

spring cloud(3):hystrix
一 hystrix介绍
1.1 hystrix是什么?
Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。
断路器本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。
大型项目中会出现的一些问题:
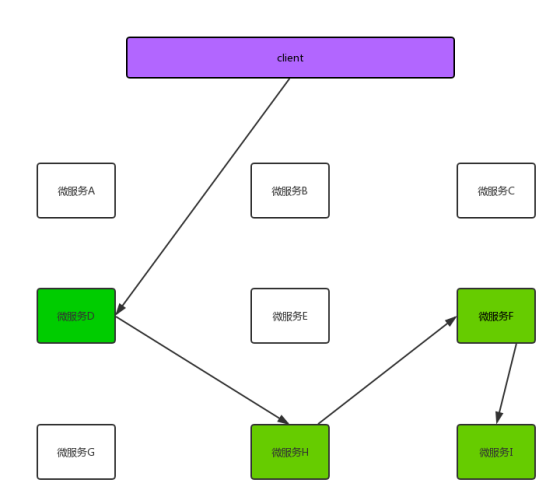
上图是一条微服务调用链, 正常的情况我们就不必在讨论了, 我们来说一下非正常情况, 假设现在 微服务H 响应时间过长,或者微服务H直接down机了如图:
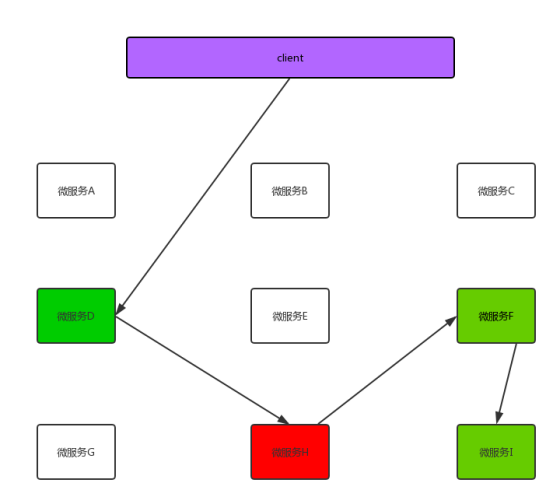
来看下上图, 我们联想一下上图, 如果发生这种情况, 也就是说所有发给微服务D的请求 都会被卡在微服务H那, 就会导致线程一直累计在这里, 那么其他的微服务(比如A,B,C...) 就没有可用线程了, 导致整个服务器崩溃,这就是服务雪崩。
针对上面的问题,我们来看看有哪些解决方案 :
- 服务限流
- 超时监控
- 服务熔断
- 服务降级
1.2 降级和超时
我们先来解释一下降级,降级是当我们的某个微服务响应时间过长,或者不可用了,讲白了也就是那个微服务调用不了了,我们不能吧错误信息返回出来,或者让他一直卡在那里,所以要在准备一个对应的策略(一个方法)当发生这种问题的时候我们直接调用这个方法来快速返回这个请求,不让他一直卡在那 。
讲了这么多,我们来看看具体怎么操作:
我们刚刚说了某个微服务调用不了了要做降级,也就是说,要在调用方做降级(不然那个微服务都down掉了再做降级也没什么意义了) 比如说我们 user 调用power,那么就在user 做降级。
现在user模块的pom里面加入以下依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
启动类加入注解@EnableHystrix 或者@EnableCircuitBreaker,他们之间是一个继承关系,2个注解所描述的内容是完全一样的,可能看大家之前都是EnableXXX(比如eureka)这里专门再写一个EnableHystrix方便大家记吧
package com;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
import org.springframework.cloud.netflix.hystrix.EnableHystrix;
import org.springframework.cloud.openfeign.EnableFeignClients;
@SpringBootApplication
@EnableEurekaClient
@EnableFeignClients
@EnableHystrix
public class AppUserClient {
public static void main(String[] args) {
SpringApplication.run(AppUserClient.class);
}
}
然后在我们的controller上面加入注解@HystrixCommand(fallbackMethod就是我们刚刚说的方法的名字)
package com.luban.controller;
import com.luban.service.PowerServiceClient;
import com.luban.util.R;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
import java.util.HashMap;
import java.util.Map;
@RestController
public class UserController {
@Autowired
RestTemplate restTemplate;
@Autowired
PowerServiceClient power;
private static final String POWER_URL="http://SERVER-POWER";
@RequestMapping("/getUser.do")
public R getUser(){
HashMap<String, Object> map = new HashMap<String, Object>();
map.put("key","user数据");
return R.success("返回成功",map);
}
@RequestMapping("/getPower.do")
public R getPower(){
Map<String,Object> map=new HashMap<String, Object>();
map.put("key1","value1");
R.success().set("key1","value1").set("key1","value1");
return R.success("操作成功",restTemplate.getForObject(POWER_URL+"/getPower.do",Object.class));
}
@RequestMapping("/feignPower.do")
@HystrixCommand(fallbackMethod = "getFeignPowerFullback")
public R feignPower(){
return power.power();
}
public R getFeignPowerFullback(){
return R.error("系统在维护中,请稍后重试");
}
}
这里的这个降级信息具体内容得根据业务需求来, 比如说返回一个默认的查询信息,亦或是系统维护(因为有可能要暂时关闭某个微服务而把资源让给其他服务)等等
我们在power代码里面模拟一个异常
package com.luban.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
@RestController
public class PowerController {
@RequestMapping("/getPower.do")
public Object getPower(String name) throws Exception {
HashMap<String, Object> map = new HashMap<String, Object>();
map.put("key","power数据");
if(null== name){
throw new Exception();
}
return map;
}
}
然后调用服务看一下结果,由于power搭建了集群,一个代码正常,一个模拟异常,ribbon的负载均衡设置的是轮询,所以会轮流出现可以访问和服务异常的情况。

