10 Spark的理解
1、Spark是一个计算框架
- MR是批量计算框架,Spark-Core是批量计算框架
- Spark相比MR速度快,MR作为一个job,在中间环节中结果是落地的(会经过磁盘交换),Spark计算过程中数据流转都是在内存的(减少了对HDFS的依赖)
- MR:多进程模型(缺点:每个任务启动时间长,所以不适合于低延迟的任务
- 优点:资源隔离,稳定性高,开发过程中不涉及内存锁(互斥锁、读写锁)的开发)
- Spark:多线程模型(缺点:稳定性差----因为可能使用到统一进程空间,需要锁
- 优点:速度快,适合低延迟的任务,适合于内存密集型任务)
- 一个机器节点,所有的任务都会运载jvm进程(executor进程),
- 每一个进程包含一个executor对象,在对象内部会维持一个线程池,提高效率,每一个线程执行一个task
2、Spark的运行模式:
- (1)单机模式:方便人工调试
- (2)Standalone模式:自己独立一套集群(master/client/slave),缺点:资源不利于充分利用
- (3)Yarn模式:
- 1)Yarn-Client模式:Driver运行在本地
- 适合交互调试
- 2)Yarn-Cluster模式:Driver运行在集群(AM)
- 正式提交任务的模式(remote)
- 1)Yarn-Client模式:Driver运行在本地
S p a r k 和 H a d o o p 作业之间的区别
- • Hadoop中:
- 一个MapReduce程序就是一个job,而一个job里面可以有一个或多个Task,Task又可以区分为Map Task和Reduce Task
- MapReduce中的每个Task分别在自己的进程中运行,当该Task运行完时,进程也就结束

- • Spark中:
- Application:spark-submit提交的程序
- Driver:完成任务的调度以及和executor和cluster manager进 行协调
- Executor:每个Spark executor作为一个YARN容器 (container)运行
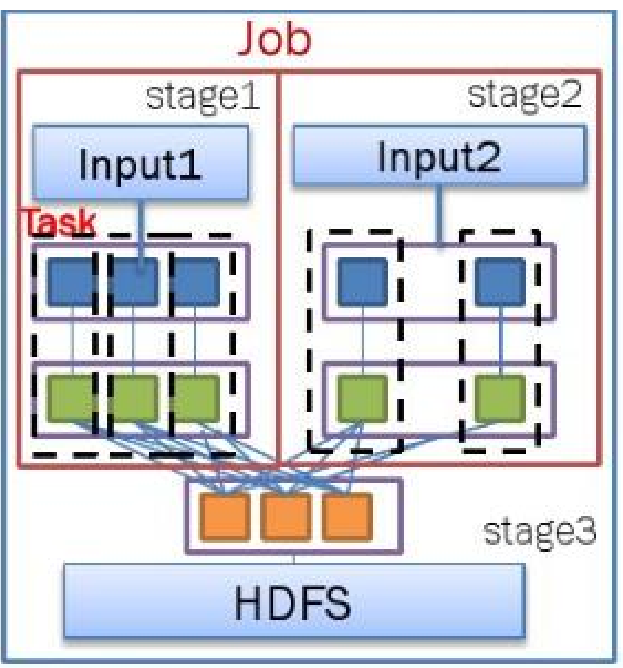
- Job:和MR中Job不一样。MR中Job主要是Map或者Reduce Job。而Spark的Job其实很好区别,一个action算子就算一个 Job,比方说count,first等
