
常用的算法思想总结
对于计算机科学而言,算法是一个非常重要的概念。它是程序设计的灵魂,是将实际问题同解决该问题的计算机程序建立起联系的桥梁。接下来,我们来看看一些常用的算法思想。
(一)穷举法思想
穷举法,又称为强力法。它是一种最为直接,实现最为简单,同时又最为耗时的一种解决实际问题的算法思想。
基本思想:在可能的解空间中穷举出每一种可能的解,并对每一个可能解进行判断,从中得到问题的答案。
使用穷举法思想解决实际问题,最关键的步骤是划定问题的解空间,并在该解空间中一一枚举每一个可能的解。这里有两点需要注意,一是解空间的划定必须保证覆盖问题的全部解,二是解空间集合及问题的解集一定是离散的集合,也就是说集合中的元素是可列的、有限的。
穷举法用时间上的牺牲换来了解的全面性保证,因此穷举法的优势在于确保得到问题的全部解,而瓶颈在于运算效率十分低下。但是穷举法算法思想简单,易于实现,在解决一些规模不是很大的问题,使用穷举法不失为一种很好地选择。
现在我们通过具体的实例来理解穷举法思想。
/**
* 实例:寻找[1,100]之间的素数
*
*/
#include <stdio.h>
/**
* 判断n是否是素数,是则返回1,不是则返回0
*/
int isPrime(int n)
{
int i = 0;
for (i = 2; i < n; i++) {
if (0 == n % i) {
return 0;
}
}
return 1;
}
/**
* 寻找[low,high]之间的素数
*/
void getPrime(int low, int high)
{
int i = 0;
for (i = low; i <= high; i++) {
if (isPrime(i)) {
printf("%d ", i);
}
}
}
int main(int argc, const char * argv[]) {
// insert code here...
int low = 0, high = 0;
printf("Please input the domain for searching prime\n");
printf("low limitation:");
scanf("%d", &low);
printf("high limitation:");
scanf("%d", &high);
printf("The whole primes in this domain are\n");
getPrime(low, high);
getchar();
return 0;
}
程序运行结果:
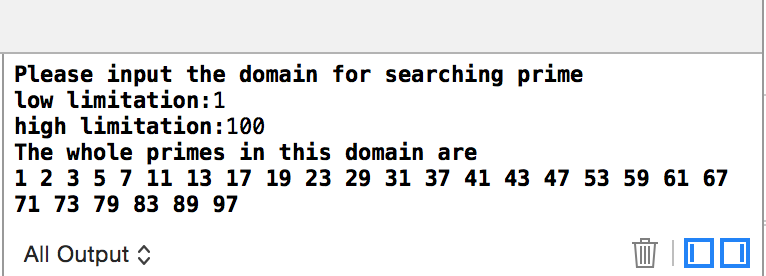
(二)递归与分治思想
递归与分治的算法思想往往是相伴而生的,它们在各类算法中使用非常频繁,应用递归和分治的算法思想有时可以设计出代码简洁且比较高效的算法来。
在解决一些比较复杂的问题,特别是解决一些规模较大得问题时,常常将问题进行分解。具体来说,就是将一个规模较大的问题分割成规模较小的同类问题,然后将这些小问题的子问题逐个加以解决,最终也就将整个大问题解决了。这种思想称之为分治。在解决一些问题比较复杂、计算量庞大的问题时经常被用到。
最为经典的使用分治思想设计的算法就是“折半查找算法”。折半查找算法利用了元素之间的顺序关系(有序序列),采用分而治之的策略,不断缩小问题的规模,每次都将问题的规模减小至上一次的一半。
而递归思想也是一种常见的算法设计思想,所谓递归算法,就是一种直接或间接地调用原算法本身的一种算法。
接下来我们通过实例代码来理解递归、分治思想。
分治思想:
/**
* 有一个数组A[10],里面存放了10个整数,顺序递增
* A[10] = {2, 3, 5, 7, 8, 10, 12, 15, 19, 21}
*
*/
#include <stdio.h>
int bin_search(int A[], int n, int key)
{
int low = 0, high = 0, mid = 0;
high = n - 1;
while (low <= high) {
mid = (low + high) / 2;
if (A[mid] == key) { //查找成功,返回mid
return mid;
}
if (A[mid] < key) { //在后半序列中查找
low = mid + 1;
}
if (A[mid] > key) { //在前半序列中查找
high = mid - 1;
}
}
return -1; //查找失败
}
int main(int argc, const char * argv[]) {
// insert code here...