我们来测试一下超时,我们改动一下power的代码 让他故意等待一回儿(模拟响应超时)
package com.luban.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;
@RestController
public class PowerController {
@RequestMapping("/getPower.do")
public Object getPower(String name) throws Exception {
HashMap<String, Object> map = new HashMap<String, Object>();
map.put("key","power数据");
Thread.sleep(2000);
return map;
}
}
public R getFeignPowerFullback(){
return R.error("系统超时,请稍后重试");
}

可能会有疑问, 我这里什么都没干, 就让他休眠了一下 , 怎么就知道我这里超时了呢?
因为hystrix他有默认的超时监听,当你这个请求默认超过了1秒钟就会超时 当然,这个可以配置的,至于怎么配置,待会儿我会把一些配置统一列出来
讲了这么多, 这个降级到底有什么用呢?
第一, 他可以监听你的请求有没有超时,第二,报错了他这里直接截断了没有让请求一直卡在这里
其实降级还有一个好处, 就是当你的系统马上迎来大量的并发(双十一秒杀这种 或者促销活动) 这时候如果发现系统马上承载不了这么大的并发时, 可以考虑先关闭一些不重要的微服务(在降级方法里面返回一个比较友好的信息),把资源让给主微服务,总结一下就是
整体资源快不够了,忍痛将某些服务先关掉,待渡过难关,再开启回来。
2.3 熔断和限流
说完降级,我们来讲讲熔断,其实熔断,就好像我们生活中的跳闸一样, 比如说你的电路出故障了,为了防止出现大型事故 这里直接切断了你的电源以免意外继续发生, 把这个概念放在我们程序上也是如此, 当一个微服务调用多次出现问题时(默认是10秒内20次当然 这个也能配置),hystrix就会采取熔断机制,不再继续调用你的方法(会在默认5秒钟内和电器短路一样,5秒钟后会试探性的先关闭熔断机制,但是如果这时候再失败一次【之前是20次】 那么又会重新进行熔断) 而是直接调用降级方法,这样就一定程度上避免了服务雪崩的问题


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理