

正则表达式
一、正则表达式
是用来描述字符串内容格式,使用它通常用于匹配一个字符串的内容是否符合格式要求。
1.[ ]:表示一个字符,该字符可以是[ ]中指定的内容
例如:

[0123456789]:匹配0-9任意一个数字(全写)
[0-9]:匹配0-9任意一个数字(缩写)
[abc]:这个字符可以是a或b或c [a-z]:匹配任意一个小写字母
[A-Z]:匹配任意一个大写字母
[a-zA-Z]:表示任意一个字母
[a-zA-Z0-9_]:表示任意一个数字字母下划线
[^abc]:该字符只要不是a或b或c
ps:字符组内所有的数据默认都是或的关系
2.特殊符号:
. :表示任意一个除了换行符以外的字符 \d :表示任意一个数字,等同于[0-9] \w :表示任意一个数字、字母、下划线,等同于[a-zA-Z0-9_] \s :表示任意一个空白字符 \D :表示不是数字 \W :不是单词字符 \S:不是空白字符
^: 匹配字符串的开头
$: 匹配字符串的结尾
^与$组合使用可以非常精确的限制匹配内容
a|b:匹配a或者b(管道符的意思是或)
():给正则表达式分组 不影响表达式的匹配功能
[]:字符组,内部填写的内容默认都是或的关系
[^]:取反操作,匹配除了字符组里面的其他所有字符
注意:上尖号在中括号内和中括号意思完全不同
3.量词:
?:表示前面的内容出现0-1次,作为量词意义不大主要用于非贪婪匹配 例如: [abc]? 可以匹配:a 或 b 或 c 或什么也不写 +:表示前面的内容最少出现1次,默认是多次 例如: [abc]+ 可以匹配:b或aaaaaaaaaa…或abcabcbabcbabcba… 但是不能匹配:什么都不写 或 abcfdfsbbaqbb34bbwer… *:表示前面的内容出现任意次(0-多次)—默认是多次 例如: [abc]* 可以匹配:b或aaaaaaaaaa…或abcabcba…或什么都不写 但是不能匹配:abcfdfsbbaqbb34bbwer… {n}:表示前面的内容出现n次 例如: [abc]{3} 可以匹配:aaa 或 bbb 或 aab 或abc 或bbc 但是不能匹配: aaaa 或 aad {n,m}:表示前面的内容出现最少n次最多m次 例如: [abc]{3,5} 可以匹配:aaa 或 abcab 或者 abcc 但是不能匹配:aaaaaa 或 aabbd {n,}:表示前面的内容出现n次以上(含n次) 例如: [abc]{3,} 可以匹配:aaa 或 aaaaa… 或 abcbabbcbabcba… 但是不能匹配:aa 或 abbdaw…
ps:量词必须结合表达式一起使用,不能单独出现,并且只影响左边第一个表达式
Alex\d{3} 只影响\d
4.()用于分组,是将括号内的内容看做是一个整体
**'(abc){3}'** 表示abc整体出现3次. 可以匹配abcabcabc,但是不能匹配aaa 或abcabc '(abc|def){3}' 表示abc或def整体出现3次. 可以匹配: abcabcabc 或 defdefdef 或 abcdefabc 但是不能匹配abcdef 或abcdfbdef
二、正则表达式相关练习
1. . ^ $
| 正则 | 待匹配字符 | 匹配结果 | 说明 |
| 海. | 海燕海娇海东 | 海燕海娇海东 | 匹配所有"海."的字符 |
| ^海. | 海燕海娇海东 | 海燕 | 只从开头匹配"海." |
| 海.$ | 海燕海娇海东 | 海东 | 只匹配结尾的"海.$" |
2.* + ?{}
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李.? | 李杰和李莲英和李二棍子 | 李杰 李莲 李二 |
?表示重复零次或一次,即只匹配"李"后面一个任意字符 |
| 李.* | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 |
*表示重复零次或多次,即匹配"李"后面0或多个任意字符 |
| 李.+ | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 |
+表示重复一次或多次,即只匹配"李"后面1个或多个任意字符 |
| 李.{1,2} | 李杰和李莲英和李二棍子 | 李杰和 李莲英 李二棍 |
{1,2}匹配1到2次任意字符
|
注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李.*? | 李杰和李莲英和李二棍子 | 李 李 李 |
惰性匹配 |
3. 字符集 [ ] [^]
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李[杰莲英二棍子]* | 李杰和李莲英和李二棍子 | 李杰 李莲英 李二棍子 |
表示匹配"李"字后面[杰莲英二棍子]的字符任意次 |
| 李[^和]* | 李杰和李莲英和李二棍子 | 李杰 李莲英 李二棍子 |
表示匹配一个不是"和"的字符任意次 |
| [\d] | 456bdha3 | 4 5 6 3 |
