mysql常用语句操作
概述:
1.通过表结构介绍、来操作mysql常用的语法&语句;
2.现在学习下几个基本的sql语句,万变不离其宗,把基础弄扎实了其它的就很容易了
一、表结构&建表:
1.学生基础信息表student:
DROP TABLE IF EXISTS `student`; CREATE TABLE `student` ( `sid` int(11) NOT NULL COMMENT '学生id', `sname` varchar(30) DEFAULT NULL COMMENT '学生姓名', `sage` int(11) DEFAULT NULL COMMENT '学生年龄', `ssex` varchar(8) DEFAULT NULL COMMENT '学生性别', `creation_time` datetime NOT NULL COMMENT '创建时间', PRIMARY KEY (`sid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2.学生成绩表sc:
DROP TABLE IF EXISTS `sc`; CREATE TABLE `sc` ( `sid` INT (11) NOT NULL COMMENT '学生id', `cid` INT (11) NOT NULL COMMENT '成绩id', `score` INT (11) DEFAULT NULL COMMENT '成绩分数', `creation_time` datetime NOT NULL COMMENT '创建时间' ) ENGINE = INNODB DEFAULT CHARSET = utf8mb4;
备注:`sid` 、`cid`、`score`不是引号,而是~号下的 `
二、常用语法:
查询:
1.简单查询
#查询sage等于25 SELECT * from student where sage=25; #查询sage不等于25 SELECT * from student where sage<>25; SELECT * from student where sage!=25; ########逻辑查询 and、or SELECT * from student where sage=25 and sage='女'; SELECT * from student where sage=25 or sage='女'; #in,not in 的用法 SELECT * FROM student WHERE sname in ('刘亦菲','王康','陈三'); SELECT * FROM student WHERE sname not in('刘亦菲','王康','陈三'); ####is 和not is、null #查询不为null SELECT * from student where ssex IS not NULL; #查询为null SELECT * from student where ssex IS NULL; #############限制返回记录: #最后三条 select * from student order by sage desc limit 3; #分页查询(范围) select * from student limit 0,5 #显示前2行 select * from student limit 2 #随机显示3条(RAND()随机函数) select * from student where sname="test" ORDER BY RAND() limit 3 #把查询记录汇总到一条记录(逗号分开) SELECT GROUP_CONCAT(字段) AS combined_names FROM 表名; #把查询记录汇总到一条记录(不分开) SELECT REPLACE(GROUP_CONCAT(字段), ',', '') AS combined_names FROM 表名;
2.范围查询
#查询sage 25到30的数据 SELECT * from student where sage BETWEEN 25 and 30; #查询 creation_time日期范围 SELECT * from student where creation_time BETWEEN '2021-10-03 00:00:00' and '2021-10-25 18:00:00' #查询creation_time数据 SELECT * from student where creation_time like '2021-10-%'
3.分组查询
#查询后分组 SELECT * from student where ssex='女' GROUP BY sage; #分组后倒序 SELECT * from student where ssex='女' GROUP BY sage ORDER BY creation_time desc; #倒序-desc SELECT * from student where ssex='女' ORDER BY creation_time desc; #顺序-asc SELECT * from student where ssex='女' ORDER BY creation_time asc;
4.like匹配查询
#####查询匹配关键字(%表示所有,_表示任意一个字符) #匹配包含'刘'记录 select * from student where sname like '%刘%'; #匹配以'伊朗'结尾的记录 select * from student where sname like '%伊朗';
#匹配以'伊朗'开头的记录 select * from student where sname like '伊朗%'; #匹配任意一个字符(如:刘x菲) select * from student where sname like '刘_菲';
5.子查询
#子查询-包含查询 select * from student where sage in(select sage from student where ssex='女' and sage<30 and creation_time like '2021-10%' GROUP BY sage); #子查询-别名查询 SELECT * from( (SELECT date_format(creation_time,'%Y-%m-%d') as _time FROM districtdervice_task_synchronization where DATE_SUB(CURDATE(),INTERVAL 7 DAY) <=date(creation_time)) ) 别名 GROUP BY _time;
