25 SparkSQL案例
0 简介
Spark SQL 的前身是 shark,Shark 是基于 Spark 计算框架之上且兼容 Hive 语法的 SQL 执行引擎,
由于底层的计算采用了 Spark,性能比 MapReduce 的 Hive 普遍快 2 倍以上,当数
据全部 load 在内存的话,将快 10 倍以上,因此 Shark 可以作为交互式查询应用服务来使用。
除了基于 Spark 的特性外,Shark 是完全兼容 Hive 的语法,表结构以及 UDF 函数等,
已有的 HiveSql 可以直接进行迁移至 Shark 上。Shark 底层依赖于 Hive 的解析器,查询优化
器,但正是由于 Shark 的整体设计架构对 Hive 的依赖性太强,难以支持其长远发展,比如
不能和 Spark 的其他组件进行很好的集成,无法满足 Spark 的一栈式解决大数据处理的需求
Hive 是 Shark 的前身,Shark 是 SparkSQL 的前身,相对于 Shark,SparkSQL 有什么优势呢?
- SparkSQL 产生的根本原因,是因为它完全脱离了 Hive 的限制
- SparkSQL 支持查询原生的 RDD,这点就极为关键了。RDD 是 Spark 平台的核心概念,是 Spark 能够高效的处理大数据的各种场景的基础
- 能够在 Scala 中写 SQL 语句。支持简单的 SQL 语法检查,能够在 Scala 中写 Hive 语句访问 Hive 数据,并将结果取回作为 RDD 使用
- Spark 和 Hive 有两种组合
- Spark on Hive
- Hive 只是作为了存储的角色
- SparkSQL 作为计算的角色
- Hive on Spark
- Hive 承担了一部分计算(解析 SQL,优化 SQL...)的和存储
- Spark 作为了执行引擎的角色
1 Dataframe
Spark SQL 是 Spark 的核心组件之一,于 2014 年 4 月随 Spark 1.0 版一同面世,在 Spark
1.3 当中,Spark SQL 终于从 alpha(内测版本)阶段毕业。Spark 1.3 更加完整的表达了 Spark
SQL 的愿景:让开发者用更精简的代码处理尽量少的数据,同时让 Spark SQL 自动优化执行
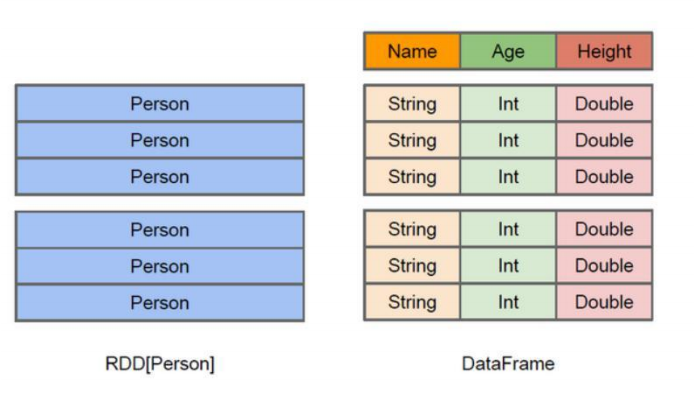
过程,以达到降低开发成本,提升数据分析执行效率的目的。与 RDD 类似,DataFrame 也
是一个分布式数据容器。然而 DataFrame 更像传统数据库的二维表格,除了数据以外,还
掌握数据的结构信息,即 schema。同时,与 Hive 类似,DataFrame 也支持嵌套数据类型
(struct、array 和 map)。从 API 易用性的角度上看,DataFrame API 提供的是一套高层的
关系操作,比函数式的 RDD API 要更加友好,门槛更低
1.1 RDD VS DataFrame
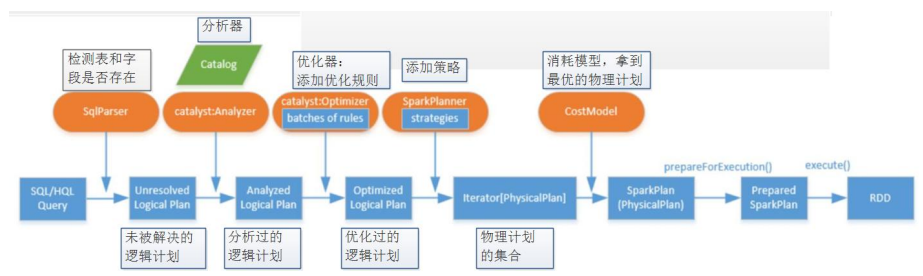
1.2 DataFrame 底层架构
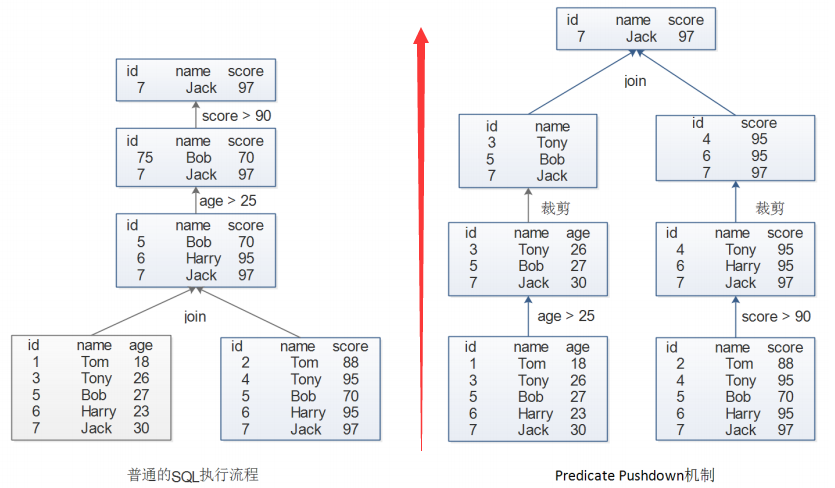
1.3 Predicate Pushdown 机制
- 执行如下 SQL 语句:
SELECT table1.name,table2.score
FROM table1 JOIN table2 ON (table1.id=table2.id)
WHERE table1.age>25 AND table2.score>90- 我们比较一下普通 SQL 执行流程和 Spark SQL 的执行流程
1.4 案例1 读取json数据
- people.txt
{"name":"Michael"},
{"name":"Andy", "age":30},
{"name":"Justin", "age":19}- SparkSQLTest
import org.apache.spark.sql.{DataFrame, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
object SparkSQLTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("SparkSQL")
conf.setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
//两种方式读取
//val df: DataFrame = sqlContext.read.format("json").load("./data/people.txt")
val df: DataFrame = sqlContext.read.json("./data/people.txt")
//查看 DataFrame 中的数据, df.show(int n)可以指定显示多少条数据,默认20条
df.show()
/** df.show()结果
* +----+-------+
* | age| name|
* +----+-------+
* |null|Michael|
* | 30| Andy|
* | 19| Justin|
* +----+-------+
*/
//打印 DataFrame 的结构
df.printSchema()
/** df.printSchema()结果
* root
* |-- age: long (nullable = true)
* |-- name: string (nullable = true)
*/
//将 DF 注册成一张临时表,这张表是逻辑上的,数据并不会落地
