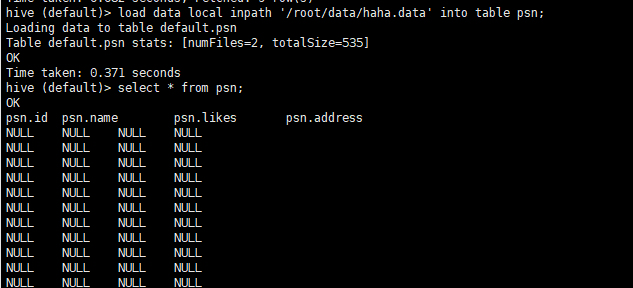
- 2、hive:写时不检查,读时检查(实现解耦,提高数据记载的效率)
- 3、关系型数据库:写时检查(如果数据不对,是不能插入数据的)
- 1.5.6 创建表案例(分区表):
- 分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
-
1.5.6.1单分区建表语句
create table psn3
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(age int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
- 数据灌库
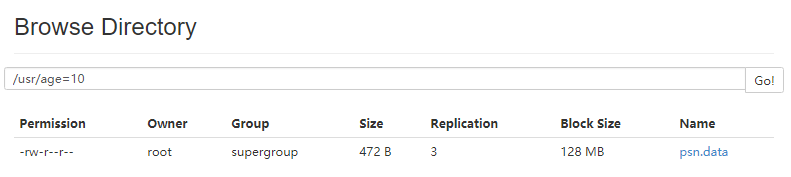
load data local inpath '/root/data/psn.data' into table psn3 partition(age=10);
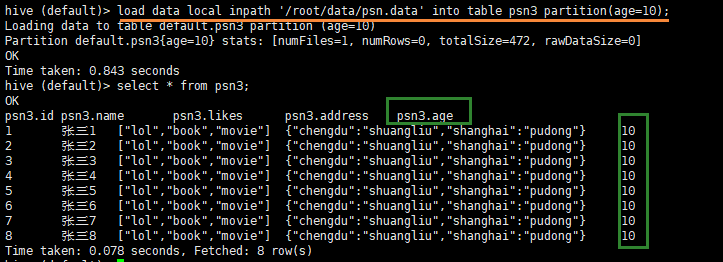
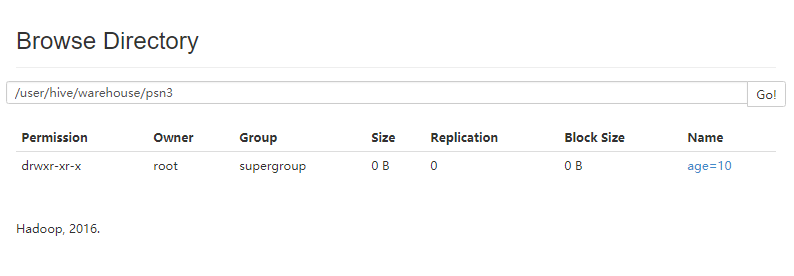
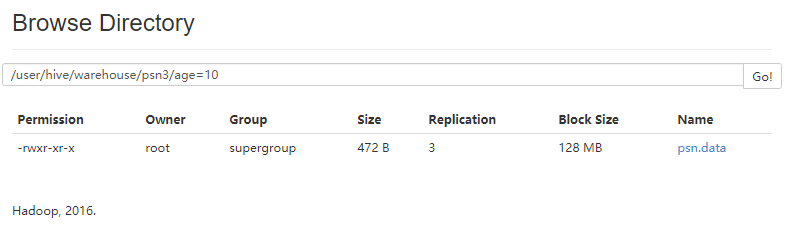
- 再次数据灌库
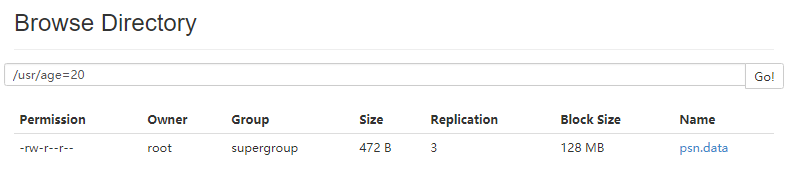
load data local inpath '/root/data/psn.data' into table psn3 partition(age=20);
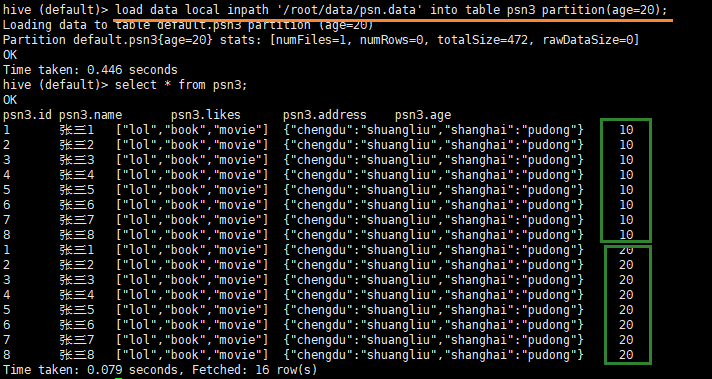
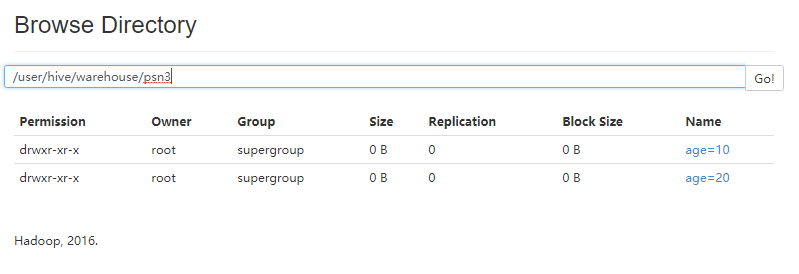
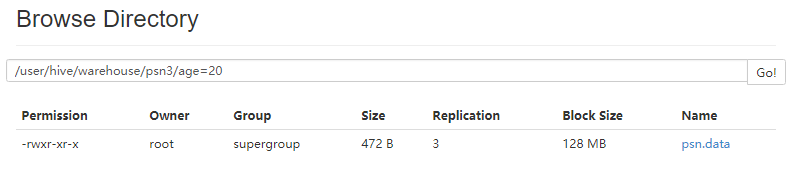
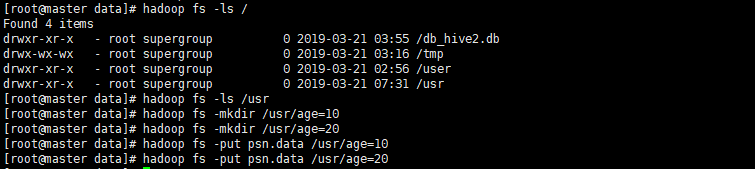
- hive查询分区结果
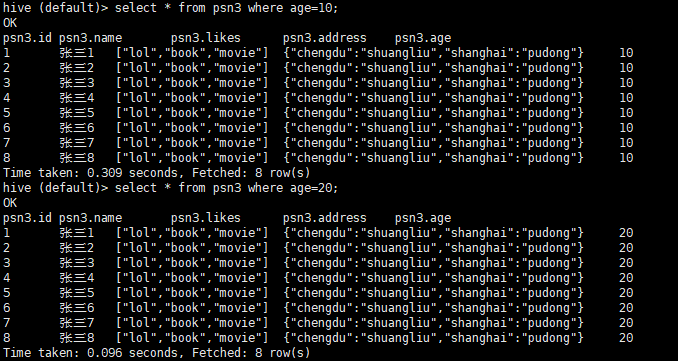
-
1.5.6.2多分区建表语句
create table psn4
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(age int,sex string)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
load data local inpath '/root/data/psn.data' into table psn3 partition(age=10,sex='man');
load data local inpath '/root/data/psn.data' into table psn4 partition(age=10,sex='feman');
- 查询
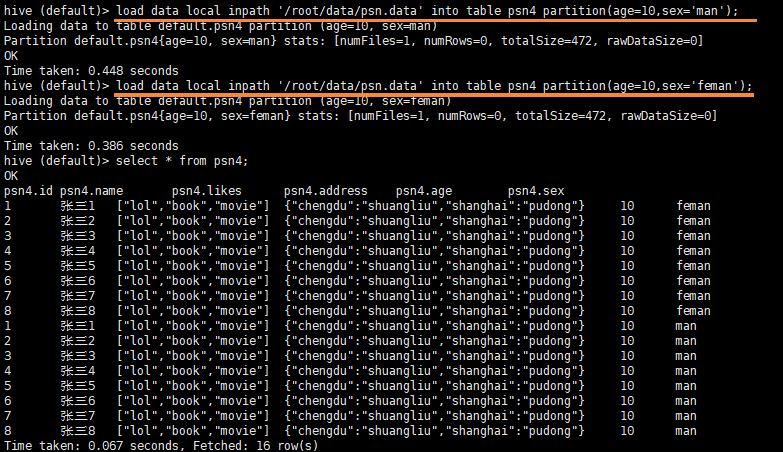
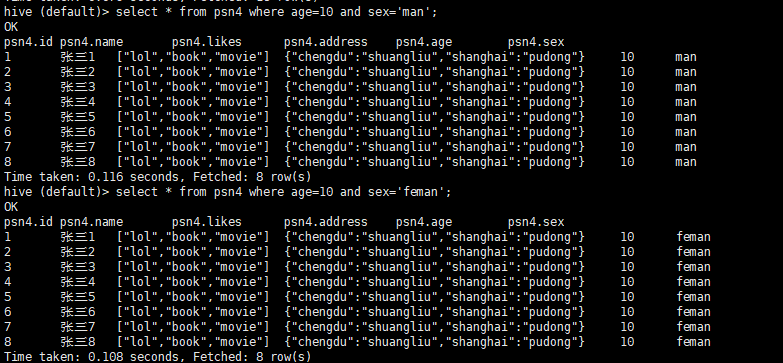
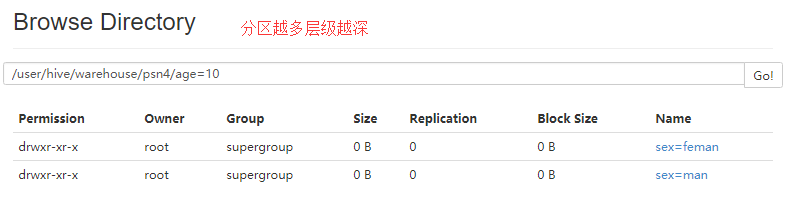
- 创建分区不加数据(必须写全分区字段)
alter table psn4 add partition(age=20,sex='boy');

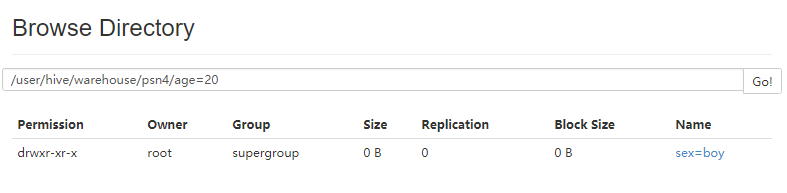
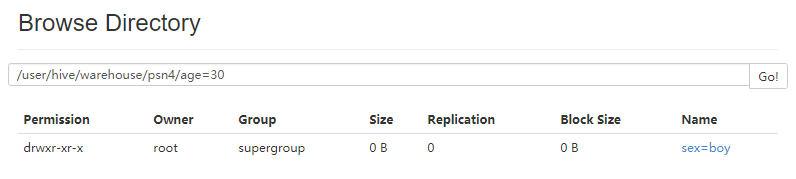
- 删除分区(可以不用写全分区字段)
alter table psn4 droppartition(sex='boy');

-
1.5.6.3多分区先有数据,怎么使用分区表处理
- 创建外部分区表语句
create external table psn5
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(age int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/usr/';
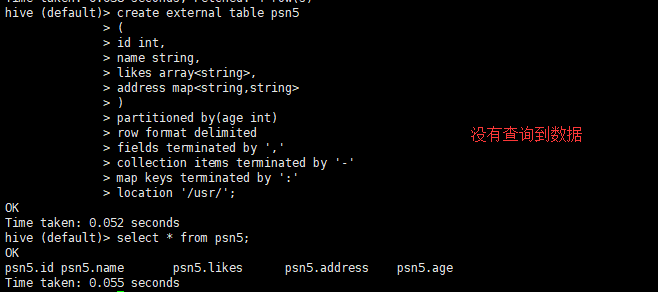
- 修复分区命令
msck repair table psn5;
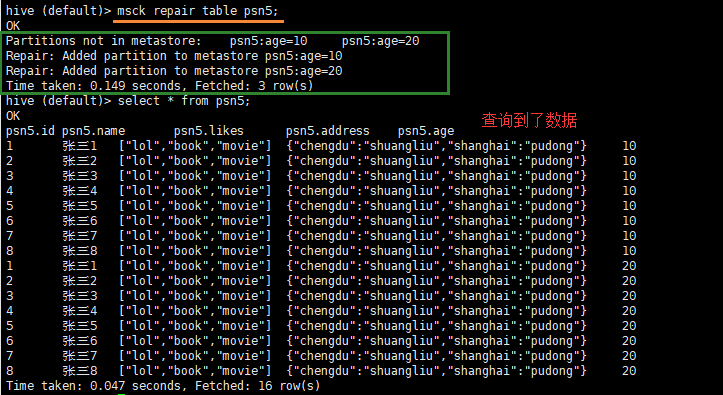
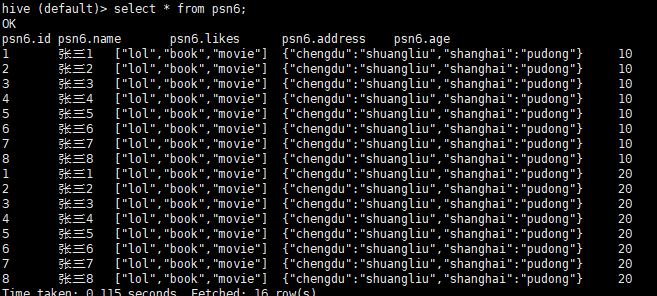
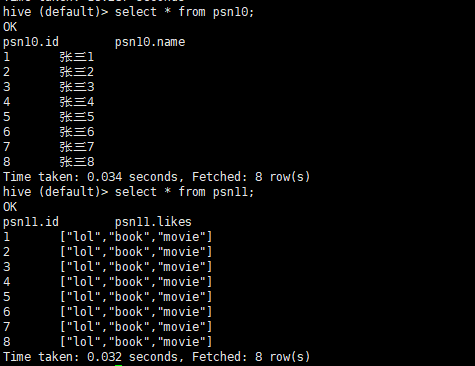
- 1.5.7 通过查询创建表(包含数据):
create table psn6 as select * from psn3;

- 1.5.8 通过查询创建表(不包含数据):
create table psn7 like psn3;

1.6 修改表
- 5.7.1 表重命名
ALTER TABLE table_name RENAME TO new_table_name
- 5.7.2 增加、修改和删除表分区(参考5.6)
- 5.7.3 增加/修改/替换列信息
- 更新列
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
- 增加和替换列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
- 5.7.4 增加/修改/替换列信息demo
- 查询表结构
desc dept_partition;
- 添加列
alter table dept_partition add columns(deptdesc string);
- 查询表结构
desc dept_partition;
- 更新列
alter table dept_partition change column deptdesc desc int;
- 查询表结构
desc dept_partition;
- 替换列
alter table dept_partition replace columns(deptno string, dname string, loc string);
- 查询表结构
desc dept_partition;
1.7 删除表
hive (default)> drop table dept_partition;
2 DML数据定义语言
2.1 清除表中数据(Truncate)
- 注意:Truncate只能删除管理表,不能删除外部表中数据
- 注意:hive不支持delete
