
文件处理_配置文件_excel_文件下载
文件读取及判断
主要按照分类标准来看,方便记忆:
- 是否可写
- w 仅可写,写覆盖
- a 仅可写,写追加
- w+ 可以读写,写覆盖
- r+ 可以读写,写覆盖
- a+ 可以读写,写追加
- wb 以二进制格式打开一个文件只用于写入(如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件)
- 是否可读
- r 仅可读
- r+ 可以读写
- w+ 可以读写
- a+ 可以读写
- rb 以二进制格式打开一个文件用于只读
- 不可读的打开方式: w a
- 如果不存在会创建新文件的打开方式:a a+ w w+
###################################1.普通文件操作部分#####################################################
1.文件操作方法:
#!/usr/bin/env python # encoding: utf-8 ''' Created on 2017年9月15日 @author:实现文件读写_判断_处理操作 ''' import os import shutil # os.remove(r"H:\123.txt")#删除指定文件 # chen=os.path.isfile(r"H:\1234.txt")#检验路径是否有指定文件 # os.removedirs(r"c:\python")#删除目录 # chen1=os.path.isdir(r"H:\wei")#检验路径是否有指定目录 # chen2=os.path.split(r"H:\656.txt")#返回文件名和路径 # chen3=os.stat(r"H:\656.txt")#获取文件属性 # chen4=os.path.getsize(r"H:\656.txt")#获取文件大小,以字节计算 # chen5=os.mkdir('chenwei')#在当前位置创建一个目录 # chen6=os.makedirs(r"H:/667/chen")#指定位置创建目录 # os.mknod("test.txt")#创建空文件 # chen7= open(r"h:/test.txt",'r')#直接打开一个文件,如果文件不存在则创建文件 # shutil.move(r"H:\656.txt",r"H:\444")#移动文件 # ______________________________读文件________________________________________________ ##=================方式一:open================== w = open('123.txt','r') #shu = w.readline()#读取一行 shu = w.read()#读取全部 #shu = w.readlines()#把内容按行读取到list(数组)中 print('文件内容:\n%s'%shu) w.close() ##不推荐使用,打开文件后需要手动关闭,不然报错 # #==================方式二:with open================= with open('123.txt', 'r') as f: data = f.read()#readline(),readlines() #print('文件内容:{}'.format(data)) print('文件内容:{}'.format(data))#关闭文件后打印文件内容 ##推荐使用,获取后自动关闭文件 ## ___________________________写入文件__________________________________________________ ##===============方式一============================= wen= 'hrhufgrhfurufhu5556556566666sssss56656' abc= open('123.txt','a')#没有文件自动新建,w会覆盖原本的内容,a表示追加 abc.write(wen)#把wen写入abc,后面加换行符 #abc.writelines(wen)#把wen写入abc,不加任何东西 abc.close() ##==============方式二=============================== with open('123.txt', 'w') as f: data = '123456chen5666\naaabbbccc' f.write(data) #________________________读写文件-二进制______________________________________________________ # 要读取二进制文件,比如图片、视频等等,用'rb'模式打开文件即 #########读文件######### with open(r'C:\Users\Administrator\Desktop\123.png', mode='rb') as f: text=f.read() #print('文件内容:\n{}'.format(text)) #写文件 with open(r'C:\Users\Administrator\Desktop\IOS_Dalan_Automation\test123.png', mode='wb') as tt: tt.write(text)#把123.png写入test123.png #----------------------------------读取时连续read()获取空--------------------------------------- ##原因:对象被read后,文件指针会指到最后,再次read会从当前指针(也就是文件最后)读取内容,所以就是空 with open(r'C:\Users\Administrator\Desktop\123.txt', 'r') as fid: print(fid.read()) # 一定要加这一句,将游标移动到文件开头 fid.seek(0) print(fid.read()) # # ————————————判断文件中是否存在某个字符—————————————————————— with open('d://12345.txt', 'r') as foo: # foo=open('d://12345.txt','r') # chen=foo.readlines() # print(chen[1]) for chen in foo.readlines(): # foo.readlines()把内容按行读取到list中, chen表示循环行数 if '陈伟' in chen: print(chen) # # —————————————————读取文件、去掉换行符———————————————————————————— wo = open(r'G:\eclipse_1\web_selenium1\test\123.txt', 'r') shu1 = wo.readline() shu = shu1.strip('\n') # 去掉换行符 # # ——————————判断str中是否包含某个字符———————————————— cc = 'hduheudheuw陈伟额656565656565wedwdw' keke = 'yy' in cc print(keke) # true或false # # ——————————判断str中是否包含某个字符(也可以判断字符串位置)———————————————— string = 'helloworldchenwei565656566565656565656565' # 判断某个字符是否在string变量中 if string.find('chenwei') == 10: # 判断chenwei位置是否从10开始(10可加可不加) print('Exist') else: print('not Exist') ###_________________________读文件去掉空白行,再写入文件_______________________________________ def delblankline(infile, outfile): infopen = open(infile, 'r')#读文件 outfopen = open(outfile, 'w')#写文件 lines = infopen.readlines()#获取所有行为list for line in lines: if line.split(): #print(line.split()) #把字符串转成list outfopen.writelines(line) else: pass infopen.close() outfopen.close() delblankline("aa.txt", "o4444.txt")#目标文件,处理后保存的文件 ##____________________________直接读文件并过滤空白行___________________________________________ ##方法一: file1 = open('aa.txt', 'r') #可以指定编码 encoding="utf-8" for line in file1.readlines(): if line.split(): aa=line.strip()#删除左右两端空格 print(aa) file1.close() ##方法二: bb='' with open(r'aa.txt','r') as fr: for text in fr.readlines(): if text.split(): bb+=text.strip()+'\n' #变量追加需要加\n换行(直接打印不用加\n) print(bb)
文件和目录操作:


#!/usr/bin/env python # -*- coding: utf-8 -*- import os import json import shutil from pathlib import Path def copy_file(source_file,dest_file,count=20): '''功能:把文件复制并重命名多个文件 参数:source_file父文件路径(绝对路径), dest_file生成后存放的目录, count生文件的个数 ''' for i in range(1,count+1): dest_filenew = dest_file + "\\"+str(i) + os.path.split(source_file)[1] # 复制文件并重命名 shutil.copy(source_file, dest_filenew) # 确认复制成功 if os.path.exists(dest_filenew): print(f"文件已成功复制并重命名为:{dest_filenew}") else: print("文件复制失败") def del_file(path): """功能:清空目录所有文件""" try: for elm in Path(path).glob('*'): elm.unlink() if elm.is_file() else shutil.rmtree(elm) except: print("清空文件异常") if __name__ == '__main__': source_file=r"C:\Users\chenwei3\Desktop\knowledgefile\mainfile\maxfilea.xlsx" dest_file=r"C:\Users\chenwei3\Desktop\knowledgefile\sub_file" #清空目录数据保留目录 del_file(dest_file) #复制并重命名文件 copy_file(source_file,dest_file,5)
#####################################2.excel读写###############################################################
1.读取excel数据:
import xlrd import xlwt def read_excel(): # 打开文件 workBook = xlrd.open_workbook('data/HanXueLi_201801.xlsx'); # 1.获取sheet的名字 # 1.1 获取所有sheet的名字(list类型) allSheetNames = workBook.sheet_names(); print(allSheetNames); # 1.2 按索引号获取sheet的名字(string类型) sheet1Name = workBook.sheet_names()[0]; print(sheet1Name); # 2. 获取sheet内容 ## 2.1 法1:按索引号获取sheet内容 sheet1_content1 = workBook.sheet_by_index(0); # sheet索引从0开始 ## 2.2 法2:按sheet名字获取sheet内容 sheet1_content2 = workBook.sheet_by_name('Sheet1'); # 3. sheet的名称,行数,列数 print(sheet1_content1.name,sheet1_content1.nrows,sheet1_content1.ncols); # 4. 获取整行和整列的值(数组) rows = sheet1_content1.row_values(3); # 获取第四行内容 cols = sheet1_content1.col_values(2); # 获取第三列内容 print(rows); # 5. 获取单元格内容(三种方式) print(sheet1_content1.cell(1, 0).value); print(sheet1_content1.cell_value(2, 2)); print(sheet1_content1.row(2)[2].value); # 6. 获取单元格内容的数据类型 # Tips: python读取excel中单元格的内容返回的有5种类型 [0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error] print(sheet1_content1.cell(1, 0).ctype); if __name__ == '__main__': read_excel()
2.list嵌套字典写execl:
# -*- coding: utf-8 -*- import xlsxwriter # 生成excel文件 def generate_excel(expenses): workbook = xlsxwriter.Workbook('rec_data.xlsx') worksheet = workbook.add_worksheet() # 设定格式,等号左边格式名称自定义,字典中格式为指定选项 # bold:加粗,num_format:数字格式 bold_format = workbook.add_format({'bold': True}) # money_format = workbook.add_format({'num_format': '$#,##0'}) # date_format = workbook.add_format({'num_format': 'mmmm d yyyy'}) #设置列的宽度(下标从0开始) worksheet.set_column(5,6, 40)# 把5列6列宽度改为40(从0开始) worksheet.set_column(3,3, 15) worksheet.set_column(9,10, 30) # 用符号标记位置,例如:A列1行 worksheet.write('A1', '项目', bold_format) worksheet.write('B1', '模块', bold_format) worksheet.write('C1', '用例id', bold_format) worksheet.write('D1', '用例描述', bold_format) worksheet.write('E1', '是否启用', bold_format) worksheet.write('F1', 'headers', bold_format) worksheet.write('G1', '请求url', bold_format) worksheet.write('H1', '请求方式', bold_format) worksheet.write('I1', '请求数据', bold_format) worksheet.write('J1', '预期结果', bold_format) worksheet.write('K1', '执行结果', bold_format) worksheet.write('L1', '测试结果', bold_format) worksheet.write('M1', '测试人员', bold_format) row = 1 col = 0 for item in (expenses): # 使用write_string方法,指定数据格式写入数据 worksheet.write_string(row, col, item['项目']) worksheet.write_string(row, col + 