- Task:是Spark中最新的执行单元。RDD一般是带有partitions 的,每个partition在一个executor上的执行可以认为是一个 Task
- Stage:是spark中独有的。一般而言一个Job会切换成一定数量 的stage。各个stage之间按照顺序执行
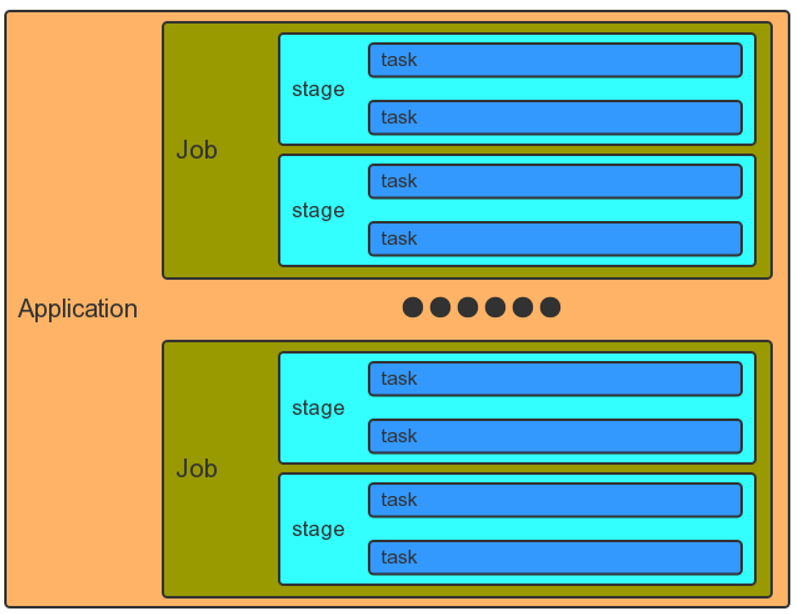
- • Spark中:
- 应用程序: 由一个driver program和 多个job构成
- Job : 由多个stage组成
- Stage : 对应一个taskset
- Taskset : 对应一组关联的相互之间没 有shuffle依赖关系的task组成
- Task : 任务最小的工作单元
- • Driver Program:
- (驱动程序)是Spark的核心组件
- 构建SparkContext(Spark应用的入口,创建需要的变量,还包含集群的配置信息等)
- 将用户提交的job转换为DAG图(类似数据处理的流程图)
- 根据策略将DAG图划分为多个stage,根据分区从而生成一系列tasks
- 根据tasks要求向RM申请资源 – 提交任务并检测任务状态
- • Executor:
- 真正执行task的单元,一个Work Node上可以有多个Executor
Spark环境安装
Spark环境安装
0. Spark源码包下载
mirror.bit.edu.cn/apache/spark/
1. 集群环境
Master 192.168.192.10
Slave1 192.168.192.11
Slave2 192.168.192.12
2. 下载软件包
Master节点
wget http://mirror.bit.edu.cn/apache/spark/spark-1.6.0/spark-1.6.0-bin-hadoop2.6.tgz
tar -zxvf spark-1.6.0-bin-hadoop2.6.tgz
wget https://downloads.lightbend.com/scala/2.10.5/scala-2.10.5.tgz
tar -zxvf scala-2.10.5.tgz3. 修改Spark配置文件
