

23 SparkStreaming案例1
0 Strom VS SparkStreaming
- Storm 是一个纯实时的流式处理框,SparkStreaming 是一个准实时的流式处理框架,(微批处理:可以设置时间间隔)
- SparkStreaming 的吞吐量比 Storm 高
- Storm 的事务机制要比 SparkStreaming 好(每个数据只处理一次)
- Storm 支持动态资源调度
- SparkStreaming 的应用程序中可以写 SQL 语句来处理数据,所以 SparkingStreaming 擅
- 长复杂的业务处理,而 Storm 不擅长复杂的业务处理,它擅长简单的汇总型计算(天猫双十一销量)
1 SparkStreaming 执行流程
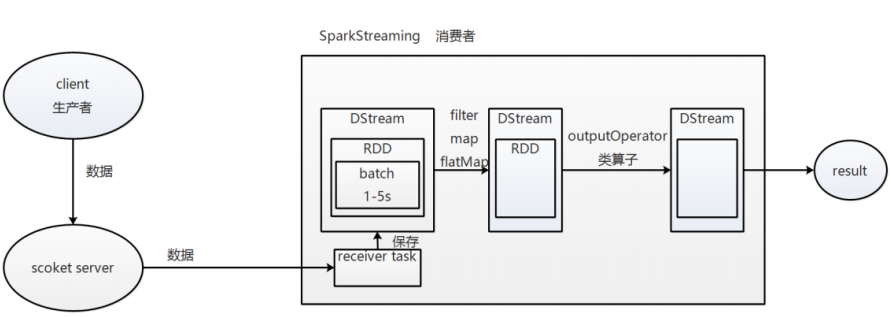
总结:
receiver task 是 7*24h 一直在执行,一直接收数据,将接收到的数据保存到 batch 中,假设 batch interval 为 5s,
那么把接收到的数据每隔 5s 切割到一个 batch,因为 batch 是没有分布式计算的特性的,而 RDD 有,
所以把 batch 封装到 RDD 中,又把 RDD 封装到DStream 中进行计算,在第 5s 的时候,计算前 5s 的数据,
假设计算 5s 的数据只需要 3s,那么第 5-8s 一边计算任务,一边接收数据,第 9-11s 只是接收数据,然后在第 10s 的时
候,循环上面的操作。如果 job 执行时间大于 batch interval,那么未执行的数据会越攒越多,最终导致 Spark集群崩溃。
2demo 监听端口案例
- 使用
nc -lk 9999监控9999端口
- 启动sparkshell测试
/usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-shell --master local[2] - 输入以下代码测试
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
val ssc = new StreamingContext(sc,Seconds(10))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()- 在监听端口中输入一些数据看到测试结果


3.1demo 监听hdfs案例(使用jar包方式)
- 服务器船舰world.txt文件
hadoop java
java scala
python spark- 编写WorldCountStreaming.scala
package com.tzy.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WorldCountStreaming {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("StreamingWorldCount")
val ssc = new StreamingContext(conf,Seconds(10))
//监控hdfs上的data目录
val lines = ssc.textFileStream("hdfs://master:9000/data/")
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}- 上传服务器

-
启动
/usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-submit --master local[2] --class com.tzy.streaming.WorldCountStreaming news-1.0-SNAPSHOT.jar - 上传测试
hadoop fs -put world.txt /data/1
hadoop fs -put world.txt /data/2
hadoop fs -put world.txt /data/3



3.2demo 监听hdfs案例(使用SparkShell加载scala脚本)
- 也可以直接使用scala文件进行测试,编写WorldCountStreaming.scala文件
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
val ssc = new StreamingContext(sc,Seconds(10))
val lines = ssc.textFileStream("hdfs://master:9000/data/")
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()- 进如sparkshell命令
/usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-shell --master local[2] -
加载scala文件
:load /root/test_spark/WorldCountStreaming.scala

