

进程
进程状态
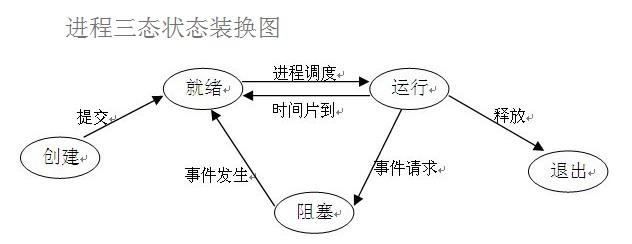
在了解其他概念之前,我们首先要了解进程的几个状态。在程序运行的过程中,由于被操作系统的调度算法控制,程序会进入几个状态:就绪,运行和阻塞。
(1)就绪(Ready)状态
当进程已分配到除CPU以外的所有必要的资源,只要获得处理机便可立即执行,这时的进程状态称为就绪状态。
(2)执行/运行(Running)状态
当进程已获得处理机,其程序正在处理机上执行,此时的进程状态称为执行状态。
(3)阻塞(Blocked)状态
正在执行的进程,由于等待某个事件发生而无法执行时,便放弃处理机而处于阻塞状态。引起进程阻塞的事件可有多种,例如,等待I/O完成、申请缓冲区不能满足、等待信件(信号)等。

同步与异步
用来表达任务的提交方式。
同步
提交完任务之后原地等待任务的返回结果,期间不做任何事。
异步
提交完任务之后不原地等待任务的返回结果,直接去做其他事,有结果自动通知。
举例说明
比如我去银行办理业务,可能会有两种方式:
第一种 :选择排队等候;
第二种 :选择取一个小纸条上面有我的号码,等到排到我这一号时由柜台的人通知我轮到我去办理业务了;
第一种:前者(排队等候)就是同步等待消息通知,也就是我要一直在等待银行办理业务情况;
第二种:后者(等待别人通知)就是异步等待消息通知。在异步消息处理中,等待消息通知者(在这个例子中就是等待办理业务的人)往往注册一个回调机制,在所等待的事件被触发时由触发机制(在这里是柜台的人)通过某种机制(在这里是写在小纸条上的号码,喊号)找到等待该事件的人。
阻塞
在得到函数返回值之前,该进程处于挂起状态,不属于工作队列(可运行状态进程组成的队列),不会占用CPU资源。
非阻塞
进程调用函数之后,无论是否返回结果,进程都会继续运行,进程仍处于可运行状态。
举例:
继续上面的那个例子,不论是排队还是使用号码等待通知,如果在这个等待的过程中,等待者除了等待消息通知之外不能做其它的事情,那么该机制就是阻塞的,表现在程序中,也就是该程序一直阻塞在该函数调用处不能继续往下执行。
相反,有的人喜欢在银行办理这些业务的时候一边打打电话发发短信一边等待,这样的状态就是非阻塞的,因为他(等待者)没有阻塞在这个消息通知上,而是一边做自己的事情一边等待。
注意:同步非阻塞形式实际上是效率低下的,想象一下你一边打着电话一边还需要抬头看到底队伍排到你了没有。如果把打电话和观察排队的位置看成是程序的两个操作的话,这个程序需要在这两种不同的行为之间来回的切换,效率可想而知是低下的;而异步非阻塞形式却没有这样的问题,因为打电话是你(等待者)的事情,而通知你则是柜台(消息触发机制)的事情,程序没有在两种不同的操作中来回切换。
同步/异步与阻塞/非阻塞
1. 同步阻塞
效率最低。拿上面的例子来说,就是你专心排队,什么别的事都不做。
2. 异步阻塞
如果在银行等待办理业务的人采用的是异步的方式去等待消息被触发(通知),也就是领了一张小纸条,假如在这段时间里他不能离开银行做其它的事情,那么很显然,这个人被阻塞在了这个等待的操作上面;
异步操作是可以被阻塞住的,只不过它不是在处理消息时阻塞,而是在等待消息通知时被阻塞。
3. 同步非阻塞
实际上是效率低下的。
想象一下你一边打着电话一边还需要抬头看到底队伍排到你了没有,如果把打电话和观察排队的位置看成是程序的两个操作的话,这个程序需要在这两种不同的行为之间来回的切换,效率可想而知是低下的。
4. 异步非阻塞
效率更高。
因为打电话是你(等待者)的事情,而通知你则是柜台(消息触发机制)的事情。程序没有在两种不同的操作中来回切换。
比如说,这个人突然发觉自己烟瘾犯了,需要出去抽根烟,于是他告诉大堂经理说,排到我这个号码的时候麻烦到外面通知我一下,那么他就没有被阻塞在这个等待的操作上面,自然这个就是异步+非阻塞的方式了。
很多人会把同步和阻塞混淆,是因为很多时候同步操作会以阻塞的形式表现出来,同样的,很多人也会把异步和非阻塞混淆,因为异步操作一般都不会在真正的IO操作处被阻塞。