6.单表统计
#统计'2021年10月份'每天的sname字段的个数 SELECT date_format(creation_time,'%Y-%m-%d') as _time ,count(sname) FROM student where creation_time like '2021-10%' GROUP BY DAY(creation_time); #DAY()按天统计 , WEEK()按周统计,MONTH()按月统计,QUARTER()按季度统计,YEAR()按年统计 # date_format日期格式化 #统计最近30天,每天的sname字段的个数 SELECT date_format(creation_time,'%Y-%m-%d') as _time ,count(sname) FROM student where DATE_SUB(CURDATE(), INTERVAL 30 DAY) <=date(creation_time) GROUP BY DAY(creation_time); #统计某个月的记录数 SELECT count(*) from student where creation_time like '%2021-10%'; #查询年龄小于25以性别分组,然后分别统计分组值(分组后在统计) SELECT ssex,count(*) from student where sage <25 GROUP BY ssex;
7.聚合函数
#去重 SELECT distinct* from student; #统计条数 SELECT count(*) from student; #求和 SELECT sum(sage) from student where ssex='女'; #平均数 SELECT avg(sage) from student where ssex='女'; #ROUND(字段,n)保留小数n位 SELECT ROUND(avg(sage),1) as _avg from student where ssex='女'; #最大值 SELECT max(sage) from student where ssex='女'; #最小值 SELECT min(sage) from student where ssex='女';
8.多表连接查询
#等值查询 select * from student st INNER JOIN sc scc on st.sid = scc.sid where st.sage=25 select st.sid,st.sname,st.sage,st.ssex,scc.sid,scc.score from student st INNER JOIN sc scc on st.sid = scc.sid where st.ssex='女'; #左连接 select st.sid,st.sname,st.sage,st.ssex,scc.sid,scc.score from student st left JOIN sc scc on st.sid = scc.sid where st.ssex='女'; #右连接 select st.sid,st.sname,st.sage,st.ssex,scc.sid,scc.score from student st right join sc scc on st.sid = scc.sid where st.ssex='女';
#左连接:
1.若条件成立,显示左右两表数据; 2.条件不成立时,显示左表数据,右表为空(右表的字段都置NULL)
#右连接:
1.若条件成立,显示左右两表数据; 2.条件不成立时,显示右表数据,左表为空(左表的字段都置NULL)
9.REGEXP正则
#匹配包含某个字符的记录 SELECT * FROM student WHERE sname REGEXP '刘'; #匹配字段包含数字的记录 SELECT * FROM student WHERE sname REGEXP '\\d'; SELECT * FROM student WHERE sage REGEXP '[0-9]'; #匹配包含数字5位以上的记录 SELECT * FROM student WHERE sname REGEXP '\\d{5}'; #匹配'王'开头 SELECT * FROM student WHERE sname REGEXP '^王'; #匹配'菲'结尾 SELECT * FROM student WHERE sname REGEXP '菲$'; #匹配整型至少3位开始 SELECT * FROM student WHERE sage REGEXP '^\\d{3,}$'; #匹配整型3到5位(字段为整形,筛选3到5位数) SELECT * FROM student WHERE sage REGEXP '^\\d{3,5}$'; #匹配字符串,显示2到6位的记录 SELECT * FROM dalan_test WHERE apk_link REGEXP '^\\w{2,6}$'; #匹配包含"陈"或"菲"的记录 SELECT * FROM student WHERE sname REGEXP '陈|菲'; #匹配任意一位字符串 SELECT * FROM student WHERE sname REGEXP '刘.菲'; #匹配一次或多次 SELECT * FROM student WHERE sname REGEXP '刘.+菲'; #匹配任意次数 SELECT * FROM student WHERE sname REGEXP '刘*';
10.联合查询
联合查询结果是将多个select语句的查询结果合并到一块,因为在某种情况下需要将几个select语句查询的结果合并起来显示。需要两个表结构一样
其中union选项有两个选项可选
all:表示无论重复都输出
distinct: 去重(整个重复)(默认的)
select * from student union all select * from student111;
备注:不加all,就会过滤相同的记录
Union:
作用:把2次或多次查询结果合并起来
要求:两次查询的列数一致
推荐:查询的每一列,相对应的列类型也一样
#合并两个查询结果 SELECT * from districtdervice_task_synchronization where job_flow_id=20007 UNION SELECT * from districtdervice_task_synchronization where job_flow_id=22420
11.EXISTS的用法
EXISTS用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False