- Truncate不经过事务,delete经过事务
hive (default)> truncate table student;
2.2 向表中装载数据(Load)
hive>load data [local] inpath '/usr/age=10/psn.data' [overwrite] into table psn [partition (partcol1=val1,…)];
(1)load data:表示加载数据
(2)local:表示从本地加载数据到hive表;否则从HDFS加载数据到hive表
(3)inpath:表示加载数据的路径
(4)into table:表示加载到哪张表
(5)student:表示具体的表
(6)overwrite:表示覆盖表中已有数据,否则表示追加
(7)partition:表示上传到指定分区
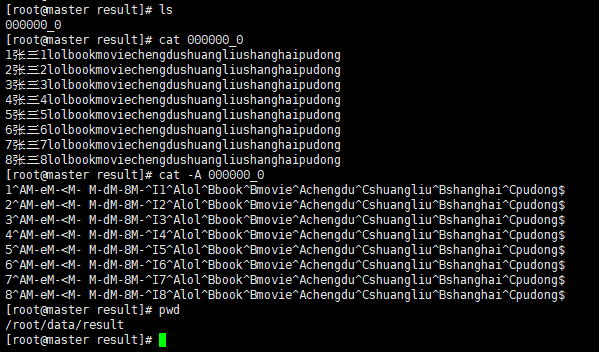
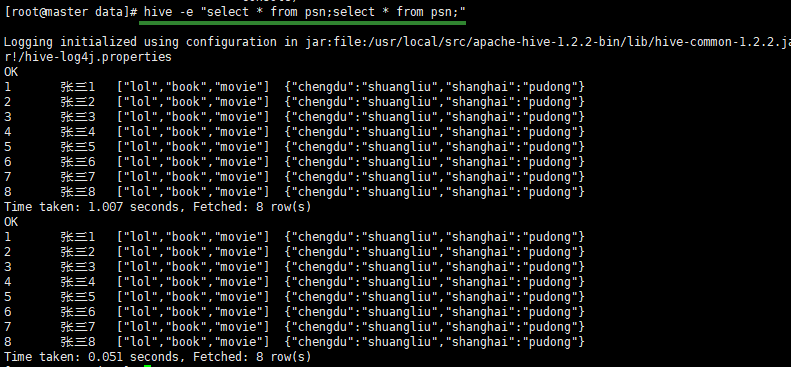
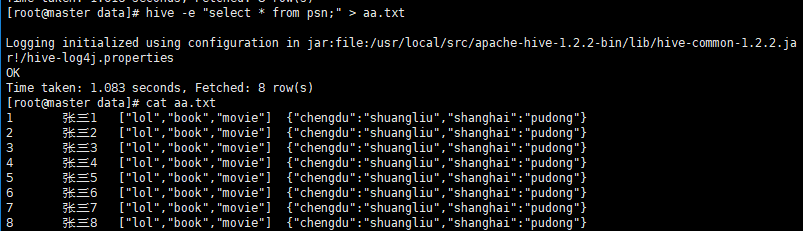
insert overwrite local directory '/root/data/result'
select * from psn;
2.3Hive SerDe
- 实际开发中,有些很复杂的日志数据需要导入hive。
- 数据文件如下:data.log
192.168.147.10 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-upper.png HTTP/1.1" 304 -
192.168.147.10 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-nav.png HTTP/1.1" 304 -
192.168.147.10 - - [29/Feb/2016:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
192.168.147.10 - - [29/Feb/2016:18:14:36 +0800] "GET /tomcat.css HTTP/1.1" 304 -
192.168.147.10 - - [29/Feb/2016:18:14:36 +0800] "GET /asf-logo.png HTTP/1.1" 304 -
192.168.147.10 - - [29/Feb/2016:18:14:36 +0800] "GET /bg-middle.png HTTP/1.1" 304 -
192.168.147.10 - - [29/Feb/2016:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
192.168.147.10 - - [29/Feb/2016:18:14:36 +0800] "GET /tomcat.css HTTP/1.1" 304 -
192.168.147.10 - - [29/Feb/2016:18:14:36 +0800] "GET /tomcat.png HTTP/1.1" 304 -
192.168.147.10 - - [29/Feb/2016:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
192.168.147.10 - - [29/Feb/2016:18:14:36 +0800] "GET /tomcat.css HTTP/1.1" 304 -
192.168.147.10 - - [29/Feb/2016:18:14:36 +0800] "GET /bg-upper.png HTTP/1.1" 304 -
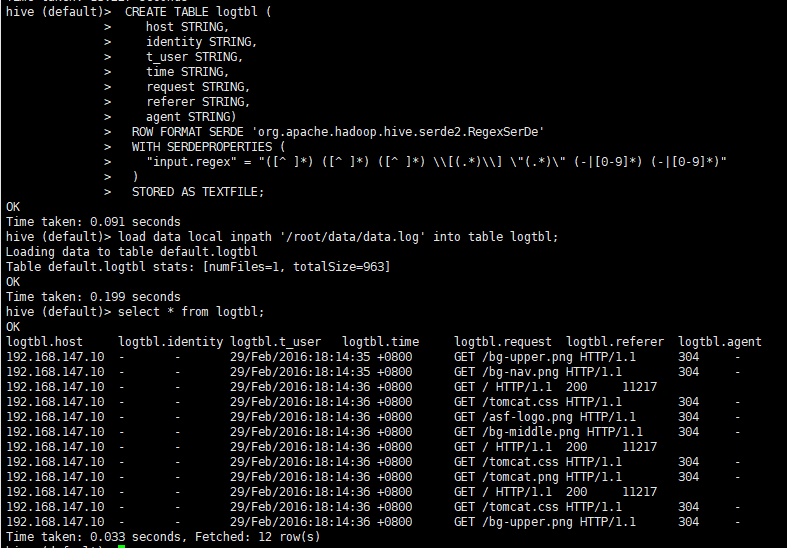
CREATE TABLE logtbl (
host STRING,
identity STRING,
t_user STRING,
time STRING,
request STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) \\[(.*)\\] \"(.*)\" (-|[0-9]*) (-|[0-9]*)"
)
STORED AS TEXTFILE;
- 导入数据查询
load data local inpath '/root/data/data.log' into table logtbl;
3 函数
3.1内置运算符
3.1.1关系运算符
| A = B |
所有原始类型 |
如果A与B相等,返回TRUE,否则返回FALSE |
| A == B |
无 |
失败,因为无效的语法。 SQL使用”=”,不使用”==”。 |
| A <> B |
所有原始类型 |
如果A不等于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A < B |
所有原始类型 |
如果A小于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A <= B |
所有原始类型 |
如果A小于等于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A > B |
所有原始类型 |
如果A大于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A >= B |
所有原始类型 |
如果A大于等于B返回TRUE,否则返回FALSE。如果A或B值为”NULL”,结果返回”NULL”。 |
| A IS NULL |
所有类型 |
如果A值为”NULL”,返回TRUE,否则返回FALSE |
| A IS NOT NULL |
所有类型 |
如果A值不为”NULL”,返回TRUE,否则返回FALSE |
| A LIKE B |
字符串 |
如 果A或B值为”NULL”,结果返回”NULL”。字符串A与B通过sql进行匹配,如果相符返回TRUE,不符返回FALSE。B字符串中 的””代表任一字符,”%”则代表多个任意字符。
例如: (‘foobar’ like ‘foo’)返回FALSE,( ‘foobar’ like ‘foo _ _’或者 ‘foobar’ like ‘foo%’)则返回TURE |
| A RLIKE B |
字符串 |
如 果A或B值为”NULL”,结果返回”NULL”。字符串A与B通过java进行匹配,如果相符返回TRUE,不符返回FALSE。
