爱根,logging模块和序列化模块!
logging模块
一、默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明
默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG),默认的日志格式
为日志级别:Logger名称:用户输出消息。
import logging
# debug info warning(默认) error critical #默认是从warning开始显示后面的配置信息。 #配置两种方式: 1 congfig 2 logger # 1 congfig函数
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有: filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。 filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 format:指定handler使用的日志显示格式。 datefmt:指定日期时间格式。 level:设置rootlogger(后边会讲解具体概念)的日志级别 stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 format参数中可能用到的格式化串: %(name)s Logger的名字 %(levelno)s 数字形式的日志级别 %(levelname)s 文本形式的日志级别 %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 %(filename)s 调用日志输出函数的模块的文件名 %(module)s 调用日志输出函数的模块名 %(funcName)s 调用日志输出函数的函数名 %(lineno)d 调用日志输出函数的语句所在的代码行 %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d 线程ID。可能没有 %(threadName)s 线程名。可能没有 %(process)d 进程ID。可能没有 %(message)s用户输出的消息
举例:
logging.basicConfig(level=logging.DEBUG, #设置显示等级是从debug开始的。 format="%(asctime)s [%(lineno)s] %(message)s", #显示格式是结构化时间--行号信息--配置信息 datefmt="%Y-%m-%d %H:%M:%S", #时间格式指定日期时间格式。 filename="logger", #文件名称,也可以指定路径。 filemode="a" #文件的读写模式。 ) logging.debug('debug message') #logging调用该项的配置信息。 num=1000 logging.info('cost %s'%num) logging.warning('warning messagegfdsgsdfg') # logging.error('error message') logging.critical('critical message') # 以上都是默认写入文件,在频幕上不显示。
二、logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接
口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。另外,
可以通过:logger.setLevel(logging.Debug)设置级别。
举例 # # 2 logger对象 def get_logger(): logger=logging.getLogger() #创建一个logger对象。 fh=logging.FileHandler("logger2") # 创建一个handler,用于写入日志文件 sh=logging.StreamHandler() # 再创建一个handler,用于输出到控制台 logger.setLevel(logging.DEBUG) #设定输出等级 fm=logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s") #设定显示格式 # datefmt = "%H:%M:%S %Y-%m-%d %H:%M:%S", # 时间格式指定日期时间格式。经实验,在这里没有用!!! logger.addHandler(fh) #交给对象在文件中显示的权限。 logger.addHandler(sh) #交给对象在频幕上显示的权限。 fh.setFormatter(fm) #在文件中显示的格式为设定的fm格式。 sh.setFormatter(fm) #在屏幕上显示的格式为设定的fm格式。 return logger #返回修改后的logger对象。 Logger=get_logger() Logger.debug('logger debug message') Logger.info('logger info message') Logger.warning('logger warning message') Logger.error('logger error message') Logger.critical('logger critical message')
1 启动端---使用端 2 3 import sys,os 4 5 6 base=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) 7 sys.path.append(base) 8 9 from log import loging 10 11 log_test=loging.get_logger("test") #logger=logging.getLogger(paths) 路径test 12 13 log_test1=loging.get_logger1("test1") #logger=logging.getLogger() 路径test1 14 15 # test_logger=loging.test_logger() #logger=logging.getLogger() 路径test 16 if __name__ == '__main__': 17 while True: 18 inp=input("输入要写的内容》》》") #test中出现两条,test1中也有一条,且不会递增 19 log_test.info(inp) 20 inp1=input("shuruyaoxiedeneirong") #test 和 test1 中各出现一条,且不会递增 21 log_test1.info(inp1) 22 # inp2=input("输入内容") 23 # test_logger.info(inp2) #test 和 test1 中各出现一条,且不会递增 24 25 #得出实验结果: 26 # logger = logging.getLogger() 的情况下,会出现该文件下会自动传参数 27 ## logger=logging.getLogger(paths) 要这么使用才行,不会重复,各自生成各自的对象。