-
测试
hadoop fs -put world.txt /data/4

3.3demo 监听hdfs并保存在hdfs案例(使用SparkShell加载scala脚本)
- 编写SaveWorldCountStreaming.scala文件
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
val ssc = new StreamingContext(sc,Seconds(10))
val lines = ssc.textFileStream("hdfs://master:9000/data/")
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
//同3.2案例修改的这一句
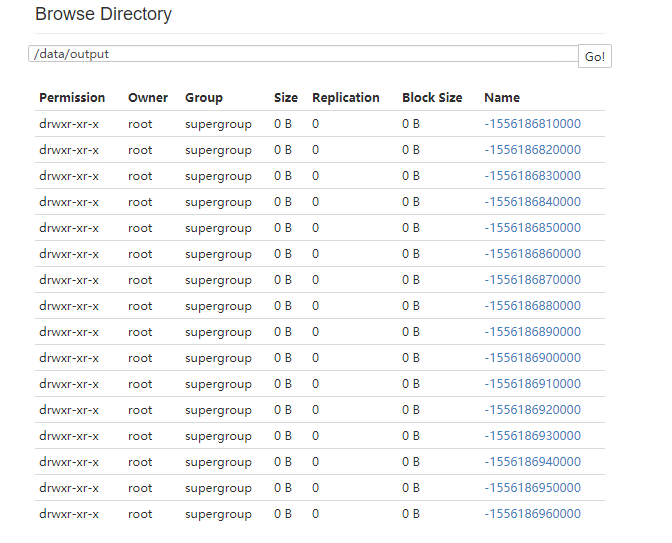
wordCounts.saveAsTextFiles("hdfs://master:9000/data/output/")
ssc.start()
ssc.awaitTermination()- 使用
nc -lk 9999监控9999端口 - 进如sparkshell命令
/usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-shell --master local[2] - 加载scala文件
:load /root/test_spark/SaveWorldCountStreaming.scala - 在监控端测试

4.1demo spark-flume(push)
- Source --> Channel --->Sink(Spark Streaming)
-
进入flume配置目录
cd /usr/local/src/apache-flume-1.6.0-bin/conf -
vim flume_push_streaming.conf编写配置文件
#flume->push->streaming
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
#file control
#a1.sources.r1.type = exec
#a1.sources.r1.command = tail -f /opt/datas/spark_flume/wctotal.log
#a1.sources.r1.shell = /bin/bash -c
#port control
a1.sources.r1.type = netcat
a1.sources.r1.bind = master
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = avro
#window测试192.168.88.1集群测试master
a1.sinks.k1.hostname = 192.168.88.1
a1.sinks.k1.port = 41414
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 1000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1- 编写StreamingFlume.scala
package com.sparkdemo.streaming
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object FlumePushWorldCount {
def main(args: Array[String]): Unit = {
if (args.length != 2) {
System.err.println("Usage: FlumePushWorldCount <hostname> <name>")
System.exit(1)
}
val Array(hostname, port) = args
val conf = new SparkConf().setAppName("FlumePushWorldCount").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(10))
//监控flume上配置的机器和端口---集群测试使用master
val flumeStream = FlumeUtils.createStream(ssc, hostname, port.toInt, StorageLevel.MEMORY_ONLY_SER_2)
//通过事件拿到主体内容
flumeStream.map(x => new String(x.event.getBody.array()).trim)
.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print()
ssc.start()
ssc.awaitTermination()
}
}- 本地测试(修改flume发送的机器)启动本地sparkstreaming程序,注意官网提示必须先启动sparkstreaming
- 配置参数
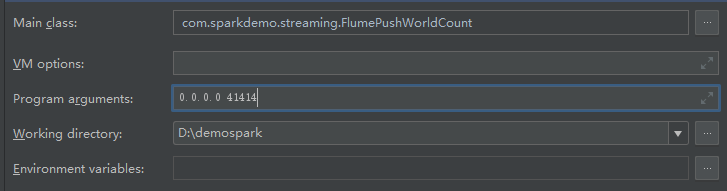
- 现在sparkstreaming已经在跑了

- 启动flume
/usr/local/src/apache-flume-1.6.0-bin/bin/flume-ng agent \ --name a1 \ --conf /usr/local/src/apache-flume-1.6.0-bin/conf \ --conf-file /usr/local/src/apache-flume-1.6.0-bin/conf/flume_push_streaming.conf \ -Dflume.root.logger=DEBUG,console- 启动端口传输
telnet master 44444

- 配置参数
- 集群测试生产无网需要(将spark-streaming-flume_2.10-1.6.0.jar一起上传其他两个包在flume里有)
- 去掉图中代码

- 打包上传

- 启动streaming(注意packages 需要联网)
/usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-submit \ --master local[2] \ --packages org.apache.spark:spark-streaming-flume_2.10:1.6.0 \ --class com.sparkdemo.streaming.FlumePushWorldCount \ sparkdemo-1.0-SNAPSHOT.jar \ master 41414- 修改flume配置文件

- 启动flume
/usr/local/src/apache-flume-1.6.0-bin/bin/flume-ng agent \ --name a1 \ --conf /usr/local/src/apache-flume-1.6.0-bin/conf \ --conf-file /usr/local/src/apache-flume-1.6.0-bin/conf/flume_push_streaming.conf \ -Dflume.root.logger=DEBUG,console- telnet连接测试
telnet master 44444

