GDT/IDT

全局符号与弱符号之间的区别主要有两点:
(1). 当链接编辑器组合若干可重定位的目标文件时,不允许对同名的 STB_GLOBAL 符号(全局变量)给出多个定义。 另一方面如果一个已定义的全局符号已经存在,出现一个同名的弱符号并不会产生错误(强弱附后存在,取强)。链接编辑器尽关心全局符号,忽略弱符号。 类似地,如果一个公共符号(符号的 st_shndx 中包含 SHN_COMMON),那么具有相同名称的弱符号出现也不会导致错误。链接编辑器会采纳公共定义,而忽略弱定义。
(2). 当链接编辑器搜索归档库(archive libraries)时,会提取那些包含未定义全局符号的档案成员。成员的定义可以是全局符号,也可以是弱符号。连接编辑器不会提取档案成员来满足未定义的弱符号。 未能解析的弱符号取值为0。
在每个符号表中,所有具有 STB_LOCAL 绑定的符号都优先于弱符号和全局符号。符号表节区中的 sh_info 头部成员包含第一个非局部符号的符号表索引。
main.c #include <stdio.h> int main(int argc, char *argv[]) { int a = 5; printf("%d",a); return 0; } a.c int a = 6; gcc main.c a.c -o result 结果为5
段寄存器后两位表示当前CPU状态
如图11-4 所示,每个描述符在GDT 中占8 字节,也就是2 个双字,或者说是64 位。图中,下面是低32 位,上面是高32 位。

20 位的段界限用来限制段的扩展范围(大小)。因为访问内存的方法是用段基地址加上偏移量,所以,对于向上扩展的段,如代码段和数据段来说,偏移量是从0 开始递增,段界限决定了偏移量的最大值;对于向下扩展的段,如堆栈段来说,段界限决定了偏移量的最小值。
G 位是粒度(Granularity)位,用于解释段界限的含义。当G 位是“0”时,段界限以字节为单位。此时,段的扩展范围是从1 字节到1 兆字节(1B~1MB),因为描述符中的界限值是20 位的。相反,如果该位是“1”,那么,段界限是以4KB 为单位的。这样,段的扩展范围是从4KB到4GB。
S 位用于指定描述符的类型(Descriptor Type)。当该位是“0”时,表示是一个系统段;为“1”时,表示是一个代码段或者数据段(堆栈段也是特殊的数据段)。
DPL 表示描述符的特权级(Descriptor Privilege Level,DPL)。这两位用于指定段的特权级。共有4 种处理器支持的特权级别,分别是0、1、2、3,其中0 是最高特权级别,3 是最低特权级别,在这里,描述符的特权级用于指定要访问该段所必须具有的最低特权级。如果这里的数值是2,那么,只有特权级别为0、1 和2 的程序才能访问该段,而特权级为3 的程序访问该段时,处理器会予以阻止。
