激活函数
激活函数
建立一个神经网络时,需要关心的一个问题是,在每个不同的独立层中应当采用哪种激活函数。
激活函数都是非线性的,原因在于使用线性的激活函数时,输出结果将是输入的线性组合,这样的话使用神经网络与直接使用线性模型的效果相当,此时神经网络就类似于一个简单的逻辑回归模型,失去了其本身的优势和价值。
Sigmoid函数
表达式
表达式为:
\[\sigma (z) = \frac{1}{{1 + {e^{ - z}}}}
\]
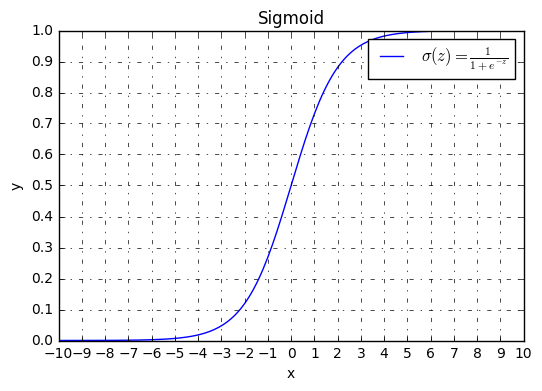
图像
函数图像为:
导数
\[\frac{d}{{dz}}\sigma(z) = \frac{1}{{1 + {e^{ - z}}}}(1 - \frac{1}{{1 + {e^{ - z}}}}) = \sigma(z)(1 - \sigma(z))
\]
- 当z=10或者z=-10的时:\(\frac{d}{{dz}}\sigma(z) \approx 0\)
- 当z=0时:\(\frac{d}{{dz}}\sigma(z) = \sigma(z)(1 - \sigma(z)) = \frac{1}{4}\)
双曲正切函数
表达式
tanh函数(Hyperbolic Tangent Function,双曲正切函数)的表达式为:
\[tanh(z) = \frac{e^z - e^{-z}}{e^z + e^{-z}}
\]
图像
函数图像为:
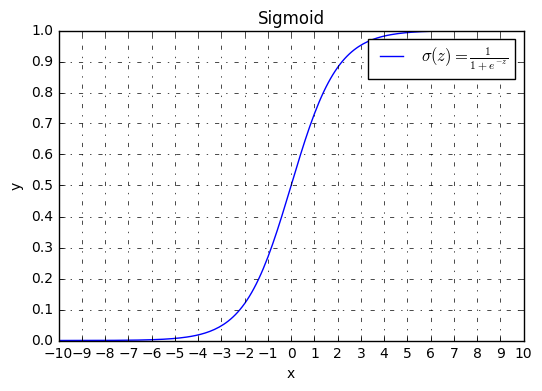
- tanh函数其实是sigmoid函数的移位版本。对于隐藏单元,选用tanh函数作为激活函数的话,效果总比sigmoid函数好,因为tanh函数的值在-1到1之间,最后输出的结果的平均值更趋近于0,而不是采用sigmoid函数时的0.5,这实际上可以使得下一层的学习变得更加轻松。但是对于二分类问题,为确保输出在0到1之间,将仍然采用sigmiod函数作为输出的激活函数。
- sigmoid函数和tanh函数都具有的缺点之一是,在z接近无穷大或无穷小时,这两个函数的导数也就是梯度变得非常小,此时梯度下降的速度也会变得非常慢。
导数
\[\frac{d}{{dz}}tanh(z) = 1 - {(\tanh (z))^2}
\]
- 当z=10或者z=-10的时:\(\frac{d}{{dz}}tanh(z) \approx 0\)
- 当z=0时:\(\frac{d}{{dz}}tanh(z) = 1 - (0) = 1\)
