20-IO编程
文件读写
打开文件对象
磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序直接操作磁盘,所以,读写文件就是请求操作系统打开一个文件对象(通常称为文件描述符),然后,通过操作系统提供的接口从这个文件对象中读取数据(读文件),或者把数据写入这个文件对象(写文件)。
打开一个文件对象,使用python内置的open()函数,传入文件名和标示符:
file object = open(file_name [, access_mode][, buffering])
file_name:file_name参数是一个字符串值,指定要访问的文件的名称。
access_mode:access_mode确定文件打开的模式,即读取,写入,追加等。
buffering:如果buffering值设置为0,则不会发生缓冲。如果缓冲值buffering为1,则在访问文件时执行行缓冲。如果将缓冲值buffering指定为大于1的整数,则使用指定的缓冲区大小执行缓冲操作。如果为负,则缓冲区大小为系统默认值(默认行为)。
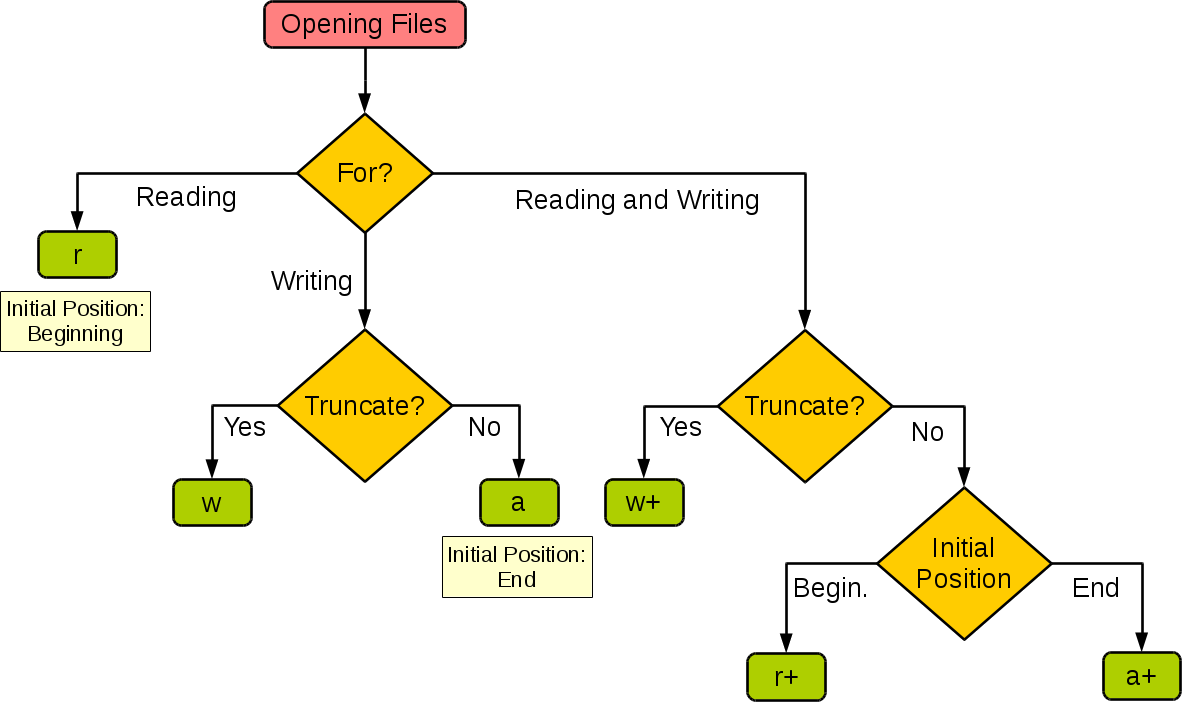
不同模式打开文件的完全列表:

模式如下图所示:
操作文件对象的方法
假设已经创建了一个称为 f 的文件对象,新建一个test.txt,其内容如下:
hello,world!
this is a test file.
f.read()
为了读取一个文件的内容,调用 f.read(size), 这将读取一定数目的数据, 然后作为字符串或字节对象返回。
size 是一个可选的数字类型的参数。 当 size 被忽略了或者为负, 那么该文件的所有内容都将被读取并且返回。
f = open("./test.txt","r")
str = f.read()
print(str)
执行结果:
hello,world!
this is a test file.
f.readline()
f.readline() 会从文件中读取单独的一行。换行符为 '\n'。f.readline() 如果返回一个空字符串, 说明已经已经读取到最后一行。
f = open("./test.txt","r")
str = f.readline()
print(str)
str = f.readline()
print(str)
执行结果:
hello,world!