P 位用于指示描述符所对应的段是否存在,当内存空间紧张时,有可能只是建立了描述符,对应的内存空间并不存在,这时,就应当把描述符的P 位清零,表示段并不存在。另外,同样是在内存空间紧张的情况下,会把很少用到的段换出到硬盘中,腾出空间给当前急需内存的程序使用(当前正在执行的),这时,同样要把段描述符的P 位清零。当再次轮到它执行时,再装入内存,然后将P 位置1。
D/B(很罕见了) 位是“默认的操作数大小”(Default Operation Size)或者“默认的堆栈指针大小”(DefaultStack Pointer Size),又或者“上部边界”(Upper Bound)标志。
设立该标志位,主要是为了能够在32 位处理器上兼容运行16 位保护模式的程序
TYPE 字段共4 位,用于指示描述符的子类型,或者说是类别。如表11-1 所示,对于数据段来说,这4 位分别是X、E、W、A 位;而对于代码段来说,这4 位则分别是X、C、R、A 位。
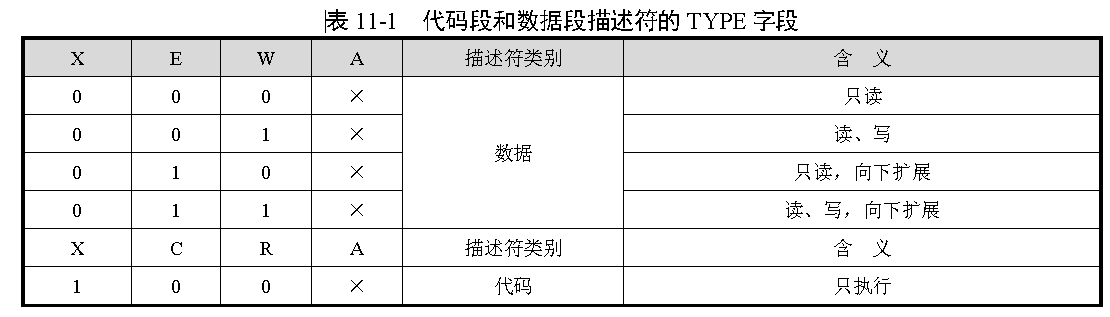

X 表示是否可以执行(eXecutable)。数据段总是不可执行的,X=0;代码段总是可以执行的,因此,X=1。
对于数据段来说,E 位指示段的扩展方向。E=0 是向上扩展的,也就是向高地址方向扩展的,是普通的数据段;E=1 是向下扩展的,也就是向低地址方向扩展的,通常是堆栈段。W 位指示段的读写属性,或者说段是否可写,W=0 的段是不允许写入的,否则会引发处理器异常中断;W=1的段是可以正常写入的。
对于代码段来说,C 位指示段是否为特权级依从的(Conforming)。C=0 表示非依从的代码段,这样的代码段可以从与它特权级相同的代码段调用,或者通过门调用;C=1 表示允许从低特权级的程序转移到该段执行,
R 位指示代码段是否允许读出。代码段总是可以执行的,但是,为了防止程序被破坏,它是不能写入的,也许有人会问,既然代码段是不可读的,那处理器怎么从里面取指令执行呢?事实上,这里的R 属性并非用来限制处理器,而是用来限制程序和指令的行为
数据段和代码段的A 位是已访问(Accessed)位,用于指示它所指向的段最近是否被访问过。在描述符创建的时候,应该清零。之后,每当该段被访问时,处理器自动将该位置“1”。
AVL 是软件可以使用的位(Available),通常由操作系统来用,处理器并不使用它
问题一:这些描述符表放置在内存哪里?
答案是没有固定的位置,可以任由程序员安排在任意合适的位置。
