24 SparkStreaming案例2
1需求
- 今天到现在为止课程的访问量
-
今天到现在为止从搜索引擎引流过来的课程的访问量
2访问日志需求
- 网站页面的访问量
- 网站的粘性
-
推荐
3 模拟日志服务开发
- 3.1开发generate_log.py文件
# coding=UTF-8
import random
import time
# 访问路径
url_paths = [
"class/112.html",
"class/128.html",
"class/145.html",
"class/146.html",
"class/131.html",
"class/130.html",
"class/145.tml",
"learn/821",
"course/list",
]
# ip地址
ip_slices = [156, 132, 124, 29, 10, 167, 143, 187, 30, 46, 55, 63, 72, 81, 98, 168]
# 来源网站
http_referers = [
"https://www.baidu.com/s?wd={query}",
"https://www.sogou.com/web?query={query}",
"https://cn.bing.com/search?q={query}",
"https://search.yahoo.com/search?p={query}",
"https://www.google.com/search?q={query}"
]
# 搜索内容
search_keyword = [
"Spark SQL实战",
"Hadoop基础",
"JAVA入门",
"大数据精通",
"SCALA深入"
]
# 状态码
status_codes = ["200", "400", "500"]
# 生成连接如:class/130.html
def sample_url():
# url_paths中随机获取1个元素,作为一个片断返回,然后再取第一个
return random.sample(url_paths, 1)[0]
# 生成IP如:168,167,10,72
def sample_ip():
slice = random.sample(ip_slices, 4)
return ",".join([str(item) for item in slice])
# 生成来源和搜索内容如:https://www.sogou.com/web?query=Hadoop基础
def sample_referer():
# 生成0-1之间的小数
if random.uniform(0, 1) > 0.2:
return "-"
refer_str = random.sample(http_referers, 1)
query_str = random.sample(search_keyword, 1)
return refer_str[0].format(query=query_str[0])
# 取状态码如:200
def sample_status_code():
return random.sample(status_codes, 1)[0]
# 拼接日志信息
def generate_log(count=10):
# 时间
time_str = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
f = open('/root/test_spark/logs/access.log', 'w+')
while count >= 1:
query_log = "{ip}\t{local_time}\tGET /{url} HTTP/1.1 \t{status}\t{referer}".format(ip=sample_ip(),
local_time=time_str,
url=sample_url(),
status=sample_status_code(),
referer=sample_referer())
print(query_log)
f.write(query_log + "\n")
count = count - 1
# 用于产生访问日志
if __name__ == '__main__':
generate_log(100)- 3.2 测试
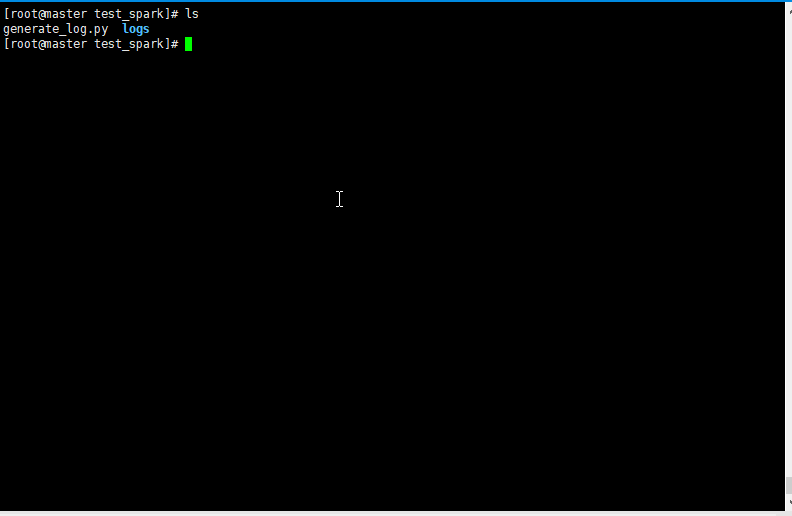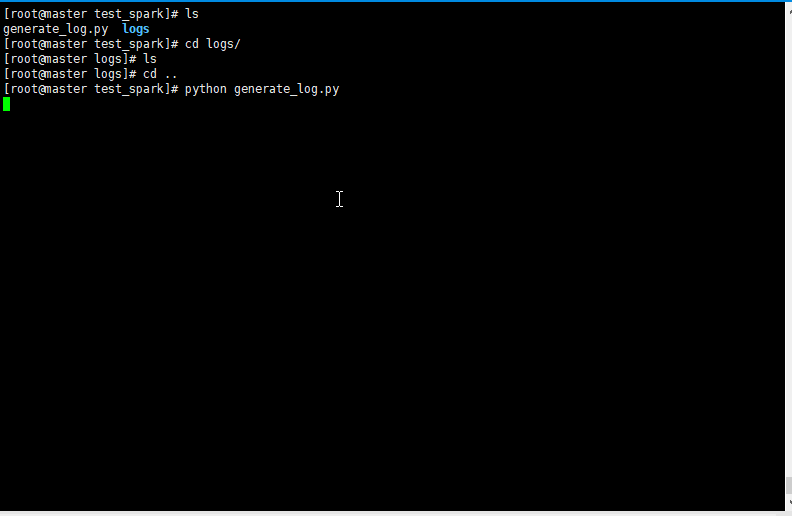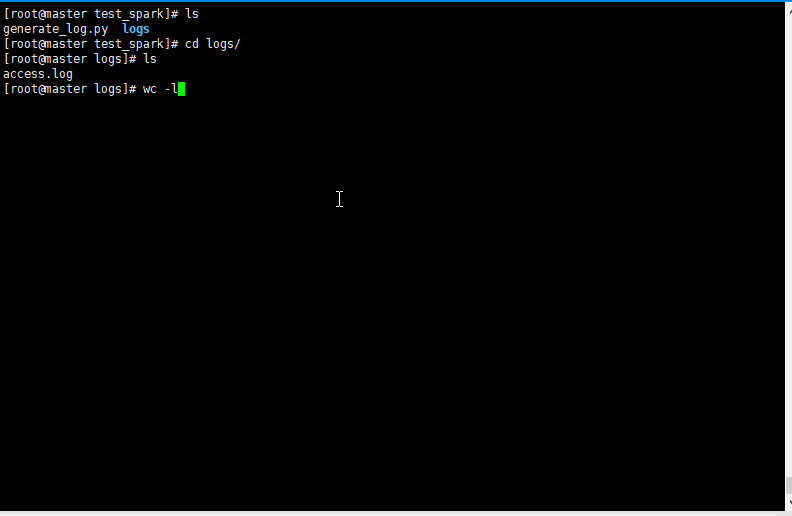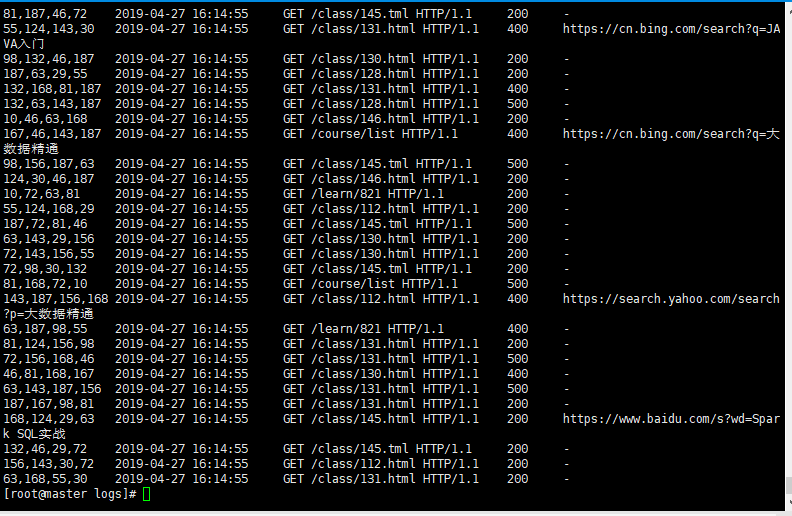
4 定时调度工具,每分钟生产一批数据

- 4.1创建脚本文件log_generator.sh并修改权限
python /root/test_spark/generate_log.py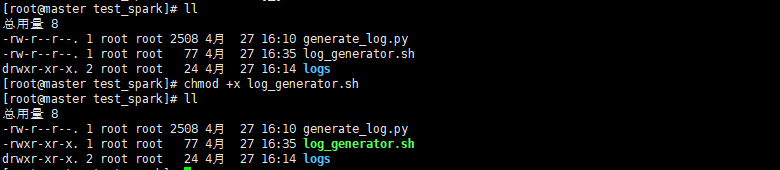
-
4.2使用
tail -200f access.log监控日志文件(一旦刷新就会看见信息) - 4.3检查crontab环境及配置定时任务
- 检查
crontab -l
- 安装