但凡是硬件,都需要有操作系统去管理,只要有操作系统,就有进程的概念,就需要有创建进程的方式,一些操作系统只为一个应用程序设计,比如微波炉中的控制器,一旦启动微波炉,所有的进程都已经存在。
而对于通用系统(跑很多应用程序),需要有系统运行过程中创建或撤销进程的能力,主要分为4中形式创建新的进程:
1. 系统初始化(查看进程linux中用ps命令,windows中用任务管理器,前台进程负责与用户交互,后台运行的进程与用户无关,运行在后台并且只在需要时才唤醒的进程,称为守护进程,如电子邮件、web页面、新闻、打印)
2. 一个进程在运行过程中开启了子进程(如nginx开启多进程,os.fork,subprocess.Popen等)
3. 用户的交互式请求,而创建一个新进程(如用户双击暴风影音)
4. 一个批处理作业的初始化(只在大型机的批处理系统中应用)
无论哪一种,新进程的创建都是由一个已经存在的进程执行了一个用于创建进程的系统调用而创建的。
在不同的操作系统中创建进程底层原理不一样
windows:以导入模块的形式创建进程
linux/mac:以拷贝代码的形式创建进程
在python中需要用到multiprocess模块,仔细说来,multiprocess不是一个模块而是python中一个操作、管理进程的包。 之所以叫multi是取自multiple的多功能的意思,在这个包中几乎包含了和进程有关的所有子模块。由于提供的子模块非常多,为了方便大家归类记忆,我将这部分大致分为四个部分:创建进程部分,进程同步部分,进程池部分,进程之间数据共享
multiprocess.process模块
process模块介绍
process模块是一个创建进程的模块,借助这个模块,就可以完成进程的创建。
方式1:直接创建函数,用函数创建进程
同步状态:

import time from multiprocessing import Process def task(): print('task is running') time.sleep(3) print('task is over') # 创建一个新的进程 if __name__ == '__main__': p1 = Process(target=task) # 创建一个进程 task() # 同步 print('主')
上面为同步方式,task()调用上面的函数,同步等待函数的执行结果,先打印'task is running',3秒之后打印'task is over',之后才是打印最后的“主”。
异步状态:
import time from multiprocessing import Process def task(): print('task is running') time.sleep(3) print('task is over') # 创建一个新的进程 if __name__ == '__main__': p1 = Process(target=task) p1.start() # 异步 告诉操作系统创建一个新的进程,并在该进程中执行task函数 print('主')
上面为异步方式,创建新的进程之后先执行自己的命令,之后再执行新进程里的命令。
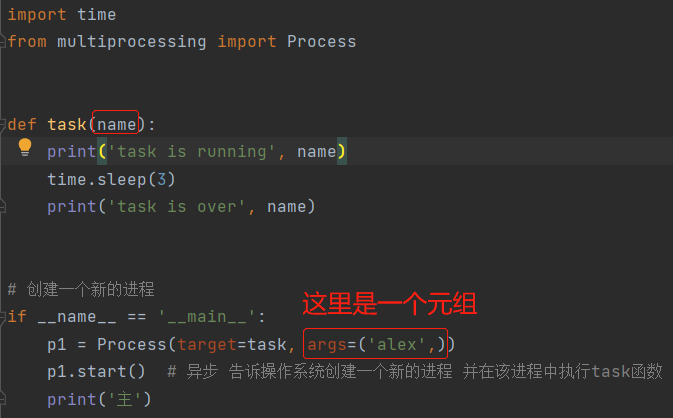
补充:如何传参
1. 位置传参
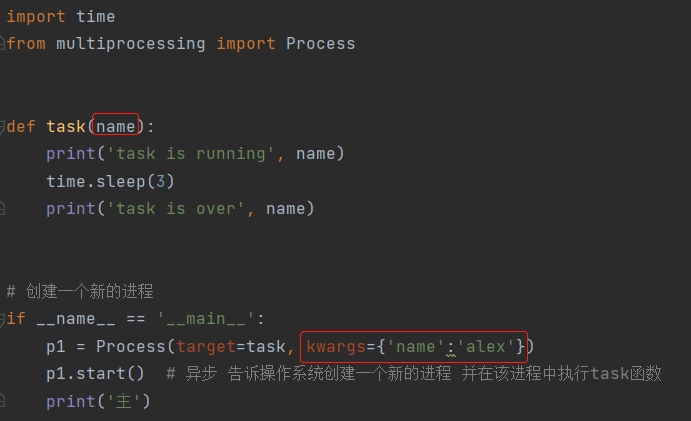
2. 关键字传参(不推荐使用)
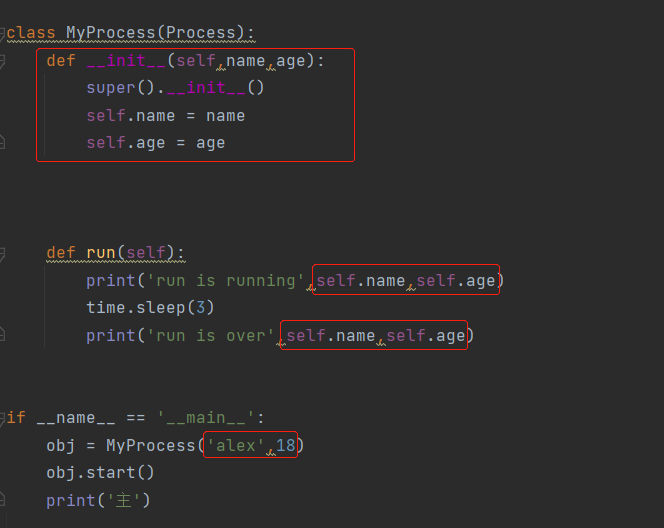
方式2:面向对象的方式
使用派生方法定义一个新的类,然后创建对象,对象调用方法创建进程