EXISTS 指定一个子查询,检测 行 的存在。
select * from student where sid<10 and EXISTS( select sage from student where ssex='女' and sage<30 and creation_time like '2021-10%' GROUP BY sage );
备注:如果子查询结果为空,那么整体查询也为空
12高级查询case...when....then
注意:使用case...when....then将表中的列数据转为行(表头)构建一个虚表,再使用case...when....then根据条件替换数据
when表示条件,then表示替换的值(可以是字段)
使用场景:等值转换、范围转换、行转列
##___________________________________student表查询_______________________________ #一行显示多个条件并统计 select * from( (select '小于20',count(sage)as 'sage' from student where sage<20) chen20, (select '20到40',count(sage)as 'sage' from student where sage between 20 and 40) wei, (select '大于40',count(sage)as 'sage' from student where sage>40) cheb40 ); #多条件查询后,分组并统计 select count(sage),评分 from( (SELECT sage, (CASE WHEN sage >=40 THEN '优秀' WHEN sage >=30 THEN '及格' ELSE '不及格' END) AS '评分' FROM student) chen) GROUP BY 评分; #使用case...when....then 把条件放到一列 SELECT sage, (CASE WHEN sage >=40 THEN '优秀' WHEN sage >=30 THEN '及格' ELSE '不及格' END) AS '评分' FROM student; #使用case...when....then一行查询 SELECT sage,(case when sage >=40 then '优秀' when sage >=30 then '及格' else '不及格' end) FROM student; #################################行列互转################################ ####################行转列(7001,7002,7003表示表里的成绩id值) #方式一:行转列(查询每个学生的成绩),7001,7002,7003表示表里的成绩id值 SELECT sid, MAX(CASE cid WHEN '7001' THEN score ELSE 0 END) 语文, MAX(CASE cid WHEN '7002' THEN score ELSE 0 END) 数学, MAX(CASE cid WHEN '7003' THEN score ELSE 0 END) 物理 FROM sc GROUP BY sid; #方式二:行转列 SELECT sid, SUM(IF(`cid`='7001',score,0)) as '语文', SUM(IF(`cid`='7002',score,0)) as '数学', SUM(IF(`cid`='7003',score,0)) as '物理' FROM sc GROUP BY sid; #方式三:行转列 SELECT sid,GROUP_CONCAT(`cid`,":",score)AS 成绩 FROM sc GROUP BY sid ###################列转行 SELECT sid,'分数' AS c_score,score AS aaa FROM sc UNION ALL SELECT sid,'时间' AS c_score,creation_time AS aaa FROM sc UNION ALL SELECT sid,'成绩id' AS c_score,cid AS aaa FROM sc ORDER BY sid https://blog.csdn.net/MGmuscler/article/details/125149998
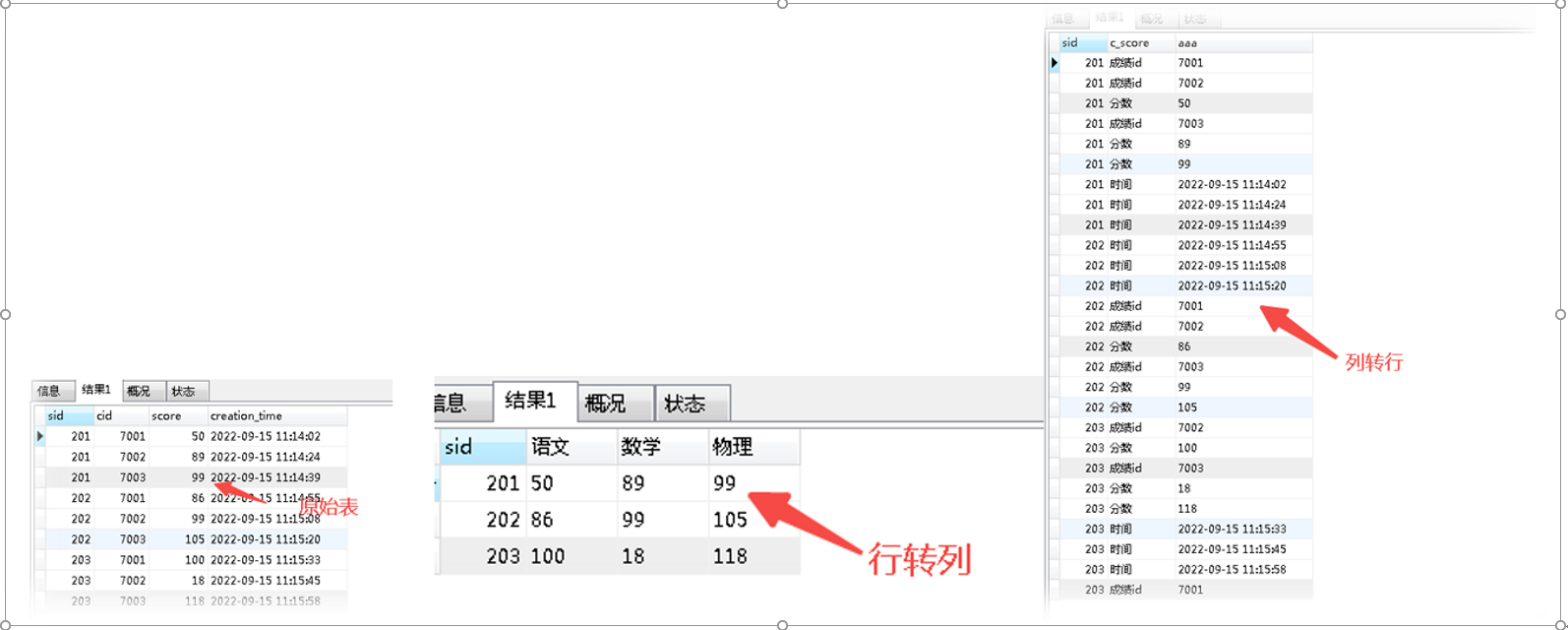
13.查询记录以'逗号'作为条件:
#以student.sname字段作为条件,使用逗号查询 select * from sc as sccc where find_in_set( sccc.sid,(select sname FROM student WHERE sid=3)) #以逗号分割查询,并排序 select * from sc as sccc where find_in_set( sccc.sid,(select sname FROM student WHERE sid=3)) ORDER BY find_in_set( sccc.sid,(select sname FROM student WHERE sid=3))
student表: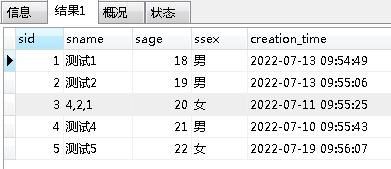 sc表:
sc表: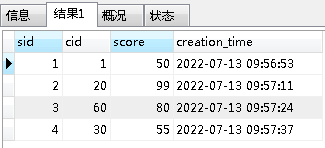
结果: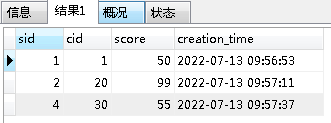 排序结果:
排序结果:
14.日期查询:
##############################通用查询###################################### #查看student表最近30天的记录 SELECT * FROM student where DATE_SUB(CURDATE(), INTERVAL 30 DAY) <=date(creation_time); #查看昨天记录 SELECT * FROM 表名 WHERE TO_DAYS(NOW( ) ) - TO_DAYS( 时间字段名) <= 1; #查看过去7天 SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 7 DAY) <=date(时间字段名); #查看本月 SELECT * FROM 表名 WHERE DATE_FORMAT( 时间字段名, '%Y%m' ) =DATE_FORMAT( CURDATE( ) , '%Y%m' ); #查看上月 SELECT * FROM 表名 WHERE PERIOD_DIFF( date_format( now( ) , '%Y%m' ) , date_format( 时间字段名, '%Y%m' ) ) =1 #查看本年 select * from `ht_invoice_information` where YEAR(create_date)=YEAR(NOW()); #查看上年 select * from `ht_invoice_information` where year(create_date)=year(date_sub(now(),interval 1 year)); ##################################其他################################# #显示creation_time月份最后一天 select *,LAST_DAY(creation_time) AS 月份最后一天 from student #怎么查询creation_time为每月最后一条的记录 SELECT * FROM student WHERE creation_time IN ( SELECT MAX(creation_time) FROM student #按年、月分组(先按年筛选后再按月) GROUP BY YEAR(creation_time), MONTH(creation_time) ); #显示当前年份 select YEAR(NOW())
15.把字段内的字典或json、作为查询条件
#单条件查询 SELECT * FROM dict_table WHERE 字段->>'$.key' = 'value';
SELECT * FROM dict_table WHERE 字段->>'$.key.name' = 'value';
#多条件查询 SELECT * FROM dict_table WHERE 字段->>'$.key1' = 'key1_value' AND 字段->>'$.key2' = 'ykey2_value';
##提取json的值 SELECT JSON_EXTRACT(json_str, '$.key'); #或 SELECT json_str->'$.key' FROM table_name; #或(->>会直接过滤引号) SELECT json_str->>'$.key' FROM table_name;
##用于去除JSON字符串值的引号 SELECT JSON_UNQUOTE(JSON_EXTRACT(json_str, '$.key')); ##用于在JSON文档中添加新的键值对或替换现有的键值。 UPDATE table_name SET json_str = JSON_REPLACE(json_str, '$.key', 'new_value'); ##用于从JSON文档中移除指定的键。 UPDATE table_name SET json_str = JSON_REMOVE(json_str, '$.key');
插入:
#指定全字段插入 INSERT INTO student(sid,sname,sage,ssex,creation_time) VALUES('19','招佳轩',32,'女','2021-10-07 16:48:31'); #指定部分字段插入 INSERT INTO student(sid,sname,sage,creation_time) VALUES('20','招佳轩',32,'2021-10-07 16:48:31'); #直接插入 INSERT INTO student VALUES('21','招佳轩',32,'男','2021-10-07 16:48:31'); #通过set插入 INSERT INTO student set sid=23,sname='招佳轩',sage=25,ssex='男',creation_time='2021-10-07 16:48:31';
#先查询将查询结果插入数据表:
INSERT INTO 表名1(字段1) SELECT 字段2 FROM 表名2 WHERE 条件表达式;
更新:
#普通更新 UPDATE student SET ssex = '男',sname = '100' WHERE sage=30; #连表更新 update student,sc set student.sname='这是测试111',sc.score='59' where student.sid=sc.sid and student.sage=29; #同表条件更新(条件和更新字段在同一个表) update student set sname='test123' WHERE sid IN( SELECT stu.sid from( SELECT sid from student where sname='王丽') stu ) #子更新(条件和更新字段不在同表) UPDATE student SET sage=50 WHERE sname IN(SELECT student_chen.sname from student_chen WHERE student_chen.sid=31) #JSON_QUOTE()函数用于将一个值转换为一个合法的 JSON 字符串 UPDATE 表名 SET 字段 = JSON_QUOTE( "{\"tt_sport_data.read_minutes\":\"5\",\"tt_sport_data.min_video_view_num\":\"6\",\"tt_sport_data.max_video_view_num\":\"14\",\"tt_sport_data.keywords\":\"运动,健身\",\"tt_sport_data.zhibo_action_weights\":\"30,20,50\",\"tt_sport_data.video_action_weights\":\"20,20,10,20,30\"}") WHERE id="123456"
#把结果加上双引号 UPDATE 表名 SET 字段 = JSON_QUOTE( '{"name":"wei","id":"5555"}') WHERE id="123456"
删除:
delete 和 truncate 仅仅删除表数据(这两种都不删除表的结构),drop 连表数据和表结构一起删除。
truncate和drop不能回滚(删除后不能找回数据),delete可以回滚数据
执行的速度上:drop>truncate>delete,打个比方,drop 是神舟火箭,truncate 是和谐号动车,delete 是自行车。
truncate不用写日志,delete要写日志,前者的删除效率要高于后者,前者是整体删除后者是逐句删除