1, item['模块']) worksheet.write_string(row, col + 2, item['用例id']) worksheet.write_string(row, col + 3, item['用例描述']) worksheet.write_string(row, col + 4, item['是否启用']) worksheet.write_string(row, col + 5, item['headers']) worksheet.write_string(row, col + 6, item['请求url']) worksheet.write_string(row, col + 7, item['请求方式']) worksheet.write_string(row, col + 8, item['请求数据']) worksheet.write_string(row, col + 9, item['预期结果']) worksheet.write_string(row, col + 10, item['执行结果']) worksheet.write_string(row, col + 11, item['测试结果']) worksheet.write_string(row, col + 11, item['测试人员']) row += 1 workbook.close() if __name__ == '__main__': rec_data = [{'请求数据': '', '用例id': 'login_3', '预期结果': '{"data":{"yesterday":{"date":"6日星期一","high":"高温 12℃","fx":"北风","low":"低温 -3℃","fl":"<![CDATA[3级]]>","type":"晴"},"city":"北京","forecast":[{"date":"7日星期二","high":"高温 10℃","fengli":"<![CDATA[1级]]>","low":"低温 -3℃","fengxiang":"西北风","type":"多云"},{"date":"8日星期三","high":"高温 7℃","fengli":"<![CDATA[1级]]>","low":"低温 0℃","fengxiang":"南风","type":"阴"},{"date":"9日星期四","high":"高温 8℃","fengli":"<![CDATA[1级]]>","low":"低温 -1℃","fengxiang":"东南风","type":"多云"},{"date":"10日星期五","high":"高温 8℃","fengli":"<![CDATA[1级]]>","low":"低温 -1℃","fengxiang":"北风","type":"多云"},{"date":"11日星期六","high":"高温 8℃","fengli":"<![CDATA[1级]]>","low":"低温 0℃","fengxiang":"北风","type":"阴"}],"ganmao":"感冒高发期,尽量避免外出,外出戴口罩防护。","wendu":"3"},"status":1000,"desc":"OK"}', '请求url': 'https://qqlykm.cn/api/api/tq.php?city=北京', '实际返回': '{"data":{"yesterday":{"date":"7日星期二","high":"高温 10℃","fx":"西北风","low":"低温 -3℃","fl":"<![CDATA[1级]]>","type":"多云"},"city":"北京","forecast":[{"date":"8日星期三","high":"高温 6℃","fengli":"<![CDATA[1级]]>","low":"低温 0℃","fengxiang":"南风","type":"阴"},{"date":"9日星期四","high":"高温 8℃","fengli":"<![CDATA[1级]]>","low":"低温 -1℃","fengxiang":"东风","type":"阴"},{"date":"10日星期五","high":"高温 8℃","fengli":"<![CDATA[1级]]>","low":"低温 0℃","fengxiang":"北风","type":"多云"},{"date":"11日星期六","high":"高温 8℃","fengli":"<![CDATA[2级]]>","low":"低温 -1℃","fengxiang":"北风","type":"阴"},{"date":"12日星期天","high":"高温 4℃","fengli":"<![CDATA[3级]]>","low":"低温 -6℃","fengxiang":"西北风","type":"晴"}],"ganmao":"感冒多发期,适当减少外出频率,适量补充水分,适当增减衣物。","wendu":"5"},"status":1000,"desc":"OK"}', '测试结果': '', '项目': '天气预报', '请求方式': 'GET', '模块': '获取天气', '用例描述': '获取北京天气', 'headers': "{'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8'}", '执行结果': '', '测试人员': '', '是否启用': 'yes'}] generate_excel(rec_data)
如图:

3.二维list写入execl及读取:
#!/usr/bin/env python # encoding: utf-8 import openpyxl def write_excel_xlsx(path, sheet_name, value): '''写数据''' index = len(value) workbook = openpyxl.Workbook() sheet = workbook.active sheet.title = sheet_name for i in range(0, index): for j in range(0, len(value[i])): sheet.cell(row=i+1, column=j+1, value=str(value[i][j])) workbook.save(path) print("xlsx格式表格写入数据成功!") def read_excel_xlsx(path, sheet_name): '''读数据''' workbook = openpyxl.load_workbook(path) # sheet = wb.get_sheet_by_name(sheet_name)这种方式已经弃用,不建议使用 sheet = workbook[sheet_name] for row in sheet.rows: for cell in row: print(cell.value, "\t", end="") print() #需要写入的数据 value3 = [["姓名", "性别", "年龄", "城市", "职业"], ["111", "女", "66", "石家庄", "运维工程师"], ["222", "男", "55", "南京", "饭店老板"], ["333", "女", "27", "苏州", "保安"],] book_name_xlsx = 'xlsx格式测试工作簿.xlsx' #给保存的文件取名字 sheet_name_xlsx = 'xlsx格式测试表' #定义Sheet1 if __name__ == "__main__": #写入数据 write_excel_xlsx(book_name_xlsx, sheet_name_xlsx, value3) #读取数据 read_excel_xlsx(book_name_xlsx, sheet_name_xlsx)
4.封装-读写execl:
#!/usr/bin/env python # encoding: utf-8 __author__ = "晨晨" import xlrd from xlutils.copy import copy class OperationExcel: def __init__(self,file_name=None,sheet_id=None): if file_name: self.file_name = file_name self.sheet_id = sheet_id else: self.file_name = '../dataconfig/test.xls' self.sheet_id = 0 self.data = self.get_data() #获取sheets的内容 def get_data(self): data = xlrd.open_workbook(self.file_name) tables = data.sheets()[self.sheet_id] return tables #获取单元格的行数 def get_lines(self): tables = self.data return tables.nrows #获取某一个单元格的内容 def get_cell_value(self,row,col): return self.data.cell_value(row,col) #写入数据 def write_value(self,row,col,value): ''' 写入excel数据 row,col,value ''' read_data = xlrd.open_workbook(self.file_name) write_data = copy(read_data) sheet_data = write_data.get_sheet(0) sheet_data.write(row,col,value) write_data.save(self.file_name) #根据对应的caseid 找到对应行的内容 def get_rows_data(self,case_id): row_num = self.get_row_num(case_id) rows_data = self.get_row_values(row_num) return rows_data #根据对应的caseid找到对应的行号 def get_row_num(self,case_id): num = 0 clols_data = self.get_cols_data() for col_data in clols_data: if case_id in col_data: return num num = num+1 #根据行号,找到该行的内容 def get_row_values(self,row): tables = self.data row_data = tables.row_values(row) return row_data #获取某一列的内容 def get_cols_data(self,col_id=None): if col_id != None: cols = self.data.col_values(col_id) else: cols = self.data.col_values(0) return cols if __name__ == '__main__': opers = OperationExcel() print(opers.get_cell_value(1,2))#获取单元格的内容 print(opers.get_row_values(2))#获取某行的内容 print(opers.get_cols_data(2))#获取某列的内容 opers.write_value(3,2,'需要写入的数据')#指定单元格写入数据(单元格有数据则覆盖)
5.获取excel行与列:
#!/usr/bin/env python # -*- coding: utf-8 -*- import xlrd def excel_hang(): u''''读取excel所有行数据''' book = xlrd.open_workbook(r'D:\dalan\python\xuexi\dalan\xlsx格式测试工作簿.xlsx') sheet = book.sheet_by_index(0) rows = sheet.nrows#获取所有行 print (sheet.row_values(2))#打印指定行的值(打印第3行) print(sheet.col_values(2,0))#打印指定单元格(打印第3列所有行,0表示所有) print(sheet.col_values(2,2))#打印第3列从2行开始 case_list = [] for i in range(rows):#遍历所有行,并把行的数据传到case_list case_list.append(sheet.row_values(i)) print('每一行的数据:',sheet.row_values(i)) print('所有行的数据:',case_list) #return case_list #-------------读取指定列—————————————————— cols=sheet.col_values(1,0)#第二列第一条内容 print('指定某一列',cols) # ———————处理list中文乱码(针对2.7版本)———————————————————— # case_list_righ = str(case_list).replace('u\'','\'') # print case_list_righ.decode("unicode-escape") excel_hang()
6.单元格样式:
#!/usr/bin/env python # encoding: utf-8 from openpyxl import Workbook from openpyxl.styles import Font from openpyxl.styles import Alignment ###____________________________________________________________单元格样式______________________________________________________________________ def write_excel_xlsx(path, sheet_name, value): '''写数据''' # 自定义字体样式 font = Font( name="微软雅黑", # 字体 size=15, # 字体大小 color="0000FF", # 字体颜色,用16进制rgb表示 bold=True, # 是否加粗,True/False italic=True, # 是否斜体,True/False strike=None, # 是否使用删除线,True/False underline=None, # 下划线, 可选'singleAccounting', 'double', 'single', 'doubleAccounting' ) index = len(value) wb = Workbook() #工作簿的抽象 ws = wb.active # 获取worksheet对象 ws.title = sheet_name #单元格自定义样式 ws["B1"].font = font #设置B1的样式 ws["C2"].font = font #设置C2的样式 #指定列宽度 ws.column_dimensions['A'].width=20 #设置A列宽度为20 ws.column_dimensions['B'].width=30 #设置B列宽度为30 #指定行的高度 ws.row_dimensions[2].height = 60 # 设置第2行高度为60 #设置单元格字体对齐方式 ws['B2'].alignment=Alignment( horizontal='center', # 水平对齐,可选general、left、center、right、fill、justify、centerContinuous、distributed vertical='center', # 垂直对齐, 可选top、center、bottom、justify、distributed text_rotation=0, # 字体旋转,0~180整数 wrap_text=False, # 是否自动换行 shrink_to_fit=False, # 是否缩小字体填充 indent=0, # 缩进值 ) for i in range(0, index): for j in range(0, len(value[i])): ws.cell(row=i+1, column=j+1, value=str(value[i][j])) wb.save(path) print("xlsx格式表格写入数据成功!") #需要写入的数据 value3 = [["姓名", "性别", "年龄", "城市", "职业"], ["111", "女", "66", "石家庄", "运维工程师"], ["222", "男", "55", "南京", "饭店老板"], ["333", "女", "27", "苏州", "保安"],] book_name_xlsx = 'xlsx格式测试工作簿.xlsx' #给保存的文件取名字 sheet_name_xlsx = 'xlsx格式测试表' #定义Sheet1 if __name__ == "__main__": #写入数据 #write_excel_xlsx(book_name_xlsx, sheet_name_xlsx, value3) pass ###_______________________________________________单元格合并__________________________________________________________ # from openpyxl import load_workbook # # wb = load_workbook(filename = r'D:\dalan\python\xuexi\reports\test123.xlsx') #工作簿的抽象 # # # 获取所有的sheet名 # sheets = wb.sheetnames # # 读取第一个sheet表格 # ws = wb[sheets[0]] # # # 单元格合并 # ws.merge_cells("A2:A3") #____________________________________________________整个表格居中和样式_________________________________________________________ from openpyxl import Workbook from openpyxl.styles import Alignment from openpyxl.styles import Font def write_excel(value): index = len(value)#获取数据条数 wb = Workbook()#工作簿的抽象 # 获取所有的sheet名 sheets = wb.sheetnames print('sheets名字',sheets) # 读取第一个sheet表格 ws = wb[sheets[0]] #获取worksheet对象 ##重新命名sheet和创建sheet ws.title = '重命名sheet' wb.create_sheet('创建第二个sgheet',index=1) wb.create_sheet('创建第三个sgheet',index=3) #单元格样式居中 alignment_center = Alignment(horizontal='center', vertical='center') #单元格字体样式 font = Font( name="微软雅黑", size=15, bold=True) # 指定区域单元格居中 ws_area = ws["A1:E5"] for i in ws_area: for j in i: j.alignment = alignment_center; # 指定单元格字体样式 ws_area = ws["A1:E1"] for i in ws_area: for j in i: j.font = font; #写入数据 for i in range(0, index): for j in range(0, len(value[i])): ws.cell(row=i+1, column=j+1, value=str(value[i][j])) wb.save(r'D:\dalan\python\xuexi\reports\test123.xlsx')#保存数据 print("xlsx格式表格写入数据成功!") #需要写入的数据 value3 = [["姓名", "性别", "年龄", "城市", "职业"], ["111", "女", "66", "石家庄", "运维工程师"], ["222", "男", "55", "南京", "饭店老板"]] if __name__ == "__main__": #写入数据 write_excel(value3)
7.openpyxl读写
########################################################获取表格数据############################################################# import pandas as pd ####################按字典的方式获取(sheet_name可以去掉) df = pd.read_excel(r'C:\Users\PC\PycharmProjects\pythonProject\抖音_二年级_3条.xlsx', sheet_name='Sheet1',engine='openpyxl') # 将 DataFrame 转换为字典列表 data = df.to_dict(orient='records') print("获取表格全部数据:",data) # 打印每一行数据 for item in data: print(item) # #####################指定sheet读取数据 from openpyxl import load_workbook # 加载 .xlsx 文件 workbook = load_workbook(r'C:\Users\PC\PycharmProjects\pythonProject\抖音_二年级_3条.xlsx') # 选择工作表 sheet = workbook.sheetnames ws = workbook[sheet[0]] # 读取数据,从第2行开始,只读取第2列和第3列 for row in ws.iter_rows(min_row=2, min_col=2, max_col=3, values_only=True): print(row) ####################不指定sheet读取数据 from openpyxl import load_workbook # 加载 .xlsx 文件 workbook = load_workbook(r'C:\Users\PC\PycharmProjects\pythonProject\抖音_二年级_3条.xlsx') # 选择工作表 sheet = workbook.active # 读取数据,从第2行开始4行结束(min_row、max_row可以不填写) for row in sheet.iter_rows(min_row=2,max_row=4, values_only=True): print(row) ################################################################写入表格######################################################## #############################list写入表格 from openpyxl import Workbook # 创建一个新的工作簿 wb = Workbook() # 获取当前活动的工作表 ws = wb.active # 数据列表(list和元组都行) name_list = [ ['时间', '包名', '设备名称', 'FPS', '设备电量', '设备温温度℃', '上行流量KB', '下行流量KB', '设备可用内存MB','包占用内存MB'], ['08_10 15:29:55', 'com.dl.wssgl', 'HUAWEIMHA-AL00', 0.0, 49, 42.0, 1581279.9, 36583.2, 1358.04, 767.477], ['08_10 15:29:57', 'com.dl.wssgl', 'HUAWEIMHA-AL00', 0.0, 49, 42.0, 1581279.9, 36583.2, 1362.632, 764.021] ] # 将数据写入工作表 for row_data in name_list: ws.append(row_data) # 每个元组作为一行写入 # 保存工作簿到文件 wb.save("data.xlsx") print("数据已成功写入 data.xlsx 文件中!") ###########################字典写入表格 from openpyxl import Workbook # 创建一个新的工作簿 wb = Workbook() # 获取当前活动的工作表 ws = wb.active # 数据列表 data_list = [ {'时间': '08_10 15:29:55', '包名': 'com.dl.wssgl', '设备名称': 'HUAWEIMHA-AL00', 'FPS': 0.0, '设备电量': 49, '设备温温度℃': 42.0, '上行流量KB': 1581279.9}, {'时间': '08_10 15:29:57', '包名': 'com.dl.wssgl', '设备名称': 'HUAWEIMHA-AL00', 'FPS': 0.0, '设备电量': 49, '设备温温度℃': 42.0, '上行流量KB': 1581279.9} ] # 获取所有列名(假设所有字典的键都相同) columns = list(data_list[0].keys()) # 写入表头 ws.append(columns) # 写入数据 for row_data in data_list: ws.append([row_data[col] for col in columns]) # 保存工作簿到文件 wb.save("data11111.xlsx") print("数据已成功写入 data11111.xlsx 文件中!")
########################################### 3.json和execl转换 ################################################################
1.json数据写入execl:
请确保在运行代码之前安装了 pandas 库。你可以使用以下命令通过 pip 安装:pip install pandas
#!/usr/bin/env python3 #coding: utf-8 __author__ = "love" import pandas as pd import json # JSON 数据 json_data = { "code": 0, "data": { "total_count": 0, "details": [] }, "message": "OK", "request_id": "EMSAgIDQg42vChiuBCDaq637pjEoqNemhgU=" } # 将 JSON 数据转换为 DataFrame df = pd.json_normalize(json_data) # 将 DataFrame 写入 Excel 文件 df.to_excel('data.xlsx', index=False)
2.execl数据写入json文件(需要处理格式):
#!/usr/bin/env python3 #coding: utf-8 __author__ = "love" import pandas as pd import json # 读取 Excel 文件 df = pd.read_excel('data.xlsx') # 将 DataFrame 转换为 JSON json_data = df.to_json(orient='records') # 打印 JSON 数据 print(json_data) # 将 JSON 数据写入文件 with open('data.json', 'w') as file: file.write(json_data)
3.读取execl数据写入json文件,处理格式(依赖于json数据写入execl):
#!/usr/bin/env python3 #coding: utf-8 __author__ = "love" import pandas as pd import json # 读取 Excel 文件 df = pd.read_excel('data.xlsx') # 将 DataFrame 转换为 JSON json_data = df.to_json(orient='records') # 打印 JSON 数据(如果有多行需要遍历),,转成字典 data=eval(json_data)[0] # 构建新的 JSON 对象 new_data = { "code": data["code"], "message": data["message"], "request_id": data["request_id"], "data": { "total_count": data["data.total_count"], "details": data["data.details"] } } # 将新的 JSON 对象转换为 JSON 字符串 new_json_string = json.dumps(new_data) # 打印新的 JSON 字符串 print(new_json_string) # 将 JSON 数据写入文件 with open('data.json', 'w') as file: file.write(new_json_string)#把new_json_string写入data.json
############################################### 4.文件通用处理 ###########################################################
1.获取文件大小并转换单位:
#!/usr/bin/env python # -*- coding: utf-8 -* import os def size_format(path): size=os.path.getsize(path)#获取文件字节 if size < 1000: return '%i' % size + 'size' elif 1000 <= size < 1000000: return '%.1f' % float(size/1000) + 'KB' elif 1000000 <= size < 1000000000: return '%.1f' % float(size/1000000) + 'MB' elif 1000000000 <= size < 1000000000000: return '%.1f' % float(size/1000000000) + 'GB' elif 1000000000000 <= size: return '%.1f' % float(size/1000000000000) + 'TB' print(size_format(r'C:\Users\Administrator\Desktop\大蓝\工作\apk\母包\mubao.apk'))
2.linux定时检查文件是否新增并提取增量数据:
#!/usr/bing/env python # -*- coding: utf-8 -*- import os import threading #总行数 count=os.popen('grep "Tunnel established at" nohup.out').readlines() count_1=len(count) #每次扫描行数 def every_time(): a=os.popen('grep "Tunnel established at" nohup.out').readlines() return len(a) #当有新增时获取最后一行 def every_tail(): a=os.popen('grep "Tunnel established at" nohup.out|tail -n 1').readline() b=a.rstrip()[-28:]+'/jenkins' c=b.lstrip() return c def python_timer(): print("start" ) global count_1 print(count_1)#初始行数 every_count=every_time() print(every_count)#每次扫描 if count_1 < every_count: count_1=every_count url=every_tail() print(url) ########这里可以把更新的内容发送邮件 timer = threading.Timer(300,python_timer) timer.start() if __name__ == "__main__": python_timer()
3.获取文件增量数据:
#!/usr/bin/env python # encoding: utf-8 import time def one_file(path): '''首次打开文件,主要获取文件结尾位置''' fd=open("o4444.txt",'r') #获得一个句柄 aa=fd.read() #print('文件全部内容:',aa) label=fd.tell() #记录读取到的位置 print('记录文件末尾位置:',label) return label fd.close() def two_file(path,tail_label): '''再次阅读文件-获取增量部分''' fd=open(path,'r') #获得一个句柄 fd.seek(tail_label,0)# 把文件读取指针移动到之前记录的位置 bb=fd.read() #接着上次的位置继续向下读取 print('获取文件增量部分:',bb) fd.close() if __name__=='__main__': ##首次调文件-获取结尾位置 tail_label=one_file(r'D:\dalan\python\xuexi\dalan\o4444.txt') ##等待、追加内容到文件 time.sleep(10) ##获取文件增量数据 two_file(r'D:\dalan\python\xuexi\dalan\o4444.txt',tail_label) #___________________________________实时查看文件增量数据________________________________________________ def real_time_file(path): '''实时查看文件增量数据''' with open(path, 'r') as f: while True: a=f.read()#读取文件 #print('文件内容为:',a) label2=f.tell() #记录读取到的位置 print('文件末尾的位置',label2) time.sleep(2)#每两秒轮循一次 f.seek(label2)# 把文件读取指针移动到之前记录的位置 bb=f.read() #接着上次的位置继续向下读取 print('实时增量数据为:{}'.format(bb)) if __name__=='__main__': real_time_file(r'D:\dalan\python\xuexi\dalan\o4444.txt') #________________________________________文件增量获取及指定字符串读取_______________________________________________ class cd_file(object): def __init__(self,path): self.path=path def file(self): fd=open(self.path,'r') #获得一个句柄 a=len(fd.readlines()) fd.close() #关闭文件 return a def write(self): with open(self.path,mode="a+",encoding="UTF-8",errors="ignore") as abc: abc.write('\n') abc.write('11111111111111111\n') abc.write('22222222222222222\n') def zai_read(self,label): #再次阅读文件 reprt='' fd=open(self.path,'r') for line in fd.readlines()[label:]: #if line not in'\n': #过滤换行 reprt+=line return reprt def log_re(self,name): '''获取文件中 指定字符串后的内容''' shuju=[] with open(self.path,mode="r",encoding="gbk",errors="ignore") as abc: fileContent=abc.readlines() for i in range(len(fileContent)): #判断是否包含444444444444444444444的字符串 if name in fileContent[i]: shuju.append(fileContent[i]) for a in range(len(fileContent)): if shuju[len(shuju)-1] in fileContent[a]: #return '\n'.join(fileContent[a:]) #换行切割 return ''.join(fileContent[a+1:])#直接返回 if __name__ == '__main__': #获取文件指定字符串后的数据 read=cd_file(r'./chenwei.log') #在文件中指定字符串,获取字符串后的数据 print('在文件中获取指定字符串之后的内容:\n',read.log_re('444444444444444444444')) #获取文件增量数据 read=cd_file(r'./chen.log') weizhi=read.file()#获取执行前文件句柄 print('执行前文件位置:',weizhi) read.write()#写入数据到文件 print('从执行前位置往下读取,获取增量部分:\n',read.zai_read(weizhi))
4.文件处理:
#!/usr/bin/env python3 #coding: utf-8 import requests import os import time from urllib import request #________________________判断url是否可用_________________________________________ try: with request.urlopen("http://chenwei.com") as file: print(file.status) print(file.reason) print(file.geturl()) except Exception as e: print(e) #_______________________________在5秒内判断url是否可用____________________________ url = 'http://chenwei.com' print(time.strftime('%Y-%m-%d %H:%M:%S')) try: html = requests.get(url, timeout=5) print('打印响应内容',html.read()) print('返回url',html.url) print('success') except requests.exceptions.RequestException as e: print('已经超时了') print(e) print(time.strftime('%Y-%m-%d %H:%M:%S')) #__________________________通过url判断文件大小___________________________________ def size_file(url): '''获取url文件的大小-不下载''' r=requests.get(url) file_size_str=r.headers['Content-Length'] #提取出来的是个数字str file_size=int(file_size_str)/1024/1024 #把提取出数字str转为int或者float进行运算 size=round(file_size,2)#保留小数后2位 print(size,'M') #____________________下载文件显示进度条&下载时间&平均下载速度_____________________ def progressbar(url,path): if not os.path.exists(path): # 看是否有该文件夹,没有则创建文件夹 os.mkdir(path) start = time.time() #下载开始时间 response = requests.get(url, stream=True) #stream=True必须写上 size = 0 #初始化已下载大小 chunk_size = 1024 # 每次下载的数据大小 content_size = int(response.headers['content-length']) # 下载文件总大小 try: if response.status_code == 200: #判断是否响应成功 file_size=round((content_size / chunk_size /1024),2)#文件大小 print('文件大小为:{size:.2f} MB'.format(size = content_size / chunk_size /1024)) #开始下载,显示下载文件大小 filepath = path+'\123.apk' #设置图片name,注:必须加上扩展名 with open(filepath,'wb') as file: #显示进度条 for data in response.iter_content(chunk_size = chunk_size): file.write(data) size +=len(data) #print('\r'+'[下载进度]:%s%.2f%%' % ('>'*int(size*50/ content_size), float(size / content_size * 100)) ,end=' ')#显示进度条 end = time.time() #下载结束时间 print('下载所用时间: %.2f秒' % (end - start)) #输出下载用时时间 print('平均下载速度:{}M/s'.format(round (file_size/(end-start)),2)) except: print('文件下载异常') progressbar('https://pkg.wbdd2018.com/game/lmhxclhxtt_ad/apk_sem/bd_lmhxclhxtt_ad_1883_2507.apk',r'C:\Users\Administrator\Desktop\chenwei')#url,存储路径
5.csv文件读写:
#!/usr/bin/env python # -*- coding: utf-8 -*- import csv """ csv文件和txt文件操作方法都一样可以通用 """ # ___________________________________________________________________________________________________________csv文件写入__________________________________________________________________________________________________ # 二维数组(list) name_list = [( '时间', '包名', '设备名称', 'FPS', '设备电量', '设备温温度℃', '上行流量KB', '下行流量KB', '设备可用内存MB', '包占用内存MB', '设备可用CPU', '包占用CPU'), ( '08_10 15:29:55', 'com.dl.wssgl', 'HUAWEIMHA-AL00', 0.0, 49, 42.0, 1581279.9, 36583.2, 1358.04, 767.477, '73.5%', '16.125%'), ( '08_10 15:29:57', 'com.dl.wssgl', 'HUAWEIMHA-AL00', 0.0, 49, 42.0, 1581279.9, 36583.2, 1362.632, 764.021, '70.62%', '16.875%')] # 一维数组(list) list = ['2086', '2085', '2084', '2083', '2082', '2081', '2080', '2079', '2078', '2077', '2076', '2075', '2074', '2073', '2072', '2071', '2070', '2069', '2068', '2067'] def write_file_a(data): '''二维数组写入,按行显示嵌套列表''' csv_file = open('test123456.csv', 'w', newline='') with csv_file: writer = csv.writer(csv_file) # 遍历获取嵌套的列表 for row in data: writer.writerow(row) def write_file_b(data): '''二维数组写入,按列显示嵌套列表''' ###所有嵌套列表写入一列 with open(r'C:\Users\chenwei3\Desktop\所有嵌套列表写入一列.csv', 'w', newline='', encoding='utf-8') as csvfile: writer = csv.writer(csvfile) for year in data: writer.writerow([year]) ###每个嵌套列表分列显示 with open('每个嵌套列表分列显示.csv', 'w', newline='') as file: writer = csv.writer(file) # 写入每一列数据(需要先定义下标) writer.writerow([name_list[0], [name_list[1]], [name_list[2]]]) def write_file_c(data): '''一维数组(list)写入csv''' import csv # 以列的方式写入 with open(r'C:\Users\chenwei3\Desktop\以列的方式写入.csv', 'w', newline='') as csvfile: writer = csv.writer(csvfile) for year in data: writer.writerow([year]) # 以行的方式写入(可以直接把csv文件改成txt) with open(r'C:\Users\chenwei3\Desktop\以行的方式写入.csv', 'w', newline='') as csvfile: #with open(r'C:\Users\chenwei3\Desktop\以行的方式写入.txt', 'w', newline='') as csvfile: writer = csv.writer(csvfile) writer.writerow(data) # write_file_a(name_list)#二维数组按行写入 # write_file_b(name_list)#二维数组按列写入 # write_file_c(list)#一维数组写入 # ________________________________________________________________________________________________________csv文件读取_____________________________________________________________________________________________________________ def read_file_a(): '''读取文件: 按list读取每一行''' # 可以通过encoding指定编码 with open('./test123456.csv') as f: for row in csv.reader(f, skipinitialspace=True): print(row) def read_file_b(): '''读取文件: 使用字典方式读取''' import codecs with codecs.open(r'C:\Users\chenwei3\Desktop/test123456.csv') as f: for row in csv.DictReader(f, skipinitialspace=True): print(row) def read_file_c(): '''读取文件: 指定方式读取''' import pandas as pd df = pd.read_csv("filename.csv") print("读取所有数据:\n",df) # 获取某一行的值 print(df.iloc[1]) # 获取某一列的值 print(df["item_id"]) # 列名是item_id的列 # 获取某一行某一列的值 print(df.iloc[1]["item_id"]) print(df.iloc[1,5])#读取第一行第5列的值 ###全部读取 # read_file_a()#读取方式一:按list读取 # read_file_b()#读取方式二:按字典方式读取 ###指定读取 read_file_c()
################################################# 5.文件下载 #################################################################
1.常规文件下载:
#! /usr/bin/env python # -*- coding:utf-8 -*- import os import gevent import asyncio import aiohttp import urllib.request from gevent import monkey ####_______________________________单个文件下载_________________________________________________________________________________________ ####image_url = 'http://img.jingtuitui.com/759fa20190115144450401.jpg' image_url='https://ss0.bdstatic.com/70cFuHSh_Q1YnxGkpoWK1HF6hhy/it/u=2340497325,2166644129&fm=26&gp=0.jpg' file_path = r'C:/Users/Administrator/Desktop/' try: if not os.path.exists(file_path): os.makedirs(file_path) #如果没有这个path则直接创建 file_suffix = os.path.splitext(image_url)[1] print(file_suffix) filename = '{}test{}'.format(file_path, file_suffix) print(filename) urllib.request.urlretrieve(image_url, filename=filename) print('图片下载成功') except IOError as e: print('磁盘读写操作错误', e) except Exception as e: print('下载异常非磁盘io错误', e) ####__________________________________________________多文件下载__________________________________________________________________________ def img_download(image_url,file_path): for i in image_url: if not os.path.exists(file_path): os.makedirs(file_path) #如果没有这个path则直接创建 #分离文件路径和后缀名 file_suffix = os.path.splitext(i)[1] print(file_suffix) filename = '{}{}{}'.format(file_path,i[-15:], file_suffix) print(filename) urllib.request.urlretrieve(i, filename=filename) print('图片下载成功') print('全部下载完毕') if __name__ == "__main__": #可以用淘宝、京东图片 image_url=['https://ss0.bdstatic.com/70cFuHSh_Q1YnxGkpoWK1HF6hhy/it/u=2340497325,2166644129&fm=26&gp=0.jpg','http://img.jingtuitui.com/759fa20190115144450401.jpg','https://img.alicdn.com/imgextra/i3/827894246/O1CN01elaeCK1hEiIV640YT_!!0-item_pic.jpg_430x430q90.jpg'] file_path = r'C:/Users/Administrator/Desktop/' img_download(image_url,file_path) ####______________________________________________异步-使用协程下载图片(第三方 gevent)________________________________________________________________________ monkey.patch_all() def download(name, url): file_path= r'C:/Users/Administrator/Desktop/' obj = urllib.request.urlopen(url)#请求url content = obj.read()#读取文件对象 #打开并写入 with open(file_path+name, "wb") as f: f.write(content) # 读取图片到1.jpg def main(): # 等待所有的协程开始运行结束 gevent.joinall( [ gevent.spawn(download, "1.jpg", "https://ss0.bdstatic.com/70cFuHSh_Q1YnxGkpoWK1HF6hhy/it/u=2340497325,2166644129&fm=26&gp=0.jpg"), gevent.spawn(download, "2.jpg", "http://img.jingtuitui.com/759fa20190115144450401.jpg"), gevent.spawn(download, "3.jpg", "https://img.alicdn.com/imgextra/i3/827894246/O1CN01elaeCK1hEiIV640YT_!!0-item_pic.jpg_430x430q90.jpg") ] ) if __name__ == "__main__": main() #______________________________________________________async异步下载文件________________________________________________________________ async def handler(url, file_path): headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:68.0) Gecko/20100101 Firefox/68.0" } async with aiohttp.ClientSession() as session: r = await session.get(url=url, headers=headers) with open(file_path, "wb") as f: f.write(await r.read()) f.flush() os.fsync(f.fileno()) loop = asyncio.get_event_loop() loop.run_until_complete(handler(url, file_path)) #___________________________________________下载文件_______________________________________________________________________________________ import os import requests def img_down(url): filename = os.path.basename(url)#获取文件名 r = requests.get(url) with open(filename, "wb") as code: code.write(r.content) img_down('http://img.jingtuitui.com/759fa20190115144450401.jpg')
#!/usr/bin/env python # -*- coding: utf-8 -*- #############################################多文件异步下载############################################ import time import aiohttp import asyncio import os async def download_file(session, url, save_path): try: async with session.get(url) as response: if response.status == 200: file_name = os.path.basename(url) file_name_time=str(time.time_ns())+".mp4" #自定文件名称 file_path = os.path.join(save_path, file_name_time)#这里可以替换 with open(file_path, 'wb') as f: while True: chunk = await response.content.read(1024) if not chunk: break f.write(chunk) print(f"文件 {file_name} 下载完成,保存路径为 {file_path}") else: print(f"下载失败,状态码:{response.status}") except Exception as e: print(f"下载文件 {url} 时发生错误:{e}") async def download_files(urls, save_path): async with aiohttp.ClientSession() as session: tasks = [download_file(session, url, save_path) for url in urls] await asyncio.gather(*tasks) if __name__ == "__main__": save_path = "downloaded_files" #保存的目录 if not os.path.exists(save_path): os.makedirs(save_path) urls = [ 'https://agent-circle-public-1257687450.cos.ap-beijing.myqcloud.com/145518/mba1em9eaq86ijmysk9dfbou1e5ief0b.mp4', 'https://agent-circle-public-1257687450.cos.ap-beijing.myqcloud.com/145518/nyuf5t5bga98lhpqnk5ial70k0ecb6sn.mp4', 'https://agent-circle-public-1257687450.cos.ap-beijing.myqcloud.com/145518/qw5as9p0k23fgs8b8zyp1rtg1zrqv85y.mp4', ] # 确保在 Windows 上使用正确的事件循环 if os.name == 'nt': asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy()) asyncio.run(download_files(urls, save_path))
########################################## 6.配置文件 #############################################################
1.python配置文件读取:
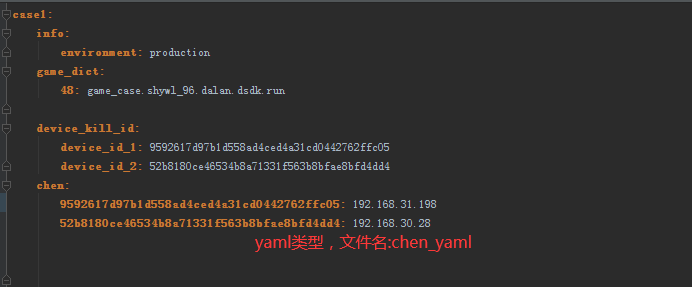
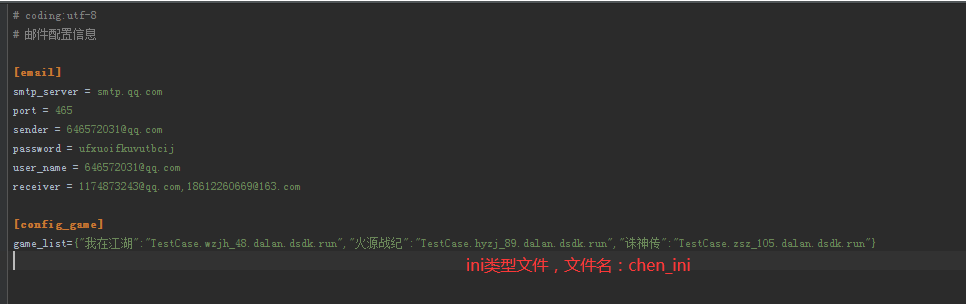
#!/usr/bin/env python # encoding: utf-8 __author__ = "晨晨" import yaml import configparser #___________________________________获取ini文件__________________________________________________________ configPath ='../chen_ini.ini'#在不同路径调用,需要修改不同路径 conf = configparser.ConfigParser() conf.read(configPath) #获取数据 smtp_server = conf.get("email", "smtp_server") port = conf.get("email", "port") sender = conf.get("email", "sender") password = conf.get("email", "password") user_name = conf.get("email", "user_name") receiver = conf.get("email", "receiver") game_dict = conf.get("config_game", "game_list") # # print(smtp_server) # print(port) # print(sender) # print(user_name) #print(receiver) #_________________________________获取yaml配置文件内容______________________________________________________ def get_config(): '''获取设备uid对应的ip''' with open('../chen_yaml.yaml', encoding='utf-8') as file: data = yaml.safe_load(file) #print('所有数据:',data) return (data['case1']['chen']) def game(): '''获取游戏资源''' with open('../chen_yaml.yaml', encoding='utf-8') as file: data = yaml.safe_load(file) return (data['case1']['game_dict']) def using_huanj(): '''获取配置文件中环境''' with open('../chen_yaml.yaml', encoding='utf-8') as file: data = yaml.safe_load(file) return (data['case1']['info']['environment']) def device_id_kill(): '''获取需要kill的设备id''' with open('../chen_yaml.yaml', encoding='utf-8') as file: data = yaml.safe_load(file) return data['case1']['device_kill_id'] if __name__=='__main__': print(get_config().keys()) print(game()) #print(device_id_kill()['device_id_2']) #print(using_huanj())
################################################## 7.进度条 ##############################################################
1.使用tqdm模块实现多线程进度条
#!/usr/bin/env python #coding: utf-8 from tqdm import tqdm from time import sleep from threading import Thread def jindu(mun): for i in tqdm(range(mun)): sleep(1) #print('业务代码') tasks = [1,2] threads = [] for task in tasks: t = Thread(target=jindu(task)) t.start() threads.append(t) for t in threads: t.join()
################################################## 8.xml文件读写 ##############################################################
下面代码案例,可以保存到文件如.xml 或者jmeter的脚本文件.jmx文件:
<jmeterTestPlan version="1.2" properties="5.0" jmeter="5.6.2"> <hashTree> <TestPlan guiclass="TestPlanGui" testclass="TestPlan" testname="测试计划" enabled="true"> <boolProp name="TestPlan.functional_mode">false</boolProp> <boolProp name="TestPlan.tearDown_on_shutdown">false</boolProp> <boolProp name="TestPlan.serialize_threadgroups">false</boolProp> <elementProp name="TestPlan.user_defined_variables" elementType="Arguments" guiclass="ArgumentsPanel" testclass="Arguments" testname="用户定义的变量" enabled="true"> <collectionProp name="Arguments.arguments" /> </elementProp> </TestPlan> <hashTree> <CSVDataSet guiclass="TestBeanGUI" testclass="CSVDataSet" testname="全局参数化" enabled="true"> <stringProp name="delimiter">,</stringProp> <stringProp name="fileEncoding">UTF-8</stringProp> <stringProp name="filename">C:\Users\chenwei3\Desktop\BND\AIGC性能测试\AIGC性能测试脚本\testparameter.csv</stringProp> <boolProp name="ignoreFirstLine">true</boolProp> <boolProp name="quotedData">false</boolProp> <boolProp name="recycle">true</boolProp> <stringProp name="shareMode">shareMode.all</stringProp> <boolProp name="stopThread">false</boolProp> <stringProp name="variableNames">pet_fileurl,pet_fileid,pet_type,petfile_type,pet_search,pet_agentappid,pet_skillid</stringProp> </CSVDataSet> <hashTree /> <ThreadGroup guiclass="ThreadGroupGui" testclass="ThreadGroup" testname="业务集成测试" enabled="true"> <stringProp name="ThreadGroup.on_sample_error">continue</stringProp> <elementProp name="ThreadGroup.main_controller" elementType="LoopController" guiclass="LoopControlPanel" testclass="LoopController" testname="循环控制器" enabled="true"> <stringProp name="LoopController.loops">${__P(cycles,1)}</stringProp> <boolProp name="LoopController.continue_forever">false</boolProp> </elementProp> <stringProp name="ThreadGroup.num_threads">${__P(concurrent_number,1)}</stringProp> <stringProp name="ThreadGroup.ramp_time">1</stringProp> <boolProp name="ThreadGroup.delayedStart">false</boolProp> <boolProp name="ThreadGroup.scheduler">false</boolProp> <stringProp name="ThreadGroup.duration" /> <stringProp name="ThreadGroup.delay" /> <boolProp name="ThreadGroup.same_user_on_next_iteration">true</boolProp> </ThreadGroup> <hashTree> <CounterConfig guiclass="CounterConfigGui" testclass="CounterConfig" testname="计数器" enabled="true"> <stringProp name="CounterConfig.start">1</stringProp> <stringProp name="CounterConfig.end">20000</stringProp> <stringProp name="CounterConfig.incr">1</stringProp> <stringProp name="CounterConfig.name">counts</stringProp> <stringProp name="CounterConfig.format" /> <boolProp name="CounterConfig.per_user">false</boolProp> </CounterConfig> <hashTree /> <IfController guiclass="IfControllerPanel" testclass="IfController" testname="助理初始化" enabled="false"> <boolProp name="IfController.evaluateAll">false</boolProp> <boolProp name="IfController.useExpression">true</boolProp> <stringProp name="IfController.condition">${__jexl3(${counts}==1,)}</stringProp> </IfController> <hashTree> <HTTPSamplerProxy guiclass="HttpTestSampleGui" testclass="HTTPSamplerProxy" testname="初始化创建知识集" enabled="true"> <boolProp name="HTTPSampler.postBodyRaw">false</boolProp> <elementProp name="HTTPsampler.Arguments" elementType="Arguments" guiclass="HTTPArgumentsPanel" testclass="Arguments" enabled="true"> <collectionProp name="Arguments.arguments"> <elementProp name="" elementType="HTTPArgument"> <boolProp name="HTTPArgument.always_encode">false</boolProp> <stringProp name="Argument.value">{"title":"性能测试库自动创建${__time(yyyy-MM-dd HH:mm:ss,)}","description":"性能测试用的${__time(yyyy-MM-dd HH:mm:ss,)}"} </stringProp> <stringProp name="Argument.metadata">=</stringProp> <boolProp name="HTTPArgument.use_equals">true</boolProp> </elementProp> </collectionProp> </elementProp> <stringProp name="HTTPSampler.domain">pet-saas-aigc.bndxqc.com</stringProp> <stringProp name="HTTPSampler.protocol">https</stringProp> <stringProp name="HTTPSampler.path">/thinker/api/v1/knowledge/set/create</stringProp> <stringProp name="HTTPSampler.method">POST</stringProp> <boolProp name="HTTPSampler.follow_redirects">true</boolProp> <boolProp name="HTTPSampler.auto_redirects">false</boolProp> <boolProp name="HTTPSampler.use_keepalive">true</boolProp> <boolProp name="HTTPSampler.DO_MULTIPART_POST">false</boolProp> <boolProp name="HTTPSampler.BROWSER_COMPATIBLE_MULTIPART">false</boolProp> <boolProp name="HTTPSampler.image_parser">false</boolProp> <boolProp name="HTTPSampler.concurrentDwn">false</boolProp> <stringProp name="HTTPSampler.concurrentPool">6</stringProp> <boolProp name="HTTPSampler.md5">false</boolProp> <intProp name="HTTPSampler.ipSourceType">0</intProp> <stringProp name="HTTPSampler.implementation">HttpClient4</stringProp> <stringProp name="TestPlan.comments">Created from cURL on 2023-11-23T15:09:01.2773184</stringProp> </HTTPSamplerProxy> <hashTree /> <HTTPSamplerProxy guiclass="HttpTestSampleGui" testclass="HTTPSamplerProxy" testname="初始化创建助理" enabled="true"> <boolProp name="HTTPSampler.postBodyRaw">true</boolProp> <elementProp name="HTTPsampler.Arguments" elementType="Arguments"> <collectionProp name="Arguments.arguments"> <elementProp name="" elementType="HTTPArgument"> <boolProp name="HTTPArgument.always_encode">false</boolProp> <stringProp name="Argument.value">{ "name":"test001", "chen":"你好" } </stringProp> <stringProp name="Argument.metadata">=</stringProp> </elementProp> </collectionProp> </elementProp> <stringProp name="HTTPSampler.domain">pet-saas-aigc.bndxqc.com</stringProp> <stringProp name="HTTPSampler.protocol">https</stringProp> <stringProp name="HTTPSampler.path">/thinker/api/v1/app/create</stringProp> <stringProp name="HTTPSampler.method">POST</stringProp> <boolProp name="HTTPSampler.follow_redirects">true</boolProp> <boolProp name="HTTPSampler.auto_redirects">false</boolProp> <boolProp name="HTTPSampler.use_keepalive">true</boolProp> <boolProp name="HTTPSampler.DO_MULTIPART_POST">false</boolProp> <boolProp name="HTTPSampler.BROWSER_COMPATIBLE_MULTIPART">false</boolProp> <boolProp name="HTTPSampler.image_parser">false</boolProp> <boolProp name="HTTPSampler.concurrentDwn">false</boolProp> <stringProp name="HTTPSampler.concurrentPool">6</stringProp> <boolProp name="HTTPSampler.md5">false</boolProp> <intProp name="HTTPSampler.ipSourceType">0</intProp> <stringProp name="HTTPSampler.implementation">HttpClient4</stringProp> <stringProp name="TestPlan.comments">Created from cURL on 2023-11-23T15:09:01.2773184</stringProp> </HTTPSamplerProxy> <hashTree> <HeaderManager guiclass="HeaderPanel" testclass="HeaderManager" testname="重写请求头管理器" enabled="false"> <collectionProp name="HeaderManager.headers"> <elementProp name="" elementType="Header"> <stringProp name="Header.name">X-Agent-Appid</stringProp> <stringProp name="Header.value">${__property(set_agent_appid)}</stringProp> </elementProp> <elementProp name="" elementType="Header"> <stringProp name="Header.name">Auth-Token</stringProp> <stringProp name="Header.value">${Auth-Token}</stringProp> </elementProp> <elementProp name="" elementType="Header"> <stringProp name="Header.name">content-type</stringProp> <stringProp name="Header.value">application/json</stringProp> </elementProp> <elementProp name="" elementType="Header"> <stringProp name="Header.name">authorization</stringProp> <stringProp name="Header.value">${authorization}</stringProp> </elementProp> <elementProp name="" elementType="Header"> <stringProp name="Header.name">ts</stringProp> <stringProp name="Header.value">${ts}</stringProp> </elementProp> </collectionProp> </HeaderManager> <hashTree /> </hashTree> </hashTree> <HTTPSamplerProxy guiclass="HttpTestSampleGui" testclass="HTTPSamplerProxy" testname="AI助理—基础信息" enabled="false"> <boolProp name="HTTPSampler.postBodyRaw">true</boolProp> <elementProp name="HTTPsampler.Arguments" elementType="Arguments"> <collectionProp name="Arguments.arguments"> <elementProp name="" elementType="HTTPArgument"> <boolProp name="HTTPArgument.always_encode">false</boolProp> <stringProp name="Argument.value">{ "agent_appid":"${__P(agent_uid)}" }</stringProp> <stringProp name="Argument.metadata">=</stringProp> </elementProp> </collectionProp> </elementProp> <stringProp name="HTTPSampler.domain">pet-saas-aigc.bndxqc.com</stringProp> <stringProp