xpath的 text()和string() 区别
原文:https://www.cnblogs.com/CYHISTW/p/12312570.html
Xpath的text()与string(.)
我们在爬取网站使用Xpath提取数据的时候,最常使用的就是Xpath的text()方法,该方法可以提取当前元素的信息,但是某些元素下包含很多嵌套元素,
我们想一并的提取出来,这时候就用到了string(.)方法,但是该方法使用的时候跟text()不太一样,下面就举实例来讲解一下具体的区别。
实例网站:https://www.biedoul.com/wenzi/1/
例如
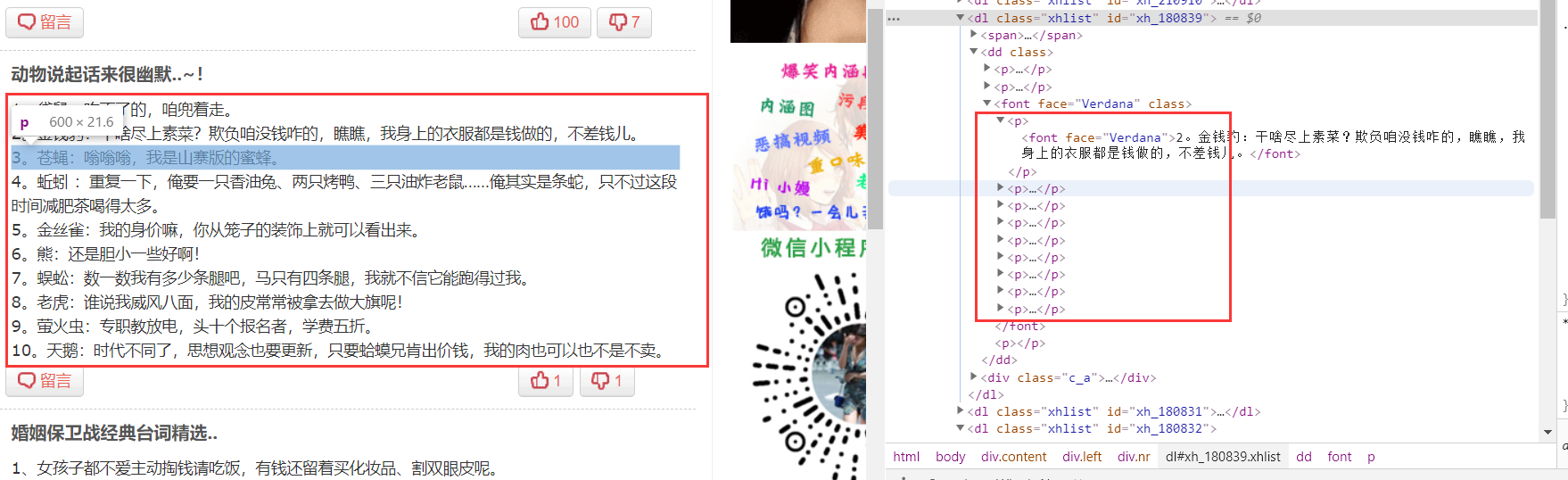
以这个段子为例,如果我们使用text()来拿取这个,会发现这一个段子竟然有11个text()信息,那么我们直接用text()来拿会怎么样呢?我们来看下结果
发现我们确实拿到了,可是我们却是拿到一个列表中的多个字符串,我们想合成一个还需要拼接,所以我们可以使用 string(.),来看看效果
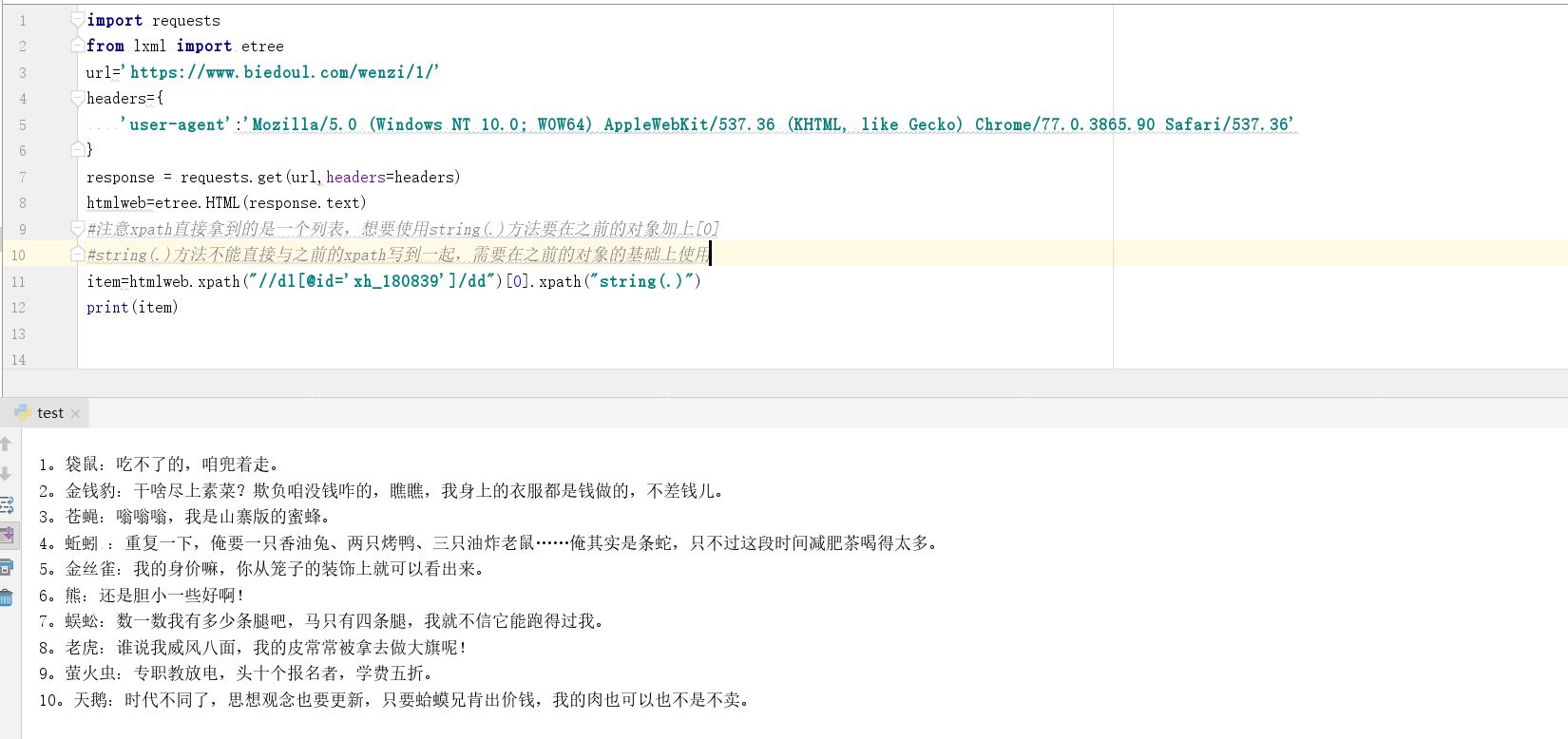
发现现在就是我们想要的结果了,因此当我们需要拿取嵌套节点的内容时候,使用string(.)方法效果更好
附上代码:

import requests
from lxml import etree
url='https://www.biedoul.com/wenzi/1/'
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
}
response = requests.get(url,headers=headers)
htmlweb=etree.HTML(response.text)
#注意xpath直接拿到的是一个列表,想要使用string(.)方法要在之前的对象加上[0]
#string(.)方法不能直接与之前的xpath写到一起,需要在之前的对象的基础上使用
item=htmlweb.xpath("//dl[@id='xh_180839']/dd")[0].xpath("string(.)")
print(item)
既然写到这里了就直接附上爬取整个网站的代码吧,网站比较简单,没事用来看看段子也还凑合
import requests
from lxml import etree
urllist=[]
#构造1000页的url
for i in range(1,1001):
urllist.append('https://www.biedoul.com/wenzi/'+str(i)+'/')
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
}
number=0
for url in urllist:
print('当前网站为'+str(url))
response=requests.get(url=url,headers=headers)
#使用xpath时候需要先用lxml转换一下内容
htmlweb=etree.HTML(response.content.decode())
items=htmlweb.xpath("//dl[@class='xhlist']")
#注意xpath拼接写法 要加上"."
for item in items:
print('*************************段子编号'+str(number)+'**************************************')
print('title:'+item.xpath(".//dd/a/strong/text()")[0])
#string(.)方法切记如何使用 可以获取节点下所有嵌套节点内容
print('content:'+item.xpath("./dd")[0].xpath("string(.)"))
number+=1
print('\n')
效果如图


 浙公网安备 33010602011771号
浙公网安备 33010602011771号