kafka一些基本原理
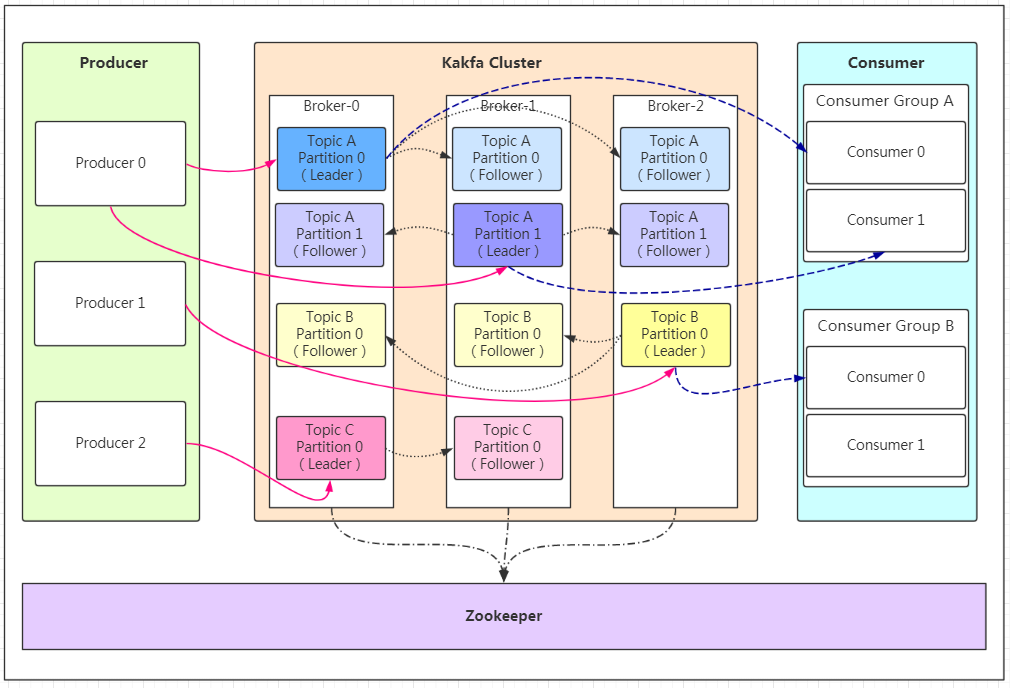
Producer:Producer即生产者,消息的产生者,是消息的入口。
kafka cluster:
Broker:Broker是kafka实例,每个服务器上有一个或多个kafka的实例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如图中的broker-0、broker-1等……
Topic:消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic。
Partition:Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹!
Replication:每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
Message:每一条发送的消息主体。
Consumer:消费者,即消息的消费方,是消息的出口。
Consumer Group:我们可以将多个消费组组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
Zookeeper:kafka集群依赖zookeeper来保存集群的的元信息,来保证系统的可用性。
在实际的应用中,建议消费者组的consumer的数量与partition的数量一致!
工作流程
1,producer先从集群中获取leader
2,producer将消息发送给leader
3,leader将消息写入本地文件
4,followers从leader pull消息
5,followers将消息写入本地文件后,向leader发送ack
6,leader收到所有followers的ack后向producer发送ack
重点:消息写入leader后,follower是主动的去leader进行同步的!producer采用push模式将数据发布到broker,每条消息追加到分区中,顺序写入磁盘,所以保证同一分区内的数据是有序的!
kafka为什么要分区呢?
1、 方便扩展。因为一个topic可以有多个partition,所以我们可以通过扩展机器去轻松的应对日益增长的数据量。
2、 提高并发。以partition为读写单位,可以多个消费者同时消费数据,提高了消息的处理效率。
kafka写消息时选择partition的原则:
1、 partition在写入的时候可以指定需要写入的partition,如果有指定,则写入对应的partition。
2、 如果没有指定partition,但是设置了数据的key,则会根据key的值hash出一个partition。
3、 如果既没指定partition,又没有设置key,则会轮询选出一个partition。
kafka怎么保证消息不丢失
通过ACK应答机制!
在producer向队列写入消息时,可以设置ack参数,来确定是否确认kafka接收到数据:
ack=0:代表producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效率最高。
ack=1:代表producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功。
ack=all:代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,确保leader发送成功和所有的副本都完成备份。安全性最高,但是效率最低。
kafka消息数据淘汰策略
1、 基于时间,默认配置是168小时(7天)。
2、 基于大小,默认配置是1073741824。
-------------------------------------------
个性签名:做一个灵魂有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!
万水千山总是情,打赏一分行不行,所以如果你心情还比较高兴,也是可以扫码打赏博主,哈哈哈(っ•̀ω•́)っ✎⁾⁾!