yum install -y vixie-cron
yum install crontabs
- 启动
/sbin/service crond start
- 加入开机自动启动
chkconfig --level 35 crond on
- 继续执行上面第一条命令:
crontab -l
这时会出现 “no crontab for root” 这是由于你还没有创建任何定时任务或者命令打错,
即没有使用crontab -e命令去创建任何任务。
- crontab命令主要有3个参数:
-e :编辑用户的crontab
-l :列出用户的crontab的内容
-r :删除用户的crontab的内容使用crontab -e进入定时器设置
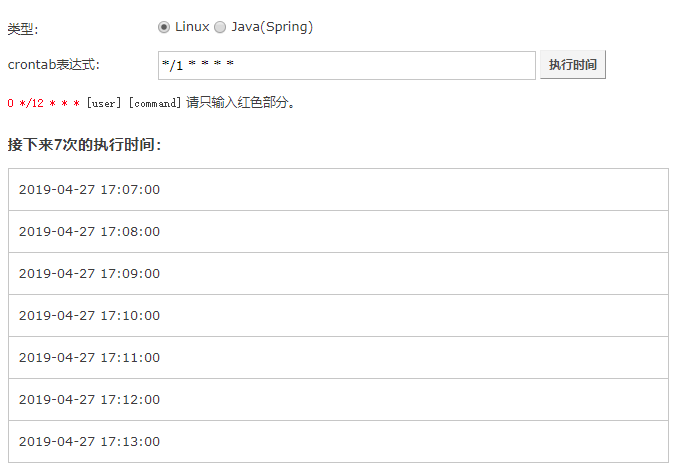
输入*/1 * * * * /root/test_spark/log_generator.sh

等一分钟观察日志文件
5 对接flume(控制台查看可以直接跳下一步)
- 5.1编写配置文件streaming_project.conf(监控文件控制台打印)
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /root/test_spark/logs/access.log
a1.sources.r1.shell = /bin/bash -c
# sink
a1.sinks.k1.type = logger
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 1000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1- 5.2启动flume

/usr/local/src/apache-flume-1.6.0-bin/bin/flume-ng agent \
--name a1 \
--conf /usr/local/src/apache-flume-1.6.0-bin/conf \
--conf-file /root/test_spark/streaming_project.conf \
-Dflume.root.logger=INFO,console等一分钟观察flume上是否有日志输出
6 对接flume及kafka
- 6.1编写配置文件streaming_project.conf(监控文件控制台打印)
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /root/test_spark/logs/access.log
a1.sources.r1.shell = /bin/bash -c
# sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = streamingtopic
a1.sinks.k1.brokerList = master:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 1000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1- 6.2启动flume
/usr/local/src/apache-flume-1.6.0-bin/bin/flume-ng agent \
--name a1 \
--conf /usr/local/src/apache-flume-1.6.0-bin/conf \
--conf-file /root/test_spark/streaming_project.conf \
-Dflume.root.logger=INFO,console-6.3 启动kafka消费
- 查看topic
/usr/local/src/kafka_2.11-1.1.1/bin/kafka-topics.sh --list --zookeeper master:2181
- 创建一个topic
/usr/local/src/kafka_2.11-1.1.1/bin/kafka-topics.sh --create --zookeeper master:2181 --replication-factor 1 --partitions 1 --topic streamingtopic
- 消费者
/usr/local/src/kafka_2.11-1.1.1/bin/kafka-console-consumer.sh --zookeeper master:2181 --topic streamingtopic等一分钟观察kafka消费者上是否有日志输出
7 streaming处理kafka过来的数据
- 7.1编写KafkaStreamingApp.scala
package com.sparkdemo.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object KafkaStreamingApp {
def main(args: Array[String]): Unit = {
if (args.length != 4) {