//people 是临时表的表名,后面的 SQL 直接 FROM 这个表名
df.registerTempTable("people")
//SELECT name from table
//df.select("name").show()
/**
* +-------+
* | name|
* +-------+
* |Michael|
* | Andy|
* | Justin|
* +-------+
*/
//SELECT name,age+10 from table
//df.select(df("name"), df("age").plus(10)).show()
/**
* +-------+----------+
* | name|(age + 10)|
* +-------+----------+
* |Michael| null|
* | Andy| 40|
* | Justin| 29|
* +-------+----------+
*/
//SELECT * FROM table WHERE age > 10
//df.filter(df("age")>10).show()
/**
* +---+------+
* |age| name|
* +---+------+
* | 30| Andy|
* | 19|Justin|
* +---+------+
*/
//SELECT count(*) FROM table GROUP BY age
//df.groupBy("age").count.show()
/**
* +----+-----+
* | age|count|
* +----+-----+
* |null| 1|
* | 19| 1|
* | 30| 1|
* +----+-----+
*/
//sqlContext.sql("select * from people where age > 20").show()
/**
* +---+----+
* |age|name|
* +---+----+
* | 30|Andy|
* +---+----+
*/
}
}1.5 案例2 读取嵌套json数据
- nestingPeople.txt
{"name":"zhangsan","score":100,"infos":{"age":30,"gender":"man"}},
{"name":"lisi","score":66,"infos":{"age":28,"gender":"feman"}},
{"name":"wangwu","score":77,"infos":{"age":15,"gender":"feman"}}- readNestJsonFile
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{DataFrame, SQLContext}
object readNestJsonFile {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SparkSQL").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
//读取嵌套的json文件
val frame: DataFrame = sqlContext.read.format("json").load("./data/nestingPeople.txt")
frame.printSchema()
frame.show(100)
frame.registerTempTable("infosView")
sqlContext.sql("select name,infos.age,score,infos.gender from infosView").show(100)
/**
* root
* |-- infos: struct (nullable = true)
* | |-- age: long (nullable = true)
* | |-- gender: string (nullable = true)
* |-- name: string (nullable = true)
* |-- score: long (nullable = true)
*/
/**
* +----------+--------+-----+
* | infos| name|score|
* +----------+--------+-----+
* | [30,man]|zhangsan| 100|
* |[28,feman]| lisi| 66|
* |[15,feman]| wangwu| 77|
* +----------+--------+-----+
*/
/**
* +--------+---+-----+------+
* | name|age|score|gender|
* +--------+---+-----+------+
* |zhangsan| 30| 100| man|
* | lisi| 28| 66| feman|
* | wangwu| 15| 77| feman|
* +--------+---+-----+------+
*/
}
}1.6 案例3 读取嵌套jsonArray数据
- arrayPeople.txt
{"name":"zhangsan","age":18,"scores":[{"yuwen":98,"shuxue":90,"yingyu":100,"xueqi":1},{"yuwen":77,"shuxue":33,"yingyu":55,"xueqi":2}]},