例如:( ‘foobar’ rlike ‘foo’)返回FALSE,(’foobar’ rlike ‘^f.*r$’ )返回TRUE。 |
| A REGEXP B |
字符串 |
与RLIKE相同。 |
3.1.2算术运算符
| A + B |
所有数字类型 |
A和B相加。结果的与操作数值有共同类型。例如每一个整数是一个浮点数,浮点数包含整数。所以,一个浮点数和一个整数相加结果也是一个浮点数。 |
| A – B |
所有数字类型 |
A和B相减。结果的与操作数值有共同类型。 |
| A * B |
所有数字类型 |
A和B相乘,结果的与操作数值有共同类型。需要说明的是,如果乘法造成溢出,将选择更高的类型。 |
| A / B |
所有数字类型 |
A和B相除,结果是一个double(双精度)类型的结果。 |
| A % B |
所有数字类型 |
A除以B余数与操作数值有共同类型。 |
| A & B |
所有数字类型 |
运算符查看两个参数的二进制表示法的值,并执行按位”与”操作。两个表达式的一位均为1时,则结果的该位为 1。否则,结果的该位为 0。 |
| A | B |
所有数字类型 |
运算符查看两个参数的二进制表示法的值,并执行按位”或”操作。只要任一表达式的一位为 1,则结果的该位为 1。否则,结果的该位为 0。 |
| A ^ B |
所有数字类型 |
运算符查看两个参数的二进制表示法的值,并执行按位”异或”操作。当且仅当只有一个表达式的某位上为 1 时,结果的该位才为 1。否则结果的该位为 0。 |
| ~A |
所有数字类型 |
对一个表达式执行按位”非”(取反)。 |
3.1.3逻辑运算符
| A AND B |
布尔值 |
A和B同时正确时,返回TRUE,否则FALSE。如果A或B值为NULL,返回NULL。 |
| A && B |
布尔值 |
与”A AND B”相同 |
| A OR B |
布尔值 |
A或B正确,或两者同时正确返返回TRUE,否则FALSE。如果A和B值同时为NULL,返回NULL。 |
| A | B |
布尔值 |
与”A OR B”相同 |
| NOT A |
布尔值 |
如果A为NULL或错误的时候返回TURE,否则返回FALSE。 |
| ! A |
布尔值 |
与”NOT A”相同 |
3.1.4复杂类型函数
| map |
(key1, value1, key2, value2, …) |
通过指定的键/值对,创建一个map。 |
| struct |
(val1, val2, val3, …) |
通过指定的字段值,创建一个结构。结构字段名称将COL1,COL2,… |
| array |
(val1, val2, …) |
通过指定的元素,创建一个数组。 |
3.1.5对复杂类型函数操作
| A[n] |
A是一个数组,n为int型 |
返回数组A的第n个元素,第一个元素的索引为0。如果A数组为['foo','bar'],则A[0]返回’foo’和A[1]返回”bar”。 |
| M[key] |
M是Map<K, V>,关键K型 |
返回关键值对应的值,例如mapM为 {‘f’ -> ‘foo’, ‘b’ -> ‘bar’, ‘all’ -> ‘foobar’},则M['all'] 返回’foobar’。 |
| S.x |
S为struct |
返回结构x字符串在结构S中的存储位置。如 foobar {int foo, int bar} foobar.foo的领域中存储的整数。 |
3.2内置函数
3.2.1数学函数
| BIGINT |
round(double a) |
四舍五入 |
| DOUBLE |
round(double a, int d) |
小数部分d位之后数字四舍五入,例如round(21.263,2),返回21.26 |
| BIGINT |
floor(double a) |
对给定数据进行向下舍入最接近的整数。例如floor(21.2),返回21。 |
| BIGINT |
ceil(double a), ceiling(double a) |
将参数向上舍入为最接近的整数。例如ceil(21.2),返回23. |
| double |
rand(), rand(int seed) |
返回大于或等于0且小于1的平均分布随机数(依重新计算而变) |
| double |
exp(double a) |
返回e的n次方 |
| double |
ln(double a) |
返回给定数值的自然对数 |
| double |
log10(double a) |
返回给定数值的以10为底自然对数 |
| double |
log2(double a) |
返回给定数值的以2为底自然对数 |
| double |
log(double base, double a) |
返回给定底数及指数返回自然对数 |
| double |
pow(double a, double p) power(double a, double p) |
返回某数的乘幂 |
| double |
sqrt(double a) |
返回数值的平方根 |
| string |
bin(BIGINT a) |
返回二进制格式 |
| string |
hex(BIGINT a) hex(string a) |
将整数或字符转换为十六进制格式 |
| string |
unhex(string a) |
十六进制字符转换由数字表示的字符。 |
| string |
conv(BIGINT num, int from_base, int to_base) |
将 指定数值,由原来的度量体系转换为指定的试题体系。例如CONV(‘a’,16,2),返回。参考:’1010′ http://dev.mysql.com/doc/refman/5.0/en/mathematical-functions.html#function_conv |
| double |
abs(double a) |
取绝对值 |
| int double |
pmod(int a, int b) pmod(double a, double b) |
返回a除b的余数的绝对值 |
| double |
sin(double a) |
返回给定角度的正弦值 |
| double |
asin(double a) |
返回x的反正弦,即是X。如果X是在-1到1的正弦值,返回NULL。 |
| double |
cos(double a) |
返回余弦 |
| double |
acos(double a) |
返回X的反余弦,即余弦是X,,如果-1<= A <= 1,否则返回null. |
