
mooc机器学习第七天-分类支持向量机svm.svc
1.函数简介
sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0, shrinking=True, probability=False,
Tol=0.001, cache_size200, class_weight=None, verbose=False, max_iter=-1,
decision_function_shape=None,random_state=None)
参数:
1、C:C-SVC的惩罚参数C默认值是1.0,C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
C一般可以选择为:0.0001 到10000,选择的越大,表示对错误例惩罚程度越大,可能会导致模型过拟合
2、kernel :核函数,默认是rbf,可以是'linear', 'poly', 'rbf', 'sigmoid', 'precomputed'
0 – 线性:u'v
1 – 多项式:(gamma*u'*v + coef0)^degree
2 – RBF函数:exp(-gamma|u-v|^2)
3 –sigmoid:tanh(gamma*u'*v + coef0)
数学表达式:
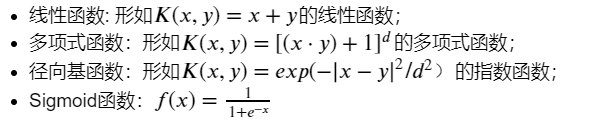
3、degree :多项式poly函数的维度,默认是3,选择其他核函数时会被忽略。建议设置为2;
4、gamma :'rbf','poly'和'sigmoid'的核系数。当前默认值为'auto',它使用1 / n_features,如果gamma='scale'传递,则使用1 /(n_features * X.std())作为gamma的值。当前默认的gamma''auto'将在版本0.22中更改为'scale'。
5、 coef0 :核函数的常数项。对于'poly'和 'sigmoid'有用。
6、probability :默认False。是否启用概率估计。必须在调用fit之前启用它,并且会减慢该方法的速度。
7、shrinking :默认为true,是否采用shrinking heuristic(收缩启发式)方法
8、 tol :默认为1e-3,停止训练的误差值大小,
9、cache_size :默认为200,核函数cache缓存大小
10、 class_weight :{dict,'balanced'}。将类i的参数C设置为SVC的class_weight [i] * C. 如果没有给出,所有类都应该有一个权重。"平衡"模式使用y的值自动调整与输入数据中的类频率成反比的权重n_samples / (n_classes * np.bincount(y))
11、verbose :默认False。启用详细输出。请注意,此设置利用libsvm中的每进程运行时设置,如果启用,则可能无法在多线程上下文中正常运行。
12、max_iter :最大迭代次数。-1为无限制。
13、decision_function_shape :'ovo', 'ovr' or None, default=None3
14、random_state :默认 无。伪随机数生成器的种子在对数据进行混洗以用于概率估计时使用。如果是int,则random_state是随机数生成器使用的种子; 如果是RandomState实例,则random_state是随机数生成器; 如果没有,随机数生成器所使用的RandomState实例np.random。
主要调节的参数有:C、kernel、degree、gamma、coef0。
与核函数相对应的libsvm参数建议:
1)对于线性核函数,没有专门需要设置的参数
2)对于多项式核函数,有三个参数。-d用来设置多项式核函数的最高此项次数,也就是公式中的d,默认值是3。-g用来设置核函数中的gamma参数设置,也就是公式中的第一个r(gamma),默认值是1/k(k是类别数)。-r用来设置核函数中的coef0,也就是公式中的第二个r,默认值是0。
3)对于RBF核函数,有一个参数。-g用来设置核函数中的gamma参数设置,也就是公式中的第一个r(gamma),默认值是1/k(k是类别数)。
4)对于sigmoid核函数,两个参数g以及r:gamma一般可选1 2 3 4,coef0选0.2 0.4 0.60.8 1
属性:
support_ :支持向量索引。
support_vectors_ :支持向量。
n_support_ :每一类的支持向量数目
dual_coef_ :决策函数中支持向量的系数
coef_ :赋予特征的权重(原始问题中的系数)。这仅适用于线性内核。
intercept_ :决策函数中的常量。
2.mooc实例简介