2 使用端 import logging def get_logger(paths): logger=logging.getLogger(paths) #生成该路径下指定的logger对象 fh=logging.FileHandler(paths) #创建文件路径的对象 sh=logging.StreamHandler() #创建频幕输出的对象 logger.setLevel(logging.DEBUG) #设置输出等级 fm=logging.Formatter("%(asctime)s-%(name)s-%(levelname)s-%(message)s") #设置输出格式 logger.addHandler(fh) #给logger对象增加该属性 logger.addHandler(sh) fh.setFormatter(fm) #设置屏幕和日志的输出格式 sh.setFormatter(fm) return logger #返回logger对象 def get_logger1(paths): logger=logging.getLogger(paths) fh=logging.FileHandler(paths) sh=logging.StreamHandler() logger.setLevel(logging.DEBUG) fm=logging.Formatter("%(asctime)s-%(name)s-%(levelname)s-%(message)s") logger.addHandler(fh) logger.addHandler(sh) fh.setFormatter(fm) sh.setFormatter(fm) return logger def test_logger(): logger=logging.getLogger() fh=logging.FileHandler("test") sh=logging.StreamHandler() logger.setLevel(logging.DEBUG) fm=logging.Formatter("%(asctime)s-%(name)s-%(levelname)s-%(message)s") logger.addHandler(fh) logger.addHandler(sh) fh.setFormatter(fm) sh.setFormatter(fm) return logger
jason
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
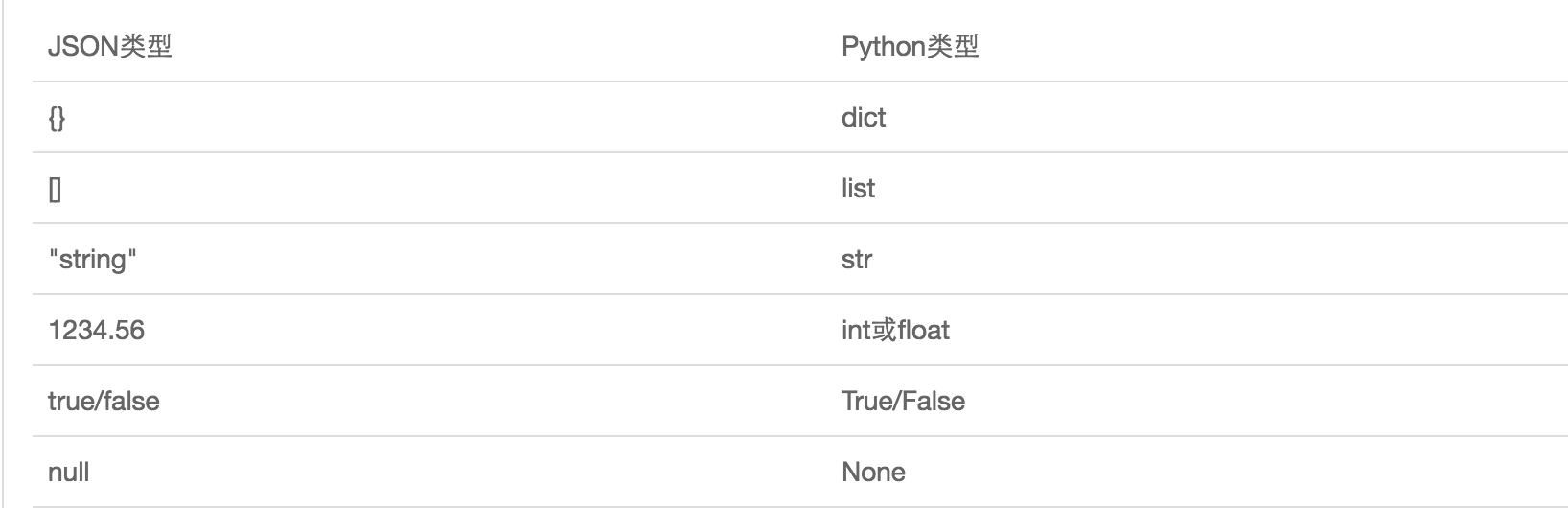
JSON表示的对象就是标准的JavaScript语言的对象一个子集,JSON和Python内置的数据类型对应如下:
# d={"河北":["廊坊","保定"],"湖南":["长沙","韶山"]} # # s=str(d) # with open("data","w") as f: # f.write(s) # with open("data") as f2: # s2=f2.read() # d2=eval(s2) # print(d2["河北"]) # '{"河北":["廊坊","保定"],"湖南":["长沙","韶山"]}' # print(eval("12+34*34")) import json # i=10 # s='hello' # t=(1,4,6) # l=[3,5,7] # d={'name':"yuan"} # # json_str1=json.dumps(i) # json_str2=json.dumps(s) # json_str3=json.dumps(t) # json_str4=json.dumps(l) # json_str5=json.dumps(d) # # print(json_str1) #'10' # print(json_str2) #'"hello"' # print(json_str3) #'[1, 4, 6]' # print(json_str4) #'[3, 5, 7]' # print(json_str5) #'{"name": "yuan"}' # d={'name':"egon"} # s=json.dumps(d) # 将字典d转为json字符串---序列化 # print(type(s)) # print(s) # f=open("new",'w+') # f.write(s) # # f.flush() # print(f.read()) # f.close() # -------------- dump方式 # f=open("new2",'w') # json.dump(d,f)#---------1 转成json字符串 2 将json字符串写入f里 # f.close() # -----------------反序列化loads一步读取。 # f=open("new") # data=f.read() # data2=json.loads(data) # print(data2["name"]) #------练习 # f=open("new3") # data=f.read() # ret=json.loads(data) # # ret=[123] # print(type(ret[0])) # print(ret)
1 import json
2 with open("a.json","w") as file: #打开一个名为jsondata.json文本,只能写入状态 如果没有就创建
3 json.dump("asfsaewegfgdgdfvdrew",file) #data转换为json数据格式并写入文件
4 file.close()#关闭文件
5 with open("a.json","r") as file:#打开文本读取状态
6 l = json.load(file) #解析读到的文本内容 转为python数据 以一个变量接收
7 print(l) #打印变量
8 file.close() #关闭文件
pickle import pickle # import datetime # t=datetime.datetime.now() # d={"data":t} # json.dump(d,open("new4","w")) #无法转换,因为time模块是python内部的数据类型,jason是语言之间的类型。 d={"name":"alvin"} s=pickle.dumps(d) #转化成了二进制数据 print(s) #b'\x80\x03}q\x00X\x04\x00\x00\x00nameq\x01X\x05\x00\x00\x00alvinq\x02s.' print(type(s)) #<class 'bytes'> f=open('new5',"wb") f.write(s) f.close() f=open("new5","rb") data=pickle.loads(f.read()) #一步达成。但写入的时候必须是转化成二进制数据的类型。否则报错。 print(data)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号