| int double |
positive(int a) positive(double a) |
返回A的值,例如positive(2),返回2。 |
| int double |
negative(int a) negative(double a) |
返回A的相反数,例如negative(2),返回-2。 |
3.2.2收集函数
| int |
size(Map<K.V>) |
返回的map类型的元素的数量 |
| int |
size(Array) |
返回数组类型的元素数量 |
3.2.3类型转换函数
| 指定 |
“type” cast(expr as ) |
类型转换。例如将字符”1″转换为整数:cast(’1′ as bigint),如果转换失败返回NULL。 |
3.2.4日期函数
| string |
from_unixtime(bigint unixtime[, string format]) |
UNIX_TIMESTAMP参数表示返回一个值’YYYY- MM – DD HH:MM:SS’或YYYYMMDDHHMMSS.uuuuuu格式,这取决于是否是在一个字符串或数字语境中使用的功能。该值表示在当前的时区。 |
| bigint |
unix_timestamp() |
如果不带参数的调用,返回一个Unix时间戳(从’1970- 01 – 0100:00:00′到现在的UTC秒数)为无符号整数。 |
| bigint |
unix_timestamp(string date) |
指定日期参数调用UNIX_TIMESTAMP(),它返回参数值’1970- 01 – 0100:00:00′到指定日期的秒数。 |
| bigint |
unix_timestamp(string date, string pattern) |
指定时间输入格式,返回到1970年秒数:unix_timestamp(’2009-03-20′, ‘yyyy-MM-dd’) = 1237532400 |
| string |
to_date(string timestamp) |
返回时间中的年月日: to_date(“1970-01-01 00:00:00″) = “1970-01-01″ |
| string |
to_dates(string date) |
给定一个日期date,返回一个天数(0年以来的天数)。 |
| int |
year(string date) |
返回指定时间的年份,范围在1000到9999,或为”零”日期的0。 |
| int |
month(string date) |
返回指定时间的月份,范围为1至12月,或0一个月的一部分,如’0000-00-00′或’2008-00-00′的日期。 |
| int |
day(string date) dayofmonth(date) |
返回指定时间的日期。 |
| int |
hour(string date) |
返回指定时间的小时,范围为0到23。 |
| int |
minute(string date) |
返回指定时间的分钟,范围为0到59。 |
| int |
second(string date) |
返回指定时间的秒,范围为0到59。 |
| int |
weekofyear(string date) |
返回指定日期所在一年中的星期号,范围为0到53。 |
| int |
datediff(string enddate, string startdate) |
两个时间参数的日期之差。 |
| int |
date_add(string startdate, int days) |
给定时间,在此基础上加上指定的时间段。 |
| int |
date_sub(string startdate, int days) |
给定时间,在此基础上减去指定的时间段。 |
3.2.5条件函数
| T |
if(boolean testCondition, T valueTrue, T valueFalseOrNull) |
判断是否满足条件,如果满足返回一个值,如果不满足则返回另一个值。 |
| T |
COALESCE(T v1, T v2, … |
返回一组数据中,第一个不为NULL的值,如果均为NULL,返回NULL。 |
| T |
CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END |
当a=b时,返回c;当a=d时,返回e,否则返回f。 |
| T |
CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END |
当值为a时返回b,当值为c时返回d。否则返回e。 |
3.2.6字符函数
| int |
length(string A) |
返回字符串的长度 |
| string |
reverse(string A) |
返回倒序字符串 |
| string |
concat(string A, string B…) |
连接多个字符串,合并为一个字符串,可以接受任意数量的输入字符串 |
| string |
concat_ws(string SEP, string A, string B…) |
链接多个字符串,字符串之间以指定的分隔符分开。 |
| string |
substr(string A, int start) substring(string A, int start) |
从文本字符串中指定的起始位置后的字符。 |
| string |
substr(string A, int start, int len) substring(string A, int start, int len) |
从文本字符串中指定的位置指定长度的字符。 |
| string |
upper(string A) ucase(string A) |
将文本字符串转换成字母全部大写形式 |
| string |
lower(string A) lcase(string A) |
将文本字符串转换成字母全部小写形式 |
| string |
trim(string A) |
删除字符串两端的空格,字符之间的空格保留 |
| string |
ltrim(string A) |
删除字符串左边的空格,其他的空格保留 |
| string |
rtrim(string A) |
删除字符串右边的空格,其他的空格保留 |
| string |
regexp_replace(string A, string B, string C) |
字符串A中的B字符被C字符替代 |
| string |
