
mooc机器学习第三天- 聚类dbscan算法
考试周终于结束继续来学mooc~~
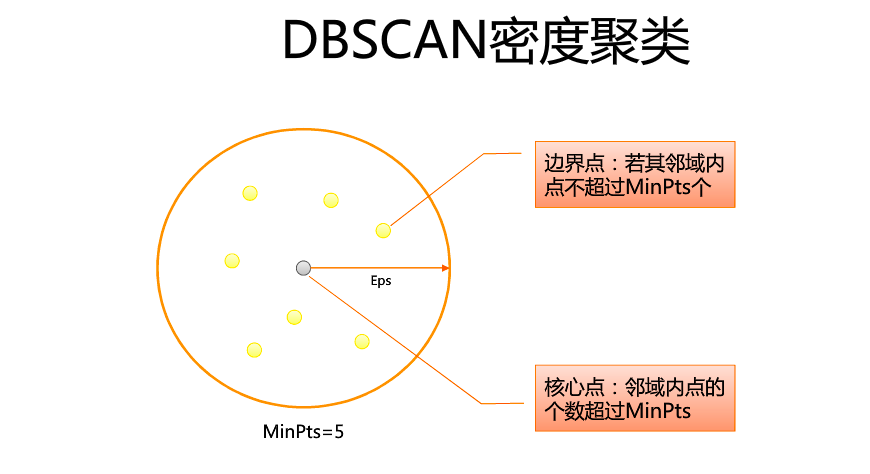
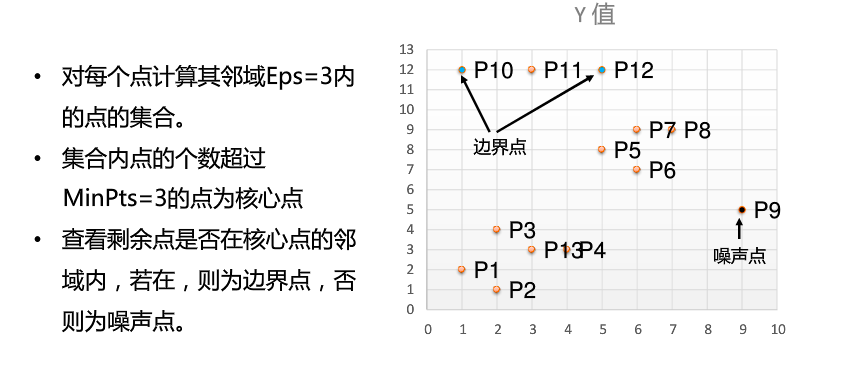
1.介绍







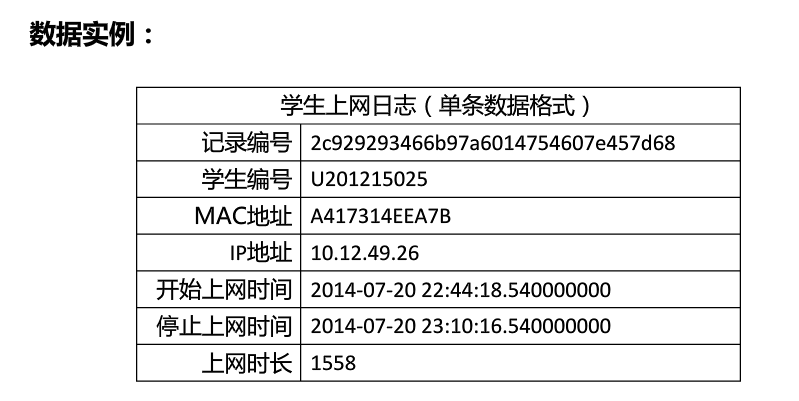
2.代码
import numpy as np
import sklearn.cluster as skc
from sklearn import metrics #距离计算方式
import matplotlib.pyplot as plt
mac2id = dict()
onlinetimes = []
f = open('/Users/helong/PycharmProjects/untitled1/'
'study/machine_learning/聚类/学生月上网时间分布-TestData.txt', encoding='utf-8')
for line in f:
mac = line.split(',')[2]
onlinetime = int(line.split(',')[6])
starttime = int(line.split(',')[4].split(' ')[1].split(':')[0])
if mac not in mac2id:
mac2id[mac] = len(onlinetimes)#每存入一个mac且完成计数
onlinetimes.append((starttime, onlinetime))
else:
onlinetimes[mac2id[mac]] = [(starttime, onlinetime)]
real_X = np.array(onlinetimes).reshape((-1, 2))#二维,2个element一行
# print(real_X)
X = real_X[:, 0:1]#取出开始时间且以reshape((-1,2))的组成形式([n]取一个数,[n:m]取的是一个维度形式)
# print(X)#因为使用的是曼哈顿算法,所以X必须是二维的点
db = skc.DBSCAN(eps=0.01, min_samples=20).fit(X)#eps核心点半径,min_samples簇的样本数
labels = db.labels_
print('Labels:')
print(labels)
print("*******")
# print(labels[:]==-1)#标签==-1的噪声数据作为条件
raito = len(labels[labels[:] == -1]) / len(labels)#噪声比例计算
print('Noise raito:', format(raito, '.2%'))
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)#计算簇的个数
print('Estimated number of clusters: %d' % n_clusters_)
print("Silhouette Coefficient: %0.3f" % metrics.silhouette_score(X, labels))
#打印个簇的标及簇内的数据
for i in range(n_clusters_):
print('Cluster ', i, ':')