this is a test file.
f.readlines()
f.readlines() 将返回该文件中包含的所有行。
f = open("./test.txt","r")
str = f.readlines()
print(str)
执行结果:
['hello,world!\n', 'this is a test file.']
f.tell()
f.tell() 返回文件对象当前所处的位置, 它是从文件开头开始算起的字节数。
f.seek()
如果要改变文件当前的位置, 可以使用 f.seek(offset, from_what) 函数。
from_what 的值, 如果是 0 表示开头, 如果是 1 表示当前位置, 2 表示文件的结尾,例如:
- seek(x,0) : 从起始位置即文件首行首字符开始移动 x 个字符
- seek(x,1) : 表示从当前位置往后移动x个字符
- seek(-x,2):表示从文件的结尾往前移动x个字符
from_what 值为默认为0,即文件开头。
f.write()
f.write(string) 将 string 写入到文件中, 然后返回写入的字符数。
f.close()
在文本文件中 (那些打开文件的模式下没有 b 的), 只会相对于文件起始位置进行定位。
当你处理完一个文件后, 调用 f.close() 来关闭文件并释放系统的资源,如果尝试再调用该文件,则会抛出异常。
当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。
with 关键字
当处理一个文件对象时, 使用 with 关键字是非常好的方式。在结束后, 它会帮你正确的关闭文件。
with open('//test.txt', 'r') as f:
read_data = f.read()
操作文件和目录
操作文件和目录的函数一部分放在os模块中,一部分放在os.path模块中。
查看当前目录的绝对路径:
import os
import os.path
dir = os.path.abspath('.')
print(dir)
常用函数
os.mkdir()
创建一个目录
os.rmdir()
删除一个目录
os.path.join()
把两个路径合成一个时,不要直接拼字符串,而要通过os.path.join()函数,这样可以正确处理不同操作系统的路径分隔符。在Linux/Unix/Mac下,os.path.join()返回这样的字符串:
part-1/part-2
而Windows下会返回这样的字符串:
part-1\part-2
os.path.split()
要拆分路径时,也不要直接去拆字符串,而要通过os.path.split()函数,这样可以把一个路径拆分为两部分,后一部分总是最后级别的目录或文件名:
dir = os.path.split('/Users/michael/testdir/file.txt')
print(dir)
执行结果:
('/Users/michael/testdir', 'file.txt')
os.path.splitext()
可以直接得到文件扩展名,很多时候非常方便:
dir = os.path.splitext('/path/to/file.txt')
print(dir)
执行结果:
('/path/to/file', '.txt')
注意:
这些合并、拆分路径的函数并不要求目录和文件要真实存在,它们只对字符串进行操作。
os.rename(src, dst)
重命名文件或者目录。
os.remove(path)
删除路径为path的文件,如果path 是一个文件夹,将抛出OSError。
os.rmdir(path)
删除path指定的空目录,如果目录非空,则抛出一个OSError异常。
序列化
在程序运行的过程中,所有的变量都是在内存中,可以随时修改变量,但是一旦程序结束,变量所占用的内存就被操作系统全部回收。
我们把变量从内存中变成可存储或传输的过程称之为序列化,在python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
python提供了pickle模块来实现序列化。
基本接口:
pickle.dump(obj, file, [,protocol])
对象序列化并写入文件:
import pickle
d = dict(name='Bob', age=20, score=88)
du = pickle.dumps(d)
print(du)
执行结果:
b'\x80\x03}q\x00(X\x05\x00\x00\x00scoreq\x01KXX\x04\x00\x00\x00nameq\x02X\x03\x00\x00\x00Bobq\x03X\x03\x00\x00\x00ageq\x04K\x14u.'
pickle.dumps()方法把任意对象序列化成一个bytes,然后,就可以把这个bytes写入文件。
用另一个方法pickle.dump()直接把对象序列化后写入一个file-like Object:
import pickle
d = dict(name='Bob', age=20, score=88)
f = open('dump.txt', 'wb')
pickle.dump(d, f)
f.close()
看看写入的dump.txt文件,一堆乱七八糟的内容,这些都是python保存的对象内部信息。
当我们要把对象从磁盘读到内存时,可以先把内容读到一个bytes,然后用pickle.loads()方法反序列化出对象,也可以直接用pickle.load()方法从一个file-like Object中直接反序列化出对象。
import pickle
f = open('dump.txt', 'rb')
d = pickle.load(f)
f.close()
print(d) #{'score': 88, 'name': 'Bob', 'age': 20}
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,如此不能成功地反序列化也没关系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号