问题二:既然没有指定固定位置,CPU如何知道全局描述符表在哪?
答案是Intel干脆设置了一个48位的专用的全局描述符表寄存器(GDTR)来保存全局描述符表的信息。

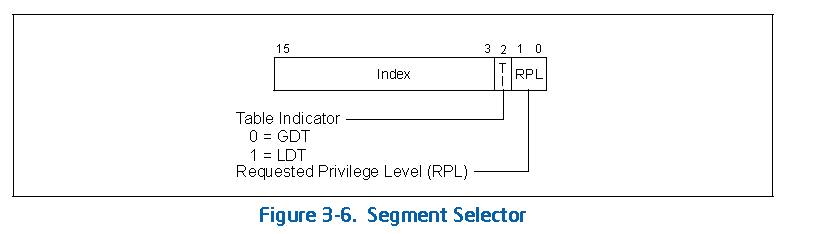
既然用16位来表示表的长度,那么2的16次方就是65536字节,除以每一个描述符的8字节,那么最多能创建8192个描述符。
80386CPU内部有5个32位的控制寄存器(Control Register,CR),分别是CR0到CR3,以及CR8。用来表示CPU的一些状态,其中的CR0寄存器的PE位(Protection Enable,保
护模式允许位),0号位,就表示了CPU的运行状态,0为实模式,1为保护模式。通过修改这个位就可以立即改变CPU的工作模式。不过需要注意的是,一旦CR0寄存器的PE位被修改,
CPU就立即按照保护模式去寻址了,所以这就要求我们必须在进入保护模式之前就在内存里放置好GDT,然后设置好GDTR寄存器。
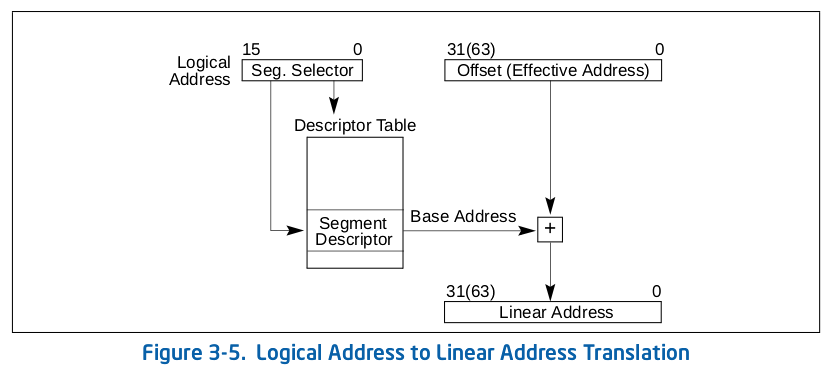
段机制的线性地址合成过程
现代操作系统几乎不再使用分段而是绕过分段技术直接使用了分页,所以我们使用所说的平坦模式(Flat Mode)绕过分段技术,当整个虚拟地址空间是一个起始地址为0,限长为4G的"段"时(这么大段相当于没分段),我们给出的偏移地址就在数值上等于是段机制处理之后的地址了。不过我们不是简单的对所有的段使用同样的描述符,而是给代码段和数据段分配不同的描述符。
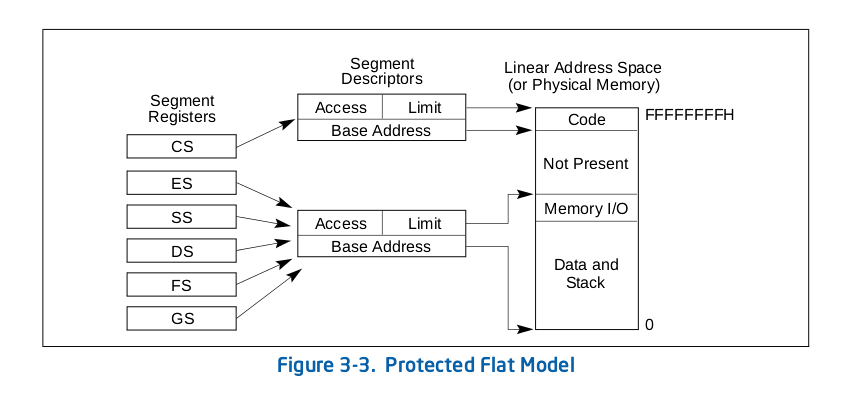
在第二章中我们谈到了GRUB在载入内核时候的一些状态,其中就有以下两条:
1. CS 指向基地址为0x00000000,限长为4G – 1的代码段描述符。
2. DS,SS,ES,FS 和GS 指向基地址为0x00000000,限长为4G–1的数据段描述符。
大家现在应该理解这两项了吧?既然GRUB已经替我们做过了,那我们还有必要再来一次吗?当然有必要了,一来是学习的必要(grub前面已经帮我们从实模式到保护模式设定好了,而且在实模式之前已经设置了GDT表,此处我们只是自己实现一遍,反正之后也没有用分段,用了我们也用lgdt重新设置了),二来在后期实现TSS任务切换的时候还要用到全局描述符表。
gdt_set_gate(0, 0, 0, 0, 0); // 按照Intel 文档要求,第一个描述符必须全0 gdt_set_gate(1, 0, 0xFFFFFFFF , 0x9A, 0xCF); // 指令段 gdt_set_gate(2, 0, 0xFFFFFFFF , 0x92, 0xCF); // 数据段 gdt_set_gate(3, 0, 0xFFFFFFFF , 0xFA, 0xCF); // 用户模式代码段 gdt_set_gate(4, 0, 0xFFFFFFFF , 0xF2, 0xCF); // 用户模式数据段