name="HTTPSampler.protocol">https</stringProp> <stringProp name="HTTPSampler.path">/thinker/api/v1/app/detail</stringProp> <stringProp name="HTTPSampler.method">POST</stringProp> <boolProp name="HTTPSampler.follow_redirects">true</boolProp> <boolProp name="HTTPSampler.auto_redirects">false</boolProp> <boolProp name="HTTPSampler.use_keepalive">true</boolProp> <boolProp name="HTTPSampler.DO_MULTIPART_POST">false</boolProp> <boolProp name="HTTPSampler.BROWSER_COMPATIBLE_MULTIPART">false</boolProp> <boolProp name="HTTPSampler.image_parser">false</boolProp> <boolProp name="HTTPSampler.concurrentDwn">false</boolProp> <stringProp name="HTTPSampler.concurrentPool">6</stringProp> <boolProp name="HTTPSampler.md5">false</boolProp> <intProp name="HTTPSampler.ipSourceType">0</intProp> <stringProp name="HTTPSampler.implementation">HttpClient4</stringProp> <stringProp name="TestPlan.comments">Created from cURL on 2024-01-17T18:23:32.210093</stringProp> </HTTPSamplerProxy> <hashTree /> <HTTPSamplerProxy guiclass="HttpTestSampleGui" testclass="HTTPSamplerProxy" testname="AI助理—更新基础规则" enabled="false"> <boolProp name="HTTPSampler.postBodyRaw">true</boolProp> <elementProp name="HTTPsampler.Arguments" elementType="Arguments"> <collectionProp name="Arguments.arguments"> <elementProp name="" elementType="HTTPArgument"> <boolProp name="HTTPArgument.always_encode">false</boolProp> <stringProp name="Argument.value">{ "model_settings":{ "temperature":0.3, "max_reply_tokens":6000, "model_type":"gpt-3.5-turbo-16k", "model":"ChatOpenAI", "model_max_tokens":16000, "model_config":null }, "prologue":"你好,我是你的AIGC自定义助理,有什么我能帮到你的?", "no_match_reply":"" }</stringProp> <stringProp name="Argument.metadata">=</stringProp> </elementProp> </collectionProp> </elementProp> <stringProp name="HTTPSampler.domain">pet-saas-aigc.bndxqc.com</stringProp> <stringProp name="HTTPSampler.protocol">https</stringProp> <stringProp name="HTTPSampler.path">/thinker/api/v1/app/update</stringProp> <stringProp name="HTTPSampler.method">POST</stringProp> <boolProp name="HTTPSampler.follow_redirects">true</boolProp> <boolProp name="HTTPSampler.auto_redirects">false</boolProp> <boolProp name="HTTPSampler.use_keepalive">true</boolProp> <boolProp name="HTTPSampler.DO_MULTIPART_POST">false</boolProp> <boolProp name="HTTPSampler.BROWSER_COMPATIBLE_MULTIPART">false</boolProp> <boolProp name="HTTPSampler.image_parser">false</boolProp> <boolProp name="HTTPSampler.concurrentDwn">false</boolProp> <stringProp name="HTTPSampler.concurrentPool">6</stringProp> <boolProp name="HTTPSampler.md5">false</boolProp> <intProp name="HTTPSampler.ipSourceType">0</intProp> <stringProp name="HTTPSampler.implementation">HttpClient4</stringProp> <stringProp name="TestPlan.comments">Created from cURL on 2024-01-18T09:39:51.0131945</stringProp> </HTTPSamplerProxy> <hashTree /> <HTTPSamplerProxy guiclass="HttpTestSampleGui" testclass="HTTPSamplerProxy" testname="AI助理—设置高级技能" enabled="true"> <boolProp name="HTTPSampler.postBodyRaw">true</boolProp> <elementProp name="HTTPsampler.Arguments" elementType="Arguments"> <collectionProp name="Arguments.arguments"> <elementProp name="" elementType="HTTPArgument"> <boolProp name="HTTPArgument.always_encode">false</boolProp> <stringProp name="Argument.value">{ "name":"妙语技能${__time}", "agent_appid":"${__P(agent_uid)}", "hint_message":"", "description":"通过技能来帮助用户解决问题", "data_source":"dialogue", "prompt_combo_type":"app", "status":"off", "id":"${__P(skill_id)}", "variable":[ { "key":"name", "value":"博纳德", "optional":true } ] }</stringProp> <stringProp name="Argument.metadata">=</stringProp> </elementProp> </collectionProp> </elementProp> <stringProp name="HTTPSampler.domain">pet-saas-aigc.bndxqc.com</stringProp> <stringProp name="HTTPSampler.protocol">https</stringProp> <stringProp name="HTTPSampler.path">/thinker/api/v1/skill/update</stringProp> <stringProp name="HTTPSampler.method">POST</stringProp> <boolProp name="HTTPSampler.follow_redirects">true</boolProp> <boolProp name="HTTPSampler.auto_redirects">false</boolProp> <boolProp name="HTTPSampler.use_keepalive">true</boolProp> <boolProp name="HTTPSampler.DO_MULTIPART_POST">false</boolProp> <boolProp name="HTTPSampler.BROWSER_COMPATIBLE_MULTIPART">false</boolProp> <boolProp name="HTTPSampler.image_parser">false</boolProp> <boolProp name="HTTPSampler.concurrentDwn">false</boolProp> <stringProp name="HTTPSampler.concurrentPool">6</stringProp> <boolProp name="HTTPSampler.md5">false</boolProp> <intProp name="HTTPSampler.ipSourceType">0</intProp> <stringProp name="HTTPSampler.implementation">HttpClient4</stringProp> <stringProp name="TestPlan.comments">Created from cURL on 2024-01-18T09:48:24.1790394</stringProp> </HTTPSamplerProxy> <hashTree /> <HTTPSamplerProxy guiclass="HttpTestSampleGui" testclass="HTTPSamplerProxy" testname="AI助理—查看可用技能列表(available)" enabled="true"> <boolProp name="HTTPSampler.postBodyRaw">true</boolProp> <elementProp name="HTTPsampler.Arguments" elementType="Arguments"> <collectionProp name="Arguments.arguments"> <elementProp name="" elementType="HTTPArgument"> <boolProp name="HTTPArgument.always_encode">false</boolProp> <stringProp name="Argument.value">{ "agent_appid":"${__P(agent_uid)}" }</stringProp> <stringProp name="Argument.metadata">=</stringProp> </elementProp> </collectionProp> </elementProp> <stringProp name="HTTPSampler.domain">pet-saas-aigc.bndxqc.com</stringProp> <stringProp name="HTTPSampler.protocol">https</stringProp> <stringProp name="HTTPSampler.path">/thinker/api/v1/skill/list/available</stringProp> <stringProp name="HTTPSampler.method">POST</stringProp> <boolProp name="HTTPSampler.follow_redirects">true</boolProp> <boolProp name="HTTPSampler.auto_redirects">false</boolProp> <boolProp name="HTTPSampler.use_keepalive">true</boolProp> <boolProp name="HTTPSampler.DO_MULTIPART_POST">false</boolProp> <boolProp name="HTTPSampler.BROWSER_COMPATIBLE_MULTIPART">false</boolProp> <boolProp name="HTTPSampler.image_parser">false</boolProp> <boolProp name="HTTPSampler.concurrentDwn">false</boolProp> <stringProp name="HTTPSampler.concurrentPool">6</stringProp> <boolProp name="HTTPSampler.md5">false</boolProp> <intProp name="HTTPSampler.ipSourceType">0</intProp> <stringProp name="HTTPSampler.implementation">HttpClient4</stringProp> <stringProp name="TestPlan.comments">Created from cURL on 2024-01-17T17:45:46.2845029</stringProp> </HTTPSamplerProxy> <hashTree /> <HTTPSamplerProxy guiclass="HttpTestSampleGui" testclass="HTTPSamplerProxy" testname="AI助理—技能列表" enabled="false"> <boolProp name="HTTPSampler.postBodyRaw">true</boolProp> <elementProp name="HTTPsampler.Arguments" elementType="Arguments"> <collectionProp name="Arguments.arguments"> <elementProp name="" elementType="HTTPArgument"> <boolProp name="HTTPArgument.always_encode">false</boolProp> <stringProp name="Argument.value">{ "agent_appid":"${__P(agent_uid)}" }</stringProp> <stringProp name="Argument.metadata">=</stringProp> </elementProp> </collectionProp> </elementProp> <stringProp name="HTTPSampler.domain">pet-saas-aigc.bndxqc.com</stringProp> <stringProp name="HTTPSampler.protocol">https</stringProp> <stringProp name="HTTPSampler.path">/thinker/api/v1/skill/list</stringProp> <stringProp name="HTTPSampler.method">POST</stringProp> <boolProp name="HTTPSampler.follow_redirects">true</boolProp> <boolProp name="HTTPSampler.auto_redirects">false</boolProp> <boolProp name="HTTPSampler.use_keepalive">true</boolProp> <boolProp name="HTTPSampler.DO_MULTIPART_POST">false</boolProp> <boolProp name="HTTPSampler.BROWSER_COMPATIBLE_MULTIPART">false</boolProp> <boolProp name="HTTPSampler.image_parser">false</boolProp> <boolProp