System.err.println("Usage: KafkaStreamingApp <zkQuorum> <group> <topics> <numThreads>")
System.exit(1)
}
val Array(zkQuorum, group, topics, numThreads) = args
val conf = new SparkConf().setAppName("KafkaStreamingApp").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(10))
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
//Streaming对接kafka
val messages = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap)
messages.map(_._2).filter(_.contains("GET")).print()
ssc.start()
ssc.awaitTermination()
}
}- 7.2设置启动参数
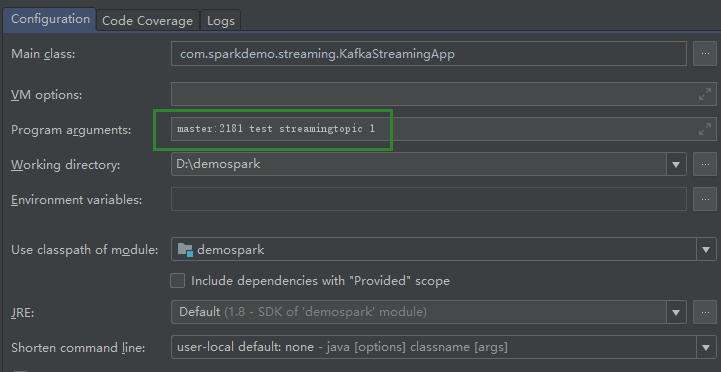

8 数据清洗
- 8.1 时间处理工具类DateUtils.scala
package com.sparkdemo.util
import java.text.SimpleDateFormat
import java.util.Date
import org.apache.commons.lang3.time.FastDateFormat
object DateUtils {
final val YYYYMMDDHHMMSS_FORMAT = "yyyy-MM-dd HH:mm:ss"
final val TARGE_FORMAT = FastDateFormat.getInstance("yyyyMMddHHmmss")
def getTime(dateStr: String): Long = {
new SimpleDateFormat(YYYYMMDDHHMMSS_FORMAT).parse(dateStr).getTime
}
def parseToMinute(time: String) = {
TARGE_FORMAT.format(new Date(getTime(time)))
}
def main(args: Array[String]): Unit = {
println(parseToMinute("2018-10-22 14:46:01"))
}
}- 8.2创建清洗后储存信息的Bean-->ClickLog.scala
package com.sparkdemo.domain
/**
* 清洗后的日志信息
* @param ip 日志访问的ip地址
* @param time 日志访问的时间
* @param courseId 日志访问的课程编号
* @param statusCode 日志访问的状态码
* @param referer 日志访问的referer
*/
case class ClickLog(ip:String,time:String,courseId:Int,statusCode:Int,referer:String)
- 8.3修改KafkaStreamingApp
package com.sparkdemo.streaming
import com.sparkdemo.domain.ClickLog
import com.sparkdemo.util.DateUtils
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object KafkaStreamingApp {
def main(args: Array[String]): Unit = {
if (args.length != 4) {
System.err.println("Usage: KafkaStreamingApp <zkQuorum> <group> <topics> <numThreads>")
System.exit(1)
}
val Array(zkQuorum, group, topics, numThreads) = args
val conf = new SparkConf().setAppName("KafkaStreamingApp").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(60))
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
//Streaming对接kafka
val messages = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap)
//修改部分开始
val logs = messages.map(_._2)
val cleanData = logs.map(line => {
//143,72,10,81 2019-04-27 17:47:01 GET /class/145.tml HTTP/1.1 400 https://www.sogou.com/web?query=SCALA深入