cd /usr/local/src/spark-1.6.0-bin-hadoop2.6/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.shexport SCALA_HOME=/usr/local/src/scala-2.10.5
export JAVA_HOME=/usr/local/src/jdk1.8.0_191
export HADOOP_HOME=/usr/local/src/hadoop-2.6.5
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_MASTER_IP=master
SPARK_LOCAL_DIRS=/usr/local/src/spark-1.6.0-bin-hadoop2.6
SPARK_DRIVER_MEMORY=1G
export SPARK_PID_DIR=/home/ap/cdahdp/app/pids
cp slaves.template slaves
vim slavesslave1
slave2
4. 拷贝安装包
scp -r /usr/local/src/spark-1.6.0-bin-hadoop2.6 root@slave1:/usr/local/src/spark-1.6.0-bin-hadoop2.6
scp -r /usr/local/src/spark-1.6.0-bin-hadoop2.6 root@slave2:/usr/local/src/spark-1.6.0-bin-hadoop2.6
scp -r /usr/local/src/scala-2.10.5 root@slave1:/usr/local/src/scala-2.10.5
scp -r /usr/local/src/scala-2.10.5 root@slave2:/usr/local/src/scala-2.10.5
5. 启动集群
cd /usr/local/src/spark-1.6.0-bin-hadoop2.6/sbin
./start-all.sh


6. 网页监控面板
master:8080 或远程192.168.192.10:8080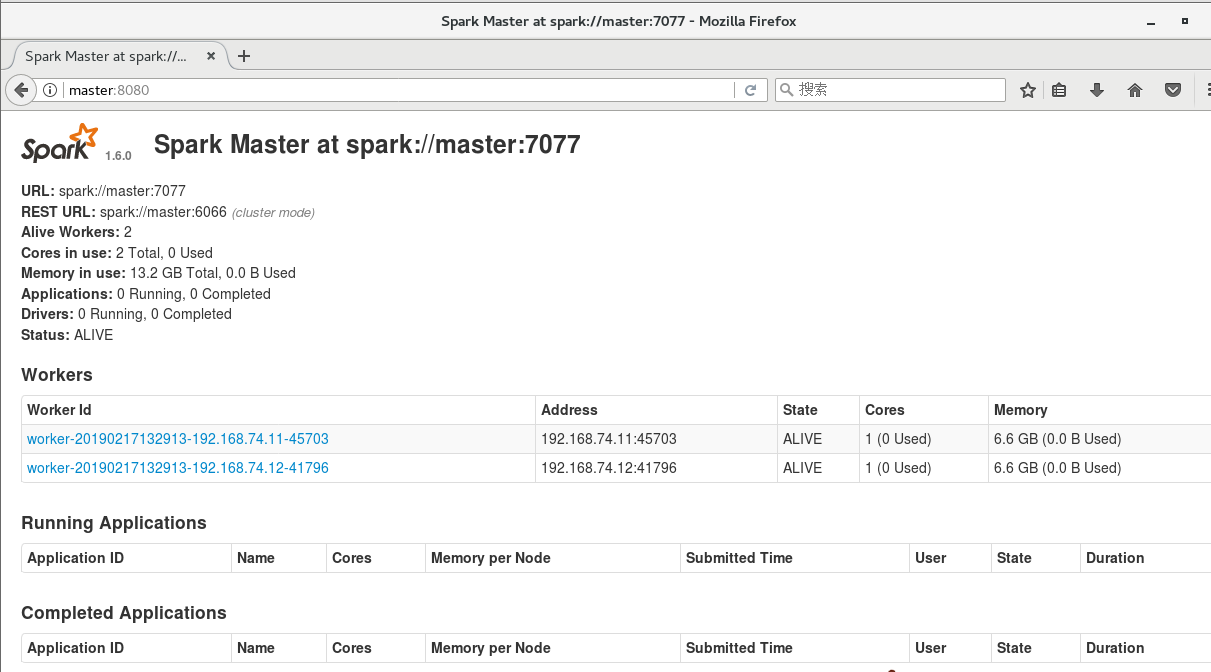
7. 验证
本地模式
不会在监控页面显示
cd /usr/local/src/spark-1.6.0-bin-hadoop2.6