plt.hist(X)
plt.show()
3.输出
Labels:
[ 0 -1 0 1 -1 1 0 1 2 -1 1 0 1 1 3 -1 -1 3 -1 1 1 -1 1 3 4
-1 1 1 2 0 2 2 -1 0 1 0 0 0 1 3 -1 0 1 1 0 0 2 -1 1 3
1 -1 3 -1 3 0 1 1 2 3 3 -1 -1 -1 0 1 2 1 -1 3 1 1 2 3 0
1 -1 2 0 0 3 2 0 1 -1 1 3 -1 4 2 -1 -1 0 -1 3 -1 0 2 1 -1
-1 2 1 1 2 0 2 1 1 3 3 0 1 2 0 1 0 -1 1 1 3 -1 2 1 3
1 1 1 2 -1 5 -1 1 3 -1 0 1 0 0 1 -1 -1 -1 2 2 0 1 1 3 0
0 0 1 4 4 -1 -1 -1 -1 4 -1 4 4 -1 4 -1 1 2 2 3 0 1 0 -1 1
0 0 1 -1 -1 0 2 1 0 2 -1 1 1 -1 -1 0 1 1 -1 3 1 1 -1 1 1
0 0 -1 0 -1 0 0 2 -1 1 -1 1 0 -1 2 1 3 1 1 -1 1 0 0 -1 0
0 3 2 0 0 5 -1 3 2 -1 5 4 4 4 -1 5 5 -1 4 0 4 4 4 5 4
4 5 5 0 5 4 -1 4 5 5 5 1 5 5 0 5 4 4 -1 4 4 5 4 0 5
4 -1 0 5 5 5 -1 4 5 5 5 5 4 4]
*******
Noise raito: 22.15%
Estimated number of clusters: 6
Silhouette Coefficient: 0.710
Cluster 0 :
[22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22]
Cluster 1 :
[23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23, 23]
Cluster 2 :
[20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20, 20]
Cluster 3 :
[21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21, 21]
Cluster 4 :
[8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8]
Cluster 5 :
[7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7]
# flatten()函数用法
#
# flatten是numpy.ndarray.flatten的一个函数,即返回一个一维数组。
#
# flatten只能适用于numpy对象,即array或者mat,普通的list列表不适用!。
#
# a.flatten():a是个数组,a.flatten()
# 就是把a降到一维,默认是按行的方向降 。
# a.flatten().A:a是个矩阵,降维后还是个矩阵,矩阵.A(等效于矩阵.getA())变成了数组。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号