val infos = line.split("\t")
//url = /class/145.tml
val url = infos(2).split(" ")(1)
//课程编号
var courseId = 0
if (url.startsWith("/class")) {
val courseIdHTML = url.split("/")(2)
courseId = courseIdHTML.substring(0, courseIdHTML.lastIndexOf(".")).toInt
}
ClickLog(infos(0), DateUtils.parseToMinute(infos(1)), courseId, infos(3).toInt, infos(4))
}).filter(clickLog => clickLog.courseId != 0)
cleanData.print()
//修改部分结束
ssc.start()
ssc.awaitTermination()
}
}- 8.4测试,注意关注kafka和flume状态
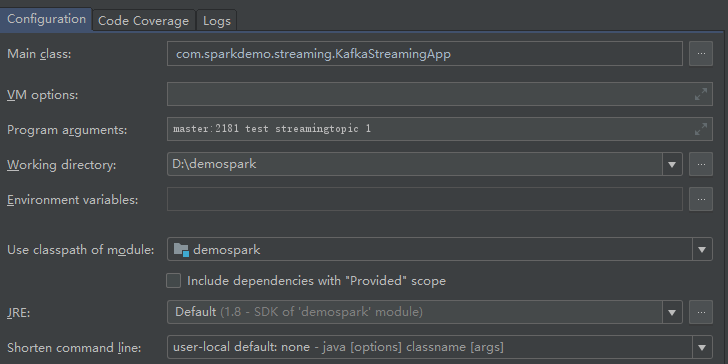
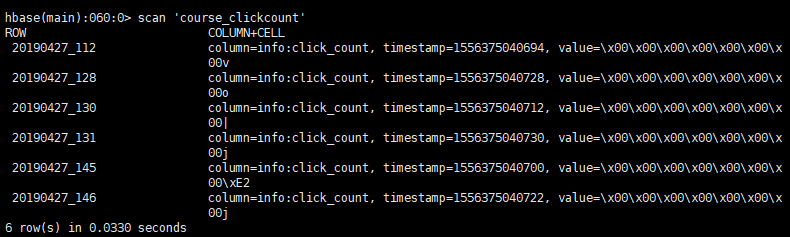
清洗后数据如下: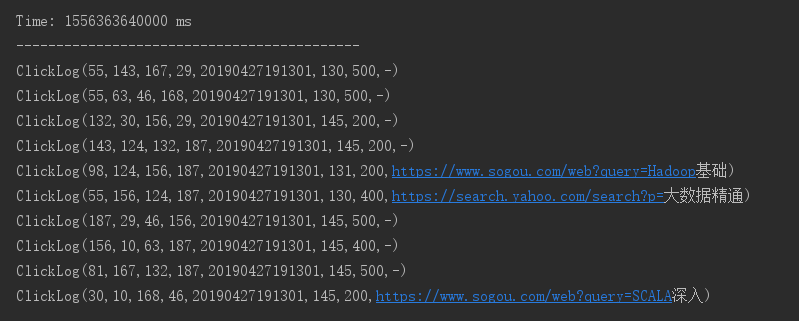
9分析及储存结果
- 9.1统计今天到现在课程的访问量
- 9.2Hbase表设计
create 'course_clickcount','info'(RowKey设计为天+课程id-->day_courseid)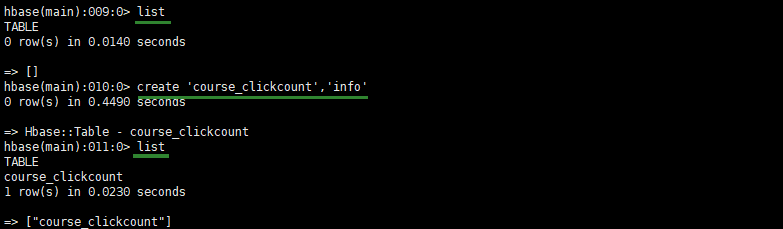
- 9.3做一个HBaseUtils.java工具类
package com.tzy.util;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
/**
* HBase操作工具类
*/
public class HBaseUtils {
HBaseAdmin admin = null;
Configuration conf = null;
/**
* 私有构造方法:加载一些必要的参数
*/
private HBaseUtils() {
conf = new Configuration();
conf.set("hbase.rootdir", "hdfs://master:9000/hbase");
conf.set("hbase.client.start.log.errors.counter", "1");
conf.set("hbase.client.retries.number","1");
conf.set("hbase.zookeeper.quorum", "master,slave1,slave2");
conf.set("hbase.zookeeper.property.clientPort","2181");
try {
admin = new HBaseAdmin(conf);
} catch (IOException e) {
e.printStackTrace();
}
}
private static HBaseUtils instance = null;
public static synchronized HBaseUtils getInstance() {
if (null == instance) {
instance = new HBaseUtils();
}
return instance;
}
/**
* 根据表名获取到HTable实例
*/
public HTable getTable(String tableName) {
HTable table = null;
try {
table = new HTable(conf, tableName);
} catch (IOException e) {
e.printStackTrace();
}
return table;
}
/**
* 根据表名和输入条件获取HBase的记录数
*/
public Map<String, Long> query(String tableName, String condition) throws Exception {
Map<String, Long> map = new HashMap<>();
HTable table = getTable(tableName);
String cf = "info";
String qualifier = "click_count";
Scan scan = new Scan();
scan.setCaching(100);
Filter filter = new PrefixFilter(Bytes.toBytes(condition));
scan.setFilter(filter);
ResultScanner rs = table.getScanner(scan);
for(Result result : rs) {
String row = Bytes.toString(result.getRow());