ReLU函数
表达式
ReLU函数也称为线性修正单元也是机器学习中常用到的激活函数之一,它的表达式为:
\[g(z) = max(0,z) =\begin{cases} 0, & \text{($z$ $\le$ 0)} \\ z, & \text{($z$ $\gt$ 0)} \end{cases}
\]
图像
函数图像为:
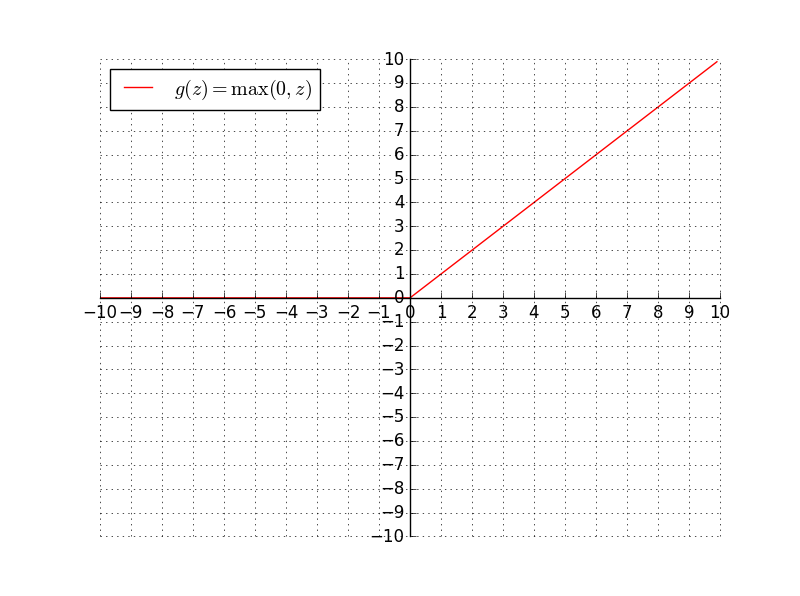
- 当z大于0时是,ReLU函数的导数一直为1,所以采用ReLU函数作为激活函数时,随机梯度下降的收敛速度会比sigmoid及tanh快得多,但负数轴的数据都丢失了。
导数
\[\frac{d}{{dz}}g(z) = \left\{ \begin{array}{l}
0\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;if\;\;z\; < 0\;\\
1\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;if\;\;z\; > 0\;\\
undefined\;\;\;\;\;if\;\;z\; = \;0
\end{array} \right.
\]
Leaky-ReLU函数
表达式
Leaky-ReLU函数是ReLU函数的修正版本,其表达式为:
\[g(z) = max(0,z) =\begin{cases} \alpha z, & \text{($z$ $\le$ 0)} \\ z, & \text{($z$ $\gt$ 0)} \end{cases}
\]
图像
函数图像为:
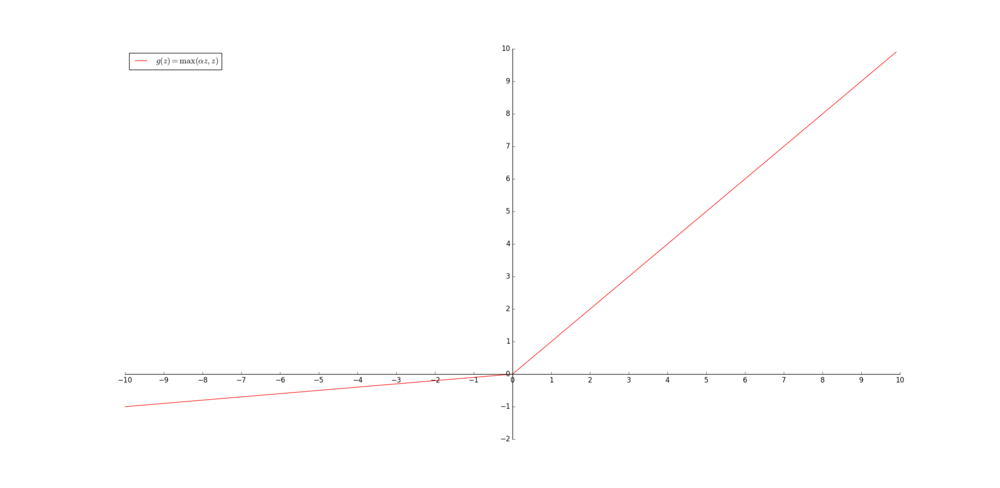
- 其中α是一个很小的常数,用来保留一部非负数轴的值。
导数
\[\frac{d}{{dz}}g(z) = \left\{ \begin{array}{l}
0.01\;\;\;\;\;\;\;\;\;\;\;\;\;if\;\;z\; < 0\;\\
1\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;if\;\;z\; > 0\;\\
undefined\;\;\;\;\;if\;\;z\; = \;0
\end{array} \right.
\]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号