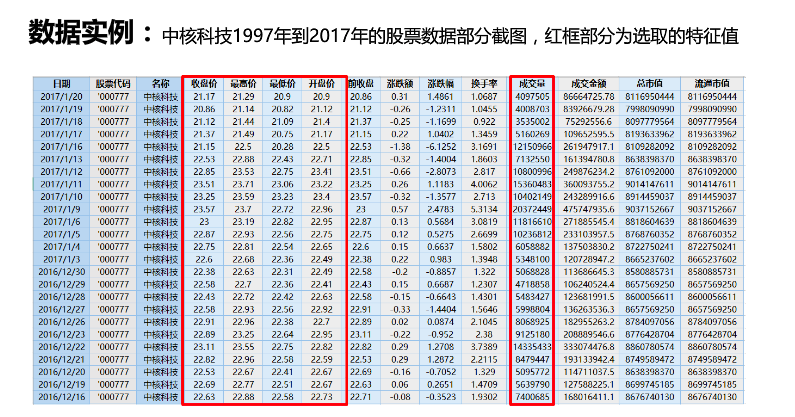


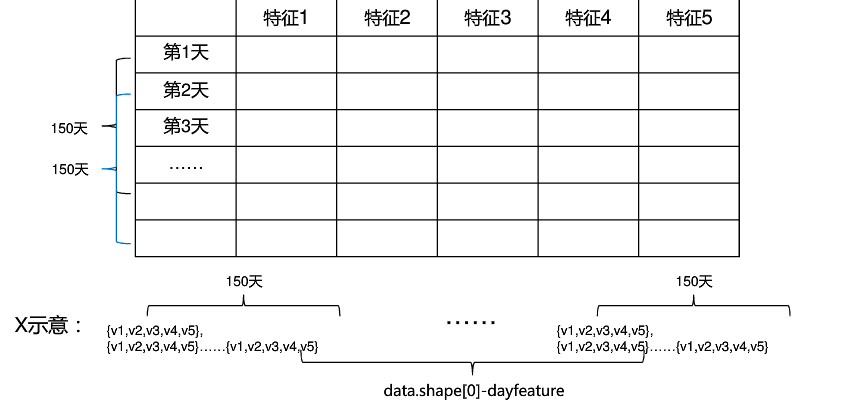



3.代码
import numpy as np
import pandas as pd
from sklearn import svm
from sklearn import cross_validation
data=pd.read_csv('。/stock/000777.csv',encoding='gbk',
parse_dates=[0],index_col=0)#读取数据,一点预处理
# print(data.head())
data.sort_index(0,ascending=True,inplace=True)
# print(data.head())
dayfeature=150
featurenum=5*dayfeature
# print(data.shape[0])
x=np.zeros((data.shape[0]-dayfeature-dayfeature,featurenum+1))
# print(x.shape)
y=np.zeros((data.shape[0]-dayfeature-dayfeature))
# print(data)
#利用range遍历花式索引取值判断赋值
for i in range(0,x.shape[0]):
x[i, 0:featurenum] = np.array(data[i:i + dayfeature] \
[[u'收盘价', u'最高价', u'最低价', u'开盘价', u'成交量']]).reshape((1, featurenum))
x[i, featurenum] = data.ix[i + dayfeature][u'开盘价']
for i in range(x.shape[0]):
if data.ix[i + dayfeature][u'收盘价'] >= data.ix[i + dayfeature][u'开盘价']:
y[i] = 1
else:
y[i] = 0
#调用算法,训练
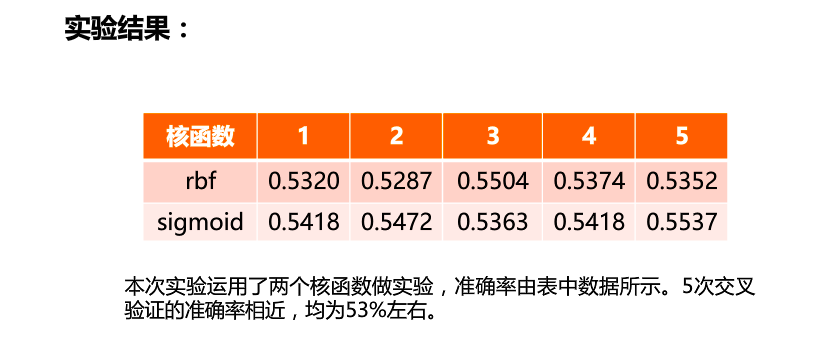
clf=svm.SVC(kernel='rbf')
result=[]
for i in range(5):
x_train,x_test,y_train,y_test=cross_validation.train_test_split(x,y,test_size=0.2)
clf.fit(x_train,y_train)
result.append(np.mean(y_test==clf.predict(x_test)))
print("svm classifier accuacy:")
print(result)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号