regexp_extract(string subject, string pattern, int index) |
通过下标返回正则表达式指定的部分。regexp_extract(‘foothebar’, ‘foo(.*?)(bar)’, 2) returns ‘bar.’ |
| string |
parse_url(string urlString, string partToExtract [, string keyToExtract]) |
返回URL指定的部分。parse_url(‘http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1′, ‘HOST’) 返回:’facebook.com’ |
| string |
get_json_object(string json_string, string path) |
select a.timestamp, get_json_object(a.appevents, ‘$.eventid’), get_json_object(a.appenvets, ‘$.eventname’) from log a; |
| string |
space(int n) |
返回指定数量的空格 |
| string |
repeat(string str, int n) |
重复N次字符串 |
| int |
ascii(string str) |
返回字符串中首字符的数字值 |
| string |
lpad(string str, int len, string pad) |
返回指定长度的字符串,给定字符串长度小于指定长度时,由指定字符从左侧填补。 |
| string |
rpad(string str, int len, string pad) |
返回指定长度的字符串,给定字符串长度小于指定长度时,由指定字符从右侧填补。 |
| array |
split(string str, string pat) |
将字符串转换为数组。 |
| int |
find_in_set(string str, string strList) |
返回字符串str第一次在strlist出现的位置。如果任一参数为NULL,返回NULL;如果第一个参数包含逗号,返回0。 |
| array<array> |
sentences(string str, string lang, string locale) |
将字符串中内容按语句分组,每个单词间以逗号分隔,最后返回数组。 例如sentences(‘Hello there! How are you?’) 返回:( (“Hello”, “there”), (“How”, “are”, “you”) ) |
| array<struct<string,double>> |
ngrams(array<array>, int N, int K, int pf) |
SELECT ngrams(sentences(lower(tweet)), 2, 100 [, 1000]) FROM twitter; |
| array<struct<string,double>> |
context_ngrams(array<array>, array, int K, int pf) |
SELECT context_ngrams(sentences(lower(tweet)), array(null,null), 100, [, 1000]) FROM twitter; |
3.3内置的聚合函数(UDAF)
| bigint |
count(*) , count(expr), count(DISTINCT expr[, expr_., expr_.]) |
返回记录条数。 |
| double |
sum(col), sum(DISTINCT col) |
求和 |
| double |
avg(col), avg(DISTINCT col) |
求平均值 |
| double |
min(col) |
返回指定列中最小值 |
| double |
max(col) |
返回指定列中最大值 |
| double |
var_pop(col) |
返回指定列的方差 |
| double |
var_samp(col) |
返回指定列的样本方差 |
| double |
stddev_pop(col) |
返回指定列的偏差 |
| double |
stddev_samp(col) |
返回指定列的样本偏差 |
| double |
covar_pop(col1, col2) |
两列数值协方差 |
| double |
covar_samp(col1, col2) |
两列数值样本协方差 |
| double |
corr(col1, col2) |
返回两列数值的相关系数 |
| double |
percentile(col, p) |
返回数值区域的百分比数值点。0<=P<=1,否则返回NULL,不支持浮点型数值。 |
| array |
percentile(col, array(p~1,, [, p,,2,,]…)) |
返回数值区域的一组百分比值分别对应的数值点。0<=P<=1,否则返回NULL,不支持浮点型数值。 |
| double |
percentile_approx(col, p[, B]) |
Returns an approximate p^th^ percentile of a numeric column (including floating point types) in the group. The B parameter controls approximation accuracy at the cost of memory. Higher values yield better approximations, and the default is 10,000. When the number of distinct values in col is smaller than B, this gives an exact percentile value. |
| array |
percentile_approx(col, array(p~1,, [, p,,2_]…) [, B]) |
Same as above, but accepts and returns an array of percentile values instead of a single one. |
| array<struct{‘x’,'y’}> |