from multiprocessing import Process import time class MyProcess(Process): def run(self): print('run is running') time.sleep(3) print('run is over') if __name__ == '__main__': obj = MyProcess() obj.start() print('主')
补充:如何传参
在python程序中的进程操作
进程之间的数据隔离问题
同一台计算机上的多个进程数据是严格意义上的物理隔离(默认情况下)
我们先来复习一下之前所学的内容:
from multiprocessing import Process money = 1000 def task(): money = 666 if __name__ == '__main__': task() print(money) # 1000 局部名称空间无法修改全局名称空间中的数据值
global之后:
money = 1000 def task(): global money money = 666 if __name__ == '__main__': task() print(money) # 666
创建一个子进程:
money = 1000 def task(): global money money = 666 if __name__ == '__main__': p1 = Process(target=task) p1.start() # 创建子进程 time.sleep(3) # 主进程代码等待3秒 print(money) # 主进程代码打印money 1000
上面我们提到,在windows中创建进程是相当于导模块的操作,因此我们可以看成子进程的代码相当于在另外一个py文件中执行,虽然用上了global改变全局变量,因为跟主进程不在一个文件,可以看成产生了数据隔离。
进程的join方法
主进程代码等待子进程代码运行结束再执行
from multiprocessing import Process import time def task(name): print('%s is running' % name) time.sleep(1) print('%s is over' % name) if __name__ == '__main__': p = Process(target=task,args=('alex',)) p.start() """"主进程代码等待子进程代码运行结束再执行""" p.join() print('主')
案例:
统计子进程运行时间
from multiprocessing import Process import time def task(name,n): print('%s is running' % name) time.sleep(n) print('%s is over' % name) if __name__ == '__main__': p1 = Process(target=task,args=('alex',1)) p2 = Process(target=task, args=('alex',2)) p3 = Process(target=task, args=('alex',3)) start_time = time.time() p1.start() p2.start() p3.start() p1.join() p2.join() p3.join() end_time = time.time() print(end_time - start_time) # 3.1966536045074463
说明:三个子进程同时创建,三个进程同时等待,第一个进程在等待1秒的时候,第二、三个进程同时也等待了1秒,那么第二个进程还需要再等待1秒,此时第三个进程也同时又等待了1秒,第二进程结束之后,第三个进程还需要再等1秒就好了,加上代码运行的时间,所以总时间是3秒多。
把上述代码稍微变动一下:
from multiprocessing import Process import time def task(name,n): print('%s is running' % name) time.sleep(n) print('%s is over' % name) if __name__ == '__main__': p1 = Process(target=task,args=('alex',1)) p2 = Process(target=task, args=('alex',2)) p3 = Process(target=task, args=('alex',3)) start_time = time.time() p1.start() p1.join() p2.start() p2.join() p3.start() p3.join() end_time = time.time() print(end_time - start_time) # 6.376286745071411
说明:后面的进程是在前面的进程执行结束之后才创建,所以总的等待时间应该是1+2+3=6秒,再加上代码运行的时间,是6秒多。
消息队列:存储数据的地方,所有人都可以存,也都可以取
from multiprocessing import Queue q = Queue(3) # 括号内可以指定存储数据的个数 # 往消息队列中存放数据 q.put(111) # print(q.full()) # 判断队列是否已满 q.put(222) q.put(333) print(q.full()) # 判断队列是否已满 True # 从消息队列中取出数据 print(q.get()) # 111 print(q.get()) # 222 print(q.empty()) # 判断队列是否为空 False print(q.get()) # 333 print(q.empty()) # 判断队列是否为空 True
注意:full(),empty() 在多进程中都不能使用!!!
主进程与子进程之间通信
from multiprocessing import Process, Queue def consumer(q): print('子进程获取队列中的数据', q.get()) if __name__ == '__main__': q = Queue() # 主进程往队列中添加数据 q.put('我是主进程添加的数据') p1 = Process(target=consumer, args=(q,)) p1.start() p1.join() print('主') """ 子进程获取队列中的数据 我是主进程添加的数据 主 """
子进程与子进程之间通信
from multiprocessing import Process, Queue def product(q): q.put('子进程p添加的数据') def consumer(q): print('子进程获取队列中的数据', q.get()) if __name__ == '__main__': q = Queue() p1 = Process(target=consumer, args=(q,)) p2 = Process(target=product, args=(q,)) p1.start() p2.start() print('主') """ 主 子进程获取队列中的数据 子进程p添加的数据 """
生产者
负责产生数据的'人'
消费者
负责处理数据的'人'
该模型除了有生产者和消费者之外,还必须有消息队列(只要是能够提供数据保存服务和提取服务的理论上都可以)
进程对象的多种方法
1.如何查看进程号
from multiprocessing import Process, current_process current_process() current_process().pid # 获取当前进程号 import os os.getpid() # 获取当前进程号 os.getppid() # 获取当前进程的主进程号
