论文阅读:Andromeda: Performance, Isolation, and Velocity at Scale in Cloud Network Virtualization (全文翻译用于资料整理和做PPT版本,之后会修改删除)
Abstract:
- This paper presents our design and experience with Andromeda, Google Cloud Platform’s network virtualization stack
本文介绍了我们使用Andromedia(google云平台的网络虚拟化堆栈)的设计和经验。
我们的生产部署提出了一些具有挑战性的要求,包括客户虚拟网络之间的性能隔离、可扩展性、大量虚拟主机的快速供应、与底层硬件基本无法区分的带宽和延迟,以及高功能速度和高可用性。
仙女座是围绕一个灵活的流处理路径层次设计的,流根据特性和性能需求动态映射到编程路径。我们引入了悬停板编程模型,它使用网关来处理低带宽流的长尾,并使控制平面能够在几秒钟内为数万个虚拟机编程网络连接。主机上的数据平面基于高性能操作系统旁路软件包处理路径,具有更高延迟目标的CPU密集型包操作在协处理器线程上执行。这种架构允许Andromeda将特性增长与快速路径性能分离,因为许多特性可以单独在协处理器路径上实现。我们表明,仙女座数据通路实现性能可与硬件竞争,同时保持灵活性和速度的软件为基础的架构。
1 Introduction:
- Cloud providers must support virtual networks with high performance and a rich set of features such as load balancing, firewall, VPN, QoS, DoS protection, isolation, and NAT, all while operating at a global scale
云计算的兴起为网络带来了新的机遇和挑战。云提供商必须支持具有高性能和丰富功能(如负载平衡、防火墙、VPN、QoS、DoS保护、隔离和NAT)的虚拟网络,同时在全球范围内运行。
- Typical research efforts focus on point problems in the space, rather than the challenges of bringing a working system together end to end
对于云计算的网络支持,特别是高速数据平面、虚拟路由基础设施和NFV中间盒,已经进行了大量的研究。典型的研究工作侧重于空间中的点问题,而不是将工作系统端到端地结合在一起的挑战。
我们开发了Andromeda,Google云平台(GCP)的网络虚拟化环境,并利用这一经验来展示我们如何将功能划分为全局、分层控制平面、高速主机虚拟交换机、数据包处理器和可扩展网关。
This paper focuses on the following topics:
-
The Andromeda Control plane is designed for agility, availability, isolation, and scalability
-
The Andromeda Dataplane is composed of a flexible set of flow processing paths
-
To remain at the cutting edge, we constantly deploy new features, new hardware, and performance improvements
本文主要关注以下主题:
-