truncate是将这个表的所有数据都删除,而delete可以用where条件删除部分数据,也可以删除所有数据
#####delete#### #指定条件删除记录(不加where条件是清空表、where条件后可加and或or) DELETE FROM student where sage=30; #删除条件为空的数据 delete from 表名 where 字段 is null; ###truncate### #删除表的所有记录,保留表 TRUNCATE table 表名; ###drop### #删除结构及表 drop table 表名; #删除表字段 alter table 表名 drop column 字段;
库、表的相关命令:
###################表结构修改############ #修改字段类型 alter table 表名 modify 字段 字段类型; #添加新的字段 alter table 表名 add 字段 字段类型; #添加字段并指定位置 alter table 表名 add 字段 字段类型 after 字段; #删除表字段 alter table 表名 drop 字段名; #修改指定的字段 alter table 表名 change 原字段名字 新的字段名字 字段类型; #修改表名 ALTER TABLE 旧表名 RENAME TO 新表名; #################数据库、表常用查询############## #查看所有的数据库 show databases; #创建一个叫test的数据库 create database test; #删除一个叫test的数据库 drop database test; #选中库 ,在建表之前必须要选择数据库 use test; #在选中的数据库之中查看所有的表 show tables; #创建表 create table 表名 (字段1 类型, 字段2 类型); #查看所在的表的字段 desc 表名; #删除表 drop table 表名; #查看创建库的详细信息 show create database 库名; #查看创建表的详细信息 show create table 表名;
约束条件:
定义:针对表中的数据,进行额外的限制,就称为约束。
|
约束类型:
|
自动增长(用于主键后)
|
主键 |
默认值
|
唯一
|
外键
|
非空 |
|
关键字
|
AUTO_INCREMENT
|
PRIMARY KEY
|
DEFAULT
|
UNIQUE
|
FOREIGN KEY
|
not null
|
CREATE TABLE department( id INT , #id int primary key # 主键(这是列级约束) dpt_name CHAR(20) NOT NULL , #非空 age int not null UNIQUE , #唯一 people_num INT(10) DEFAULT '10', #(默认值为10) CONSTRAINT dpt_pk PRIMARY KEY (id) #主键(表级约束) );
以上的代码中,我们涉及到了两种声明主键约束的方法,一种是列级约束id int primary key ,一种是表级约束CONSTRAINT dpt_pk PRIMARY KEY(id)。
自动增长:
CREATE TABLE emp5( id INT PRIMARY KEY AUTO_INCREMENT, # 这里列级约束,AUTO_INCREMENT为自增长,在未给值的时候实现自动递增 emp_name VARCHAR(15), salary DOUBLE(10,2), email VARCHAR(25) );
创建表外键:
CREATE TABLE chen( id INT NOT NULL, chen char(10), PRIMARY KEY(id) #表示主键 ); TYPE=INNODB; #(表示想数据库系统说明我用的是innodb的存储引擎)
CREATE TABLE wei( id INT, popo char(10), user_id INT, INDEX 外键别名(user_id), #创建表外键别名 FOREIGN KEY(user_id) REFERENCES chen(id) #创建表外键及指定父表 ON DELETE CASCADE);TYPE=INNODB;
备注:1.wei表的外键 user_id指向chen表的id,,插入wei.user_id字段前需要依赖chen表的id 2.若要删除wei,chen这两个表,则必须先删除wei表,再删除chen表
三、通用语法:
1.连接数据库
#远程连接 mysql -h 主机地址 -u 用户名 -p 用户密码 #本地连接 mysql -u 用户名 -p
2.查询连接数
#查看最大连接数 show variables like '%max_connections%'; #当前打开的连接的数量 show status like '%Threads_connected%'; #重新设置最大连接数 set global max_connections=1000 #同时使用的连接的最大数目 show status like '%Max_used_connections%'; #发往服务器的查询的数量 show status like '%Questions%' #尝试已经失败的MySQL服务器的连接的次数 show status like '%Aborted_connects%'; #试图连接MySQL服务器的次数。 show status like '% Connections%';
3.获取时间&日期
#获取当前时间戳 select unix_timestamp(now()); #获取当前时间戳 SELECT UNIX_TIMESTAMP(); #获取当前日期+时间 SELECT now(); #获取当前日期 SELECT curdate(); #获取当前时间 SELECT curtime(); #日期转时间戳(UNIX_TIMESTAMP函数:日期转时间戳) SELECT UNIX_TIMESTAMP(字段) time FROM 表名 where条件 #FROM_UNIXTIME函数:时间戳转日期 (第二个参数非必填,默认:%Y-%m-%d %H:%i:%s) select FROM_UNIXTIME(字段) FROM 表名 #时间戳转日期,自定义返回日期格式: select FROM_UNIXTIME(字段,'%Y-%m-%d %T') FROM 表名 where条件
4.查看数据库信息&表信息