#local[2]是本地启用几个进程模拟
./bin/run-example SparkPi 10 --master local[2]
集群Standlone(不需要启动hadoop)
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 lib/spark-examples-1.6.0-hadoop2.6.0.jar 100运行中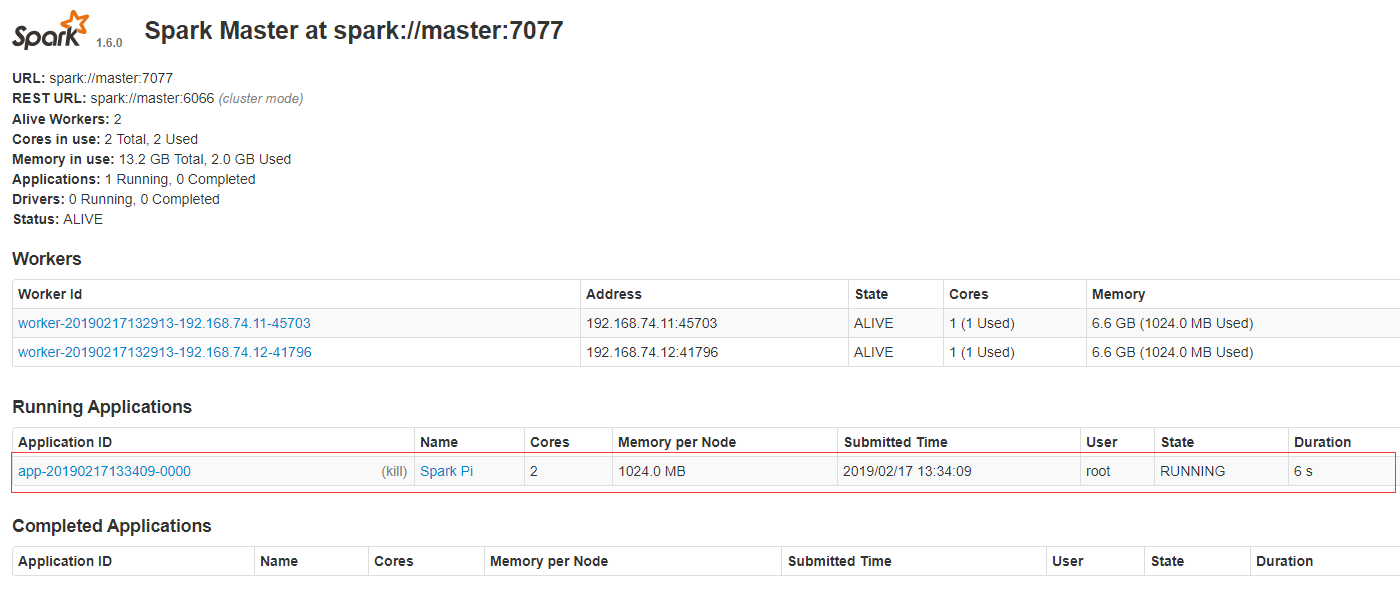
完成后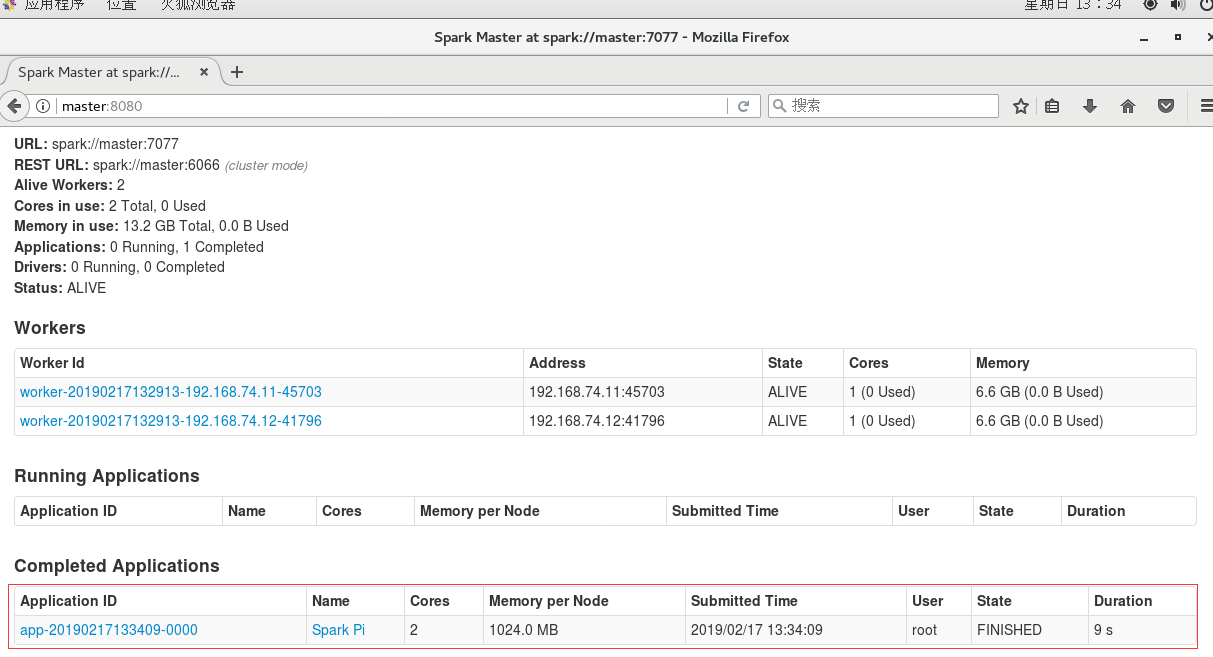
集群(需要启动hadoop)
Spark on Yarn
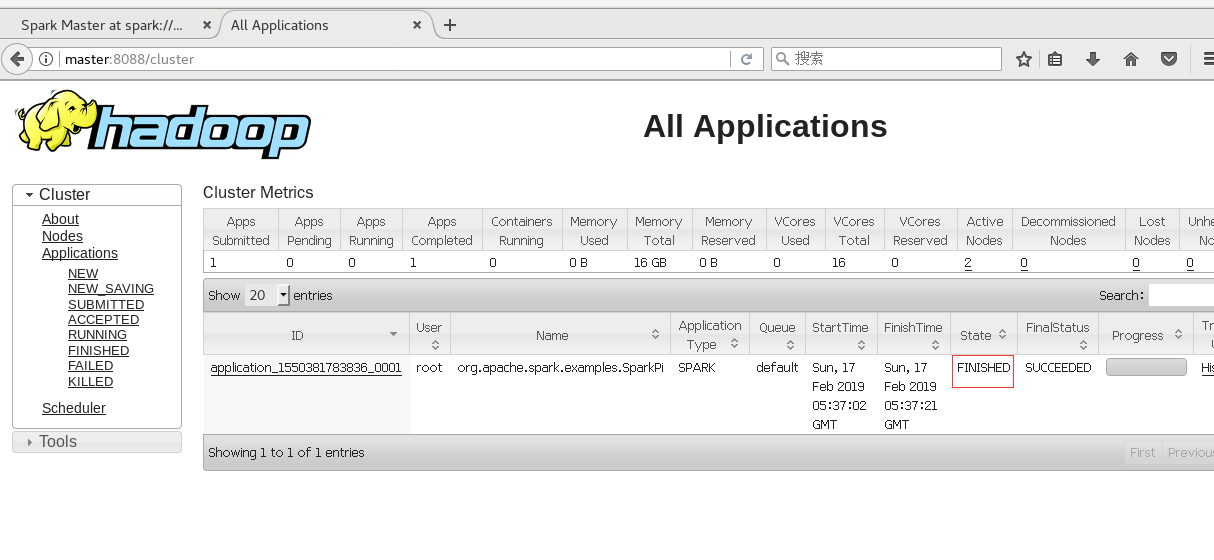
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster lib/spark-examples-1.6.0-hadoop2.6.0.jar 10由Yarn管理在8088监控页面查看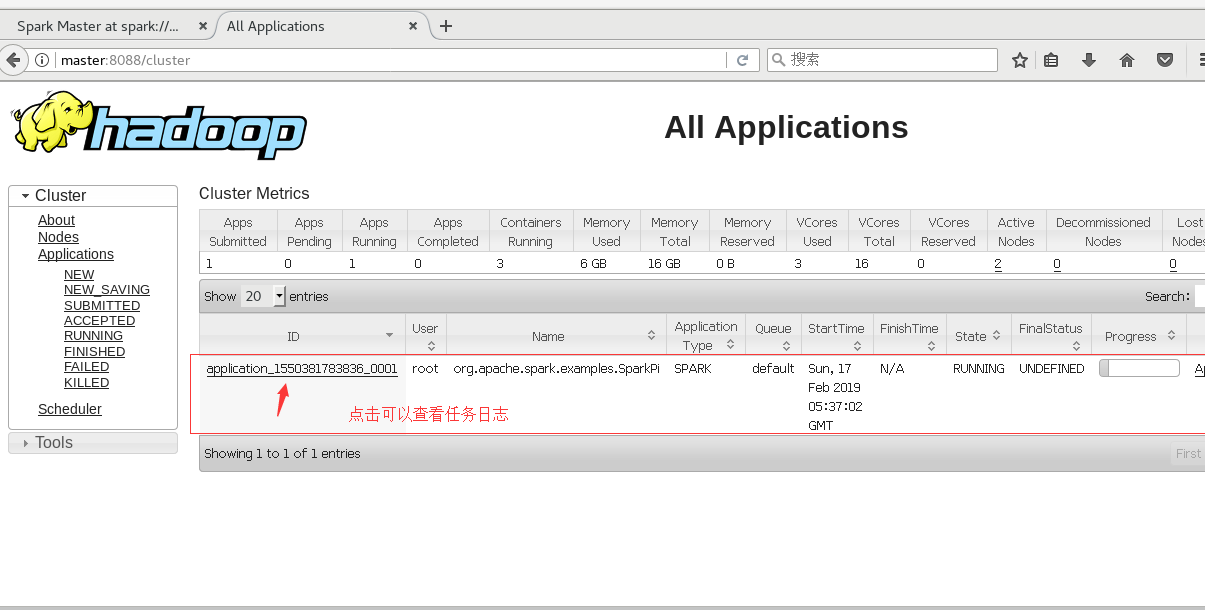
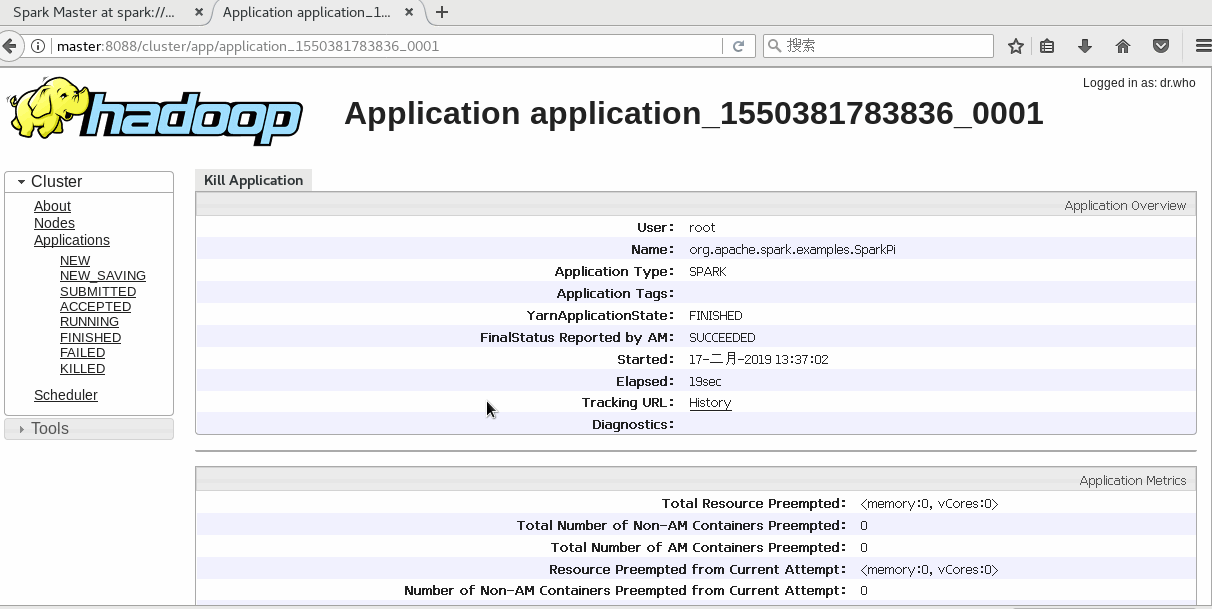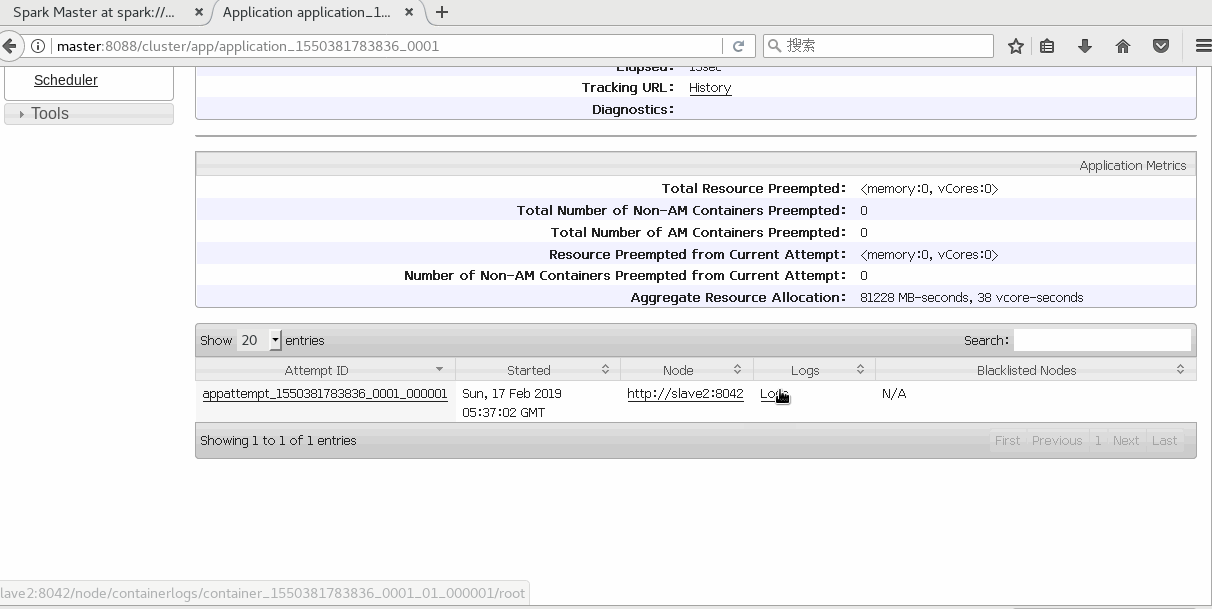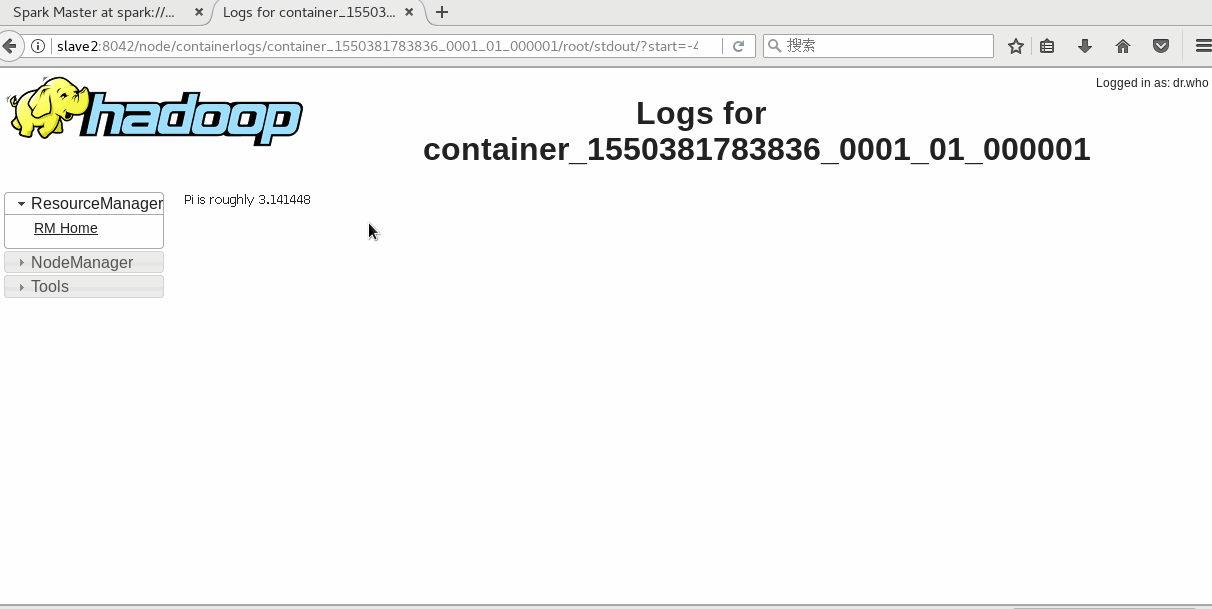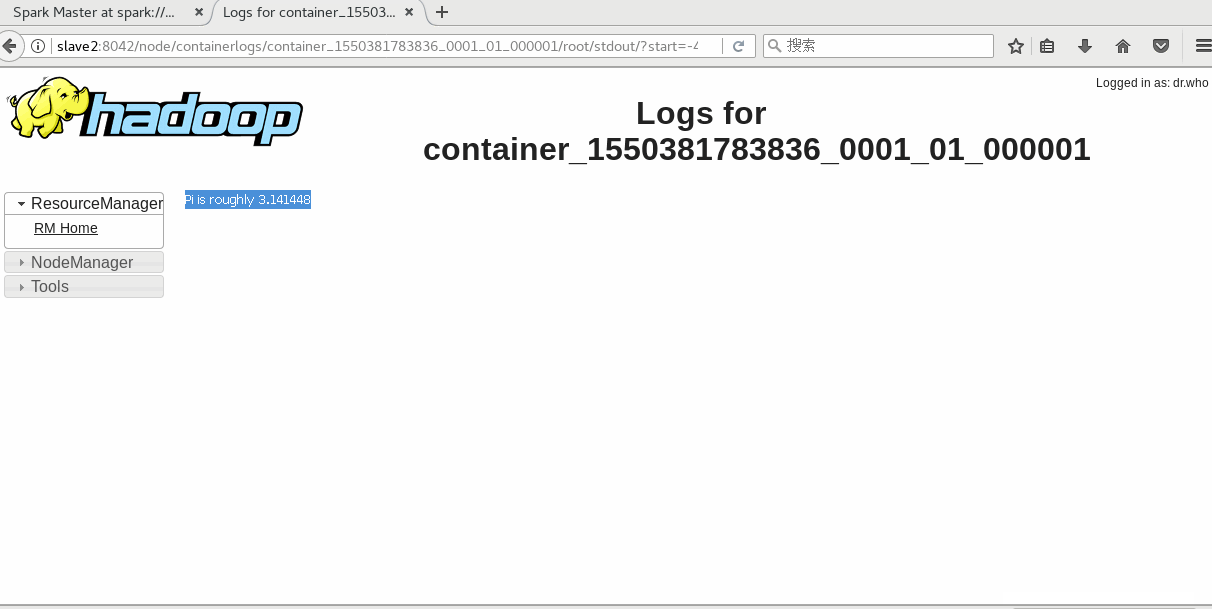
Spark History配置
- 创建目录
hadoop fs -mkdir -p /user/spark/eventlogs - 修改env文件
vim spark-env.sh拷贝defaults文件cp spark-defaults.conf.template spark-defaults.conf- 添加
SPARK_HISTORY_OPTS=-Dspark.history.fs.logDirectory=hdfs://master:9000/user/spark/eventlogs
- 添加
- 修改defaults文件
vim spark-defaults.conf
添加内容如下
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/user/spark/eventlogs
