

模块简介
模块简介
1. 模块的本质
内部具有一定的功能(代码)的py文件
2. python模块的历史
python刚开始的时候所有搞其他编程语言的程序员都看不起 甚至给python起了个外号>>>:调包侠(贬义词)
随着时间的发展项目的复杂度越来越高 上面那帮人也不得不用一下python 然后发现真香定律>>>:调包侠(褒义词)
3. python模块的表现形式
1. py文件(py文件也可以称之为是模块文件)
2. 含有多个py文件的文件夹(按照模块功能的不同划分不同的文件夹存储)
3. 已被编译为共享库或DLL的c或C++扩展(了解)
4. 使用C编写并链接到python解释器的内置模块(了解)
模块分类
1. 自定义模块
我们自己写的模块文件
2. 内置模块
python解释器提供的模块
3. 第三方模块
别人写的模块文件(python背后真正的大佬)
1.import句式
导入模块的方式一:
import 模块名
import 模块名1,模块名2……(不推荐)假设存在一个模块a.py, 模块的名称为a。
a.py中的内容有:

name = 'jason'
def func1():
print('from a.py func1')
def func2():
func1()
def change():
global name
name = 'tony'
导入整个模块:
import a
只需要import a一行代码就可以打开文件a.py ,并将a.py中的所有代码都复制到import a这行代码所在的文件中,当然我们看不到这个过程,当运行这个文件时,python在幕后复制这些代码。这样我们就可以执行a.py文件中的所有代码了。
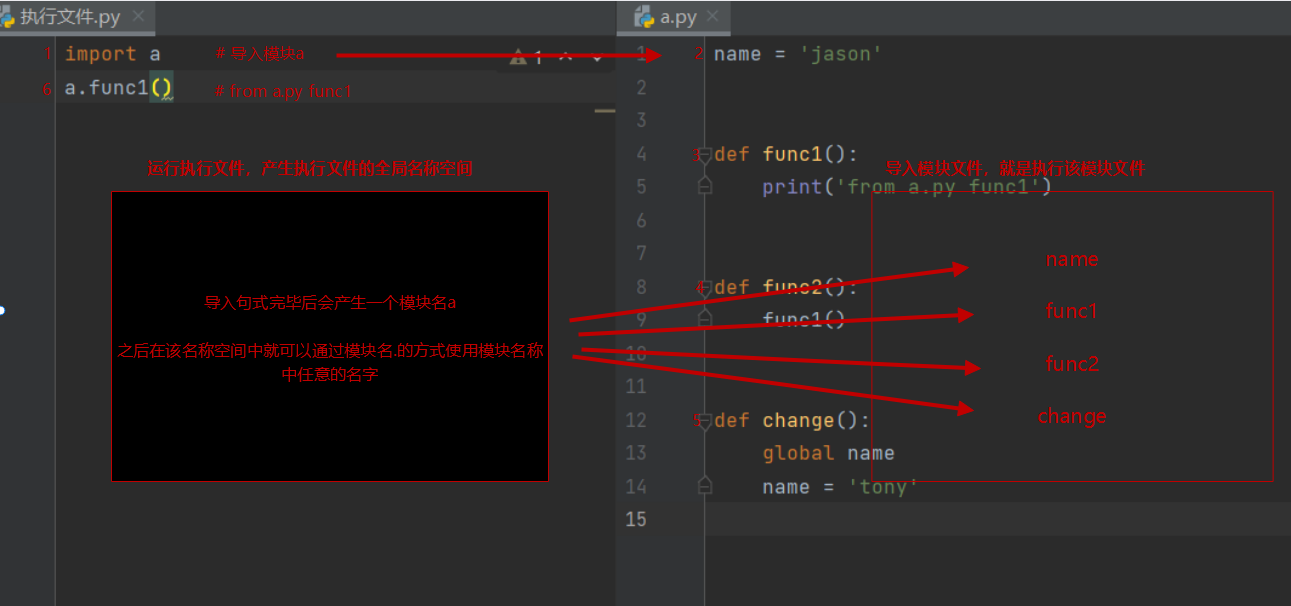
(1)先产生执行文件的名称空间
(2)执行被导入文件的代码将产生的名字放入被导入文件的名称空间中
(3)在执行文件的名称空间中产生一个模块的名字
(4)在执行文件中使用该模块名点的方式使用模块名称空间中所有的名字
强调:
- 一定要搞清楚谁是执行文件,谁是被导入文件
- 以后开发项目的时候py文件的名称一般是纯英文
不会含有中文甚至空格
01 作业讲解.py 不会出现
test.py views.py 出现
- 导入模块文件不需要填写后缀名
2. from...import...句式
from a import func1:指名道姓地导入
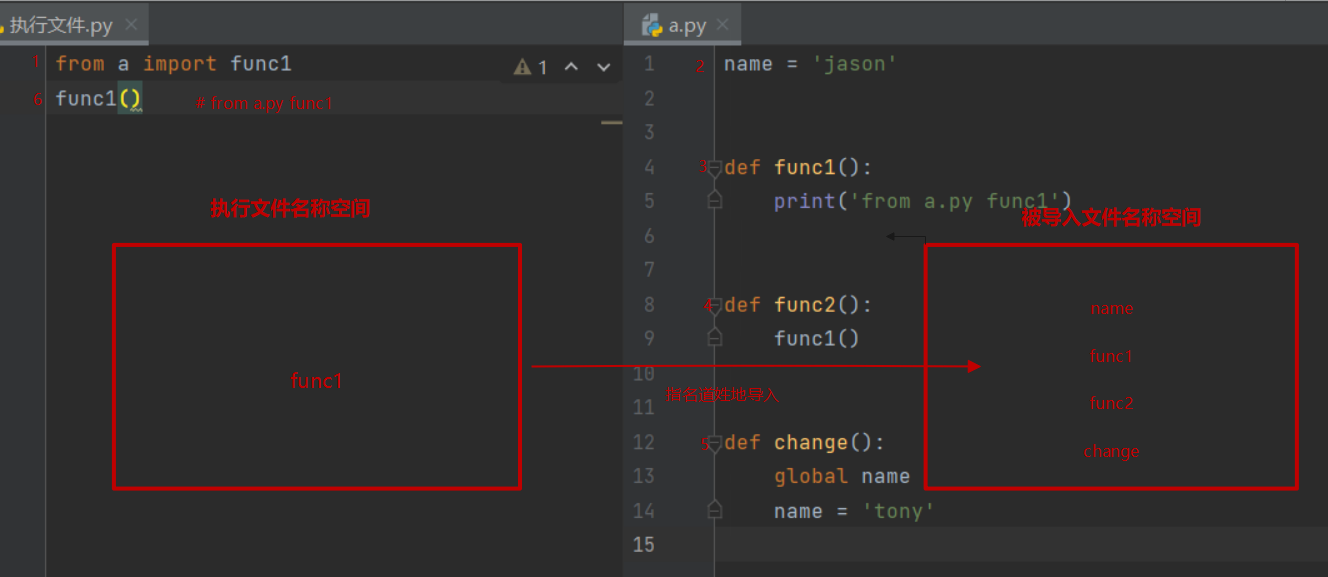
(1)先产生执行文件的名称空间
(2)执行被导入文件的代码将产生的名字放入被导入文件的名称空间中
(3)在执行文件的名称空间中产生对应的名字绑定模块名称空间中对应的名字
(4)在执行文件中直接使用名字就可以访问名称空间中对应的名字
1.import与from...import...两者优缺点
import句式