仙女座控制平面的设计具有灵活性、可用性、隔离性和可扩展性。上下扩展计算和快速提供虚拟基础设施意味着控制平面必须实现高性能和可用性,Andromeda扩展到超过100000个虚拟机的网络,并以184ms的平均延迟处理网络更新,意味着一个虚拟网络的操作(例如,旋转10k个虚拟机)不应影响其他网络的响应。
-
仙女座数据平面由一组灵活的流程处理路径组成,悬停板路径通过处理专用网关上大部分空闲流的长尾来实现控制平面缩放,活动流由主机上的数据平面处理,主机上的快速路径用于性能关键流。
-
为了保持领先地位,我们不断部署新功能、新硬件和性能改进。为了在不牺牲可用性的情况下保持高部署速度,Andromeda支持透明的虚拟机实时迁移和无中断的数据平面升级。
我们描述了仙女座的设计和我们五年来的经验。
相对于我们自己的初始生产部署,我们将吞吐量提高了19倍,CPU效率提高了16倍,延迟了7倍,最大网络规模增加了50倍。Andromeda还通过透明的虚拟机迁移和每周无中断的数据平面升级提高了速度,同时提供了一系列新的终端客户云功能。
2 Overview:
2.1 Requirements and Design Goals
一个健壮的网络虚拟化环境必须支持许多基本和高级功能,在概述我们的方法之前,我们先从一系列功能和要求开始,因为这些功能和要求启发了我们的思考。
- At the most basic level, network virtualization requires supporting isolated virtual networks for individual customers with the illusion that VMs in the virtual network are running on their own private IP network
1. 在最基本的层面上,网络虚拟化需要为单个客户支持孤立的虚拟网络,而虚拟网络中的虚拟机却在自己的私有IP网络上运行。因此一个虚拟网络中的虚拟机应该能够相互通信,对内部云提供商的服务、对第三方提供商,对互联网。这些都受客户策略的约束,同时与其他虚拟网络中的操作隔离。
我们的理想目标是支持与底层硬件的相同吞吐量和延迟。
- Beyond basic connectivity, we must support constantly evolving network features
2. 除了基本的连接性,我们还必须支持不断发展的网络功能。示例包括计费、DoS保护、跟踪、性能监视和防火墙。我们添加并改进了这些特性,并导航了几个主要的架构转换,例如转换到内核旁路数据平面,所有这些都没有中断VM。
- A promise of Cloud Computing is higher availability than what can be provisioned in smaller-scale deployments
3. 云计算的承诺是比小规模部署提供的更高的可用性。我们的网络提供全球连接,而且它是许多服务的核心依赖项,因此必须仔细设计它,以本地化故障并满足严格的可用性目标。
- Operationally, we have found live virtual machine migration [5, 11, 18, 30] to be a requirement for both overall availability and for feature velocity of our infrastructure
4. 在操作上,我们发现实时虚拟机迁移是我们基础设施的总体可用性和功能速度的要求。实时迁移有许多严格的要求,包括从一个物理服务器迁移到另一个物理服务器期间的数据包传递,以及最小化任何性能降级的持续时间。
