linux文件系统详解
最近在做磁盘性能优化,需要结合文件系统原理去思考优化方向,因此借此机会进一步加深了对文件系统的认识。在看这篇文章之前,建议先看下前面一篇关于磁盘工作原理的解读。下面简单总结一些要点分享出来:
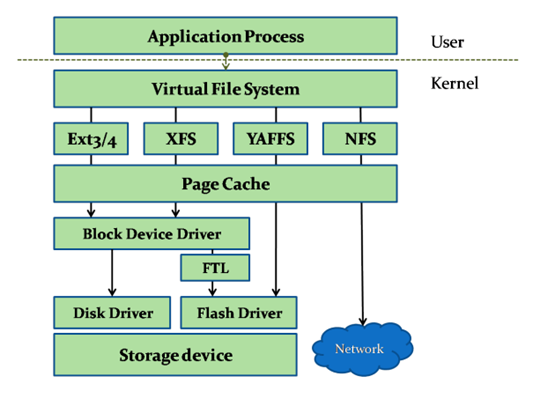
一、文件系统层次分析
由上而下主要分为用户层、VFS层、文件系统层、缓存层、块设备层、磁盘驱动层、磁盘物理层
用户层:最上面用户层就是我们日常使用的各种程序,需要的接口主要是文件的创建、删除、打开、关闭、写、读等。
VFS层:我们知道Linux分为用户态和内核态,用户态请求硬件资源需要调用System Call通过内核态去实现。用户的这些文件相关操作都有对应的System Call函数接口,接口调用 VFS对应的函数。
文件系统层:不同的文件系统实现了VFS的这些函数,通过指针注册到VFS里面。所以,用户的操作通过VFS转到各种文件系统。文件系统把文件读写命令转化为对磁盘LBA的操作,起了一个翻译和磁盘管理的作用。
缓存层:文件系统底下有缓存,Page Cache,加速性能。对磁盘LBA的读写数据缓存到这里。
块设备层:块设备接口Block Device是用来访问磁盘LBA的层级,读写命令组合之后插入到命令队列,磁盘的驱动从队列读命令执行。Linux设计了电梯算法等对很多LBA的读写进行优化排序,尽量把连续地址放在一起。
磁盘驱动层:磁盘的驱动程序把对LBA的读写命令转化为各自的协议,比如变成ATA命令,SCSI命令,或者是自己硬件可以识别的自定义命令,发送给磁盘控制器。Host Based SSD甚至在块设备层和磁盘驱动层实现了FTL,变成对Flash芯片的操作。
磁盘物理层:读写物理数据到磁盘介质。
二、文件系统结构与工作原理(主要以ext4为例)
我们都知道,windows文件系统主要有fat、ntfs等,而linux文件系统则种类多的很,主要有VFS做了一个软件抽象层,向上提供文件操作接口,向下提供标准接口供不同文件系统对接,下面主要就以EXT4文件系统为例,讲解下文件系统结构与工作原理:
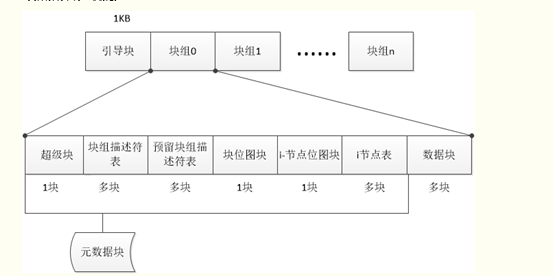
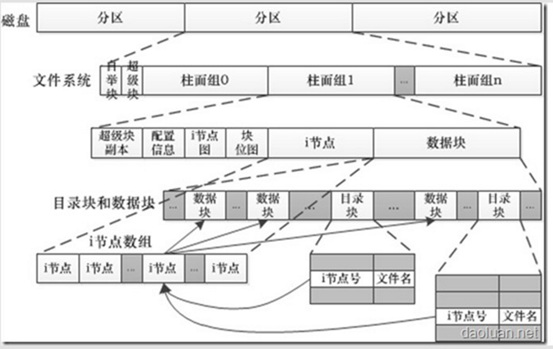
上面两个图大体呈现了ext4文件系统的结构,从中也相信能够初步的领悟到文件系统读写的逻辑过程。下面对上图里边的构成元素做个简单的讲解:
引导块:为磁盘分区的第一个块,记录文件系统分区的一些信息,,引导加载当前分区的程序和数据被保存在这个块中。一般占用2kB,
超级块:
超级块用于存储文件系统全局的配置参数(譬如:块大小,总的块数和inode数)和动态信息(譬如:当前空闲块数和inode数),其处于文件系统开始位置的1k处,所占大小为1k。为了系统的健壮性,最初每个块组都有超级块和组描述符表(以下将用GDT)的一个拷贝,但是当文件系统很大时,这样浪费了很多块(尤其是GDT占用的块多),后来采用了一种稀疏的方式来存储这些拷贝,只有块组号是3, 5 ,7的幂的块组(譬如说1,3,5,7,9,25,49…)才备份这个拷贝。通常情况下,只有主拷贝(第0块块组)的超级块信息被文件系统使用,其它拷贝只有在主拷贝被破坏的情况下才使用。
块组描述符:
GDT用于存储块组描述符,其占用一个或者多个数据块,具体取决于文件系统的大小。它主要包含块位图,inode位图和inode表位置,当前空闲块数,inode数以及使用的目录数(用于平衡各个块组目录数),具体定义可以参见ext3_fs.h文件中struct ext3_group_desc。每个块组都对应这样一个描述符,目前该结构占用32个字节,因此对于块大小为4k的文件系统来说,每个块可以存储128个块组描述符。由于GDT对于定位文件系统的元数据非常重要,因此和超级块一样,也对其进行了备份。GDT在每个块组(如果有备份)中内容都是一样的,其所占块数也是相同的。从上面的介绍可以看出块组中的元数据譬如块位图,inode位图,inode表其位置不是固定的,当然默认情况下,文件系统在创建时其位置在每个块组中都是一样的,如图2所示(假设按照稀疏方式存储,且n不是3,5,7的幂)
块组:
每个块组包含一个块位图块,一个 inode 位图块,一个或多个块用于描述 inode 表和用于存储文件数据的数据块,除此之外,还有可能包含超级块和所有块组描述符表(取决于块组号和文件系统创建时使用的参数)。下面将对这些元数据作一些简要介绍。
块位图:
块位图用于描述该块组所管理的块的分配状态。如果某个块对应的位未置位,那么代表该块未分配,可以用于存储数据;否则,代表该块已经用于存储数据或者该块不能够使用(譬如该块物理上不存在)。由于块位图仅占一个块,因此这也就决定了块组的大小。
Inode位图:
Inode位图用于描述该块组所管理的inode的分配状态。我们知道inode是用于描述文件的元数据,每个inode对应文件系统中唯一的一个号,如果inode位图中相应位置位,那么代表该inode已经分配出去;否则可以使用。由于其仅占用一个块,因此这也限制了一个块组中所能够使用的最大inode数量。
Inode表:
Inode表用于存储inode信息。它占用一个或多个块(为了有效的利用空间,多个inode存储在一个块中),其大小取决于文件系统创建时的参数,由于inode位图的限制,决定了其最大所占用的空间。
以上这几个构成元素所处的磁盘块成为文件系统的元数据块,剩余的部分则用来存储真正的文件内容,称为数据块,而数据块其实也包含数据和目录。
了解了文件系统的结构后,接下来我们来看看操作系统是如何读取一个文件的:
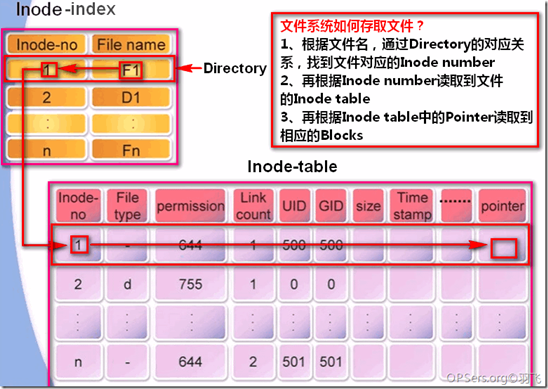
大体过程如下:
1、根据文件所在目录的inode信息,找到目录文件对应数据块
2、根据文件名从数据块中找到对应的inode节点信息
3、从文件inode节点信息中找到文件内容所在数据块块号
4、读取数据块内容
到这里,相信很多人会有一个疑问,我们知道一个文件只有一个Inode节点来存放它的属性信息,那么你可能会想如果一个大文件,那它的block一定是多个的,且可能不连续的,那么inode怎么来表示呢,下面的图告诉你答案:
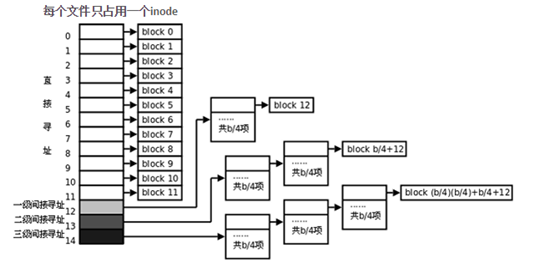
也就是说,如果文件内容太大,对应数据块数量过多,inode节点本身提供的存储空间不够,会使用其他的间接数据块来存储数据块位置信息,最多可以有三级寻址结构。
到这里,应该都已经非常清楚文件读取的过程了,那么下面再抛出两个疑问:
1、文件的拷贝、剪切的底层过程是怎样的?
2、软连接和硬连接分别是如何实现的?