- 使用模块名称空间中的名字都需要模块名点的方式才可以用
- 不会轻易的被执行文件中的名字替换掉
from...import...句式
- 指名道姓的导入模块名称空间中需要使用的名字 不需要模块名点
- 但是容易跟执行文件中名字冲突
2. 重复导入模块
解释器只会导入一次,后续重复的导入语句并不会执行
3.起别名
如果被导入模块名较长,我们可以在执行文件中自己起别名
- import 被导入模块名 as 别名
- from a import name as n,func1 as f1
4. 涉及到多个模块导入
- 连续导入
可以一个句式导入多个模块,每个模块之间用逗号隔开。
示例:
# 方式一:
import time
import os
import sys
# 方式二:
import time,os,sys
- 通用导入
from test1 import *
print(num)
get_num()
change()
注意:模块的编写者可以通过在自己的文件中定义__all__变量来控制*号代表的意思。
from a import * *默认是将模块名称空间中所有的名字导入
__all__ = ['名字1', '名字2'] 针对*可以限制导入的名字
# first.py
num = 100
def get_num():
print(x)
def change():
global num
num = 0
__all__ = ['num','get_num']
# start.py
from first import *
print(num) # 可用
get_num() # 可用
change() # 不可用
1. 循环导入
两个文件之间彼此导入彼此,并且相互使用各自名称空间中的名字,极容易报错
2. 如何解决循环导入问题
- 确保名字在使用之前就已经准备完毕
- 我们以后在编写代码的过程中应该尽可能避免出现循环导入
# m1.py
print('正在导入m1')
from m2 import y
x='m1'
# m2.py
print('正在导入m2')
from m1 import x
y='m2'
# start.py
import m1
运行start.py:
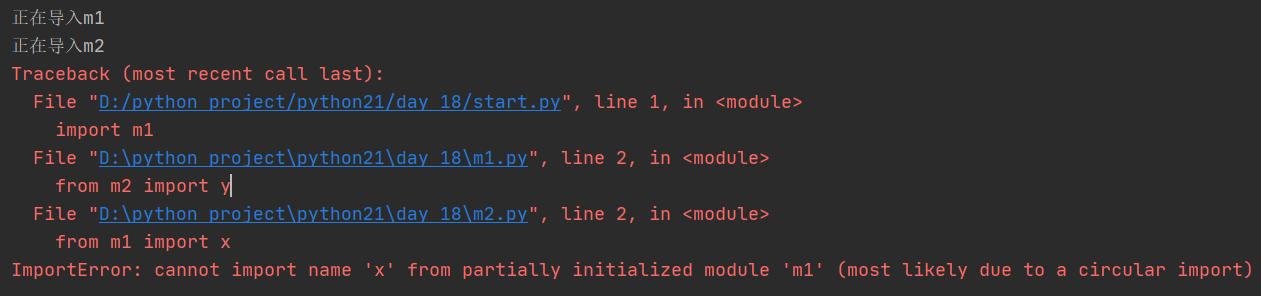
分析:
先执行start.py,执行import m1,开始导入m1,并运行其内部代码,打印内容"正在导入m1",然后执行from m2 import y 开始导入m2并运行其内部代码,打印内容“正在导入m2”,再执行from m1 import x,由于m1已经被导入过了,所以不会重新导入,所以直接去m1中拿x,然而x此时并没有存在于m1中,所以报错。
解决方案:在文件的最后导入模块
# m1.py
print('正在导入m1')
x='m1'
from m2 import y