{"name":"lisi","age":19,"scores":[{"yuwen":58,"shuxue":50,"yingyu":78,"xueqi":1},{"yuwen":66,"shuxue":88,"yingyu":66,"xueqi":2}]},
{"name":"wangwu","age":17,"scores":[{"yuwen":18,"shuxue":90,"yingyu":45,"xueqi":1},{"yuwen":88,"shuxue":77,"yingyu":44,"xueqi":2}]},
{"name":"zhaoliu","age":20,"scores":[{"yuwen":68,"shuxue":23,"yingyu":63,"xueqi":1},{"yuwen":44,"shuxue":55,"yingyu":77,"xueqi":2}]},
{"name":"tianqi","age":22,"scores":[{"yuwen":88,"shuxue":91,"yingyu":41,"xueqi":1},{"yuwen":55,"shuxue":66,"yingyu":88,"xueqi":2}]}- readJsonArray
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{DataFrame, SQLContext}
/**
* 读取嵌套的jsonArray 数组,格式:
* {"name":"zhangsan","age":18,"scores":[{"yuwen":98,"shuxue":90,"yingyu":100},{"dili":98,"shengwu":78,"huaxue":100}]}
*
* expl将json格式ode函数作用是的数组展开,数组中的每个json对象都是一条数据
*/
object readJsonArray {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("readJsonArray")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val frame: DataFrame = sqlContext.read.json("./data/arrayPeople.txt")
//不折叠显示
frame.show(false)
/**
* +---+--------+-----------------------------+
* |age|name |scores |
* +---+--------+-----------------------------+
* |18 |zhangsan|[[90,1,100,98], [33,2,55,77]]|
* |19 |lisi |[[50,1,78,58], [88,2,66,66]] |
* |17 |wangwu |[[90,1,45,18], [77,2,44,88]] |
* |20 |zhaoliu |[[23,1,63,68], [55,2,77,44]] |
* |22 |tianqi |[[91,1,41,88], [66,2,88,55]] |
* +---+--------+-----------------------------+
*/
frame.printSchema() \
/**
* root
* |-- age: long (nullable = true)
* |-- name: string (nullable = true)
* |-- scores: array (nullable = true)
* | |-- element: struct (containsNull = true)
* | | |-- shuxue: long (nullable = true)
* | | |-- xueqi: long (nullable = true)
* | | |-- yingyu: long (nullable = true)
* | | |-- yuwen: long (nullable = true)
*/
//导入使用函数
import org.apache.spark.sql.functions._
//导入的是自己定义的SQLContext的隐式转换
import sqlContext.implicits._
val transDF: DataFrame = frame.select($"name", $"age", explode($"scores")).toDF("name", "age", "allScores")
transDF.show(100, false)
/**
* +--------+---+-------------+
* |name |age|allScores |
* +--------+---+-------------+
* |zhangsan|18 |[90,1,100,98]|
* |zhangsan|18 |[33,2,55,77] |
* |lisi |19 |[50,1,78,58] |
* |lisi |19 |[88,2,66,66] |
* |wangwu |17 |[90,1,45,18] |
* |wangwu |17 |[77,2,44,88] |
* |zhaoliu |20 |[23,1,63,68] |
* |zhaoliu |20 |[55,2,77,44] |
* |tianqi |22 |[91,1,41,88] |
* |tianqi |22 |[66,2,88,55] |
* +--------+---+-------------+
*/
transDF.printSchema()
/**
* root