#查询当前用户 select user(); #查询表创建信息 show create table 表名; #查询数据库版本 select version(); #查询当前使用的数据库 select database(); #显示表结构及字段备注 SHOW FULL COLUMNS FROM 表名; #显示表结构、不含字段备注 desc 表名;
5.系统级操作&触发器
#查看当前使用的存储引擎 show variables like '%storage_engine%'; #查看数据库中已创建的触发器 SHOW TRIGGERS; #指定字符编码(一般用在建表的时候) DEFAULT CHARSET=utf8;
#我们如果要修改触发器,必须首先删除它并使用新的代码重新创建。 #因为在MySQL中没有类似:ALTER TRIGGER语句,因此,我们不能像修改其他数据库对象,如表,视图和存储过程那样修改触发器。 #使用drop trigger语句来删除现有的触发器: DROP TRIGGER IF EXISTS 触发器名称 或者DROP TRIGGER IF EXISTS 数据库名字.触发器名称 #如果要删除与employees表相关联的before_employees_update触发器,则可以执行以下语句: drop trigger employees.before_employees_update; #创建触发器 create trigger 触发器名称 after delete on 表名1 for each row begin update 表2 set 表2字段= 1 where 表2字段 = 10; end; 解释:after是执行之后触发,before是执行前触发,,,,,delete表示表1有删除操作后,就更新表2 触发器只有delete,insert ,UPDATE操作 触发器相关语法: show triggers like 'table'(查看表是否创创建触发器),,DROP TRIGGER 触发器名称(删除已创建的触发器)
6.用户新增&权限&修改密码
#新增用户 (如果想所有用户可在所有主机访问可把 用户名@登录主机 改为%@%) grant select on 数据库.* to 用户名@登录主机 identified by "密码"; #允许root用户远程访问所有的数据库 GRANT ALL PRIVILEGES ON *.* TO 'root'@'%';
#授权用户 grant all on test.*to'xiaoming'@'localhost'; #刷新权限 flush privileges; #取消授权 revoke all on test.* from 'xiaoming'@'localhost'; #改密码 mysqladmin -u 用户名 -p 旧密码 password 新密码; #删除用户 drop user 'xiaoming'@'localhost';
7.mysql备份&恢复
#备份: 语法:mysqldump -h服务器地址 -u登录名 -p 数据库名> 文件名 例子:mysqldump -hlocalhost -uroot db>e:/db.sql #恢复: 语法:mysql -h服务器地址 -u登录名 -p 数据库名<文件名 例子:mysql -hlocahost -uroot -p db2<e:/db.sql
8.其他
#创建A表从B表备份(表备份) CREATE TABLE A表 AS SELECT * FROM 表B where id=1 #创建表先先判断是否存在,存在就先删除 DROP TABLE IF EXISTS `test_chen`; CREATE TABLE `test_chen` ( `sid` int(11) NOT NULL COMMENT '学生id', `sname` varchar(30) DEFAULT NULL COMMENT '学生姓名' ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; #用文本方式将数据装入数据表中、 LOAD DATA LOCAL INFILE “D:/mysql.txt” INTO TABLE 表名; #查询字段在哪些表存在 SELECT * FROM information_schema.COLUMNS WHERE COLUMN_NAME='字段'; #查看表的创建时间 select CREATE_TIME from INFORMATION_SCHEMA.TABLES where TABLE_NAME='表名'; #查看表结构引擎及修改结构时间 select * from information_schema.tables where table_schema='db_name' and table_name='table_name';
###############mysql分区#################
什么是分区,分区呢就是把一张表的数据分成N多个区块,这些区块可以在同一个磁盘上,也可以在不同的磁盘上
#查看mysql是否支持分区(5.1之后才支持分区) SHOW VARIABLES LIKE '%partition%'; #可以查看表是否为分区表 show table status like 'ceshi2'; #查看分区个数,以及分区的行数(分区名称、分区描述、分区表达式、表行) select partition_name, PARTITION_DESCRIPTION, PARTITION_EXPRESSION, table_rows from information_schema.partitions where table_name = 'ceshi2' #查看分区的信息 select * from information_schema.partitions where table_schema=schema() and table_name = 'ceshi2';
四、存储过程:
CREATE PROCEDURE 存储过程名称() BEGIN 这里写业务逻辑和SQL END
案例:
##########################根据条件查询########################## create procedure chen(a int) if a <5 then select * from element_list where id<50; elseif a>10 and a<50 then SELECT * FROM element_list WHERE id>50; else SELECT * FROM node_list; end if; #调用存储过程函数 CALL chen(12) #########################创建存储过程变量##################### CREATE PROCEDURE GreetWorld () BEGIN SELECT CONCAT(@chen, ' World'); SET @chen = '123'; END; #调用存储过程函数 CALL GreetWorld(); #####################统计表的数据############################ DELIMITER $$ CREATE PROCEDURE chen_select(IN s_sex CHAR(10),OUT s_count INT)#s_sex参数-char类型(宽度必须大于等于输入菜单字符),,s_count参数-int类型 -- 存储过程体 BEGIN -- 把SQL中查询的结果通过INTO赋给变量 SELECT COUNT(*) INTO s_count FROM element_list WHERE control_element= s_sex; SELECT s_count; END$$ DELIMITER ; -- @s_count表示测试出输出的参数 call chen_select('关闭公告',@s_count) #############################数据循环########################## DELIMITER $$ CREATE PROCEDURE demo7 (IN num INT, OUT SUM INT) BEGIN SET SUM = 0 ; REPEAT -- 循环开始 SET num = num + 1 ; SET SUM = SUM + num ; UNTIL num >= 10 END REPEAT ; -- 循环结束 SELECT SUM ; END$$ DELIMITER ; #调用存储过程函数 CALL demo7(9,@sum); #######################通过存储过程插入数据######################################## DELIMITER $$ CREATE PROCEDURE demo_insert(IN s_student VARCHAR(10),IN s_sex CHAR(10),OUT s_result VARCHAR(20)) #s_student=Jim , s_sex=女 , s_result用于回显变量 BEGIN -- 声明一个变量 用来决定这个名字是否已经存在 DECLARE s_count INT DEFAULT 0; -- 验证这么名字是否已经存在(统计名字次数) SELECT COUNT(*) INTO s_count FROM student WHERE `name` = s_student;#判断name=s_student的次数 #没有等于0就插入数据 IF s_count = 0 THEN INSERT INTO student (`name`, sex) VALUES(s_student, s_sex); SET s_result = '数据添加成功'; ELSE SET s_result = '名字已存在,不能添加'; SELECT s_result; END IF; END$$ DELIMITER; #调用存储过程函数 CALL demo9("Jim","女",@s_result); #########################多条件查询################################################## DELIMITER $$ CREATE PROCEDURE chen_node(s_sex int) -- 存储过程体 BEGIN -- 把SQL中查询的结果通过INTO赋给变量 select * from element_list as ele where find_in_set( ele.id,(select associated_element FROM node_list WHERE id=s_sex)) ORDER BY find_in_set( ele.id,(select associated_element FROM node_list WHERE id=s_sex)); END$$ DELIMITER ; #调用存储过程函数 call chen_node(180)
#########################循环插入数据############################################### create procedure chen( ) BEGIN DECLARE i INT; SET i=0; WHILE i<100 DO INSERT INTO huju(id) VALUES(3); SET i=i+1; end WHILE; end;
五、概念&理论:
1.where和having的区别

2.内联接,外联接区别
内连接是保证两个表中所有的行都要满足连接条件,而外连接则不然。
在外连接中,某些不满条件的列也会显示出来,也就是说,只限制其中一个表的行,而不限制另一个表的行。分左连接、右连接、全连接三种。
3.什么是存储过程?用什么来调用
5.Navicat查询数据后不能修改数据
如果表中没有设置或添加一列作为primary key(主键)的话,是无法直接进行修改操作的。我们只需要添加或者设置其中一列(比如ID字段)设置为primary key并且自动递增,在查询时,添加该字段,就可以直接修改操作了
#———————————————————————————补充——————————————————————————————————————————————————————
一、索引:
1.索引类型:
1.普通索引、2.唯一索引、3.主键索引、4.组合索引、5.全文索引
2.索引作用:
- 它很类似与现实生活中书的目录,不需要查询整本书内容就可以找到想要的数据(提高查询速度)
3.使用场景:
- 经常需要搜索的列上,可以加快搜索的速度;
- 经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
- 经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
4.优点:
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性
- 可以大大加快数据的检索速度,这也是创建索引的最主要的原因
- 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间
5.缺点:
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
- 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度
- 索引非常占内存,所以索引也需要谨慎添加,那些字段需要索引
