

BLAS 整体概况
clBLAS的主要目标是让开发人员更容易地利用异构计算的固有性能和功耗优势。clBLAS接口不隐藏也不包装OpenCL接口,而是将OpenCL状态管理留给用户控制,以实现最大的性能和灵活性。
clBLAS库生成并排队优化的OpenCL内核,将用户从自己编写、优化和维护内核代码的任务中解放出来。
Basic Linear Algebra Subprograms
基本线性代数子程序(BLAS)是一种规范,它规定了一组低级例程,用于执行常见的线性代数操作,如向量加法、标量乘法、点积、线性组合和矩阵乘法。
它们实际上是线性代数库的标准低级例程;这些例程有C(“CBLAS接口”)和Fortran(“BLAS接口”)的绑定。尽管BLAS规范是通用的,但BLAS实现通常针对特定机器上的速度进行了优化,因此使用它们可以带来实质性的性能优势。BLAS实现将利用特殊的浮点硬件,如向量寄存器或SIMD指令。
它起源于1979年的Fortran库[1],其接口由BLAS技术(BLAST)论坛标准化,其最新的BLAS报告可以在netlib网站上找到。[2]这个Fortran库被称为参考实现(有时被混淆地称为BLAS库),它没有为速度进行优化,但处于公共领域
大多数提供线性代数例程的库都遵循BLAS接口,允许库用户开发与所使用的BLAS库无关的程序。BLAS库的例子包括:OpenBLAS, BLIS(类BLAS库实例化软件),Arm性能库、[5]ATLAS和Intel数学内核库(MKL)。
AMD维护一个为AMD平台优化的BLIS分支ATLAS是一个可移植的库,可以针对任意架构自动优化自身。MKL是一个免费软件[7]和专有的[8]供应商库,针对x86和x86-64进行了优化,并强调Intel处理器的性能OpenBLAS是一个为许多流行架构手工优化的开源库。LINPACK基准测试很大程度上依赖BLAS常规gem进行性能度量。许多数值软件应用程序使用blas兼容的库来进行线性代数计算,包括LAPACK, LINPACK, Armadillo, GNU Octave, Mathematica,[10] MATLAB,[11] NumPy,[12] R, and Julia.
Background
随着数值编程的出现,复杂的子程序库变得很有用。这些库将包含用于常见的高级数学运算的子程序,如求根、矩阵反演和求解方程组。选择的语言是FORTRAN。最著名的数字编程库是IBM的科学子程序包(SSP)。这些子程序库允许程序员专注于他们的特定问题,避免重新实现众所周知的算法。库例程也会比一般的实现更好;例如,矩阵算法可能使用全旋转来获得更好的数值精度。库例程也会有更高效的例程。例如,一个库可以包含一个程序来求解上三角形矩阵。这些库包括一些算法的单精度和双精度版本。
最初,这些子程序对其低级操作使用硬编码循环。例如,如果一个子例程需要执行一个矩阵乘法,那么该子例程将有三个嵌套循环。线性代数程序有许多常见的低级操作(所谓的“内核”操作,与操作系统无关)在1973年和1977年之间,确定了几个这样的内核操作这些内核操作成为数学库可以调用的定义好的子例程。内核调用比硬编码循环更有优势:库例程可读性更强,出现bug的机会更少,内核实现可以优化速度。1979年出版的第1级基本线性代数子程序(BLAS)规范了这些使用标量和向量的核操作利用BLAS实现线性代数子程序库LINPACK。
BLAS抽象允许对高性能进行定制。例如,LINPACK是一个通用库,可以在许多不同的机器上使用,无需修改。LINPACK可以使用BLAS的通用版本。为了获得性能,不同的机器可能使用定制的BLAS版本。随着计算机结构变得越来越复杂,向量机出现了。BLAS的向量机可以使用机器的快速向量运算。(虽然向量处理器最终不再受欢迎,但现代cpu中的向量指令对于BLAS例程中的最佳性能至关重要。)
机器的其他特性变得可用,也可以被利用。因此,BLAS从1984年到1986年增加了与向量矩阵运算有关的第2级核运算。内存层次结构也被认为是可以利用的东西。许多计算机都有比主存快得多的高速缓存;将矩阵操作本地化可以更好地使用缓存。在1987年和1988年,3级BLAS被确定做矩阵矩阵操作。3级BLAS鼓励块分割算法。LAPACK库使用3级BLAS
Functionality
BLAS的功能被分为三组称为“级别”的例程,它们对应于定义和发布的时间顺序,以及算法复杂性的多项式程度;1级BLAS操作通常需要线性时间,O(n), 2级操作需要二次时间,3级操作需要三次时间现代BLAS实现通常提供所有这三个级别。
Level 1
这个层次包括BLAS(1979)的原始表述中描述的所有例程,[1]只定义了跨步数组上的向量操作:点积、向量规范、形式的广义向量加法
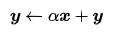
(称为“axpy”,“ax + y”)和其他一些操作。
Level 2
这一层包含矩阵-向量运算,其中包括广义矩阵-向量乘法(gemv):
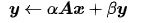
以及线性方程中x的解算器
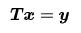
T是三角形的。2级BLAS的设计始于1984年,结果于1988年公布第2级子例程的目的是提高在向量处理器上使用BLAS的程序的性能,而第1级BLAS是次优的,“因为它们对编译器隐藏了操作的矩阵-向量性质。
Level 3
这一层,正式出版于1990年,[19]包含矩阵-矩阵运算,包括“一般矩阵乘法”(gemm)的形式
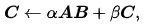
其中A和B可以选择转置或隐士共轭在例程内,所有三个矩阵可以跨行。普通的矩阵乘法A B可以通过设置α为1和C为一个大小适当的全零矩阵来实现。
级别3中还包括用于计算的例程
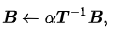
其中T是一个三角矩阵,在其他函数中。
由于矩阵乘法在许多科学应用中无处不在,包括为实现其余的三级BLAS,[21]和因为更快的算法存在超越明显的矩阵向量乘法的重复,gemm是优化BLAS实施人员的首要目标。例如,通过将A, B中的一个或两个分解成块矩阵,gemm可以递归实现。这是包含β参数的动机之一,[可疑的讨论]以便可以累积以前区块的结果。请注意,这种分解需要特殊情况β = 1,许多实现都对这种情况进行了优化,因此消除了每个c值的一次乘法。这种分解允许在产品中使用的数据的空间和时间上更好地本地化引用。反过来,这又利用了系统上的缓存对于具有多个缓存级别的系统,可以按照块在计算中使用的顺序第二次应用阻塞。这两种级别的优化都在诸如ATLAS之类的实现中使用。最近,Kazushige Goto的实现表明,仅对L2缓存进行阻塞,结合对相邻内存进行仔细的摊销,以减少TLB的丢失,这比ATLAS.[23]要好GotoBLAS、OpenBLAS和BLIS是基于这些想法的高度优化的实现。
gemm3m gemm的常见变异,计算复杂产品使用“三个真正的矩阵乘法和五个矩阵添加,而不是传统的四个真正的矩阵乘法和两个矩阵添加”,一个算法类似于Strassen算法首先描述由彼得·安格[24]。
Implementations