* |-- name: string (nullable = true)
* |-- age: long (nullable = true)
* |-- allScores: struct (nullable = true)
* | |-- shuxue: long (nullable = true)
* | |-- xueqi: long (nullable = true)
* | |-- yingyu: long (nullable = true)
* | |-- yuwen: long (nullable = true)
*/
val result: DataFrame = transDF.select($"name", $"age",
$"allScores.yuwen" as "yuwen",
$"allScores.shuxue" as "shuxue",
$"allScores.yingyu" as "yingyu",
$"allScores.xueqi" as "xueqi"
)
result.show(100)
/**
* +--------+---+-----+------+------+-----+
* | name|age|yuwen|shuxue|yingyu|xueqi|
* +--------+---+-----+------+------+-----+
* |zhangsan| 18| 98| 90| 100| 1|
* |zhangsan| 18| 77| 33| 55| 2|
* | lisi| 19| 58| 50| 78| 1|
* | lisi| 19| 66| 88| 66| 2|
* | wangwu| 17| 18| 90| 45| 1|
* | wangwu| 17| 88| 77| 44| 2|
* | zhaoliu| 20| 68| 23| 63| 1|
* | zhaoliu| 20| 44| 55| 77| 2|
* | tianqi| 22| 88| 91| 41| 1|
* | tianqi| 22| 55| 66| 88| 2|
* +--------+---+-----+------+------+-----+
*/
}
}1.7 案例4 DataFrame和Rdd互转
package com.test.scala.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
object SparkSQLTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SparkSQL").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val df: DataFrame = sqlContext.read.format("json").load("./data/people.txt")
// val df: DataFrame = sqlContext.read.json("./data/people.txt")
//查看 DataFrame 中的数据, df.show(int n)可以指定显示多少条数据
df.show()
/**
* +----+-------+
* | age| name|
* +----+-------+
* |null|Michael|
* | 30| Andy|
* | 19| Justin|
* +----+-------+
*/
val rdd: RDD[Row] = df.rdd
rdd.foreach(row=>{
val name: String = row.getAs[String]("name")
val age: Long = row.getAs[Long]("age")
println(s"name=$name,age=$age")
})
/**
* name=Michael,age=0
* name=Andy,age=30
* name=Justin,age=19
*/
}
}1.8 案例5 读取mysql数据
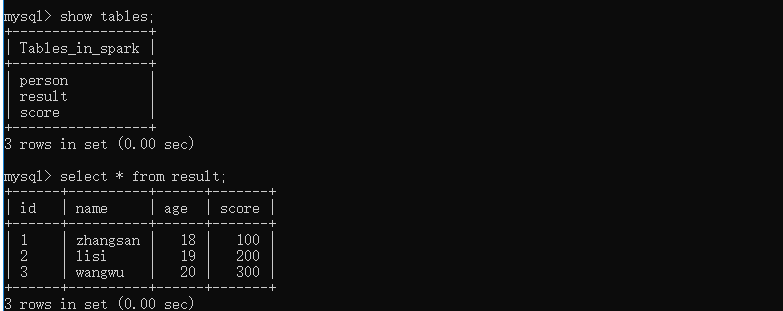
create database spark;
use spark;
create table person(id varchar(12),name varchar(12),age int(10));
create table score(id varchar(12),name varchar(12),score int(10));
insert into person values('1','zhangsan',18),('2','lisi',19),('3','wangwu',20);
insert into score values('1','zhangsan',100),('2','lisi',200),('3','wangwu',300);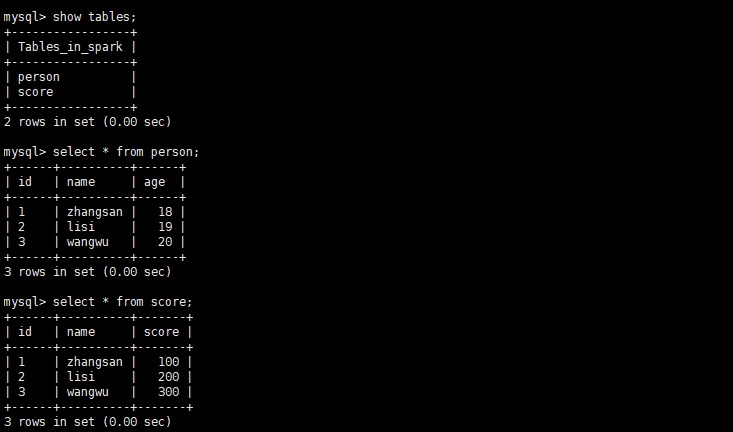
- CreateDataFrameFromMySQL
import java.util.Properties
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql._
/**
* 将MySQL中的表加载成DataFrame
*/
object CreateDataFrameFromMySQL {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("readJsonArray")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
