

Faiss Wiki
Faiss
Faiss是一个高效的相似搜索和密集向量聚类库。它包含了搜索任意大小的向量集合的算法,其中包括那些可能不适合RAM的向量。它还包含用于评估和参数调优的支持代码。Faiss是用c++编写的,带有完整的Python包装器(版本2和3)。一些最有用的算法是在GPU上实现的。它主要是由Facebook人工智能研究在外部贡献者的帮助下开发的。
What is similarity search?
给定维数为d的一组向量x_i, Faiss在RAM中构建了一个数据结构。构造结构后,当给定一个维数为d的新向量x时,它高效地执行操作:
i = argmin_i ||x - x_i||
where ||.|| is the Euclidean distance (L2).
如果是Faiss项,则数据结构是一个索引,一个具有添加x_i向量的方法的对象。注意,x_i是假定是固定的。
计算argmin是对索引的搜索操作。
这就是Faiss的意义所在。它还可以:
-
return not just the nearest neighbor, but also the 2nd nearest, 3rd, ..., k-th nearest neighbor
- 返回多个近邻对象
-
search several vectors at a time rather than one (batch processing). For many index types, this is faster than searching one vector after another
- 批处理搜索,更快
- trade precision for speed, ie. give an incorrect result 10% of the time with a method that's 10x faster or uses 10x less memory
- 牺牲精度换速度
-
perform maximum inner product search argmax_i <x, x_i> instead of minimum Euclidean search. There is also limited support for other distances (L1, Linf, etc.).
- 执行最大内积距离替代欧氏距离,对其他距离也有限支持
-
return all elements that are within a given radius of the query point (range search)
- 返回查询点给定半径内的所有元素
-
store the index on disk rather than in RAM
- 存储index在disk上,rather than in RAM
-
index binary vectors rather than floating-point vectors.
- 索引二进制向量,rather than 浮点型向量
Research foundations of Faiss
等待进一步更新。。。
Getting started
Getting some data
Faiss处理固定维数d的向量集合,通常是10秒到100秒。这些集合可以存储在矩阵中。我们假设行为主存储。向量I的第j个分量存储在矩阵的第I行第j列中。Faiss只使用32位浮点矩阵。
We need two matrices:
xbfor the database, that contains all the vectors that must be indexed, and that we are going to search in. Its size is nb-by-d
xqfor the query vectors, for which we need to find the nearest neighbors. Its size is nq-by-d. If we have a single query vector, nq=1.
在下面的例子中,我们将使用在d=64维中形成均匀分布的向量。为了好玩,我们沿着第一个维度添加小的平移,这取决于向量索引。

In Python, the matrices are always represented as numpy arrays. The data type dtype must be float32.

本例使用普通数组,因为这是所有c++矩阵库支持的最小公分母。Faiss可以容纳任何矩阵库,只要它提供一个指向底层数据的指针。例如std::vector<float>的内部指针是由data()方法给出的。
Building an index and adding the vectors to it
Faiss是围绕Index对象构建的。它封装了数据库向量集,并选择性地对它们进行预处理,以提高搜索效率。索引有很多种类型,我们将使用最简单的版本,只对它们执行强力L2距离搜索:IndexFlatL2。
所有的index都需要知道它们是什么时候建立的也就是它们作用的向量的维数,在我们的例子中是d。然后,大多数指标还需要一个训练阶段,以分析向量的分布。对于IndexFlatL2,我们可以跳过这个操作。
当建立和训练索引时,可以对索引执行两项操作:添加和搜索。
要向索引中添加元素,我们调用add on xb。我们还可以显示索引的两个状态变量:is_training(表示是否需要训练的布尔值)和ntotal(索引向量的数量)。
有些索引还可以存储与每个向量对应的整数id(但不包括IndexFlatL2)。如果没有提供id, add只使用序数向量作为id。第一个向量是0,第二个是1,等等。
In Python
In C++

Results
这应该只显示true(索引已经过训练)和100000(向量存储在索引中)。
Searching
可以在索引上执行的基本搜索操作是k近邻搜索。对于每个查询向量,找到它在数据库中的k个最近的邻居。
该操作的结果可以方便地存储在一个大小为nq × k的整数矩阵中,其中第i行包含查询向量i的邻居的id,按距离增加排序。除了这个矩阵之外,搜索操作还返回一个nq × k的浮点矩阵,它具有相应的平方距离。
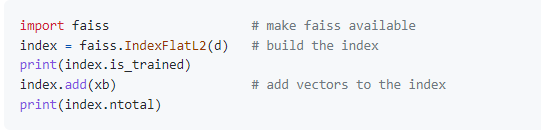
作为一个完整性检查,我们可以首先搜索一些数据库向量,以确保最近的邻居确实是向量本身。
In Python

In C++

该摘录是经过编辑的,否则c++版本会变得非常冗长,请参阅Faiss的教程/cpp子目录中的完整代码。
Results
健全检查的输出应该如下所示
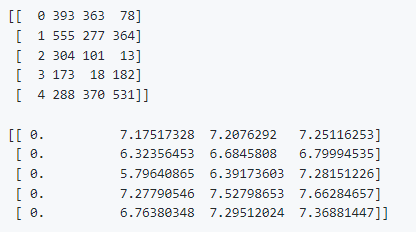
ie。每个查询的最近邻居确实是向量的索引,对应的距离为0。在一行内,距离在增加。
实际搜索的输出类似于
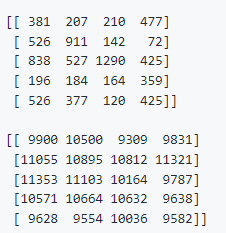
由于添加到向量的第一个分量的值,数据集沿着d-dim空间的第一个轴被涂抹。因此,前几个向量的邻域在数据集的开始附近,而在~10000附近的向量也在数据集的索引10000附近。
在一台2016年的机器上执行上述搜索大约需要3.3秒。
Home · facebookresearch/faiss Wiki (github.com)