spark.eventLog.compress true- 启动日志配置
/usr/local/src/spark-1.6.0-bin-hadoop2.6/sbin/start-history-server.sh
监控端口18080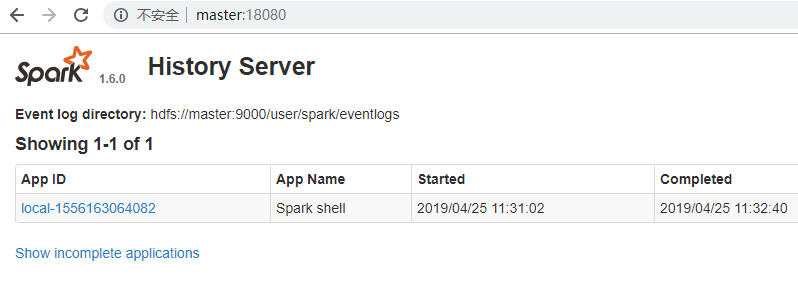
SparkSql兼容hive的配置
- 1 在$SPARK_HOME/conf/下建立hive-site.xml文件
- 2 在$SPARK_HOME/conf/hive-site.xml修改hive.metastore.warehouse.dir的属性值.其默认属性值是/user/hive/warehouse
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
<!-- add by zhou ############################# -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://master:9000/user/hive/warehouse</value>
<description>hive.metastore.warehouse.dir</description>
</property>
<!-- add by zhou ############################# -->
</configuration>- 3 使用spark sql的时候报错:javax.jdo.JDOFatalInternalException: Error creating transactional connection factory
- 原因:可能是没有添加jdbc的驱动
- 解决办法: Spark 中如果没有配置连接驱动,在spark/conf 目录下编辑spark-env.sh 添加驱动配置
- 例如:
export SPARK_CLASSPATH=$SPARK_CLASSPATH:/usr/local/src/spark-1.6.0-bin-hadoop2.6/lib/mysql-connector-java-5.1.46.jar - jar包从hive环境中拷贝的
Spark环境安装
Spark环境安装
0. Spark源码包下载