/**
* 读取mysql表第一种方式
*/
val properties = new Properties()
properties.setProperty("user", "root")
properties.setProperty("password", "root")
val person: DataFrame = sqlContext.read.jdbc("jdbc:mysql://localhost:3306/spark", "person", properties)
person.show()
/**
* +---+--------+---+
* | id| name|age|
* +---+--------+---+
* | 1|zhangsan| 18|
* | 2| lisi| 19|
* | 3| wangwu| 20|
* +---+--------+---+
*/
/**
* 读取mysql表第二种方式
*/
val map = Map[String, String](
"url" -> "jdbc:mysql://localhost:3306/spark",
"driver" -> "com.mysql.jdbc.Driver",
"user" -> "root",
"password" -> "root",
"dbtable" -> "score" //表名
)
val score: DataFrame = sqlContext.read.format("jdbc").options(map).load()
score.show()
/**
* +---+--------+-----+
* | id| name|score|
* +---+--------+-----+
* | 1|zhangsan| 100|
* | 2| lisi| 200|
* | 3| wangwu| 300|
* +---+--------+-----+
*/
/**
* 读取mysql数据第三种方式
*/
val reader: DataFrameReader = sqlContext.read.format("jdbc")
.option("url", "jdbc:mysql://localhost:3306/spark")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "root")
.option("dbtable", "score")
val score2: DataFrame = reader.load()
score2.show()
/**
* +---+--------+-----+
* | id| name|score|
* +---+--------+-----+
* | 1|zhangsan| 100|
* | 2| lisi| 200|
* | 3| wangwu| 300|
* +---+--------+-----+
*/
//将以上两张表注册临时表,关联查询
person.registerTempTable("person")
score.registerTempTable("score")
sqlContext.sql("select person.id,person.name,person.age,score.score from person ,score where person.id = score.id").show()
/**
* +---+--------+---+-----+
* | id| name|age|score|
* +---+--------+---+-----+
* | 1|zhangsan| 18| 100|
* | 2| lisi| 19| 200|
* | 3| wangwu| 20| 300|
* +---+--------+---+-----+
*/
//将结果保存在Mysql表中,String 格式的数据在MySQL中默认保存成text格式,如果不想使用这个格式 ,可以自己建表创建各个列的格式再保存。
val result: DataFrame = sqlContext.sql("select person.id,person.name,person.age,score.score from person ,score where person.id = score.id")
//将结果保存在mysql表中
result.write.mode(SaveMode.Overwrite).jdbc("jdbc:mysql://localhost:3306/spark", "result", properties)
//读取mysql中数据的第四种方式
sqlContext.read.jdbc("jdbc:mysql://localhost:3306/spark", "(select person.id,person.name,person.age,score.score from person ,score where person.id = score.id) T", properties).show()
/**
* +---+--------+---+-----+
* | id| name|age|score|
* +---+--------+---+-----+
* | 1|zhangsan| 18| 100|
* | 2| lisi| 19| 200|
* | 3| wangwu| 20| 300|
* +---+--------+---+-----+
*/
}
}- 上述代码保存到数据库中的结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号