long clickCount = Bytes.toLong(result.getValue(cf.getBytes(), qualifier.getBytes()));
map.put(row, clickCount);
}
return map;
}
public static void main(String[] args) throws Exception {
Map<String, Long> map = HBaseUtils.getInstance().query("course_clickcount" , "20190427");
for(Map.Entry<String, Long> entry: map.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
}
}- 9.4课程点击数实体类CourseClickCount.scala
package com.sparkdemo.domain
/**
* 课程点击数实体类
* @param day_course 对应的就是Hbase中的rowkey,20171111_1
* @param click_count 对应的20171111_1的访问总数
*/
case class CourseClickCount(day_course:String,click_count:Long)- 9.5课程点击数数据访问层CourseClickCountDao.scala
package com.sparkdemo.dao
import com.sparkdemo.domain.CourseClickCount
import com.sparkdemo.util.HBaseUtils
import org.apache.hadoop.hbase.client.Get
import org.apache.hadoop.hbase.util.Bytes
import scala.collection.mutable.ListBuffer
/**
* 课程点击数数据访问层
*/
object CourseClickCountDao {
val tableName = "course_clickcount"
val cf = "info"
val qualifer = "click_count"
//保存数据到Hbase
def save(list: ListBuffer[CourseClickCount]): Unit = {
val table = HBaseUtils.getInstance().getTable(tableName)
for (ele <- list) {
table.incrementColumnValue(Bytes.toBytes(ele.day_course),
Bytes.toBytes(cf),
Bytes.toBytes(qualifer),
ele.click_count)
}
}
//根据rowkey查询值
def count(day_course: String) = {
val table = HBaseUtils.getInstance().getTable(tableName)
val get = new Get(Bytes.toBytes(day_course))
val value = table.get(get).getValue(cf.getBytes(), qualifer.getBytes())
if (value == null) {
0L
} else {
Bytes.toLong(value)
}
}
def main(args: Array[String]): Unit = {
val list = new ListBuffer[CourseClickCount]
list.append(CourseClickCount("20181111_8", 8))
list.append(CourseClickCount("20181111_9", 9))
list.append(CourseClickCount("20181111_1", 100))
save(list)
println(count("20181111_8")+":"+count("20181111_9")+":"+count("20181111_1"))
//8:9:100
save(list)
println(count("20181111_8")+":"+count("20181111_9")+":"+count("20181111_1"))
//16:18:200
}
}- 9.6修改KafkaStreamingApp.scala
package com.sparkdemo.streaming
import com.sparkdemo.dao.CourseClickCountDao
import com.sparkdemo.domain.{ClickLog, CourseClickCount}
import com.sparkdemo.util.DateUtils
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.ListBuffer