int A[10] = {2, 3, 5, 7, 8, 10, 12, 15, 19, 21};
int i = 0, n = 0, addr = 0;
printf("The contents of the Array A[10] are\n");
for (i = 0; i < 10; i++) {
printf("%d ",A[i]); //显示数组A中的内容
}
printf("\nPlease input a interger for search\n");
scanf("%d", &n); //输入待查找得元素
addr = bin_search(A, 10, n); //折半查找,返回该元素在数组中的下标
if (-1 != addr) {
printf("%d is at the %dth unit is array A\n", n, addr);
}else{
printf("There is no %d in array A\n", n); //查找失败
}
getchar();
return 0;
}
运行结果:
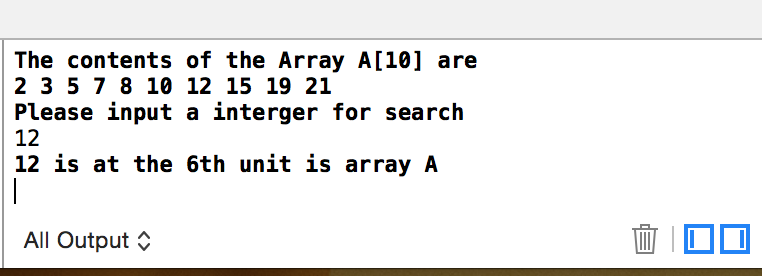
递归思想
/**
* 计算n的阶乘n!
*
*/
#include <stdio.h>
int factorial(int n)
{
if (0 == n) {
return 1;
}else{
return n * factorial(n - 1);
}
}
int main(int argc, const char * argv[]) {
// insert code here...
int n = 0, result = 0;
printf("Please input factorial number\n");
scanf("%d", &n);
result = factorial(n);
printf("result is %d", result);
getchar();
return 0;
}
运行结果
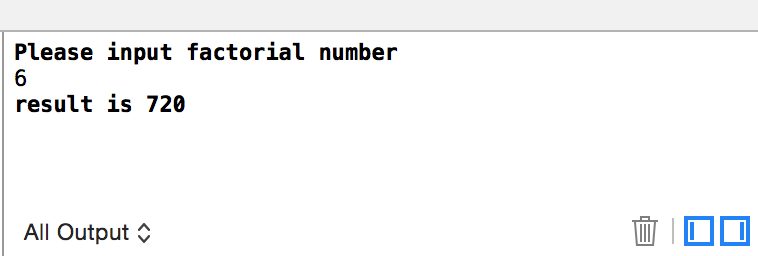
(三)贪心算法思想
贪心算法的思想非常简单且算法效率很高,在一些问题的解决上有着明显的优势。
先来看一个生活中的例子。假设有3种硬币,面值分别为1元、5角、1角。这3种硬币各自的数量不限,现在要找给顾客3元6角钱,请问怎样找才能使得找给顾客的硬币数量最少呢?你也许会不假思索的说出答案:找给顾客3枚1元硬币,1枚5角硬币,1枚1角硬币。其实也可以找给顾客7枚5角硬币,1枚1角硬币。可是在这里不符合题意。在这里,我们下意识地应用了所谓贪心算法解决这个问题。
所谓贪心算法,就是总是做出在当前看来是最好的选择的一种方法。以上述的题目为例,为了找给顾客的硬币数量最少,在选择硬币的面值时,当然是尽可能地选择面值大的硬币。因此,下意识地遵循了以下方案:
(1)首先找出一个面值不超过3元6角的最大硬币,即1元硬币。
(2)然后从3元6角中减去1元,得到2元6角,再找出一个面值不超过2元6角的最大硬币,即1元硬币。
(3)然后从2元6角中减去1元,得到1元6角,再找出一个面值不超过1元6角的最大硬币,即1元硬币。
(4)然后从1元6角中减去1元,得到6角,再找出一个面值不超过6角的最大硬币,即5角硬币。
(5)然后从6角中减去5角,得到1角,再找出一个面值不超过1角的最大硬币,即1角硬币。
(6)找零钱的过程结束。
这个过程就是一个典型的贪心算法思想。
因此,不难看出应用贪心算法求解问题,并不从问题的整体最优上加以考虑,它所作出的每一步选择只是在某种意义上得局部最优选择。因此,严格意义上讲,要使用贪心算法求解问题,该问题应当具备以下性质。
(1)贪心选择性质