- Use of GCP is growing rapidly, both in the number of virtual networks and the number of VMs per network
5.在虚拟网络数量和每个网络的虚拟机数量方面,GCP的使用正在迅速增长。
一个重要的考虑是控制平面的可伸缩性,与小型网络相比,大型网络面临三个挑战:它们需要更大的路由表,路由表必须更广泛地分发,而且它们往往具有更高的流失率,控制平面必须能够支持有几万甚至几十万个虚拟机的网络。
其次,低编程延迟对于自动缩放和故障转移非常重要。
此外,快速提供大型网络的能力使运行大规模工作负载(如MapReduce)成为可能,这些工作负载的成本低、速度快、按需运行。
2.2 Design Overview
我们的一般设计方法围绕分层数据和控制平面。
控制平面是围绕一个全局层次结构和整个云集群管理层设计的。例如,配置Andromeda只是配置计算、存储、访问控制等众多配置中的一个步骤,为了隔离,我们在每个集群中运行单独的控制堆栈。群集是具有统一网络连接且共享同一硬件故障域的共站计算机的集合。Andromeda控制平面维护有关网络中每个虚拟机当前运行位置的信息,以及所有更高级别的产品和基础结构状态,如防火墙、负载平衡器和路由策略,控制平面通过控制器的层次结构在各个服务器中安装此状态的选定子集。
数据平面由一组灵活的用户空间分组处理路径组成。VM主机快速路径是数据平面层次结构中的第一个路径,并在灵活性上以原始性能为目标。快速路径的每包CPU预算为300ns,实现这一目标需要限制快速路径工作的复杂性和处理分组所需的快速路径状态的数量,在快速路径上端到端地处理高性能、延迟关键流,Andromeda将其他流从快速路径转发到悬停板或协处理器进行额外处理。在主机软件上,在每个虚拟机浮动线程中运行的协处理器执行CPU密集型或无严格延迟目标的每个数据包工作,协处理器将特性增长与快速路径性能分离开来,提供隔离、易于编程和可伸缩性。
Andromeda将与VM主机上的流规则不匹配的数据包发送到悬停板,即执行虚拟网络路由的专用网关。控制平面根据当前的通信模式动态地仅选择要安装在VM主机上的活动流,悬停板处理大部分空闲流的长尾。由于在网络通信中,通常只需要一小部分可能的VM对,因此在单个VM主机上只需要一小部分网络配置,避免在每台主机上安装完整的转发信息,可以将每台服务器的内存利用率和控制平面的CPU可伸缩性提高一个数量级以上。
3 Control Plane:
The Andromeda control plane consists of three layers:
-
Cluster Management (CM) Layer: The CM layer provisions networking, storage, and compute resources on behalf of users
-
Fabric Management (FM) Layer: The FM layer exposes a high-level API for the CM Layer to configure virtual networks
-
Switch Layer: In this layer, two types of software switches support primitives such as encapsulation, forwarding, firewall, and load balancing
仙女座控制平面由三层组成:
集群管理(CM)层:CM层代表用户提供网络、存储和计算资源。这个层不是特定于网络的,超出了本文的范围。
结构管理(FM)层:FM层公开一个高级API,供CM层配置虚拟网络。API表达用户意图并抽象实现细节,例如编程交换机的机制、封装格式和负责特定功能的网络元素。