object KafkaStreamingApp {
def main(args: Array[String]): Unit = {
if (args.length != 4) {
System.err.println("Usage: KafkaStreamingApp <zkQuorum> <group> <topics> <numThreads>")
System.exit(1)
}
val Array(zkQuorum, group, topics, numThreads) = args
val conf = new SparkConf().setAppName("KafkaStreamingApp").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(60))
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
//Streaming对接kafka
val messages = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap)
val logs = messages.map(_._2)
val cleanData = logs.map(line => {
//143,72,10,81 2019-04-27 17:47:01 GET /class/145.tml HTTP/1.1 400 https://www.sogou.com/web?query=SCALA深入
val infos = line.split("\t")
//url = /class/145.tml
val url = infos(2).split(" ")(1)
//课程编号
var courseId = 0
if (url.startsWith("/class")) {
val courseIdHTML = url.split("/")(2)
courseId = courseIdHTML.substring(0, courseIdHTML.lastIndexOf(".")).toInt
}
ClickLog(infos(0), DateUtils.parseToMinute(infos(1)), courseId, infos(3).toInt, infos(4))
}).filter(clickLog => clickLog.courseId != 0)
// cleanData.print()
cleanData.map(x => {
//Hbase rowkey设计:20181111_88
(x.time.substring(0, 8) + "_" + x.courseId, 1)
}).reduceByKey(_ + _).foreachRDD(rdd => {
rdd.foreachPartition(partitionRecords => {
val list = new ListBuffer[CourseClickCount]
partitionRecords.foreach(pair => {
list.append(CourseClickCount(pair._1, pair._2))
})
CourseClickCountDao.save(list)
})
})
ssc.start()
ssc.awaitTermination()
}
}- 9.7测试
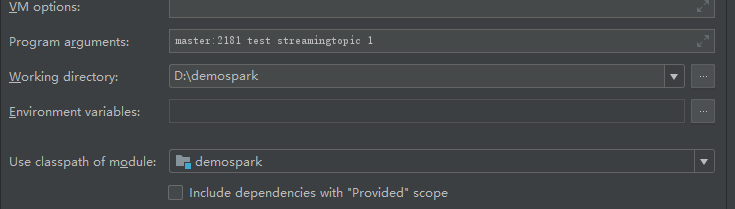
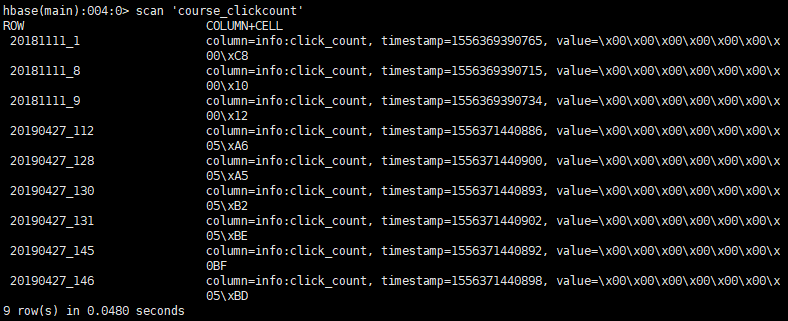
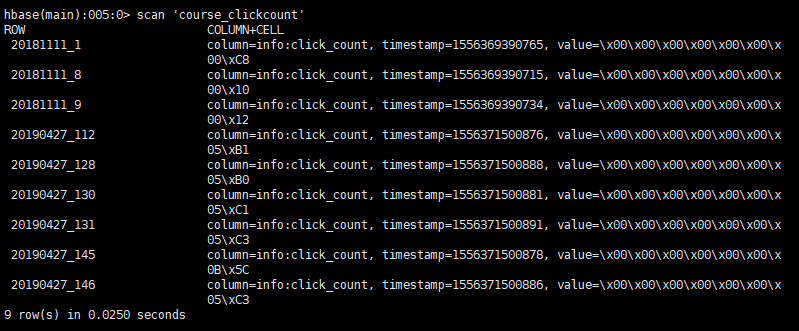
10分析及储存结果
- 10.1统计今天到现在为止从搜索引擎流过来的课程访问量
- 10.2Hbase表设计
create 'course_search_clickcount','info'(RowKey设计为天+搜索+课程id-->day_search_courseid) - 10.3擎过来的课程点击数实体类CourseSearchClickCount.scala
package com.sparkdemo.domain
/**
* 从搜索引擎过来的课程点击数实体类
* @param day_search_course 对应的就是Hbase中的rowkey,20181111_www.baidu.com_128
* @param click_count 对应的20171111_1的访问总数
*/
case class CourseSearchClickCount(day_search_course:String,click_count:Long)- 10.4从搜索引擎过来的课程点击数数据访问层CourseSearchClickCountDao.scala
package com.sparkdemo.dao
import com.sparkdemo.domain.{ CourseSearchClickCount}
import com.sparkdemo.util.HBaseUtils
import org.apache.hadoop.hbase.client.Get
import org.apache.hadoop.hbase.util.Bytes