设置段描述符内容

第一,正如上一节所述,即使是在实模式下,段寄存器的描述符高速缓存器也被用于访问内存,仅低20 位有效,高12 位是全零。当处理器进入保护模式后,不影响段寄存器的内容和使用,它们依然是有效的,程序可以继续执行但是,在保护模式下,对段的解释是不同的,处理器会把段选择器里的内容看成是描述符选择子,而不是逻辑段地址。因此,比较安全的做法是尽快刷新CS、SS、DS、ES、FS 和GS 的内容,包括它们的段选择器和描述符高速缓存器。第二,在进入保护模式前,有很多指令已经进入了流水线。因为处理器工作在实模式下,所以它们都是按16 位操作数和16 位地址长度进行译码的,即使是那些用bits 32 编译的指令。进入保护模式后,由于对段地址的解释不同,对操作数和默认地址大小的解释也不同,有些指令的执行结果可能会不正确,所以必须清空流水线
流水线:
为了提高处理器的执行效率和速度,可以把一条指令的执行过程分解成若干个细小的步骤,并分配给相应的单元来完成。各个单元的执行是独立的、并行的。如此一来,各个步骤的
执行在时间上就会重叠起来,这种执行指令的方法就是流水线(Pipe-Line)技术。
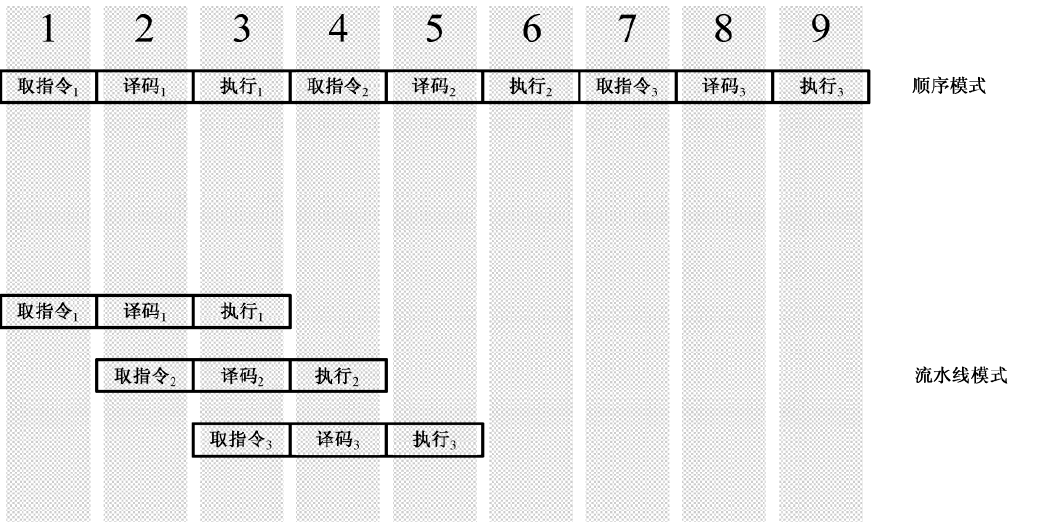
一旦将指令拆分成微操作,处理器就可以在必要的时候乱序执行(Out-Of-Order Execution)程序。考虑以下例子:
mov eax,[mem1]
shl eax,5
add eax,[mem2]
mov [mem3],eax
这里,指令add eax,[mem2]可以拆分为两个微操作。如此一来,在执行逻辑左移指令的同时,处理器可以提前从内存中读取mem2 的内容。典型地,如果数据不在高速缓存中(不中),那么处理器在获取mem1 的内容之后,会立即开始获取mem2 的内容,与此同时,shl 指令的执行早就开始了。
串行化:
序列化 (Serialization)将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
Done!!!
PS.最近文章质量很差(虽然说正常时也没什么质量),具体的我直接记录在pdf文档中,比较方便
posted on 2017-08-21 23:16 chaunceyctx 阅读(676) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号