找准目标
单一数字评估
构建机器学习系统时,通过设置一个单一数字评估指标(single-number evaluation metric),可以更为快速地判断出在经过几次调整后得到的不同结果里,哪个的效果要好些。
对于一个分类器,评价分类器性能的指标一般是分类的准确率(Accuracy),也就是正确分类的样本数和总样本数之比,它也就可以作为一个单一数字估计指标。例如之前的猫分类器的几个算法都是通过准确率作其性能好坏的标准。
对于二分类问题常用的评价指标是精确率(Precision)和召回率(Recall),将所关注的类作为正类(Positive),其他的类为负类(Negative),分类器在数据集上预测正确或不正确,4种情况出现的种数分别记为:
- TP(True Positive)——将正类预测为正类数
- FN(False Negative)——将正类预测为负类数
- FP(False Positive)——将负类预测为正类数
- TN(Ture Negative)——将负类预测为负类数
将精准率定义为:
召回率定义为:
而当遇到以下这种情况不好判别时,就需要采用F1度量(F1 Score)来判断两个分类器的好坏。
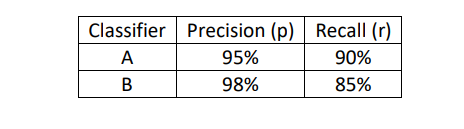
F1度量定义为:
F1度量值其实就是精准率和召回率的调和平均数(Harmonic Mean),它是一种基于其平均值改善的方法,比简单地取平均值效果要好。如此,算出上图种A分类器的F1度量值为92.4%,B分类器的为91.0%,从未得知A分类器效果好些。这里F1度量值就作为了单一数字评估指标。
满足、优化指标
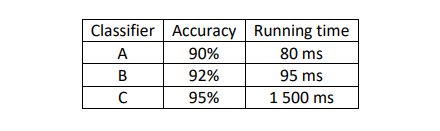
然而有时,评判的标准不限于一个单一数字评估指标。比如上图中的几个猫分类器,想同时关心它们各自的识别准确率和运行时间,但如果把这两个指标组合成一个单一数字评估指标的话,就不太好了。这时,就需要把一个指标作为优化指标(Optimizing Metric),而另外的一些的作为满足指标(Satisficing Metric)。
如上面所举的例子中,准确率就是一个优化指标,因为想要分类器尽可能做到正确分类,而运行时间就是一个满足指标,如果你想要分类器的运行时间不多于某个值,那你需要选择的分类器就应该是以这个值为界里面准确率最高的那个,以此作出权衡。
除了采用这些标准来评判一个模型外,也要学会在必要时及时地调整一些评判指标,甚至是更换训练数据。例如两个猫分类器A和B的识别误差分别为3%和5%,但是处于某种原因,A识别器会把色情图片误识为猫,引起用户的不适,而B不会出现这种情况,这时,识别误差大一些的B反而是更好的分类器。可以用以下公式来计算错误识别率:
还可以设置一个\(w^{(i)}\),当x^{(i)}是色情图片时,\(w^{(i)}\)为10,否则为1,以此来区分色情图片及其他误识别的图片:
所以要根据实际情况,正确确定一个评判指标,确保这个评判指标最优。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号