案例:
from multiprocessing import Process, current_process def task(): print(current_process()) # <_MainProcess name='MainProcess' parent=None started> print(current_process().pid) # 17980 if __name__ == '__main__': p1 = Process(target=task) p1.start() print(current_process()) # <Process name='Process-1' parent=17980 started> print(current_process().pid) # 16408
2.终止进程
p1.terminate()
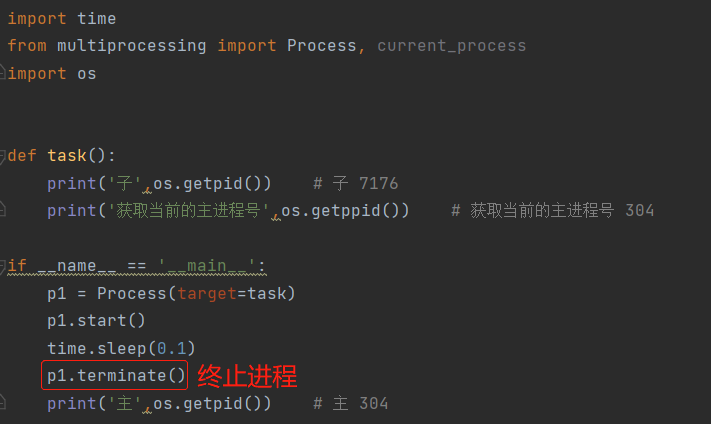
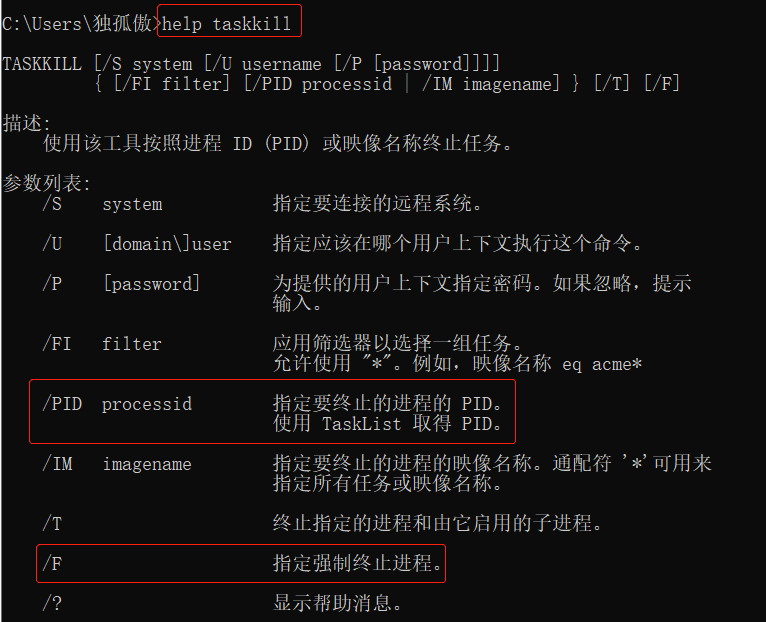
ps:计算机操作系统都有对应的命令可以直接杀死进程
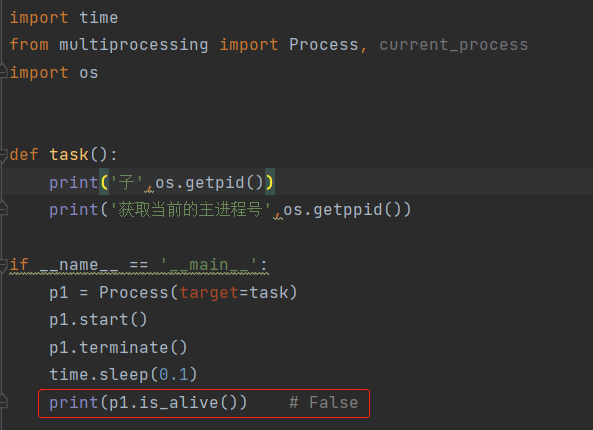
3.判断进程是否存活
p1.is_alive()
守护进程会随着守护的进程结束而立刻结束
eg: 吴勇是张红的守护进程,一旦张红嗝屁了,吴勇立刻嗝屁
from multiprocessing import Process import time def task(name): print('德邦总管:%s' % name) time.sleep(3) print('德邦总管:%s' % name) if __name__ == '__main__': p1 = Process(target=task, args=('大张红',)) p1.daemon = True # 将p1进程设置为当前主进程的守护进程,必须放在start()前面 p1.start() print('恕瑞玛皇帝:小吴勇嗝屁了')
使用场景:一键操作所有的进程——关闭和启动,可以将所有的进程都设为守护进程。
僵尸进程与孤儿进程
僵尸进程
进程执行完毕后并不会立刻销毁所有的数据,会有一些信息短暂保留下来
比如进程号、进程执行时间、进程消耗功率等给父进程查看
ps:所有的进程都会变成僵尸进程
孤儿进程
子进程正常运行,父进程意外死亡,操作系统针对孤儿进程会派遣福利院管理
多进程
from multiprocessing import Process import time import json import random # 查票 def search(name): with open(r'data.json', 'r', encoding='utf8') as f: data = json.load(f) print('%s在查票 当前余票为:%s' % (name, data.get('ticket_num'))) # 买票 def buy(name): # 再次确认票 with open(r'data.json', 'r', encoding='utf8') as f: data = json.load(f) # 模拟网络延迟 time.sleep(random.randint(1, 3)) # 判断是否有票 有就买 if data.get('ticket_num') > 0: data['ticket_num'] -= 1 with open(r'data.json', 'w', encoding='utf8') as f: json.dump(data, f) print('%s买票成功' % name) else: print('%s很倒霉 没有抢到票' % name) def run(name): search(name) buy(name) if __name__ == '__main__': for i in range(10): p = Process(target=run, args=('用户%s'%i, )) p.start()
