自然语言处理中的文本表示
文章目录
自然语言处理相关任务中要将自然语言交给机器学习中的算法来处理,通常需要将语言数学化,因为机器不是人,机器只认数学符号。向量是人把自然界的东西抽象出来交给机器处理的东西,基本上可以说向量是人对机器输入的主要方式了。
词向量就是用来将语言中的词进行数学化的一种方式,顾名思义,词向量就是把一个词表示成一个向量。
词的离散表示
One-Hot
一种最简单的词向量方式是One-Hot编码。首先根据现有文本资源,建立字典或词典(分词去重)。假设词典的大小为n(词典中有n个词),假如某个词在词典中的位置为k,则设立一个n维向量,第k维置1,其余维全都置0。
假设语料库中的一句话为:北京大学在北京
分词后为:['北', '京', '大', '学', '在']
one-hot编码:
# [1,0,0,0,0] 北
# [0,1,0,0,0] 京
# [0,0,1,0,0] 大
# [0,0,0,1,0] 学
# [0,0,0,0,1] 在
一个样本的特征向量即该样本中的每个单词的one-hot向量直接相加。
那么 “北京大学”用特征向量表示为[1,1,1,1,0]
假如这里有三句话,即三个样本:
“我喜欢你”; “你喜欢你的狗狗”; “你是狗狗”
假设已经分词完成,这个词典依次包含[我,喜欢,你,的,是,狗狗]这六个词。
根据one-hot编码,“我”就会被编码为[1,0,0,0,0,0],而“喜欢”就被编码为[0,1,0,0,0,0],以此类推。
一个样本的特征向量即该样本中的每个单词的one-hot向量直接相加。这三个样本的特征向量便会表示为:
我喜欢你:[1,1,1,0,0,0]
你喜欢你的狗狗:[0,1,2,1,0,1]
你是狗狗:[0,0,1,0,1,1]
其中,第二个句子中“你”出现了两次,因此第三维的值为2。
这样,基于one-hot的文本表示便处理完成。
该方法虽然简单,并且适用于任意文本数据,但存在很多严重问题:
- 维度爆炸。由于每一个单词的词向量的维度都等于词汇表的长度,对于大规模语料训练的情况,词汇表将异常庞大,使模型的计算量剧增造成维数灾难。
- 矩阵稀疏。有用的信息零散地分布在大量数据中。这会导致结果异常稀疏,使其难以进行优化,对于神经网络来说尤其如此。
- 向量正交。由于两两向量正交,无法表达两词向量之间的其他信息,造成了“语义鸿沟”的 现象,此特点对于NLP任务是相当致命的。
- 文本中词之间的顺序性、相对重要性等等,都没法区分和体现。
因此我们需要一种更好的表示方法:分布式表示
词的分布式表示
词的分布式表示这个名字(distributed representation)就是相对于one-hot 表示而来的,可以理解为,one-hot表示把所有的词都集中在了一个维度上,而分布式表示,就是一个词在各个维度上都分布有,分散了某种风险,增加了某些信息量。
基本想法是:通过训练将某种语言中的每一个词 映射成一个固定长度的短向量(当然这里的“短”是相对于One-Hot Representation的“长”而言的),所有这些向量构成一个词向量空间,而每一个向量则可视为 该空间中的一个点,在这个空间上引入“距离”,就可以根据词之间的距离来判断它们之间的语法、语义上的相似性了。
为什么叫Distributed Representation?一个简单的解释是这样的:对于One-Hot Representation,向量中只有一个非零分量,非常集中(有点孤注一掷的感觉);而对于Distributed Representation,向量中有大量非零分量,相对分散(有点风险平摊的感觉),把词的信息分布到各个分量中去了。这一点,跟并行计算里的分布式并行很像。
对于分布式表示来说,每个词的向量大大缩短(相比one hot编码),可以通过计算两个词之间的空间距离,这个距离可能能表征词义,语法上的相似性。
N-gram模型
自然语言处理过程中,一个值得我们注意的是,如果我们仅仅是将文本字符串分割成单独的文本,此时我们只是简单的去分析文本中每个字符所代表的潜在意义与我们需要分析的结果的关系性,然而我们忽略一个非常重要的信息,文本的顺序是含有非常重要的信息的。
该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的Bi-Gram和三元的Tri-Gram。
如果我们有一个由 m 个词组成的序列(或者说一个句子),我们希望算得概率
P
(
w
1
,
w
2
,
.