- 去掉图中代码
/usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-submit \
--master local[2] \
--jars spark-streaming-flume_2.10-1.6.0.jar,\
/usr/local/src/apache-flume-1.6.0-bin/lib/flume-avro-source-1.6.0.jar,\
/usr/local/src/apache-flume-1.6.0-bin/lib/flume-ng-sdk-1.6.0.jar \
--class com.sparkdemo.streaming.FlumePushWorldCount \
sparkdemo-1.0-SNAPSHOT.jar \
master 414144.2demo spark-flume(pull)
vim flume_pull_streaming.conf编写配置文件
#flume->pull->streaming
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
#file control
#a1.sources.r1.type = exec
#a1.sources.r1.command = tail -f /opt/datas/spark_flume/wctotal.log
#a1.sources.r1.shell = /bin/bash -c
#port control
a1.sources.r1.type = netcat
a1.sources.r1.bind = master
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink
#window测试192.168.88.1集群测试master
a1.sinks.k1.hostname = master
a1.sinks.k1.port = 41414
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 1000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1- 编写FlumePullWorldCount.java
package com.sparkdemo.streaming
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object FlumePullWorldCount {
def main(args: Array[String]): Unit = {
if (args.length != 2) {
System.err.println("Usage: FlumePullWorldCount <hostname> <name>")
System.exit(1)
}
val Array(hostname, port) = args
val conf = new SparkConf()//.setAppName("FlumePullWorldCount").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(10))
//监控flume上配置的机器和端口---集群测试使用master
val flumeStream = FlumeUtils.createPollingStream(ssc, hostname, port.toInt, StorageLevel.MEMORY_ONLY_SER_2)
//通过事件拿到主体内容
flumeStream.map(x => new String(x.event.getBody.array()).trim)
.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print()
ssc.start()
ssc.awaitTermination()
}
}- 集群测试
- 去掉图中代码

- 打包上传
- 启动flume(先启动flume)
/usr/local/src/apache-flume-1.6.0-bin/bin/flume-ng agent \ --name a1 \ --conf /usr/local/src/apache-flume-1.6.0-bin/conf \ --conf-file /usr/local/src/apache-flume-1.6.0-bin/conf/flume_pull_streaming.conf \ -Dflume.root.logger=DEBUG,console- 报错
org.apache.flume.FlumeException: Unable to load sink type: org.apache.spark.streaming.flume.sink.SparkSink, class: org.apache.spark.streaming.flume.sink.SparkSink at org.apache.flume.sink.DefaultSinkFactory.getClass(DefaultSinkFactory.java:71) at org.apache.flume.sink.DefaultSinkFactory.create(DefaultSinkFactory.java:43) at org.apache.flume.node.AbstractConfigurationProvider.loadSinks(AbstractConfigurationProvider.java:410) at org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:98) at org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:140) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: java.lang.ClassNotFoundException: org.apache.spark.streaming.flume.sink.SparkSink at java.net.URLClassLoader.findClass(URLClassLoader.java:382) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:264) at org.apache.flume.sink.DefaultSinkFactory.getClass(DefaultSinkFactory.java:69) ... 11 more- 解决:将如下jar包复制到flume的lib目录

- 启动streaming(注意packages 需要联网)
/usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-submit \ --master local[2] \ --packages org.apache.spark:spark-streaming-flume_2.10:1.6.0 \ --class com.sparkdemo.streaming.FlumePullWorldCount \ sparkdemo-1.0-SNAPSHOT.jar \ master 41414- telnet连接测试
telnet master 44444

- 去掉图中代码
5.1demo SparkStreaming-kafka(Receiver)
5.1.1kafka验证
- 创建一个topic
/usr/local/src/kafka_2.11-1.1.1/bin/kafka-topics.sh --create --zookeeper master:2181 --replication-factor 1 --partitions 1 --topic kafka_streaming_topic-
查看topic
/usr/local/src/kafka_2.11-1.1.1/bin/kafka-topics.sh --list --zookeeper master:2181
-
生产
/usr/local/src/kafka_2.11-1.1.1/bin/kafka-console-producer.sh --broker-list master:9092 --topic kafka_streaming_topic -
消费
/usr/local/src/kafka_2.11-1.1.1/bin/kafka-console-consumer.sh --zookeeper master:2181 --topic kafka_streaming_topic