交换层:在这个层中,有两种类型的软件交换机支持原语,如封装、转发、防火墙和负载平衡。每个VM主机都有一个基于Open vSwitch的虚拟交换机,它处理主机上所有VM的通信。悬停板是独立的交换机,充当某些流的默认路由器。
3.1 FM Layer
当CM层连接到FM控制器时,它发送包含集群的完整FM配置的完整更新,后续更新与都会发送不同的配置。FM配置由一组具有已知类型、唯一名称和定义实体属性的参数的实体组成。
图2列出了FM实体的一些示例。

FM API由多种类型的控制器实现,每种控制器负责不同的网络设备集。
目前,VM控制器(VMC)为VM主机和悬停板编程,而负载平衡控制器为负载平衡器编程。本文以VMCs为研究对象。
VMCs程序VM主机交换机使用OpenFlow和专有扩展的组合。
VMCs通过OpenPC向OpenFLASH前端(OFES)发送OpenFULL请求,这是ONIX启发的体系结构。OFES将这些请求转换为OpenFlow,OFES将控制器架构与OpenFlow协议分离。由于OFES维护的内部状态很少,所以它们也可以作为VM主机交换机的稳定控制点,每个交换机都有一个稳定的OFE连接,而不考虑控制器升级或重新分区。
OFES将交换机事件发送到VMC,例如当交换机连接到VMC时,或为新VM添加虚拟端口时。VMCs通过综合抽象FM编程和交换机事件中报告的物理信息,为交换机生成OpenFlow编程。当通知VMC交换机已连接时,它通过OFE读取交换机的状态,将其与VMC所期望的状态进行比较,并发出更新操作以解决任何差异,从而协调交换机的OpenFlow状态。
3.2 Switch Layer
交换机层在每个VM主机上都有一个可编程的软件交换机,还有一个叫做悬停板的软件交换机,它运行在专用机器上。悬停板和主机交换机运行用户空间数据平面,并共享用于构建高性能数据包处理器的通用框架。这些数据平面绕过主机内核网络堆栈,通过各种技术实现高性能。
我们使用了一个改进的Open-vSwitch作为Andromeda的VM主机交换机的控制部分。名为vSwitchd的用户空间进程从OFE接收OpenFlow编程,并对数据路径进行编程。数据平面包含一个流缓存,并将缓存中丢失的数据包发送到vSwitchd。vSwitchd在其OpenFlow表中查找流并插入一个缓存项。
扩展模块添加了OpenFlow中不易表达的功能。这些扩展包括连接跟踪防火墙、计费、粘性负载平衡、安全令牌验证和广域网带宽实施。
3.3 Scalable Network Programming
在Andromeda的设计和演进过程中,我们面临的一个关键问题是,如何为理论上可以扩展到数百万个虚拟机的单个虚拟网络保持正确的转发行为。传统网络大量地利用地址聚合和物理局部性来扩展转发行为的编程。相比之下,Andromeda将虚拟地址和物理地址分离,这提供了许多好处,包括对虚拟网络的灵活寻址,以及在物理基础设施中透明地迁移VMS的能力。然而,这种灵活性是以成本为代价的,特别是在缩放控制平面方面。
以下三种模型之一通常用于对软件定义的网络进行编程:
-
预编程模型:控制平面对网络中从每个虚拟机到每个虚拟机的转发规则进行全网格编程。此模型提供一致且可预测的性能,然而控制平面开销与网络大小成二次关系,虚拟网络拓扑结构的任何变化都需要将状态传播到网络中的每个节点。
-
按需模型:流的第一个包被发送到控制器,控制器对所需的转发规则进行编程。这种方法比预先编程的模型具有更好的伸缩性,然而流的第一个包具有明显更高的延迟。此外,该模型对控制平面的中断非常敏感,更糟的是,它使控制平面暴露于来自VM的意外或恶意数据包洪水中,虽然限制费率可以缓解这种洪灾,但同时保持租户之间的公平性和隔离性是很复杂的。
-