histogram_numeric(col, b) |
Computes a histogram of a numeric column in the group using b non-uniformly spaced bins. The output is an array of size b of double-valued (x,y) coordinates that represent the bin centers and heights |
| array |
collect_set(col) |
返回无重复记录 |
3.4内置表生成函数(UDTF)
| 数组 |
explode(arraya) |
数组一条记录中有多个参数,将参数拆分,每个参数生成一列。 |
| |
json_tuple |
get_json_object 语句:select a.timestamp, get_json_object(a.appevents, ‘$.eventid’), get_json_object(a.appenvets, ‘$.eventname’) from log a; json_tuple语句: select a.timestamp, b.* from log a lateral view json_tuple(a.appevent, ‘eventid’, ‘eventname’) b as f1, f2 |
3.5自定义函数
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.2</version>
</dependency>
- Lower.java继承org.apache.hadoop.hive.ql.UDF (需要实现evaluate函数,evaluate函数支持重载。)
package com.test;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public class MyLower extends UDF {
public Text evaluate(final Text s) {
if (s == null) {
return null;
}
return new Text(s.toString().toLowerCase());
}
}
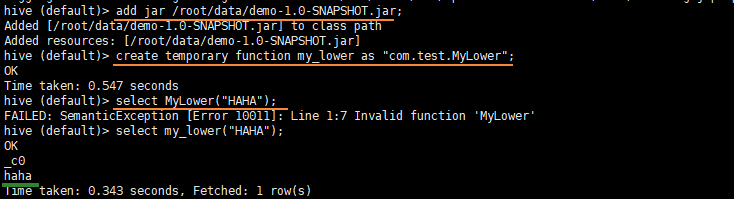
- 方式1:打成jar包上传至集群本地
- 将jar包添加到hive的classpath
add jar /root/data/demo-1.0-SNAPSHOT.jar;
- 创建临时函数与开发好的java class关联
create temporary function my_lower as "com.test.MyLower";
- 即可在hql中使用自定义的函数
hive (default)> select my_lower("HAHA");

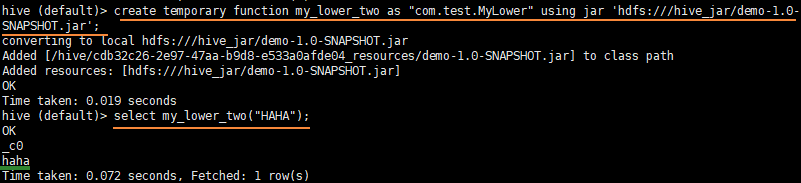
- 方式2(推荐):打成jar包上传至集群Hdfs
- 创建临时函数与开发好的java class关联
create temporary function my_lower_two as "com.test.MyLower" using jar 'hdfs:///hive_jar/demo-1.0-SNAPSHOT.jar';
- 即可在hql中使用自定义的函数
hive (default)> select my_lower_two ("HAHA");

4 hive set命令
- 在hive CLI控制台可以通过set对hive中的参数进行查询、设置
- set设置:
set hive.cli.print.header=true;
- set查看:
set hive.cli.print.header
- hive参数初始化配置hive历史操作命令集:当前用户家目录下
~/.hivehistory
- 当前用户家目录下的
.hiverc文件
- 如:
~/.hiverc
- 如果没有,可直接创建该文件,将需要设置的参数写到该文件中,hive启动运行时,会加载改文件中的配置。
5 动态分区
1,张三1,12,man,lol-book-movie,chengdu:shuangliu-shanghai:pudong
2,张三2,13,boy,lol-book-movie,chengdu:shuangliu-shanghai:pudong
3,张三3,12,man,lol-book-movie,chengdu:shuangliu-shanghai:pudong
4,张三4,13,boy,lol-book-movie,chengdu:shuangliu-shanghai:pudong
5,张三5,12,man,lol-book-movie,chengdu:shuangliu-shanghai:pudong
6,张三6,13,man,lol-book-movie,chengdu:shuangliu-shanghai:pudong
7,张三7,12,boy,lol-book-movie,chengdu:shuangliu-shanghai:pudong
8,张三8,13,boy,lol-book-movie,chengdu:shuangliu-shanghai:pudong
-
开启支持动态分区
原始数据表建表语句
- 必要参数
set hive.exec.dynamic.partition=true;set hive.exec.dynamic.partition.mode=nostrict;默认:strict(至少有一个分区列是静态分区)
- 相关参数
set hive.exec.max.dynamic.partitions.pernode;每一个执行mr节点上,允许创建的动态分区的最大数量(100)set hive.exec.max.dynamic.partitions;所有执行mr节点上,允许创建的所有动态分区的最大数量(1000)set hive.exec.max.created.files;所有的mr job允许创建的文件的最大数量(100000)
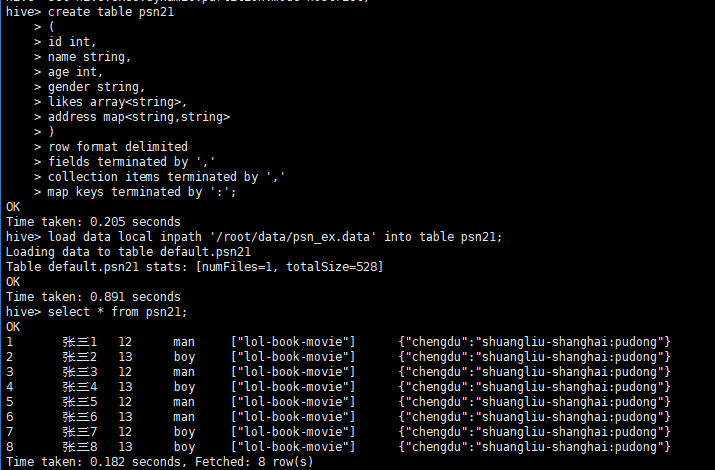
create table psn21
(
id int,
name string,
age int,
gender string,
likes array<string>,
address map<string,string>
)
row format delimited
fields terminated by ','