import scala.collection.mutable.ListBuffer
/**
* 从搜索引擎过来的课程点击数数据访问层
*/
object CourseSearchClickCountDao{
val tableName = "course_search_clickcount"
val cf = "info"
val qualifer = "click_count"
//保存数据到Hbase
def save(list: ListBuffer[CourseSearchClickCount]): Unit = {
val table = HBaseUtils.getInstance().getTable(tableName)
for (ele <- list) {
table.incrementColumnValue(Bytes.toBytes(ele.day_search_course),
Bytes.toBytes(cf),
Bytes.toBytes(qualifer),
ele.click_count)
}
}
//根据rowkey查询值
def count(day_search_course: String) = {
val table = HBaseUtils.getInstance().getTable(tableName)
val get = new Get(Bytes.toBytes(day_search_course))
val value = table.get(get).getValue(cf.getBytes(), qualifer.getBytes())
if (value == null) {
0L
} else {
Bytes.toLong(value)
}
}
def main(args: Array[String]): Unit = {
val list = new ListBuffer[CourseSearchClickCount]
list.append(CourseSearchClickCount("20181111_www.baidu.com_8", 8))
list.append(CourseSearchClickCount("20181111_www.google.com_9", 9))
list.append(CourseSearchClickCount("20181111_www.sougou.com_1", 100))
save(list)
println(count("20181111_www.baidu.com_8")+":"+count("20181111_www.google.com_9")+":"+count("20181111_www.sougou.com_1"))
//8:9:100
save(list)
println(count("20181111_www.baidu.com_8")+":"+count("20181111_www.google.com_9")+":"+count("20181111_www.sougou.com_1"))
//16:18:200
}
}- 10.5修改KafkaStreamingApp.scala
package com.sparkdemo.streaming
import com.sparkdemo.dao.{CourseClickCountDao, CourseSearchClickCountDao}
import com.sparkdemo.domain.{ClickLog, CourseClickCount, CourseSearchClickCount}
import com.sparkdemo.util.DateUtils
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.ListBuffer
object KafkaStreamingApp {
def main(args: Array[String]): Unit = {
if (args.length != 4) {
System.err.println("Usage: KafkaStreamingApp <zkQuorum> <group> <topics> <numThreads>")
System.exit(1)
}
val Array(zkQuorum, group, topics, numThreads) = args
val conf = new SparkConf().setAppName("KafkaStreamingApp").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(60))
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
//Streaming对接kafka
val messages = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap)
val logs = messages.map(_._2)
val cleanData = logs.map(line => {