网关模型:VMS将特定类型的所有数据包(例如,所有发往Internet的数据包)发送到网关设备,该设备专为高速数据包处理而设计。该模型提供了可预测的性能和控制平面可伸缩性,因为虚拟网络状态的变化需要与少量网关进行通信。缺点是网关的数量需要随着网络的使用而扩展,更糟糕的是,需要为峰值带宽使用量配置网关,我们发现峰值到平均带宽需求最多可以变化100倍,这使得高效地配置网关容量成为一个挑战。
3.3.1 Hoverboard Model
Andromeda最初使用预先编程的模型进行VM-VM通信,但是我们发现很难扩展到大型网络。此外,预先编程的模型不支持敏捷性——快速提供基础设施的能力——这是按需批量计算的关键要求。
为了应对这些挑战,我们引入了Hoverboard模型,它结合了随需应变模型和网关模型的优点。
仙女座虚拟机主机堆栈将其没有路由的所有数据包发送到具有所有虚拟网络转发信息的悬停板网关。但是,与网关模型不同,控制平面动态检测超过指定使用阈值的流和程序卸载流,这些流是绕过悬停板的主机到主机的直接流。图3显示了使用悬停板作为默认路由器的流,以及控制平面为其编程了直接主机到主机路由并将其从悬停板卸载的流。
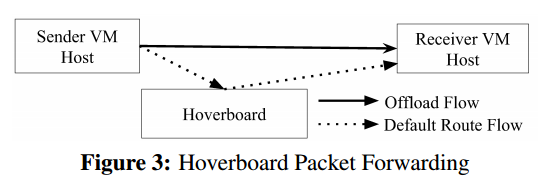
控制平面根据来自发送VM主机的使用情况报告检测这些高带宽流。为了稳健性,我们不依赖于悬停板本身的使用报告:如果悬停板过载,它们可能无法发送此类报告,因此控制平面将无法安装卸载流以减少负载。
悬停板模型避免了其他模型的陷阱。它是可扩展且易于提供的:我们的评估表明,流量带宽的分布趋向于高度倾斜,因此由控制平面安装的少量卸载流将集群中的绝大多数流量从悬停板转移开。此外,与按需模式不同,所有数据包都由为低延迟而设计的高性能数据路径处理。
3.4 Transparent VM Live Migration
我们选择了一种高性能的基于软件的体系结构,而不是像SR-IOV那样的硬件唯一解决方案,因为软件能够实现灵活、高速的特征部署。虚拟机实时迁移很难用SR-IOV透明地部署,因为来宾需要处理迁移目标主机上的不同物理NIC资源。实时迁移使得将正在运行的虚拟机移动到不同的主机上成为可能,以便于维护、升级和布局优化。
迁移实际上对VM是透明的:VM继续看到相同的虚拟以太网设备,Andromeda确保网络连接不会中断。VM在迁移中断阶段暂停,中间持续时间为65ms,第99百分位为388ms。中断后,VM在目标主机上恢复执行。
3.5 Reliability
仙女座控制平面的设计是高度可用的。为了容忍机器故障,每个VMC分区由一个选定的主分区和两个备用分区组成。图4显示了具有四个复制VMC分区的集群的Andromeda实例。
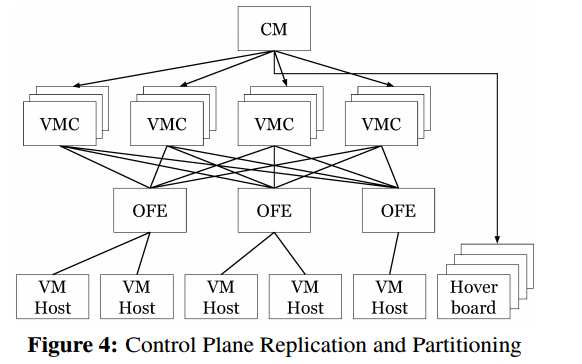
我们发现以下原则对于设计可靠的全球网络控制平面非常重要:
-
作用域控制平面:Andromeda编程的网络可以是全局的,因此集群控制平面必须接收所有其他集群中VM的更新。
-
网络隔离:一个客户网络中的搅动不应影响其他网络的网络编程延迟
-
静态失效:控制平面的每一层都被设计成静态失效
4 VM Host Dataplane
图5展示了Andromeda虚拟机主机数据平面
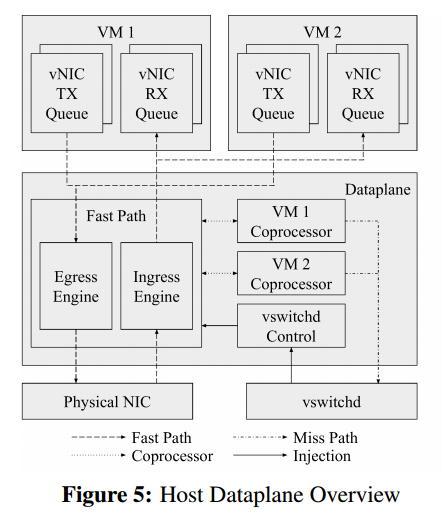
数据平面是一个用户空间进程,它执行主机上的所有VM数据包处理,同时结合了虚拟NIC和虚拟交换机功能。
有两个主要的数据平面数据包处理路径:快速路径和协处理器路径。快速路径通过流表执行高性能的包处理工作,例如封装和路由。协处理器路径执行CPU密集型或没有严格延迟要求(如WAN数据包加密)的数据包工作。
每个虚拟机都由用户空间虚拟机管理器(VMM)管理,每个虚拟机有一个VMM。VMM向Andromeda数据平面发送RPC,以执行映射来宾VM内存、配置虚拟NIC中断和卸载以及附加虚拟NIC队列等操作。