collection items terminated by ','
map keys terminated by ':';
- 灌库
load data local inpath '/root/data/psn_ex.data' into table psn21;
- 分区表建表语句
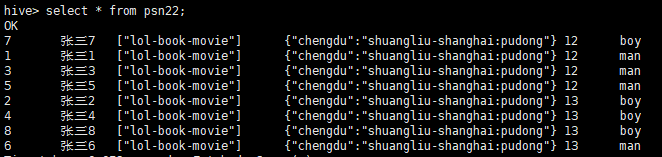
create table psn22
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(age int,gender string)
row format delimited
fields terminated by ','
collection items terminated by ','
map keys terminated by ':';
from psn21
insert into psn22 partition(age, gender)
select id, name, likes, address, age, gender;

6 分桶
- 分桶表是对列值取哈希值的方式,将不同数据放到不同文件中存储。
- 对于hive中每一个表、分区都可以进一步进行分桶。
- 由列的哈希值除以桶的个数来决定每条数据划分在哪个桶中。
-
适用场景:数据抽样( sampling )
6.1开启支持分桶
set hive.enforce.bucketing=true;- 默认:false;设置为true之后,mr运行时会根据bucket的个数自动分配reduce task个数。(用户也可以通过mapred.reduce.tasks自己设置reduce任务个数,但分桶时不推荐使用)
-
注意:一次作业产生的桶(文件数量)和reduce task个数一致。
6.2往分桶表中加载数据
insert into table bucket_table select columns from tbl;-
insert overwrite table bucket_table select columns from tbl;
6.3抽样查询(目前就这一个应用场景)
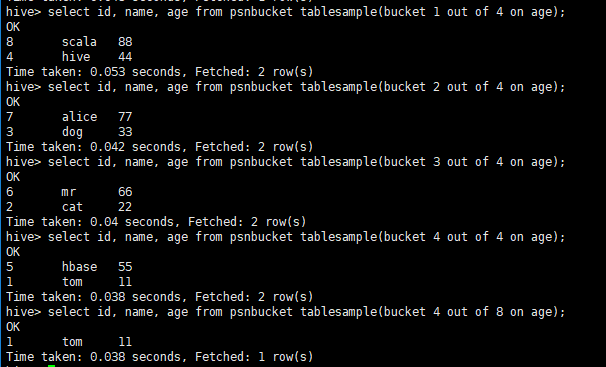
select * from bucket_table tablesample(bucket 1 out of 4 on columns);- TABLESAMPLE语法:
- TABLESAMPLE(BUCKET x OUT OF y)
- x:表示从哪个bucket开始抽取数据
- y:必须为该表总bucket数的倍数或因子
- 假设x=2,y=4,桶32:那么从2号桶取数据,取8份数据。(2,6,10,14,18,22,26,30)
-
假设x=3,y=256,桶32:那么从3号桶取数据,取1/8份数据。(一般取因子不取倍数)
6.4demo
- 设置参数
set hive.enforce.bucketing=true;
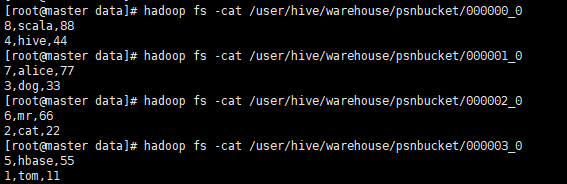
- 准备数据bucket.data
1,tom,11
2,cat,22
3,dog,33
4,hive,44
5,hbase,55
6,mr,66
7,alice,77
8,scala,88
CREATE TABLE psn31( id INT, name STRING, age INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
- 加载数据
load data local inpath '/root/data/bucket.data' into table psn31;
- 创建分桶表语句
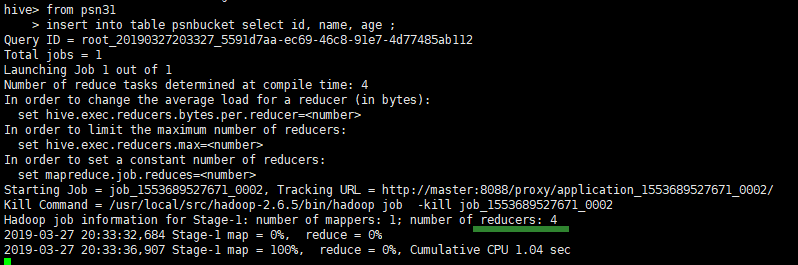
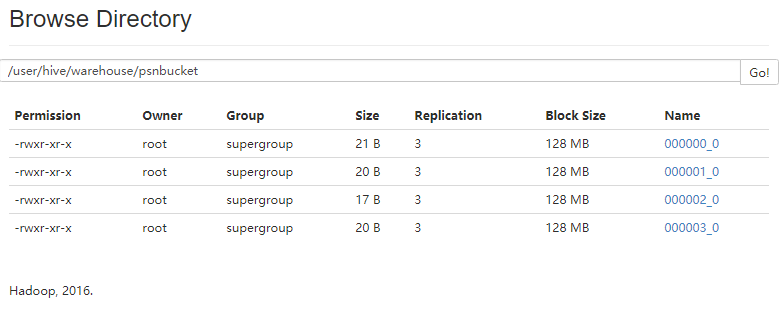
CREATE TABLE psnbucket( id INT, name STRING, age INT)
CLUSTERED BY (age) INTO 4 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
from psn31
insert into table psnbucket select id, name, age ;
- 抽样
select id, name, age from psnbucket tablesample(bucket 2 out of 4 on age);
7 Lateral View
- Lateral View用于和UDTF函数(explode、split)结合来使用。
- 首先通过UDTF函数拆分成多行,再将多行结果组合成一个支持别名的虚拟表。
- 主要解决在select使用UDTF做查询过程中,查询只能包含单个UDTF,不能包含其他字段、以及多个UDTF的问题
- 语法:
LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias)
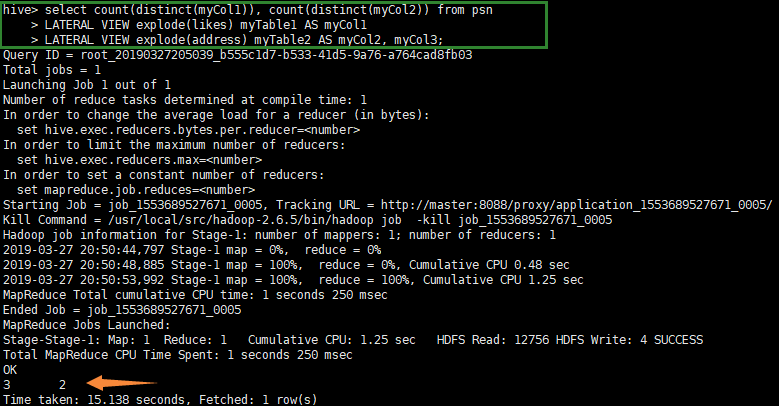
- 统计人员表中共有多少种爱好、多少个城市?
select count(distinct(myCol1)), count(distinct(myCol2)) from psn
LATERAL VIEW explode(likes) myTable1 AS myCol1
LATERAL VIEW explode(address) myTable2 AS myCol2, myCol3;
8 视图
- 和关系型数据库中的普通视图一样,hive也支持视图
- 特点:创建视图:
- 不支持物化视图
- 只能查询,不能做加载数据操作
- 视图的创建,只是保存一份元数据,查询视图时才执行对应的子查询
- view定义中若包含了ORDER BY/LIMIT语句,当查询视图时也进行ORDER BY/LIMIT语句操作,view当中定义的优先级更高
- view支持迭代视图
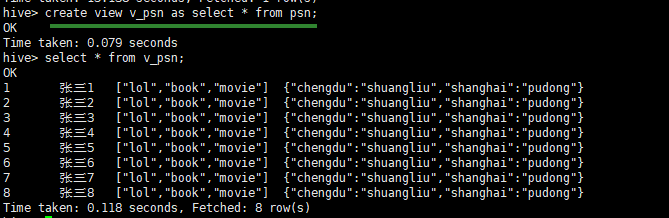
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name
[(column_name [COMMENT column_comment], ...) ]
[COMMENT view_comment]
[TBLPROPERTIES (property_name = property_value, ...)]