通过上面的代码,运行之后我们发现虽然设置成只有1张票,但是每个人都会显示买到票了。这个时候就出现了数据错乱。 但是有的时候又会发现,有时候又是正常的逻辑顺序进行抢票。 多进程操作数据很可能会造成数据错乱。
解决方案>>>:互斥锁
互斥锁——将并发变成串行,牺牲了效率但是保障了数据的安全
server端:
import socket from multiprocessing import Process def get_server(): server = socket.socket() server.bind(('127.0.0.1', 8080)) server.listen(5) return server def get_talk(sock): while True: data = sock.recv(1024) print(data.decode('utf8')) sock.send(data.upper()) if __name__ == '__main__': server = get_server() while True: sock, addr = server.accept() # 开设多进程去聊天 p = Process(target=get_talk, args=(sock,)) p.start()
client端
import socket client = socket.socket() client.connect(('127.0.0.1', 8080)) while True: client.send(b'hello baby') data = client.recv(1024) print(data)
from multiprocessing import Process, Lock import time import json import random def search(name): with open(r'data.json', 'r', encoding='utf8') as f: data = json.load(f) print('%s查看票 目前剩余:%s' % (name, data.get('ticket_num'))) def buy(name): # 先查询票数 with open(r'data.json', 'r', encoding='utf8') as f: data = json.load(f) # 模拟网络延迟 time.sleep(random.randint(1, 3)) # 买票 if data.get('ticket_num') > 0: with open(r'data.json', 'w', encoding='utf8') as f: data['ticket_num'] -= 1 json.dump(data, f) print('%s 买票成功' % name) else: print('%s 买票失败 非常可怜 没车回去了!!!' % name) def run(name, mutex): search(name) mutex.acquire() # 抢锁 buy(name) mutex.release() # 释放锁 if __name__ == '__main__': mutex = Lock() # 产生一把锁 for i in range(10): p = Process(target=run, args=('用户%s号' % i, mutex)) p.start()
"""
锁有很多种 但是作用都一样
行锁 表锁 ...
"""


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人