快速路径维护转发状态和相关分组处理动作的高速缓存,当包在快速路径缓存中丢失时,它被发送到主机上的vSwitchd,该vSwitchd保持VMC编程的完全转发状态,vSwitchd发送流缓存更新指令并将数据包重新注入快速路径。
快速路径的一个关键目标是提供高吞吐量、低延迟的虚拟机网络。为了提高性能在专用逻辑CPU上轮询,物理核心上的另一个逻辑CPU运行低CPU控制平面工作,例如RPC处理,将大部分物理核心留给快速路径使用。快速路径可以用一个CPU每秒处理超过300万个小数据包,相当于每个数据包的CPU预算为300ns。快速路径可以使用多队列NIC扩展到多个CPU。
4.1 Principles and Practices
我们的整体数据平面设计理念是灵活的,高性能的软件与硬件卸载相结合。高性能软件数据平面可以提供与底层硬件不可区分的性能。我们提供足够的快速路径CPU来实现吞吐量目标,在每个平台上利用硬件卸载来最小化所需的快速路径CPU。目前,我们使用Intel QuickData DMA引擎卸载加密、校验和和内存副本。我们正在调查更多的硬件卸载。
软件数据平面允许在具有不同NIC和硬件负载的异构硬件上运行的客户使用统一的功能集和性能配置文件。这种一致性使跨异构硬件的透明实时迁移成为可能。一个网络在软件或硬件中是否有、有部分或全部功能将成为每个平台的详细信息。主机上的软件是可扩展的,支持快速的发布速度,并可扩展到大量的状态。一个完整的SR-IOV硬件方法需要专用的中间盒来处理新特性或超出硬件表的限制,这种中间盒增加了延迟、成本、故障率和操作开销。
为了在软件中获得高性能,快速路径设计最小化了快速路径特性。我们添加到快速路径的每个功能都有成本,并且消耗每个包的CPU预算。只有性能关键的低延迟工作才属于快速路径。CPU密集型或不具有严格延迟要求的工作(例如特定于群集间或Internet通信量的工作)属于协处理器路径。我们的设计也尽量减少每流工作,所有VM数据包都经过快速路径路由流表,我们可以通过使用流键字段对每个流工作进行预计算来进行优化。例如,Andromeda在流插入期间计算一个高效的每流防火墙分类器,而不是要求为每个数据包提供昂贵的完整防火墙规则集匹配。
4.2 Fast Path Design
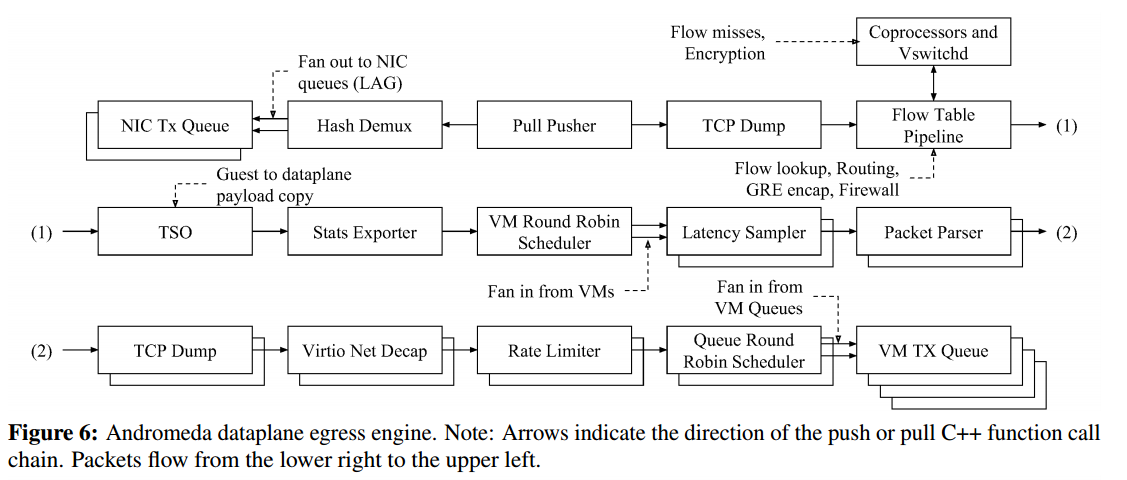
快速路径执行性能关键的VM流(如集群内VM-VM)所需的数据包处理操作。快速路径由用于数据包处理的独立入口和出口引擎以及其他周期性工作组成,例如轮询来自控制线程的命令。引擎由一组可重用的、连接的数据包处理推拉元素组成,这些元素受Click的启发,元素通常执行单个任务并操作一批数据包(入口最多128个数据包,出口最多32个数据包)。
图6和图7概述了仙女座快速通道引擎的元素和队列
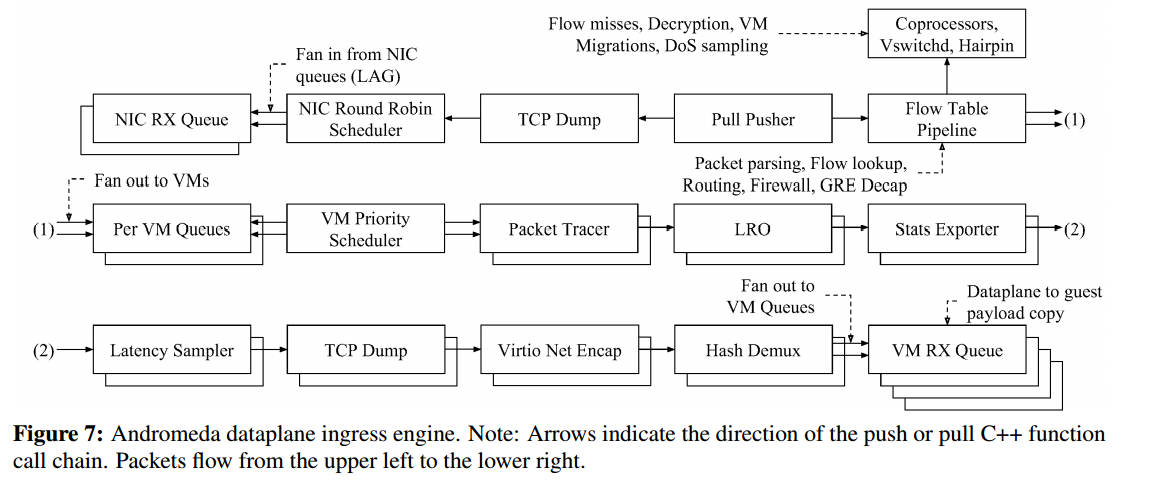
4.3 Fast Path Flow Table
所有VM数据包都通过引擎流表(FT)进行路由和每流数据包操作,如封装。
为了避免代价高昂的同步,FT不使用锁,并且从不被引擎修改。
当包通过FT发送时,FT计算包的流密钥,在流索引表中查找密钥,然后应用指定的流操作和任何启用的快速路径包阶段,最后更新统计信息。
4.3.1 Middlebox Functionality
Andromeda在主机上提供防火墙、负载平衡和NAT等中间盒功能。与传统的专用电器中间件相比,该方法实现了更高的性能和降低了配置复杂度。