表示匹配任意一个数字,匹配到4个结果 |
| [\d]+ | 456bdha3 | 456 3 |
表示匹配任意个数字,匹配到2个结果 |
4. 分组 ()与 或 |[^]
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| ^[1-9]\d{13,16}[0-9x]$ | 110101198001017032 | 110101198001017032 | 表示可以匹配一个正确的身份证号 |
| ^[1-9]\d{13,16}[0-9x]$ | 1101011980010170 | 1101011980010170 |
表示也可以匹配这串数字,但这并不是一个正确的身份证号码, 它是一个16位的数字 |
| ^[1-9]\d{14}(\d{2}[0-9x])?$ | 1101011980010170 | False |
现在不会匹配错误的身份证号了 ()表示分组,将\d{2}[0-9x]分成一组,就可以整体约束他们出现的次数为0-1次
|
| ^([1-9]\d{16}[0-9x]|[1-9]\d{14})$ | 110105199812067023 | 110105199812067023 | 表示先匹配[1-9]\d{16}[0-9x]如果没有匹配上就匹配[1-9]\d{14} |
三、转义符
在正则表达式中,有很多有特殊意义的是元字符,比如\n和\s等,如果要在正则中匹配正常的"\n"而不是"换行符"就需要对"\"进行转义,变成'\\'。
在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\也有特殊的含义,本身还需要转义。所以如果匹配一次"\n",字符串中要写成'\\n',那么正则里就要写成"\\\\n",这样就太麻烦了。这个时候我们就用到了r'\n'这个概念,此时的正则是r'\\n'就可以了。
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| \n | \n | False |
因为在正则表达式中\是有特殊意义的字符,所以要匹配\n本身,用表达式\n无法匹配 |
| \\n | \n | True |
转义\之后变成\\,即可匹配 |
| "\\\\n" | '\\n' | True |
如果在python中,字符串中的'\'也需要转义,所以每一个字符串'\'又需要转义一次 |
| r'\\n' | r'\n' | True |
在字符串之前加r,让整个字符串不转义 |
四、贪婪匹配
贪婪匹配:
在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| <.*> | <script>...<script> | <script>...<script> |
默认为贪婪匹配模式,会匹配尽量长的字符串 |
| <.*?> | r'\d' | <script> <script> |
加上?为将贪婪匹配模式转为非贪婪匹配模式,会匹配尽量短的字符串 |
几个常用的非贪婪匹配Pattern
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
.*?的用法
. 是任意字符 * 是取 0 至 无限长度 ? 是非贪婪模式。 合在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在: .*?x 就是取前面任意长度的字符,直到一个x出现
五、常用正则表达式演示:
1.邮箱演示:
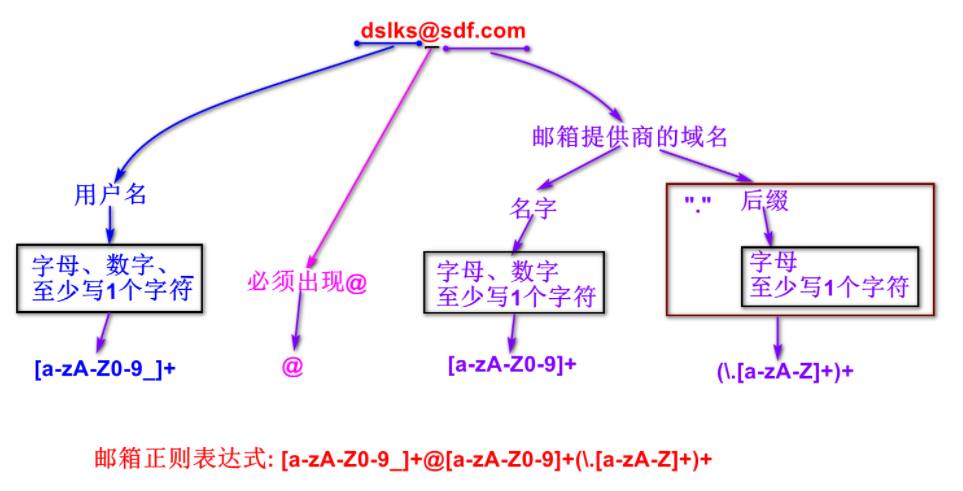
2.数字校验:
数字:^ [0-9]*$ n位的数字:^\d{n}$ 至少n位的数字:^\d{n,}$ m-n位的数字:^\d{m,n}$ 零和非零开头的数字:^(0|[1-9][0-9]*)$ 非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$ 带1-2位小数的正数或负数:^(-)?\d+(.\d{1,2})?$ 正数、负数、和小数:^(-|+)?\d+(.\d+)?$ 有两位小数的正实数:^ [0-9]+(.[0-9]{2})?$ 有1~3位小数的正实数:^ [0-9]+(.[0-9]{1,3})?$ 非零的正整数:^ [1-9]\d*$ 或 ^([1-9][0-9]){1,3}$ 或 ^+?[1-9][0-9]$ 非零的负整数:^-[1-9][]0-9"$ 或 ^-[1-9]\d$ 非负整数:^\d+$ 或 ^ [1-9]\d*|0$ 非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$ 非负浮点数:^\d+(.\d+)?$ 或 ^ [1-9]\d*.\d*|0.\d*[1-9]\d*|0?.0+|0$ 非正浮点数:^((-\d+(.\d+)?)|(0+(.0+)?))$ 或 ^(-([1-9]\d*.\d*|0.\d*[1-9]\d*))|0?.0+|0$ 正浮点数:^ [1-9]\d*.\d*|0.\d*[1-9]\d*$ 或 ^ (([0-9]+.[0-9][1-9][0-9])|([0-9][1-9][0-9].[0-9]+)|([0-9][1-9][0-9]))$ 负浮点数:^-([1-9]\d*.\d*|0.\d*[1-9]\d*)$ 或 ^(-(([0-9]+.[0-9][1-9][0-9])|([0-9][1-9][0-9].[0-9]+)|([0-9][1-9][0-9])))$ 浮点数:^(-?\d+)(.\d+)?$ 或 ^-?([1-9]\d*.\d*|0.\d*[1-9]\d*|0?.0+|0)$