- 删除
/usr/local/src/kafka_2.11-1.1.1/bin/kafka-topics.sh --delete --zookeeper master:2181,slave1:2181,slave2:2181 --topic kafka_streaming_topic- 查看描述
/usr/local/src/kafka_2.11-1.1.1/bin/kafka-topics.sh --zookeeper master:2181,slave1:2181,slave2:2181 --describe --topic kafka_streaming_topic5.1.2SparkStreaming连接kafka
- 编写KafkaReceiverWorldCount.scala
package com.sparkdemo.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object KafkaReceiverWorldCount {
def main(args: Array[String]): Unit = {
if (args.length != 4) {
System.err.println("Usage: KafkaReceiverWorldCount <zkQuorum> <group> <topics> <numThreads>")
System.exit(1)
}
val Array(zkQuorum, group, topics, numThreads) = args
val conf = new SparkConf().setAppName("KafkaReceiverWorldCount").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(10))
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
//Streaming对接kafka
val messages = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap)
messages.map(_._2).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print()
ssc.start()
ssc.awaitTermination()
}
}- 本地测试
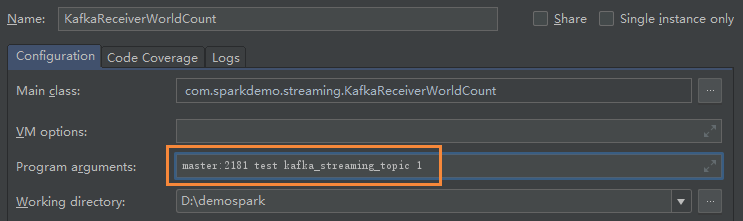
- 创建生产者生产数据
/usr/local/src/kafka_2.11-1.1.1/bin/kafka-console-producer.sh --broker-list master:9092 --topic kafka_streaming_topic
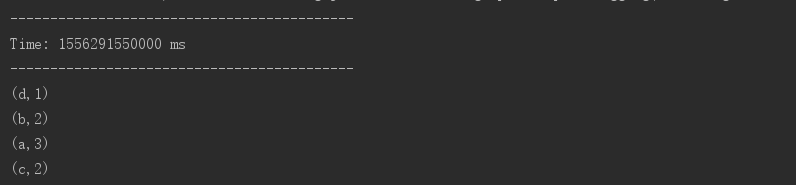
- 创建生产者生产数据
- 集群测试生产环境提交代码(无网)
- 去掉

- 打包上传

- 提交spark作业(需有网络)
/usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-submit \ --class com.sparkdemo.streaming.KafkaReceiverWorldCount \ --master local[2] \ --name KafkaReceiverWorldCount \ --packages org.apache.spark:spark-streaming-kafka_2.10:1.6.0 \ sparkdemo-1.0-SNAPSHOT.jar \ master:2181 test kafka_streaming_topic 1- 创建生产者生产数据
/usr/local/src/kafka_2.11-1.1.1/bin/kafka-console-producer.sh --broker-list master:9092 --topic kafka_streaming_topic

- 去掉
/usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-submit \
--class com.sparkdemo.streaming.KafkaReceiverWorldCount \
--master local[2] \
--name KafkaReceiverWorldCount \
--jars /root/.ivy2/jars/org.apache.spark_spark-streaming-kafka_2.10-1.6.0.jar,\
/root/.ivy2/jars/org.apache.kafka_kafka_2.10-0.8.2.1.jar,\
/root/.ivy2/jars/org.apache.kafka_kafka-clients-0.8.2.1.jar,\
/root/.ivy2/jars/com.101tec_zkclient-0.3.jar,\
/root/.ivy2/jars/com.yammer.metrics_metrics-core-2.2.0.jar \
sparkdemo-1.0-SNAPSHOT.jar \
master:2181 test kafka_streaming_topic 15.2demo SparkStreaming-kafka(Direct Approach)
- 编写KafkaReceiverWorldCount.scala
package com.sparkdemo.streaming
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object KafkaDirectWorldCount {
def main(args: Array[String]): Unit = {
if (args.length != 2) {
System.err.println("Usage: KafkaDirectWorldCount <brokers> <topics>")
System.exit(1)
}
val Array(brokers, topics) = args
val conf = new SparkConf()
//.setAppName("KafkaReceiverWorldCount").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(10))
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, String]("metadata.broker.list" -> brokers)
//Streaming对接kafka
val messages = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,topicsSet)
messages.map(_._2).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print()
ssc.start()
ssc.awaitTermination()
}
}- 集群测试
- 打包上传

- 提交spark作业(需有网络)
/usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-submit \ --class com.sparkdemo.streaming.KafkaDirectWorldCount \ --master local[2] \ --name KafkaReceiverWorldCount \ --packages org.apache.spark:spark-streaming-kafka_2.10:1.6.0 \ sparkdemo-1.0-SNAPSHOT.jar \ master:9092 kafka_streaming_topic- 创建生产者生产数据
/usr/local/src/kafka_2.11-1.1.1/bin/kafka-console-producer.sh --broker-list master:9092 --topic kafka_streaming_topic