快速路径功能的一个例子是始终在线的连接跟踪防火墙。传统防火墙需要对每个数据包进行防火墙规则查找和连接跟踪表查找,这两种方法都很昂贵。为了最小化每个流的工作,vSwitchd分析流未命中的规则,以便最小化快速路径必须执行的工作量。如果流中的IP地址和协议总是允许双向的,那么在快速路径中不需要防火墙工作。否则,vSwitchd启用防火墙阶段并计算流防火墙策略,该策略指示流IP允许的端口范围。快速路径根据这些端口范围匹配数据包,这比评估完整防火墙策略快得多。此外,如果包连接5元组在两个方向都被防火墙规则允许,则防火墙阶段跳过连接跟踪,这是VM-VM和服务器流的常见情况。
4.4 Coprocessor Path
协处理器路径实现CPU密集型或没有严格延迟要求的功能。协处理器在最小化快速路径特性、将特性增长与快速路径性能分离方面起着关键作用。
协处理器阶段包括加密、拒绝服务、滥用检测和广域网流量整形。
快速路径FT查找确定为数据包启用的协处理器阶段。如果启用了协处理器级,则快速路径通过SPSC数据包环将数据包发送到相应的协处理器线程,必要时唤醒线程。协处理器线程应用为包启用的协处理器阶段,然后通过包环将包返回到快速路径。
5 Evaluation:
5.1 On-Host Resource Consumption
仙女座消耗了主机上CPU和内存的很少一部分,为仙女座数据平面保留了一个物理CPU核心。核心的一个逻辑CPU执行繁忙的轮询快速路径,另一个大部分空闲的逻辑cpu执行不频繁的后台工作,将核心的大部分共享资源留给快速路径逻辑CPU。
在未来,我们计划将数据平面CPU预留增加到具有更快的物理NIC和更多CPU核心的较新主机上的两个物理核心,以提高VM网络吞吐量。 Andromeda数据平面的最大内存使用目标是1GB,为了支持无中断升级和单独的数据平面生命周期管理守护进程,数据平面内存容器的总限制为2.5GB,vSwitchd和主机代理的组合内存限制为1.5gb。
5.2 Dataplane Performance
在仙女座的整个进化过程中,数据平面的性能都有了显著的提高。
Andromeda1.0包括一个优化的VMM包管道和一个修改的内核开放虚拟交换机(OVS),我们添加了虚拟网卡多队列和出口卸载。
Andromeda 1.5增加了入口虚拟网卡卸载,并通过将VMM中的冗余查找与内核OVS流表查找结合起来进一步优化了数据包管道,主机内核调度和c状态管理也得到了优化,改善了延迟。
Andromeda 2.0将先前的VMM和主机内核包处理整合到一个新的操作系统中,绕过了繁忙的用户空间轮询数据平面。
Andromeda2.1直接访问数据平面中的虚拟网卡环,绕过VMM。性能关键数据包由总线调用数据平面CPU端到端处理,无需线程切换。从包数据路径中消除VMM,消除了每个网络往返的四个线程唤醒,这大大改善了延迟和CPU效率。
在整个演进过程中,我们跟踪了许多性能指标。图8描绘了两个VM使用200个TVP流可以实现的相同集群吞吐量。
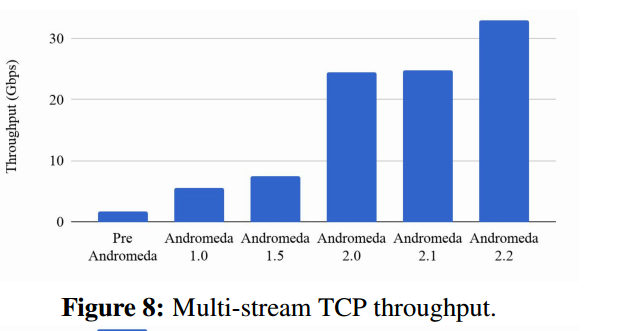
随着堆栈的发展,我们将吞吐量提高了19倍,将同一群集TCP往返延迟提高了7倍(图9)
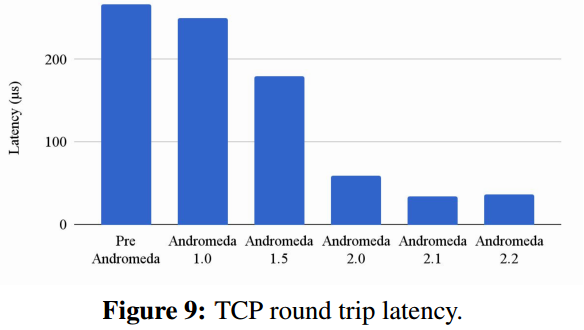
5.3 Control Plane Agility and Scale
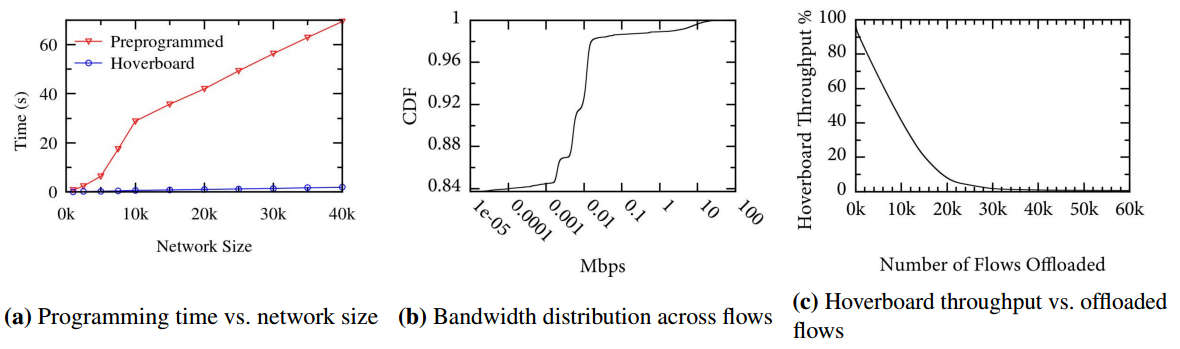
Andromeda 1.0对所有虚拟机-虚拟机流使用了预先编程的模型,最初支持多达2K个虚拟机的网络。在预编程模型下,即使是虚拟网络中的一个小变化,例如添加虚拟机,也需要更新网络中所有其他虚拟机的路由表。
我们随后开发了悬停板模型,使控制面板的可伸缩性和灵活性大大提高。使用悬停板,只要主机和悬停板被编程,新的虚拟机就具有网络连接。中位编程延迟——虚拟机控制器处理FM请求(例如,将虚拟机添加到网络)并通过OpenFlow编程适当的流规则所需的时间,从551毫秒降低到184毫秒,第99个百分位的延迟从3.7秒下降到576毫秒。此外,控制平面现在可以优雅地扩展到具有10万个虚拟机的虚拟网络。