3.验证字符:
汉字 :^[\u4e00-\u9fa5]{0,}$ 英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$ 长度为3-20的所有字符:^.{3,20}$ 由26个英文字母组成的字符串:^[A-Za-z]+$ 由26个大写英文字母组成的字符串:^[A-Z]+$ 由26个小写英文字母组成的字符串:^[a-z]+$ 由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$ 由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$ 中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$ 中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
4.其他常用验证
1.域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.? 2.手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$ 3.身份证号(15位、18位数字):^\d{15}|\d{18}$ 4.密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^ [a-zA-Z]\w{5,17}$ 5.日期格式:^\d{4}-\d{1,2}-\d{1,2} 6.一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$ 7.一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$ 8.xml文件:^([a-zA-Z]±?)+[a-zA-Z0-9]+\.[x|X][m|M][l|L]$ 9.中文字符的正则表达式:[\u4e00-\u9fa5] 10.QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始) 11.中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字) 12.IP地址:\d+.\d+.\d+.\d+ (提取IP地址时有用) 13.IP地址:(( ? : ( ?:25[0-5]|2[0-4]\d|[01]?\d?\d)\.){3}(?:25[0-5]|2[0-4]\d|[01]?\d?\d)) 14.文件扩展名效验:^([a-zA-Z]\: |\\)\\([^\\]+\\)* [ ^ \/: * ?"<>|]+\.txt(l)?$
ps:上面的表达式不要求会写,网上都能查到。
参考网站:https://tool.chinaz.com/regex
六、
import re res = re.findall('a', 'eva jason yuan') # 返回所有满足匹配条件的结果,放在列表里 print(res) #结果 : ['a', 'a'] res = re.search('a', 'eva jason yuan').group() print(res) #结果 : 'a' # 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以 # 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 res = re.match('a', 'abc').group() # 同search,不过尽在字符串开始处进行匹配 print(res) #结果 : 'a' res = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 print(res) # ['', '', 'cd'] res = re.sub('\d', 'H', 'eva3jason4yuan4', 1)#将数字替换成'H',参数1表示只替换1个 print(res) #evaHjason4yuan4 res = re.subn('\d', 'H', 'eva3jason4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次) print(res) obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 res = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 print(res.group()) #结果 : 123 import re res = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器 print(res) # <callable_iterator object at 0x10195f940> print(next(res).group()) #查看第一个结果 print(next(res).group()) #查看第二个结果 print([i.group() for i in res]) #查看剩余的左右结果
注意:
1. findall的优先级查询:
import re res = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com') print(res) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 res = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') print(res) # ['www.oldboy.com'] res = re.search('www.(baidu|oldboy).com', 'www.oldboy.com') print(res.group()) # www.oldboy.com res = re.match('www.(baidu|oldboy).com', 'www.oldboy.com') print(res.group()) # www.oldboy.com
2.split的优先级查询
res=re.split("\d+","eva3jason4yuan") print(res) #结果 : ['eva', 'jason', 'yuan'] res=re.split("(\d+)","eva3jason4yuan") print(res) #结果 : ['eva', '3', 'jason', '4', 'yuan'] #在匹配部分加上()之后所切出的结果是不同的, #没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项, #这个在某些需要保留匹配部分的使用过程是非常重要的。
3. 分组别名
res = re.search('www.(?P<content>baidu|oldboy)(?P<hei>.com)', 'www.oldboy.com') print(res.group()) # www.oldboy.com print(res.group('content')) # oldboy print(res.group(0)) # www.oldboy.com print(res.group(1)) # oldboy print(res.group(2)) # .com print(res.group('hei')) # .com
七、综合练习与扩展
1. 匹配标签
import re res = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>") #还可以在分组中利用?<name>的形式给分组起名字 #获取的匹配结果可以直接用group('名字')拿到对应的值 print(res.group('tag_name')) #结果 :h1 print(res.group()) #结果 :<h1>hello</h1> res = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>") #如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致 #获取的匹配结果可以直接用group(序号)拿到对应的值 print(res.group(1)) print(res.group()) #结果 :<h1>hello</h1>
2. 匹配整数
import re res=re.findall(r"\d+","1-2*(60+(-40.35/5)-(-4*3))") print(res) #['1', '2', '60', '40', '35', '5', '4', '3'] res=re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))") print(res) #['1', '-2', '60', '', '5', '-4', '3'] res.remove("") print(res) #['1', '-2', '60', '5', '-4', '3']


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律