mirror.bit.edu.cn/apache/spark/
1. 集群环境
Master 192.168.192.10
Slave1 192.168.192.11
Slave2 192.168.192.12
2. 下载软件包
Master节点
wget http://mirror.bit.edu.cn/apache/spark/spark-1.6.0/spark-1.6.0-bin-hadoop2.6.tgz
tar -zxvf spark-1.6.0-bin-hadoop2.6.tgz
wget https://downloads.lightbend.com/scala/2.10.5/scala-2.10.5.tgz
tar -zxvf scala-2.10.5.tgz3. 修改Spark配置文件
cd /usr/local/src/spark-1.6.0-bin-hadoop2.6/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.shexport SCALA_HOME=/usr/local/src/scala-2.10.5
export JAVA_HOME=/usr/local/src/jdk1.8.0_191
export HADOOP_HOME=/usr/local/src/hadoop-2.6.5
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_MASTER_IP=master
SPARK_LOCAL_DIRS=/usr/local/src/spark-1.6.0-bin-hadoop2.6
SPARK_DRIVER_MEMORY=1G
export SPARK_PID_DIR=/home/ap/cdahdp/app/pids
cp slaves.template slaves
vim slavesslave1
slave2
4. 拷贝安装包
scp -r /usr/local/src/spark-1.6.0-bin-hadoop2.6 root@slave1:/usr/local/src/spark-1.6.0-bin-hadoop2.6
scp -r /usr/local/src/spark-1.6.0-bin-hadoop2.6 root@slave2:/usr/local/src/spark-1.6.0-bin-hadoop2.6