所谓贪心选择性质,就是指所求解的问题的整体最优解可以通过一系列的局部最优解得到。所谓局部最优解,就是指在当前的状态下做出的最好选择。
(2)最优子结构性质
当一个问题的最优解包含着它的子问题的最优解时,就称此问题具有最优子结构性质。
我们经常使用的哈夫曼(Huffman Tree)编码算法,求解最小生成树的克鲁斯卡尔(Kruskal)算法和普利姆(Prim)算法,求解图的单源最短路径的迪克斯特拉(Dijkstra)算法都是基于贪心算法的思想设计的。
下面,我们来通过实例代码来理解贪心算法思想。
/**
* 最优装船问题
* 有一批集装箱要装入一个载质量为C的货船中,每个集装箱的质量由用户自己输入指定,在货船的装载体积不限的前提下,如何装载集装箱才能尽可能多地将集装箱装入货船中。
*/
#include <stdio.h>
void sort(int w[], int t[], int n)
{
int i = 0, j = 0, tmp = 0;
//存放w[]中的内容,用于排序
int *w_tmp = (int *)malloc(sizeof(int) * n);
for (i = 0; i < n; i++) {
t[i] = i; //初始化数组t
}
for (i = 0; i < n; i++) {
w_tmp[i] = w[i];
}
for (i = 0; i < n - 1; i++) { //冒泡排序
for (j = 0; j < n - i - 1; j++) {
if (w_tmp[j] > w_tmp[j+1]) {
tmp = w_tmp[j];
w_tmp[j] = w_tmp[j+1];
w_tmp[j+1] = tmp;
tmp = t[j];
t[j] = t[j+1];
t[j+1] = tmp;
}
}
}
}
void Loading(int x[], int w[], int c, int n)
{
int i = 0;
//存放w[]的下标,如果t[i]、t[j]、i<j,则w[i]<=w[j]
int *t = (int *)malloc(sizeof(int) * n);
//排序,用数组t[[]存放w[]的下标
sort(w, t, n);
for (i = 0; i < n; i++) {
x[i] = 0; //初始化数组x[]
}
for (i = 0; i < n && w[t[i]] <= c; i++) {
x[t[i]] = 1; //将第t[i]个集装箱装入货船中
c = c - w[t[i]]; //变量c中存放货船的剩余载质量
}
}
int main(int argc, const char * argv[]) {
// insert code here...
int x[5], w[5], c = 0, i = 0;
printf("Please input the maximum loading of the sheep\n");
scanf("%d", &c); //
printf("Please input the weight of FIVE box\n");
for (i = 0; i < 5; i++) { //
scanf("%d", &w[i]);
}
Loading(x, w, c, 5); //
printf("The following boxes will be loaded\n");
for (i = 0; i < 5; i++) { //
if (1 == x[i]) {
printf("BOX:%d ", i);
}
}
getchar();
return 0;
}
运行结果

以上,就是对算法设计中几个常见的思想的总结。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号