- 打包上传
6 Log + Flume + Kafka + SparkStreaming
6.1 Log + Flume对接
- 6.1.1编写LoggerGenerator.java类
package com.sparkdemo.log;
import org.apache.log4j.Logger;
public class LoggerGenerator {
private static Logger logger = Logger.getLogger(LoggerGenerator.class.getName());
public static void main(String[] args) throws InterruptedException {
int index = 0;
while (true) {
Thread.sleep(1000);
logger.info("Value: " + index++);
}
}
}- 6.1.2编写log4j.properties日志文件
log4j.rootLogger=INFO,stdout,debug,error,flume
#输出到控制台
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %p [%t] %C.%M(%L) | %m%n
#输出到flume
log4j.appender.flume = org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.Hostname = master
log4j.appender.flume.Port = 41414
log4j.appender.flume.UnsafeMode = true- 6.1.3集群上flume中编写log_flume_streaming.conf日志文件
#log-->flume
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# define source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41414
# define sink
a1.sinks.k1.type = logger
# define channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 1000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1- 6.1.4启动Flume
/usr/local/src/apache-flume-1.6.0-bin/bin/flume-ng agent \
--name a1 \
--conf /usr/local/src/apache-flume-1.6.0-bin/conf \
--conf-file /usr/local/src/apache-flume-1.6.0-bin/conf/log_flume_streaming.conf \
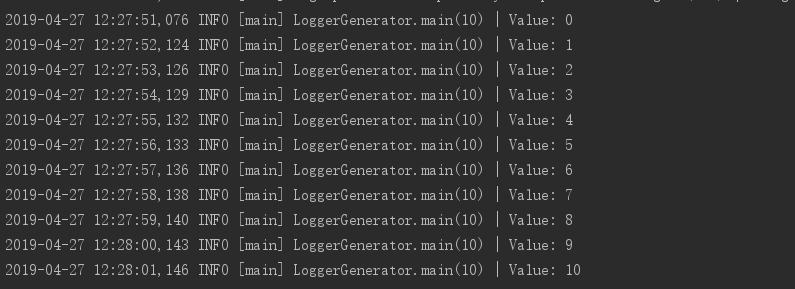
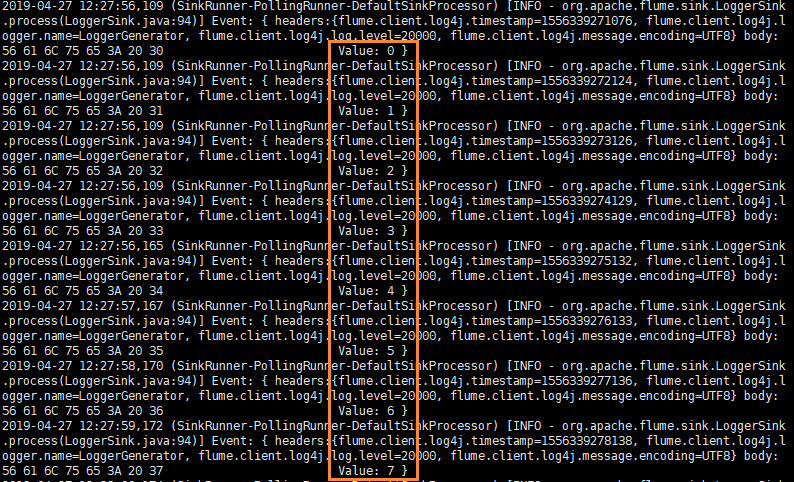
-Dflume.root.logger=INFO,console- 6.1.5启动java程序(验证对接是否成功)
6.2 Log + Flume对接基础上 + Kafka
- 6.2.1新建flume配置文件log_flume_streaming.conf
#log-->flume-->kafka
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# define source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 41414
# define sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = streamingtopic
a1.sinks.k1.brokerList = master:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
# define channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 1000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1- 6.2.2启动Flume
/usr/local/src/apache-flume-1.6.0-bin/bin/flume-ng agent \
--name a1 \
--conf /usr/local/src/apache-flume-1.6.0-bin/conf \
--conf-file /usr/local/src/apache-flume-1.6.0-bin/conf/log_flume_streaming2.conf \