AS SELECT ... ;
- 查询视图:
select colums from view;
- 删除视图:
DROP VIEW [IF EXISTS] [db_name.]view_name;
- demo
9 索引
- 目的:优化查询以及检索性能
- 创建索引(2种方式):
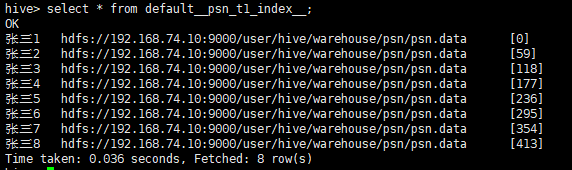
create index t1_index on table psn(name)
as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild
in table t1_index_table;
- as:指定索引器;
- in table:指定索引表,若不指定默认生成在default__psn_t1_index__表中
create index t1_index on table psn(name)
as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild;
- 查询索引
show index on psn;
- 重建索引(建立索引之后必须重建索引才能生效)
ALTER INDEX t1_index ON psn REBUILD;
- 删除索引
DROP INDEX IF EXISTS t1_index ON psn;
10 hive运行方式
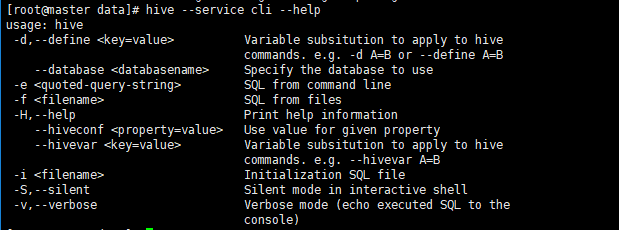
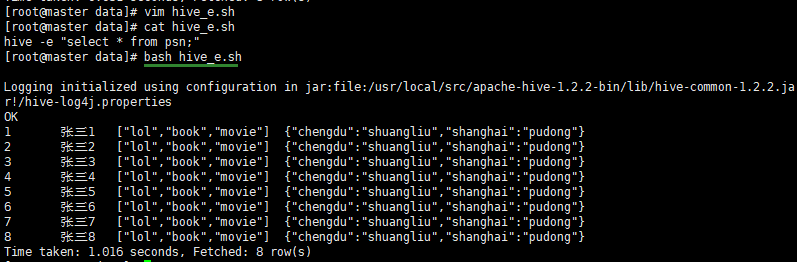
- 命令行方式cli:控制台模式脚本运行方式(实际生产环境中用最多)
- 与hdfs交互
- 例:dfs –ls /
- 与Linux交互 !开头
- 例: !pwd
- JDBC方式:hiveserver2
- web GUI接口 (hwi、hue等)
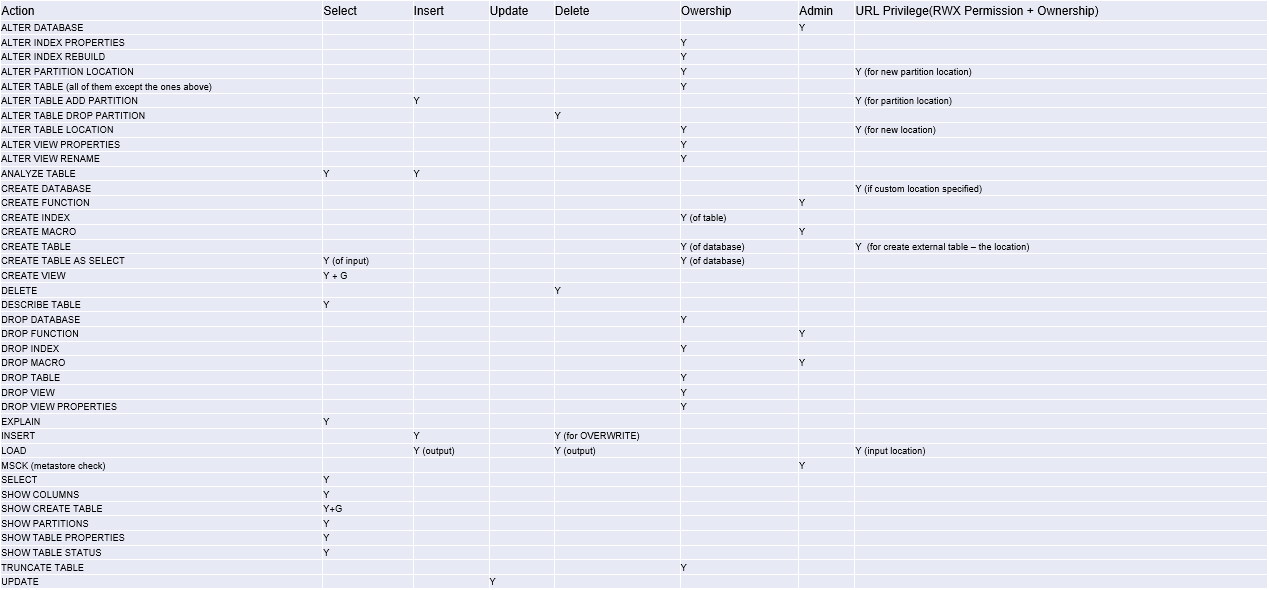
11 权限管理
12 Hive优化
- 核心思想:把Hive SQL 当做Mapreduce程序去优化
- 以下SQL不会转为Mapreduce来执行
- select仅查询本表字段
- where仅对本表字段做条件过滤
- Explain 显示执行计划
- Hive抓取策略:
- Hive中对某些情况的查询不需要使用MapReduce计算
Set hive.fetch.task.conversion=none/more;
- Hive运行方式:
- 本地模式(
set hive.exec.mode.local.auto=true;)
hive.exec.mode.local.auto.inputbytes.max默认值为128M表示加载文件的最大值,若大于该配置仍会以集群方式来运行!
- 集群模式(默认)
- 并行计算
- 通过设置以下参数开启并行模式:
set hive.exec.parallel=true;
- 注意:
hive.exec.parallel.thread.number(一次SQL计算中允许并行执行的job个数的最大值)
- 严格模式
- 通过设置以下参数开启严格模式:
set hive.mapred.mode=strict;(默认为:nonstrict非严格模式)
- 查询限制:
- 1、对于分区表,必须添加where对于分区字段的条件过滤;
- 2、order by语句必须包含limit输出限制;
- 3、限制执行笛卡尔积的查询。
- Hive排序
- Order By - 对于查询结果做全排序,只允许有一个reduce处理(当数据量较大时,应慎用。严格模式下,必须结合limit来使用)
- Sort By - 对于单个reduce的数据进行排序
- Distribute By - 分区排序,经常和Sort By结合使用
- Cluster By - 相当于 Sort By + Distribute By(Cluster By不能通过asc、desc的方式指定排序规则;可通过 distribute by column sort by column asc|desc 的方式)
- Hive Join
- Map-Side聚合
- 通过设置以下参数开启在Map端的聚合:
set hive.map.aggr=true;
- 相关配置参数:
hive.groupby.mapaggr.checkinterval: map端group by执行聚合时处理的多少行数据(默认:100000)hive.map.aggr.hash.min.reduction: 进行聚合的最小比例(预先对100000条数据做聚合,若聚合之后的数据量/100000的值大于该配置0.5,则不会聚合)hive.map.aggr.hash.percentmemory: map端聚合使用的内存的最大值hive.map.aggr.hash.force.flush.memory.threshold: map端做聚合操作是hash表的最大可用内容,大于该值则会触发flushhive.groupby.skewindata是否对GroupBy产生的数据倾斜做优化,默认为false
- 合并小文件
- 文件数目小,容易在文件存储端造成压力,给hdfs造成压力,影响效率
- 设置合并属性
- 是否合并map输出文件:hive.merge.mapfiles=true
- 是否合并reduce输出文件:hive.merge.mapredfiles=true;
- 合并文件的大小:hive.merge.size.per.task=25610001000
- 去重统计
- 数据量小的时候无所谓,数据量大的情况下,由于COUNT DISTINCT操作需要用一个Reduce Task来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替换
- 控制Hive中Map以及Reduce的数量
- Map数量相关的参数
mapred.max.split.size一个split的最大值,即每个map处理文件的最大值mapred.min.split.size.per.node一个节点上split的最小值mapred.min.split.size.per.rack一个机架上split的最小值
- Reduce数量相关的参数
mapred.reduce.tasks强制指定reduce任务的数量hive.exec.reducers.bytes.per.reducer每个reduce任务处理的数据量hive.exec.reducers.max每个任务最大的reduce数
- Hive - JVM重用
- 适用场景:
- 通过
set mapred.job.reuse.jvm.num.tasks=n; 来设置(n为task插槽个数)
- 缺点:设置开启之后,task插槽会一直占用资源,不论是否有task运行,直到所有的task即整个job全部执行完成时,才会释放所有的task插槽资源!





 浙公网安备 33010602011771号
浙公网安备 33010602011771号