.
.
w
m
,
)
=
P
(
w
1
)
∗
P
(
w
2
,
∣
w
1
)
∗
P
(
w
3
,
∣
w
1
,
w
2
)
.
.
.
∗
P
(
w
m
,
∣
w
1
,
w
,
.
.
.
,
w
m
−
1
)
P(w_{1},w_{2},...w_{m},)=P(w_{1})*P(w_{2},|w_{1})*P(w_{3},|w_{1},w_{2})...*P(w_{m},|w_{1},w_{},...,w_{m-1})
P(w1,w2,...wm,)=P(w1)∗P(w2,∣w1)∗P(w3,∣w1,w2)...∗P(wm,∣w1,w,...,wm−1)
显然这个概率显然并不好算,不妨利用马尔科夫链的假设,即当前这个词仅仅跟前面
n
n
n 个有限的词相关,因此也就不必追溯到最开始的那个词,这样便可以大幅缩减上述算式的长度。
P
(
w
1
,
w
2
,
.
.
.
w
m
,
)
=
P
(
w
i
−
n
+
1
,
w
i
−
n
+
2
,
.
.
.
,
w
i
−
n
)
P(w_{1},w_{2},...w_{m},)=P(w_{i-n+1},w_{i-n+2},...,w_{i-n})
P(w1,w2,...wm,)=P(wi−n+1,wi−n+2,...,wi−n)
NNLM
和N-gram类似,NNLM也假设当前词仅依赖于前n-1个词(nnlm是n-gram的进化版)
NNLM的主要任务是要学习一个解决语言模型任务的网络结构,语言模型就是要看到上文预测下文,而word embedding只是这个模型的副产物
它的训练方法是:给定一个句子中某个单词的前t-1个单词,要求模型能够正确预测出这个单词。
比如输入某句话中的单词 W t = B e r t Wt = Bert Wt=Bert 前面的 t − 1 t-1 t−1个单词,要求网络正确预测单词Bert,即最大化: P ( W t = B e r t ∣ W 1 , W 2 , . . . W ( t − 1 ) ; Θ ) P(Wt=Bert | W1,W2,...W(t-1);\Theta ) P(Wt=Bert∣W1,W2,...W(t−1);Θ)