//143,72,10,81 2019-04-27 17:47:01 GET /class/145.tml HTTP/1.1 400 https://www.sogou.com/web?query=SCALA深入
val infos = line.split("\t")
//url = /class/145.tml
val url = infos(2).split(" ")(1)
//课程编号
var courseId = 0
if (url.startsWith("/class")) {
val courseIdHTML = url.split("/")(2)
courseId = courseIdHTML.substring(0, courseIdHTML.lastIndexOf(".")).toInt
}
ClickLog(infos(0), DateUtils.parseToMinute(infos(1)), courseId, infos(3).toInt, infos(4))
}).filter(clickLog => clickLog.courseId != 0)
// cleanData.print()
//统计今天到现在为止的课程访问量
cleanData.map(x => {
//Hbase rowkey设计:20181111_88
(x.time.substring(0, 8) + "_" + x.courseId, 1)
}).reduceByKey(_ + _).foreachRDD(rdd => {
rdd.foreachPartition(partitionRecords => {
val list = new ListBuffer[CourseClickCount]
partitionRecords.foreach(pair => {
list.append(CourseClickCount(pair._1, pair._2))
})
CourseClickCountDao.save(list)
})
})
//统计从搜索过引擎过来的今天到现在为止的课程访问量
cleanData.map(x => {
// https://www.baidu.com/s?wd=Spark深入
val referer = x.referer.replaceAll("//", "/")
val splits = referer.split("/")
var host = ""
if (splits.length > 2) {
host = splits(1)
}
(host, x.courseId, x.time)
}).filter(_._1 != null).map(x => {
(x._3.substring(0, 8) + "_" + x._1 + "_" + x._2, 1)
}).reduceByKey(_ + _).foreachRDD(rdd => {
rdd.foreachPartition(partitionRecords => {
val list = new ListBuffer[CourseSearchClickCount]
partitionRecords.foreach(pair => {
list.append(CourseSearchClickCount(pair._1, pair._2))
})
CourseSearchClickCountDao.save(list)
})
})
ssc.start()
ssc.awaitTermination()
}
}
- 10.6测试
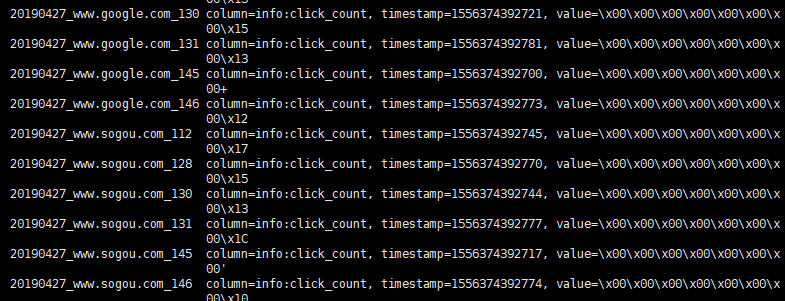
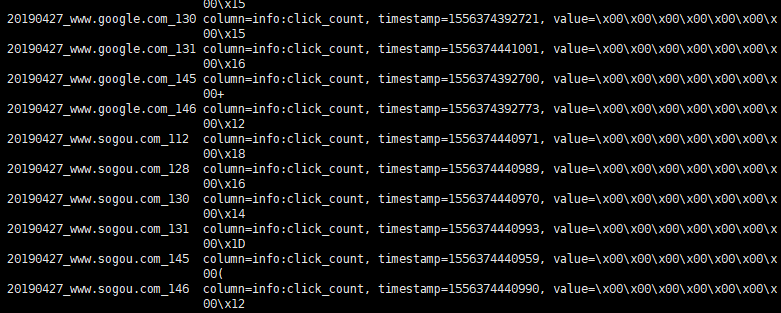
11集群提交任务
- 11.1去掉代码中的本地指定

-
11.2打包上传

- 11.3启动Flume
/usr/local/src/apache-flume-1.6.0-bin/bin/flume-ng agent \
--name a1 \
--conf /usr/local/src/apache-flume-1.6.0-bin/conf \
--conf-file /root/test_spark/streaming_project.conf \
-Dflume.root.logger=INFO,console- 11.4清空hbase表
truncate 'course_clickcount'
truncate 'course_search_clickcount'-11.5提交spark作业
/usr/local/src/spark-1.6.0-bin-hadoop2.6/bin/spark-submit \
--class com.sparkdemo.streaming.KafkaStreamingApp \
--master local[2] \
--name KafkaStreamingApp \
--packages org.apache.spark:spark-streaming-kafka_2.10:1.6.0 \
sparkdemo-1.0-SNAPSHOT-jar-with-dependencies.jar \
master:2181 test streamingtopic 1-11.6测试结果