scp -r /usr/local/src/scala-2.10.5 root@slave1:/usr/local/src/scala-2.10.5
scp -r /usr/local/src/scala-2.10.5 root@slave2:/usr/local/src/scala-2.10.5
5. 启动集群
cd /usr/local/src/spark-1.6.0-bin-hadoop2.6/sbin
./start-all.sh
6. 网页监控面板
master:8080 或远程192.168.192.10:8080
7. 验证
本地模式
不会在监控页面显示
cd /usr/local/src/spark-1.6.0-bin-hadoop2.6
#local[2]是本地启用几个进程模拟
./bin/run-example SparkPi 10 --master local[2]
集群Standlone(不需要启动hadoop)
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 lib/spark-examples-1.6.0-hadoop2.6.0.jar 100运行中
完成后
集群(需要启动hadoop)
Spark on Yarn
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster lib/spark-examples-1.6.0-hadoop2.6.0.jar 10由Yarn管理在8088监控页面查看
Spark History配置
- 创建目录
hadoop fs -mkdir -p /user/spark/eventlogs - 修改env文件
vim spark-env.sh拷贝defaults文件cp spark-defaults.conf.template spark-defaults.conf- 添加
SPARK_HISTORY_OPTS=-Dspark.history.fs.logDirectory=hdfs://master:9000/user/spark/eventlogs
- 添加
- 修改defaults文件
vim spark-defaults.conf
添加内容如下
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/user/spark/eventlogs
spark.eventLog.compress true- 启动日志配置
/usr/local/src/spark-1.6.0-bin-hadoop2.6/sbin/start-history-server.sh
监控端口18080
SparkSql兼容hive的配置
- 1 在$SPARK_HOME/conf/下建立hive-site.xml文件
- 2 在$SPARK_HOME/conf/hive-site.xml修改hive.metastore.warehouse.dir的属性值.其默认属性值是/user/hive/warehouse
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
<!-- add by zhou ############################# -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://master:9000/user/hive/warehouse</value>
<description>hive.metastore.warehouse.dir</description>
</property>
<!-- add by zhou ############################# -->
</configuration>- 3 使用spark sql的时候报错:javax.jdo.JDOFatalInternalException: Error creating transactional connection factory
- 原因:可能是没有添加jdbc的驱动
- 解决办法: Spark 中如果没有配置连接驱动,在spark/conf 目录下编辑spark-env.sh 添加驱动配置
- 例如:
export SPARK_CLASSPATH=$SPARK_CLASSPATH:/usr/local/src/spark-1.6.0-bin-hadoop2.6/lib/mysql-connector-java-5.1.46.jar - jar包从hive环境中拷贝的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号