前面任意单词 W i Wi Wi 用one-hot编码(比如:[0 0 1 0 0 0 0])作为原始单词输入,之后乘以矩阵Q后获得向量 C ( W i ) C(Wi) C(Wi) ,每个单词的 C ( W i ) C(Wi) C(Wi)拼接,上接隐层,然后接softmax去预测后面应该后续接哪个单词。这个 C ( W i ) C(Wi) C(Wi)是什么?这其实就是单词对应的Word Embedding值,那个矩阵Q包含V行,V代表词典大小,每一行内容代表对应单词的Word embedding值。只不过Q的内容也是网络参数,需要学习获得,训练刚开始用随机值初始化矩阵Q,当这个网络训练好之后,矩阵Q的内容被正确赋值,每一行代表一个单词对应的Word embedding值。所以你看,通过这个网络学习语言模型任务,这个网络不仅自己能够根据上文预测后接单词是什么,同时获得一个副产品,就是那个矩阵Q,这就是单词的Word Embedding是被如何学会的。
具体实现:
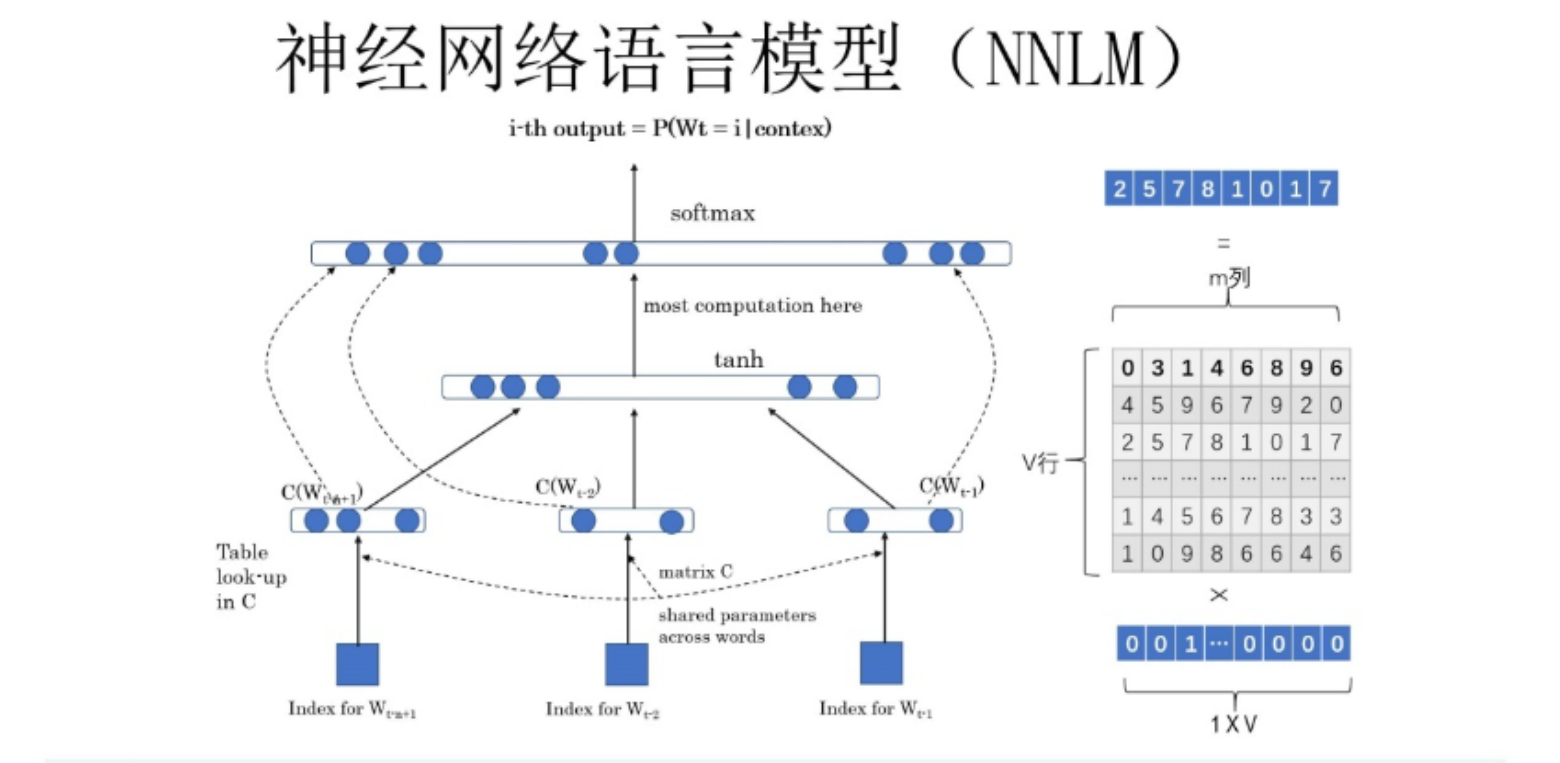
根据上图可以看出,该模型结构分为三层,分别是输入层,一层隐藏层,输出层。
输出层: 从one-hot到distribution representation
输入前
t
−
1
t-1
t−1个单词的one-hot编码,假设词表大小为
V
V
V,则每个单词
W
i
Wi
Wi 的one-hot编码向量为
1
∗
V
1*V
1∗V
经过一个参数矩阵
C
C
C ,(
C
C
C为一个
V
∗
m
V*m
V∗m的自由参数矩阵,其中V为词表大小,m表示每个词的维度),得到
C
(
W
i
)
C(Wi)
C(Wi)为
1
∗
m
1*m
1∗m的分布式向量。
将
C
(
W
t
−
1
)
,
C
(
W
t
−
2
)
,
.