-Dflume.root.logger=INFO,console- 6.2.3创建启动kafka消费端(上面相当于日志写到flume里,然后通过sink写到kafka的生产者里)
- 创建topic
/usr/local/src/kafka_2.11-1.1.1/bin/kafka-topics.sh --create --zookeeper master:2181 --replication-factor 1 --partitions 1 --topic streamingtopic
- 查看topic
/usr/local/src/kafka_2.11-1.1.1/bin/kafka-topics.sh --list --zookeeper master:2181
- 启动消费端
/usr/local/src/kafka_2.11-1.1.1/bin/kafka-console-consumer.sh --zookeeper master:2181 --topic streamingtopic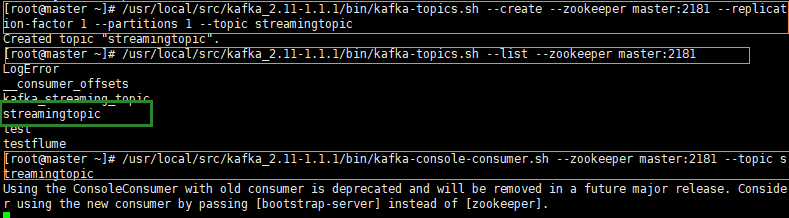
- 6.2.4启动java类(从中可以发现20个为一个批次输出,如果关闭程序,会将剩下结果输出-->因为flume中设置了batchSize=20)
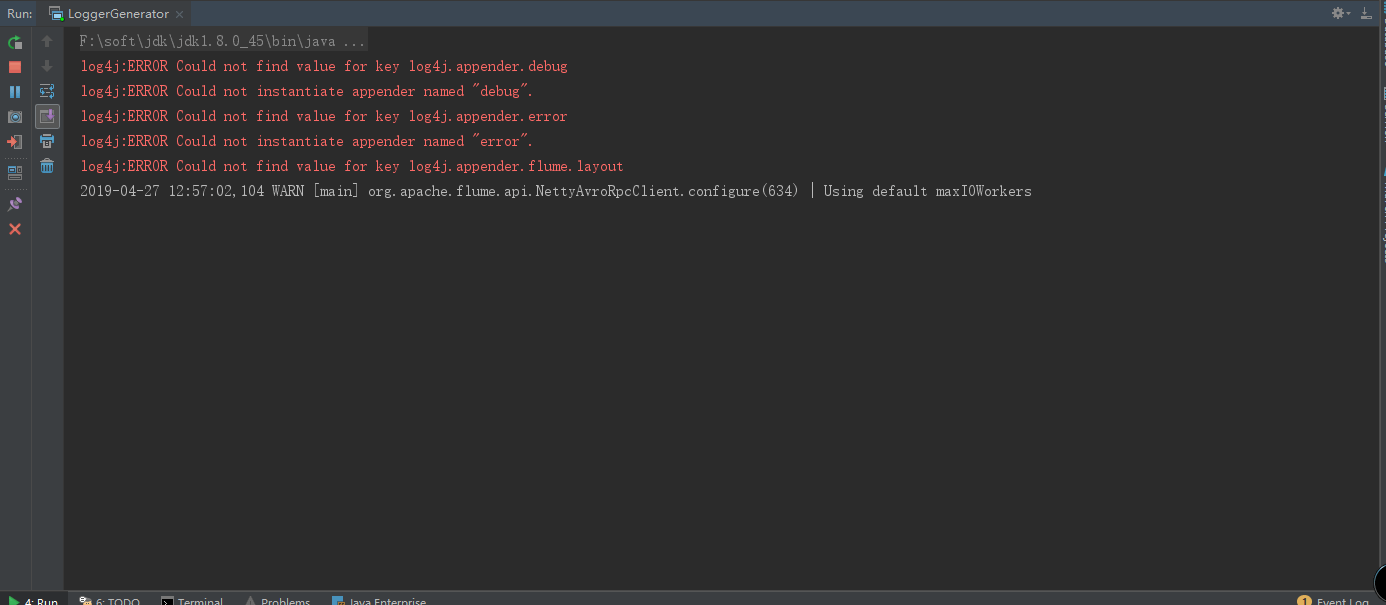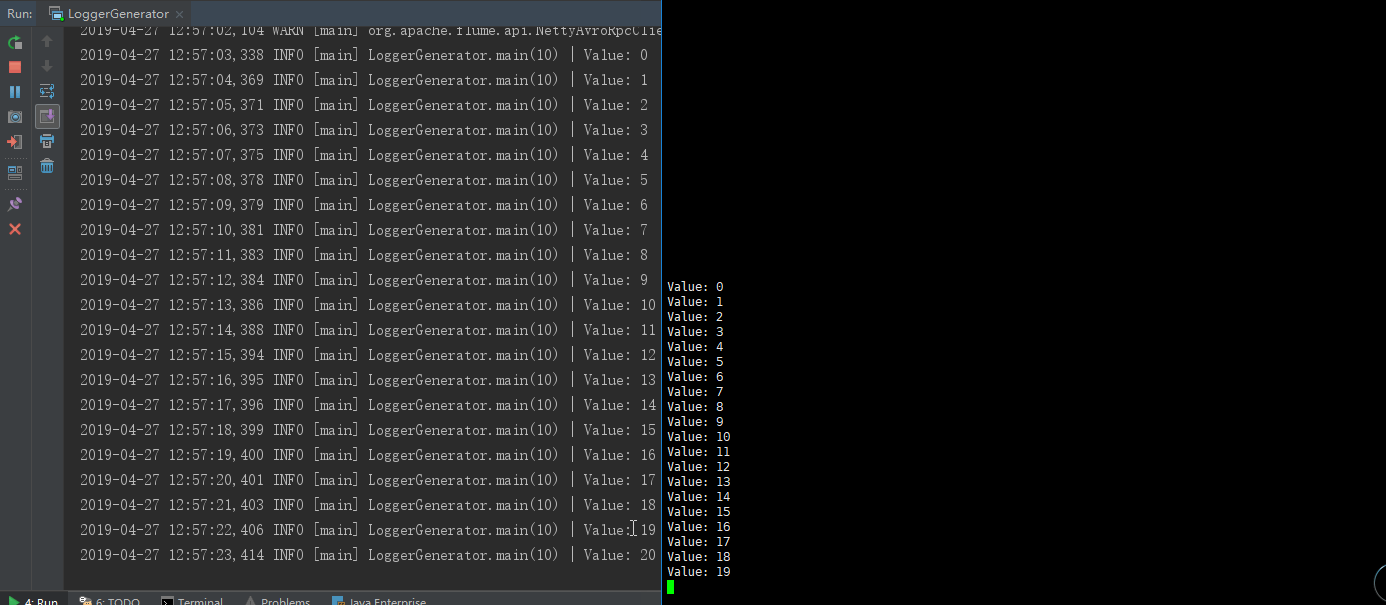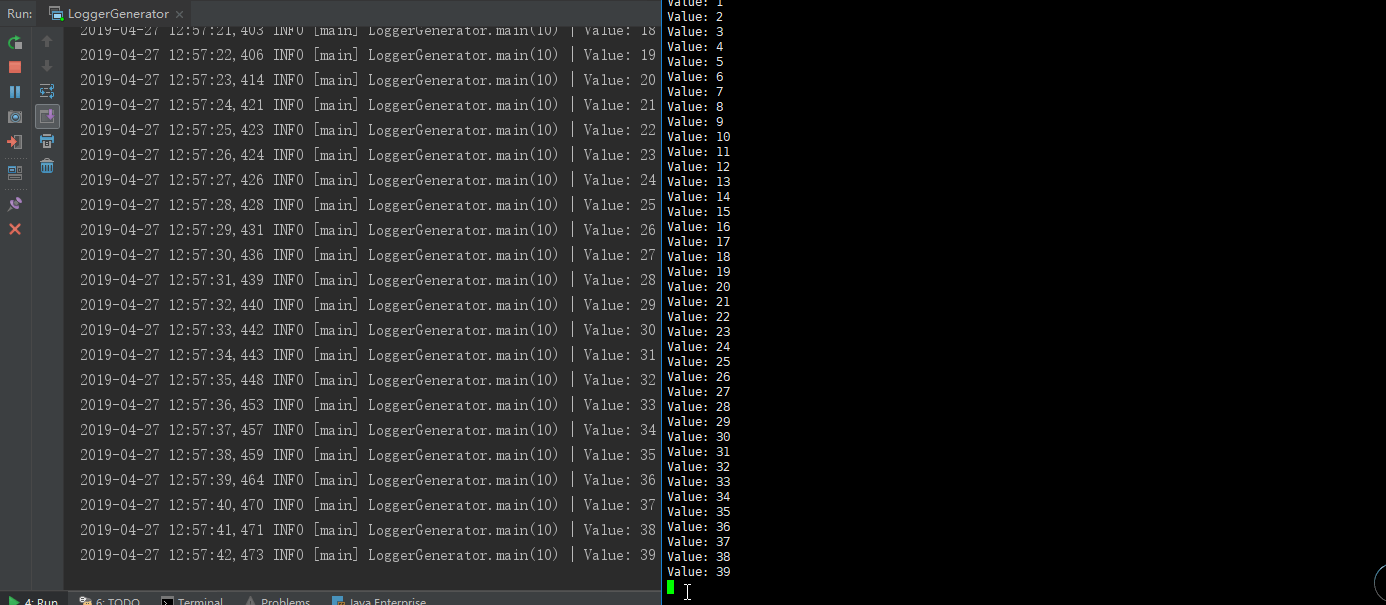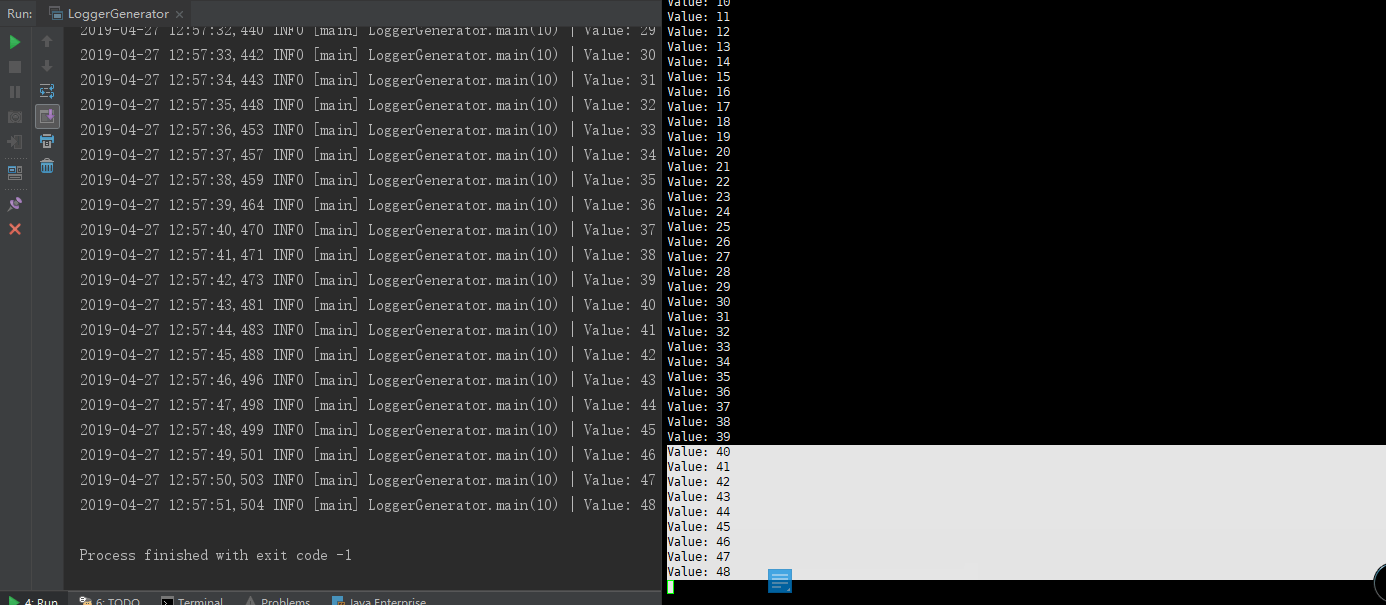
6.3 Log + Flume + Kafka对接基础上 + SparkStreaming
- 6.3.1编写KafkaStreamingApp.scala(Receiver模式)
package com.sparkdemo.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object KafkaStreamingApp {
def main(args: Array[String]): Unit = {
if (args.length != 4) {
System.err.println("Usage: KafkaStreamingApp <zkQuorum> <group> <topics> <numThreads>")
System.exit(1)
}
val Array(zkQuorum, group, topics, numThreads) = args