# m2.py
print('正在导入m2')
y='m2'
from m1 import x
# start.py
import m1
因为一个python文件,可以是执行文件,也可以是被导入文件,那么我们该如何来区分呢?python中通过__name__的内容来进行区分。
注意:
如果在执行文件中,__name__的值是__main__,并且是字符串类型。
如果作为模块时,__name__的值被赋予模块名。
作为模块的开发者,可以在文件末尾基于__name__在不同应用场景下的值的不同来控制文件执行不同的逻辑。
# test.py
if __name__ == '__main__':
test.py被当做脚本执行时运行的代码
else:
test.py被当做模块导入时运行的代码
使用场景:
1. 模块开发阶段
2. 项目启动文件
模块的查找顺序(重点)
- 先从内存中查找
- 再从内置中查找
- 最后从执行文件所在的sys.path,按照从左到右的顺序,依次查找。
如果在你的执行文件中找不到模块的时候,解决方案:把模块所在的路径加到执行文件的sys.path中。
import sys
print(sys.path) # 所有系统路径,以列表形式显示
sys.path.append(r'D:\pythonProject03\day17\mymd') # 把模块所在的路径加到系统路径中
import ccc
print(ccc.name)
绝对导入
- from mymd.aaa.bbb.ccc.ddd import name # 可以精确到变量名
- from mymd.aaa.bbb.ccc import ddd # 也可以精确到模块名
ps:套路就是按照项目根目录一层层往下查找
相对导入
- .在路径中表示当前目录
- ..在路径中表示上一层目录
- ..\..在路径中表示上上一层目录
不再依据执行文件所在的sys.path,而是以模块自身路径为准
from . import b
相对导入只能用于模块文件中,不能在执行文件中使用
说明:相对导入使用频率较低,一般用绝对导入即可,结构更加清晰
大白话:多个py文件的集合>>>:文件夹
专业:内部含有__init__.py文件的文件夹(python2必须要求,python3无所谓)
包的具体使用
虽然python3对包的要求降低了,不需要__init__.py也可以识别,但是为了兼容性考虑最好还是加上__init__.py
1. 如果只想用包中某几个模块 那么还是按照之前的导入方式即可
from aaa import md1, md2
2.如果直接导入包名
import aaa
导入包名其实就是导入包下面的__init__.py文件,该文件内有什么名字就可以通过包名点什么名字


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人