语法案例:
1______________________普通索引_______________________________________________________ 是最基本的索引,它没有任何限制。它有以下几种创建方式: 直接创建索引 CREATE INDEX index_name ON table(column(length)) 修改表结构的方式添加索引 ALTER TABLE table_name ADD INDEX index_name ON (column(length)) 创建表的时候同时创建索引 CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) CHARACTER NOT NULL , `content` text CHARACTER NULL , `time` int(10) NULL DEFAULT NULL , PRIMARY KEY (`id`), INDEX index_name (title(length)) ) 删除索引 DROP INDEX index_name ON table #_______________________________唯一索引____________________________________________________ 与普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。 如果是组合索引,则列值的组合必须唯一 创建唯一索引 CREATE UNIQUE INDEX indexName ON table(column(length)) 修改表结构 ALTER TABLE table_name ADD UNIQUE indexName ON (column(length)) 创建表的时候直接指定 CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) CHARACTER NOT NULL , `content` text CHARACTER NULL , `time` int(10) NULL DEFAULT NULL , UNIQUE indexName (title(length)) ); #_________________________________主键索引_________________________________________ 是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。 一般是在建表的时候同时创建主键索引: CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) NOT NULL , PRIMARY KEY (`id`) ); #________________________________组合索引___________________________________________ 指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合 ALTER TABLE `table` ADD INDEX name_city_age (name,city,age);
备注:indexName索引名字, table表名称,column字段名,length限制长度
相关连接:
https://blog.csdn.net/weixin_39411321/article/details/90602030 ............................mysql联合查询、连接查询、子查询
https://www.cnblogs.com/donleo123/p/11642510.html ............................................MySQL(学生表、教师表、课程表、成绩表)多表查询
https://codeleading.com/article/93662363253/........................................................Mysql高级查询,列转行,大于等于80表示优秀,大于等于60且小于80表示及格,小于60表示不及格(case when的使用场景)
https://www.cnblogs.com/meipu/p/13140835.html ..................................................mysql操作记录查看,表的约束条件
https://blog.csdn.net/qq_41772384/article/details/124251674...............................mysql存储过程的使用详解 ,,存储过程详解,,存储过程详解
https://m.php.cn/article/416691.html ......................................................................mysql索引篇 ,,mysql表映射
https://www.cnblogs.com/think-and-do/p/6591523.html .........................................python清洗mysql,,excel数据清洗
https://blog.csdn.net/u010797364/article/details/123400980 ................................docker搭建 数据库监控开源工具Lepus,,Lepus
https://blog.csdn.net/fish_study_csdn/article/details/123937237 ...........................慢查询日志分析工具mysqldumpslow,慢查询日志分析
https://zhuanlan.zhihu.com/p/98392844 .................................................................分表、分库、分区详解、分区管理案例、mysql分区实例详情介绍 ,,分区分表理论
https://www.cnblogs.com/jdy1022/p/14395929.html ..............................................水平拆分 — 分表,,MyCat的介绍及 ,,mysql存json数据


 浙公网安备 33010602011771号
浙公网安备 33010602011771号