悬停板模型的有效性是基于这样一个假设,即控制平面安装的少量卸载流可以捕获大部分流量,带长尾的小流量则通过悬停板。实际上,我们集群中的网络流遵循幂律分布,与先前的观察结果一致,例如[19]。图11b显示了生产集群中所有vm对的峰值吞吐量的cdf,在30分钟的窗口中测量。84%的虚拟机对从不通信:在悬停板模型中,这些流从不编程,它们的主机开销为零。98%的流的峰值吞吐量小于20kbps,因此在20kbps的卸载阈值下,悬停板将控制平面的可扩展性提高了50倍。
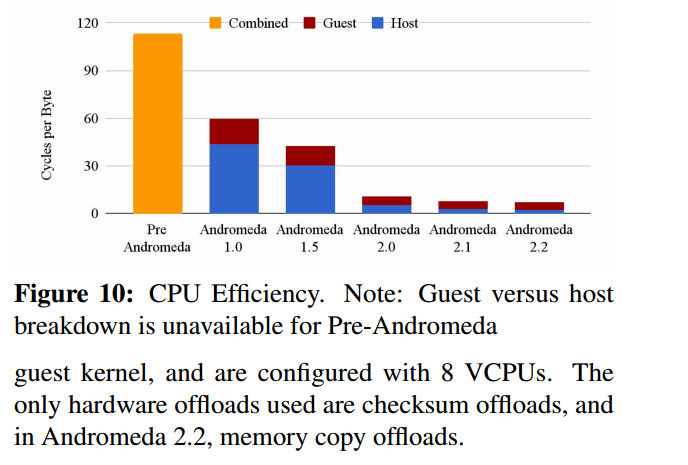
图11c显示了当我们编程更直接的主机到主机流时,通过悬停板网关的高峰流量。该图显示,通过将总共约50k个流(可能少于总流的0.1%)转移到终端主机,通过悬停板网关的峰值吞吐量将下降到不到群集带宽的1%。
6 Experiences:
本节描述了我们建造仙女座的经验,系统成长和发展过程中面临的挑战,以及我们如何应对这些挑战。
6.1 Resource Management
-
6.1.1 CPU Isolation
-
6.1.2 Guest VM Memory
-
6.1.3 Memory Provisioning
6.2 Velocity
-
6.2.1 Andromeda 1.0: Kernel Datapath
-
6.2.2 Andromeda 2.0: Userspace Datapath
6.3 Scaling and Agility
7 Related Work:
仙女座控制面板建立在大量软件定义的网络研究,OpenFlow和Open vSwitch的基础上,数据平面设计与Click、Softnic和DPDK中描述的概念重叠。
NVP是一个基于SDN的网络虚拟化堆栈,与Andromeda类似。NVP还使用Open vSwitch和OVS内核数据路径,类似于Andromeda 1.0。
NVP控制平面使用预先编程的模型(第3.3节),因此具有n个VM的网络将具有o(n 2)流。NVP通过使用分区和将控制平面划分为虚拟层和物理层来扩展。Andromeda也使用分区,但主要通过使用悬停板模型来解决缩放问题。
VFP是微软Azure的基于SDN的虚拟化主机堆栈,使用带有状态规则的分层匹配操作表模型。所有VFP特性都支持卸载到主机内核或sr-iov nic中实现的完全匹配的FastPath。
仙女座使用基于软件的层次化的用户空间分组处理路径。相对于VFP,协处理器支持对cpu密集型或没有严格延迟目标的特性进行快速迭代,并允许在快速路径之外以高性能构建这些特性。仙女座不依赖于将整个流卸载到硬件:我们证明了一个灵活的软件流水线可以实现与硬件竞争的性能。我们的快速路径支持三元组流查找,并最大限度地减少了有状态功能(如防火墙连接跟踪)的使用。虽然VFP的论文没有集中在控制平面上,但我们介绍了我们构建高度可伸缩、灵活和可靠的网络控制平面的经验和方法。
8 Conclusions:
本文介绍了Andromeda的设计原则和部署经验,Andromeda是Google云平台的网络虚拟化栈。
我们表明,操作系统旁路软件DataPath提供了与硬件竞争的性能,使用单核实现32.8gb/s。为了实现功能增长与FastPath性能的隔离和分离,我们在每个VM协处理器线程上执行CPU密集的包工作。
仙女座控制平面是为敏捷性、可用性、隔离性、特性速度和可扩展性而设计的。我们引入了悬停板,这使得在几秒钟内为数万个虚拟机编程连接成为可能。
最后,我们描述了我们部署Andromeda的经验,并解释了无中断升级和虚拟机实时迁移对于在基本上不影响客户的情况下引导生产中的主要体系结构转变是多么关键。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号