val conf = new SparkConf().setAppName("KafkaStreamingApp").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(10))
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
//Streaming对接kafka
val messages = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap)
messages.map(_._2).filter(_.contains("Value")).print()
ssc.start()
ssc.awaitTermination()
}
}- 6.3.2启动flume
/usr/local/src/apache-flume-1.6.0-bin/bin/flume-ng agent \
--name a1 \
--conf /usr/local/src/apache-flume-1.6.0-bin/conf \
--conf-file /usr/local/src/apache-flume-1.6.0-bin/conf/log_flume_streaming2.conf \
-Dflume.root.logger=INFO,console-
6.3.3启动LoggerGenerator类和KafkaStreamingApp类(观察测试结果)
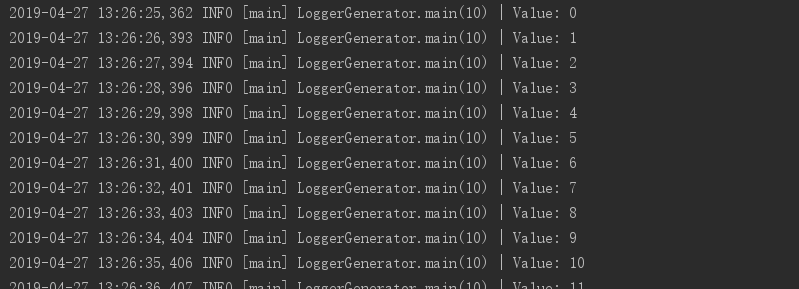

- 6.3.4集群测试,打包上传服务器,确认flume是否启动。

java -jar sparkdemo-1.0-SNAPSHOT-jar-with-dependencies.jar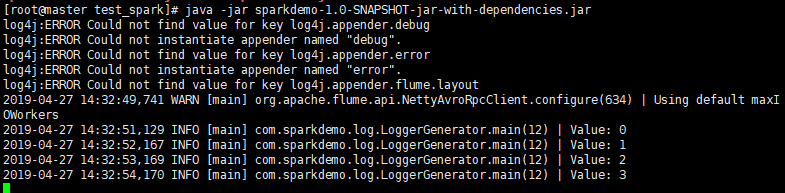
/usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-submit \
--master local[2] \
--name KafkaStreamingApp \
--packages org.apache.spark:spark-streaming-kafka_2.10:1.6.0 \
--class com.sparkdemo.streaming.KafkaStreamingApp \
sparkdemo-1.0-SNAPSHOT-jar-with-dependencies.jar \
master:2181 test streamingtopic 1