下面来结合stat命令动手操作一下,便知真相:
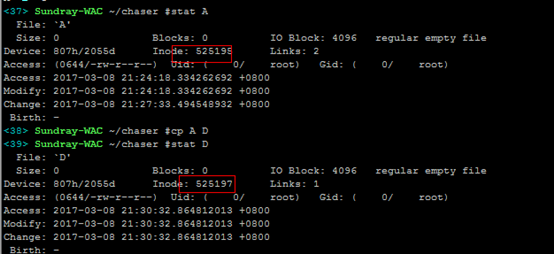
1)拷贝文件:创建一个新的inode节点,并且拷贝数据块内容
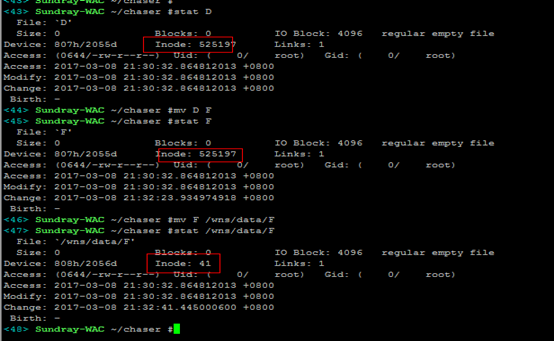
2)剪切文件:同个分区里边mv,inode节点不变,只是更新目录文件对应数据块里边的文件名和inode对应关系;跨分区mv,则跟拷贝一个道理,需要创建新的inode,因为inode节点不同分区是不能共享的。
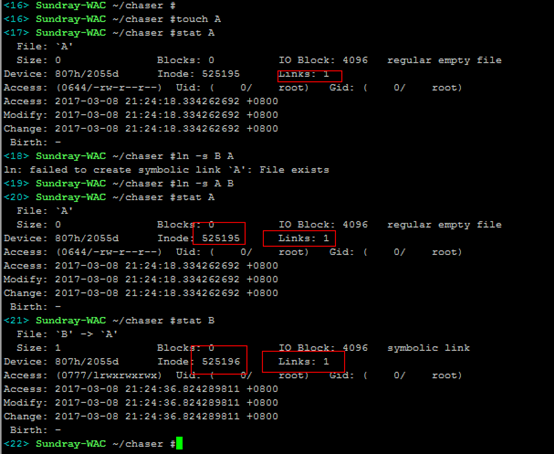
3)软连接:创建软连接会创建一个新的inode节点,其对应数据块内容存储所链接的文件名信息,这样原文件即便删除了,重新建立一个同名的文件,软连接依然能够生效。

4)硬链接:创建硬链接,并不会新建inode节点,只是links加1,还有再目录文件对应数据块上增加一条文件名和inode对应关系记录;只有将硬链接和原文件都删除之后,文件才会真正删除,即links为0才真正删除。
三、文件顺序读写和随机读写
从前面文章了解了磁盘工作原理之后,也已经明白了为什么文件随机读写速度会比顺序读写差很多,这个问题在windows里边更加明显,为什么呢?究其原因主要与文件系统工作机制有关,fat和ntfs文件系统设计上,每个文件所处的位置相对连续甚至紧靠在一起,这样没有为每个文件留下足够的扩展空间,因此容易产生磁盘碎片,用过windows系统的应该也知道,windows磁盘分区特别提供了磁盘碎片整理的高级功能。如下图:
那回过来,看看linux 文件系统ext4,都说linux不需要考虑磁盘碎片,究竟是怎么回事?
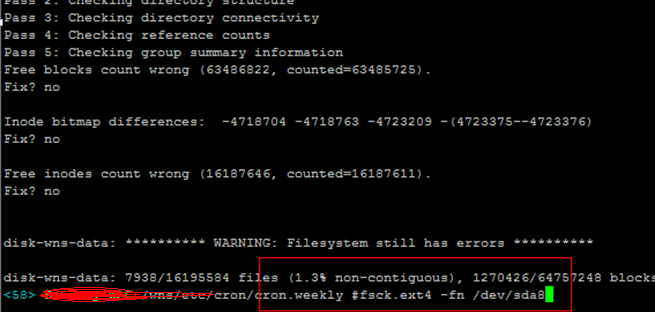
主要是因为Linux的文件系统会将文件分散在整个磁盘,在文件之间留有大量的自由空间,而不是像Windows那样将文件一个接一个的放置。当一个文件被编辑了并且变大了,一般都会有足够的自由空间来保存文件。如果碎片真的产生了,文件系统就会尝试在日常使用中将文件移动来减少碎片,所以不需要专门的碎片整理程序。但是,如果磁盘空间占用已经快满了,那碎片是不可避免的,文件系统的设计本来就是用来满足正常情况下使用的。如果磁盘空间不够,那要么就是数据冗余了,要么就该换容量更大的磁盘。你可以使用fsck命令来检测一下一个Linux文件系统的碎片化程度,只需要在输出中查看非连续i节点个数(non-contiguous inodes)就可以了。
关于文件系统的就讲这么多,下篇会讲解linux内核提供的一个资源管控机制cgroup,分析其原理及使用过程。
ext4文件系统bug:
http://www.phoronix.com/scan.php?page=news_item&px=MTIxNDQ
ext4文件系统描述:
http://blog.csdn.net/liangchen0322/article/details/50365685
http://blog.csdn.net/fybon/article/details/26243971
hexdump查看磁盘结构信息:
http://www.cnblogs.com/jiangcsu/p/5737659.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号