name="HTTPSampler.concurrentDwn">false</boolProp> <stringProp name="HTTPSampler.concurrentPool">6</stringProp> <boolProp name="HTTPSampler.md5">false</boolProp> <intProp name="HTTPSampler.ipSourceType">0</intProp> <stringProp name="HTTPSampler.implementation">HttpClient4</stringProp> <stringProp name="TestPlan.comments">Created from cURL on 2024-01-17T17:45:46.2845029</stringProp> </HTTPSamplerProxy> <hashTree /> <HTTPSamplerProxy guiclass="HttpTestSampleGui" testclass="HTTPSamplerProxy" testname="命中测试" enabled="false"> <boolProp name="HTTPSampler.postBodyRaw">true</boolProp> <elementProp name="HTTPsampler.Arguments" elementType="Arguments"> <collectionProp name="Arguments.arguments"> <elementProp name="" elementType="HTTPArgument"> <boolProp name="HTTPArgument.always_encode">false</boolProp> <stringProp name="Argument.value">{"query_text":"${pet_search}","top_k":20}</stringProp> <stringProp name="Argument.metadata">=</stringProp> </elementProp> </collectionProp> </elementProp> <stringProp name="HTTPSampler.domain">pet-saas-aigc.bndxqc.com</stringProp> <stringProp name="HTTPSampler.protocol">https</stringProp> <stringProp name="HTTPSampler.path">/thinker/api/v1/chunks/search</stringProp> <stringProp name="HTTPSampler.method">POST</stringProp> <boolProp name="HTTPSampler.follow_redirects">true</boolProp> <boolProp name="HTTPSampler.auto_redirects">false</boolProp> <boolProp name="HTTPSampler.use_keepalive">true</boolProp> <boolProp name="HTTPSampler.DO_MULTIPART_POST">false</boolProp> <boolProp name="HTTPSampler.BROWSER_COMPATIBLE_MULTIPART">false</boolProp> <boolProp name="HTTPSampler.image_parser">false</boolProp> <boolProp name="HTTPSampler.concurrentDwn">false</boolProp> <stringProp name="HTTPSampler.concurrentPool">6</stringProp> <boolProp name="HTTPSampler.md5">false</boolProp> <intProp name="HTTPSampler.ipSourceType">0</intProp> <stringProp name="HTTPSampler.implementation">HttpClient4</stringProp> <stringProp name="TestPlan.comments">Created from cURL on 2023-11-23T15:09:01.2773184</stringProp> </HTTPSamplerProxy> <hashTree /> <ResultCollector guiclass="ViewResultsFullVisualizer" testclass="ResultCollector" testname="查看结果树" enabled="true"> <boolProp name="ResultCollector.error_logging">false</boolProp> <objProp> <name>saveConfig</name> <value class="SampleSaveConfiguration"> <time>true</time> <latency>true</latency> <timestamp>true</timestamp> <success>true</success> <label>true</label> <code>true</code> <message>true</message> <threadName>true</threadName> <dataType>true</dataType> <encoding>false</encoding> <assertions>true</assertions> <subresults>true</subresults> <responseData>false</responseData> <samplerData>false</samplerData> <xml>true</xml> <fieldNames>true</fieldNames> <responseHeaders>false</responseHeaders> <requestHeaders>false</requestHeaders> <responseDataOnError>false</responseDataOnError> <saveAssertionResultsFailureMessage>true</saveAssertionResultsFailureMessage> <assertionsResultsToSave>0</assertionsResultsToSave> <bytes>true</bytes> <sentBytes>true</sentBytes> <url>true</url> <threadCounts>true</threadCounts> <idleTime>true</idleTime> <connectTime>true</connectTime> </value> </objProp> <stringProp name="filename" /> </ResultCollector> <hashTree /> </hashTree> </hashTree> </hashTree> </jmeterTestPlan>
熟悉xml的节点(这里是jmetet脚本,用的就是xml语法):
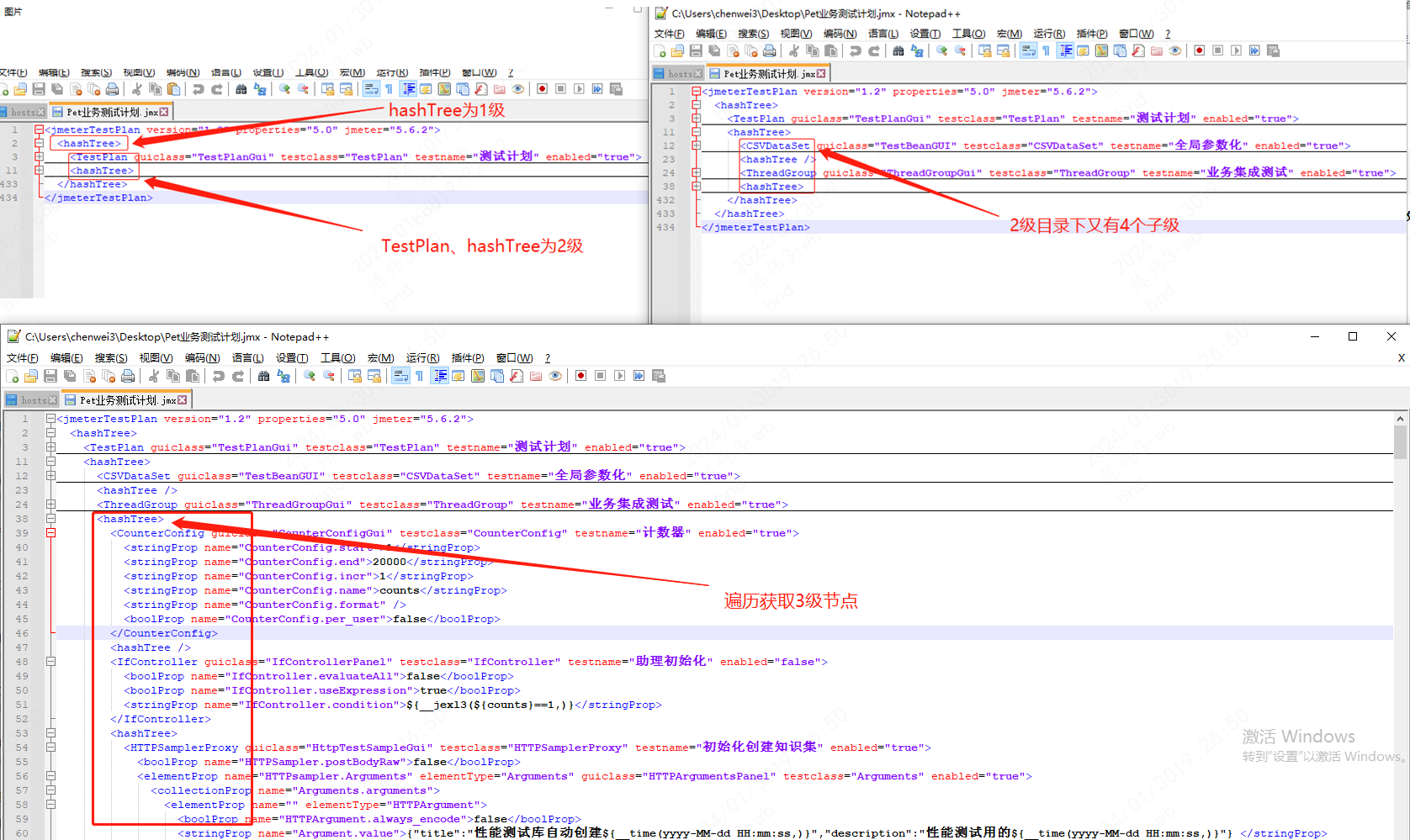
#! /usr/bin/env python # -*- coding:utf-8 -*- import xml.etree.ElementTree as ET # 1. 读取XML文档 tree = ET.parse(r'C:\Users\chenwei3\Desktop\Pet单接口测试计划.jmx') #获取XML文档的根元素,并将其存储在`root`变量中 root = tree.getroot() ###________________________遍历XML文档,并修改保存________________________________ # for child in root[0][1][3]: # print('打印当前元素的标签名称Tag:', child.tag) # print('打印当前元素的文本内容Text:', child.text) # print('打印当前元素的属性字典Attributes:', child.attrib) # #判断标签名称是否等于HTTPSamplerProxy(根据自己需求找到合适条件) # if child.tag == 'HTTPSamplerProxy': # print(child.get("testname")) # print(child.get("enabled")) # #指定条件修改 # if child.get("testname") =="命中测试": # print(child.get("enabled")) # print("找到了命中测试...................") # #修改元素的内容和属性 # child.set('enabled', "false") # #覆盖保存 # tree.write(r'C:\Users\chenwei3\Desktop\55555.xml',encoding="utf-8") ###__________________________________________详细操作_________________________________________________ ##############遍历XML文档(遍历全部)############# for child in root: print('Tag:', child.tag) print('Text:', child.text) print('Attributes:', child.attrib) ####指定子级、遍历XML文档(也可以通过findall遍历) for child in root[0][1][3]: print('Tag:', child.tag) print('Text:', child.text) print('Attributes:', child.attrib) #############读取元素的内容################# homeelement=tree.getroot() #获取XML文档的根元素 element = root.find('hashTree')#查找具有指定标签的第一个子元素(hashTree为主节点,也可以指定子节点) #查找具有指定标签的所有子元素(hashTree/hashTree/hashTree/HTTPSamplerProxy为子节点) allelement = root.findall('hashTree/hashTree/hashTree/HTTPSamplerProxy') name = allelement[1].get("testname") #获取元素的指定属性值 print("获取XML文档的根元素:",homeelement) print("获取具有指定标签的第一个子元素:",element) print("查找具有指定标签的所有子元素(list显示):",allelement) print("获取元素的指定属性值:",name) #查找具有指定标签的第一个子元素,在整个文档中搜索 nametest=root.find('.//HTTPSamplerProxy') print("打印当前元素的属性字典:",nametest.attrib) #在整个文档中搜索HTTPSamplerProxy下的test nametests=root.find('.//HTTPSamplerProxy/test') print("22打印当前元素的属性字典:",nametest.attrib) ###findall获取list一般需要遍历 for ele in allelement: print("遍历元素,当前元素的属性字典:",ele.attrib) #当前元素字典没有testname时,显示None print("遍历元素,当前元素的指定属性值:", ele.get("testname")) # print('遍历元素,打印当前元素的标签名称Tag:', ele.tag) # print('遍历元素,打印当前元素的文本内容Text:', ele.text) ###############操作元素的文本和属性################### elementname = root.find('hashTree/hashTree/hashTree/HTTPSamplerProxy') #获取多层子级 指定标签的第一个子元素 print("当前元素的属性字典:",elementname.attrib) print("当前元素的指定属性值:", elementname.get("testname")) ##################写入新的元素###################### # new_element = ET.Element('HTTPSdata') #创建一个具有指定标签的新元素对象 # new_element.text = '这是新内容' #设置新元素的文本内容。 # new_element.set('textdec', '学习python操作xml') #设置新元素的属性值 # new_element.set('name', '测试助手') # new_element.set('enabled', 'true') # root.append(new_element) #追加元素到root # ##保存修改后的XML文档 # #tree.write(r'C:\Users\chenwei3\Desktop\modified.xml',encoding="utf-8") ##################修改元素的内容和属性############### # elementdict = root.find('hashTree/hashTree/hashTree/HTTPSamplerProxy') #获取多层子级 指定标签的第一个子元素 # print("元素的属性字典:",elementdict.attrib) # elementdict.set('enabled', 'true')#修改元素的属性 # elementdict.text = '这是测试使用的内容' #修改元素的内容 # ##保存修改后的XML文档 # tree.write(r'C:\Users\chenwei3\Desktop\modified.xml',encoding="utf-8") ####################删除元素(还会报错的)####################### ###//表示在整个文档中搜索,而不仅仅是在当前节点的直接子节点中搜索。`HTTPSamplerProxy` 是要查找的元素名称。 child_to_remove = root.find('.//HTTPSamplerProxy') print("child_to_remove元素的属性字典:",child_to_remove.attrib) root.remove(child_to_remove)
相关连接:
https://www.liujiangblog.com/course/python/41 ............................................文件读写,金山在线工作簿处理
https://www.cnblogs.com/hanmk/p/9843136.html ..........................................python配置文件封装
https://blog.csdn.net/sinat_38682860/article/details/111406079 ...................ini和yaml配置文件讲解
https://www.cnblogs.com/Detector/p/8975335.html .......................................【Python】实现对大文件的增量读取
http://www.kaotop.com/it/15668.html ..............................................................文件下载几种方式
https://blog.csdn.net/tyler880/article/details/125582295.................................openpyxl设置Excel单元格样式
https://blog.csdn.net/weixin_30539625/article/details/101325400 .................Python3使用openpyxl读写Excel文件
https://blog.csdn.net/qq233325332/article/details/130799948 .....................处理xml文件(jmeter脚本文件)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号