.
.
,
C
(
W
t
−
n
+
1
)
C(W_{t-1}),C(W_{t-2}),...,C(W_{t-n+1})
C(Wt−1),C(Wt−2),...,C(Wt−n+1)首尾拼接得到
x
=
[
C
(
W
t
−
1
)
,
C
(
W
t
−
2
)
,
.
.
.
,
C
(
W
t
−
n
+
1
)
]
x = [C(W_{t-1}),C(W_{t-2}),...,C(W_{t-n+1})]
x=[C(Wt−1),C(Wt−2),...,C(Wt−n+1)],即一个x是一个
1
∗
(
t
−
1
)
m
1*(t-1)m
1∗(t−1)m维的向量
隐藏层:
x
x
x通过函数
g
g
g作用,输出概率分布。函数
g
g
g的实现可以是前向神经网络或者循环神经网络或者其它参数化的函数,论文的实现如下:
y
=
b
+
W
x
+
U
t
a
n
h
(
d
+
H
x
)
y = b+Wx+Utanh(d+Hx)
y=b+Wx+Utanh(d+Hx)
t
a
n
h
(
d
+
H
x
)
tanh(d+Hx)
tanh(d+Hx)是隐藏层,
W
,
H
,
U
,
b
W,H,U,b
W,H,U,b都是要训练的参数矩阵
输出层:
为了使得得到的概率分布之和为1,需要用到softmax函数
……
Word2Vec
Word2Vec的网络结构其实和NNLM是基本类似的。不过这里需要指出:尽管网络结构相近,而且也是做语言模型任务,但是其训练方法不太一样。Word2Vec有两种训练方法,一种叫CBOW,核心思想是从一个句子里面把一个词抠掉,用这个词的上文和下文去预测被抠掉的这个词;第二种叫做Skip-gram,和CBOW正好反过来,输入某个单词,要求网络预测它的上下文单词。而你回头看看,NNLM是怎么训练的?是输入一个单词的上文,去预测这个单词。这是有显著差异的。为什么Word2Vec这么处理?原因很简单,因为Word2Vec和NNLM不一样,NNLM的主要任务是要学习一个解决语言模型任务的网络结构,语言模型就是要看到上文预测下文,而word embedding只是无心插柳的一个副产品。但是Word2Vec目标不一样,它单纯就是要word embedding的,这是主产品,所以它完全可以随性地这么去训练网络。
Word2vec是如何得到词向量的?
首先有了语料库,对于语料库进行预处理,比如英文语料库可能需要大小写转换及拼写错误的检测等操作,如果是中文日语等语料库需要先进行分词处理,这些与语料库的种类和任务目标有关。得到预处理后的语料库以后,将其每个词的one-hot向量作为word2vec的输入,通过word2vec训练得到低维词向量。
Word2vec通过语言模型学习到词的向量表示。语言模型即是简单的神经网络模型,如y=f(x),x为输入文本,y为输出文本,f即为神经网络。通过设置网络损失函数,使得输出y最大化接近目标target,实现训练神经网络模型的目的。而训练好的神经网络模型的参数矩阵,即是词向量。
(上述一段话通俗的讲:在 NLP 中,把 x 看做一个句子里的一个词语,y 是这个词语的上下文词语,那么这里的 f,便是 NLP 中经常出现的『语言模型』(language model),这个模型的目的,就是判断 (x,y) 这个样本,是否符合自然语言的法则,更通俗点说就是:词语x和词语y放在一起,是不是人话。
Word2vec 正是来源于这个思想,但它的最终目的,不是要把 f 训练得多么完美,而是只关心模型训练完后的副产物——模型参数(这里特指神经网络的权重),并将这些参数,作为输入 x 的某种向量化的表示,这个向量便叫做——词向量)
Word2vec包含CBOW(Continuous Bag-of-Words Model)和Skip-gram (Continuous Skip-gram Model)两种训练模式。两个模型的区别是前者通过周边的词对中心词进行预测,更具体的说是将周边的词向量进行加和,得到了中间的词;而skip gram是通过中心词,预测周围的词。
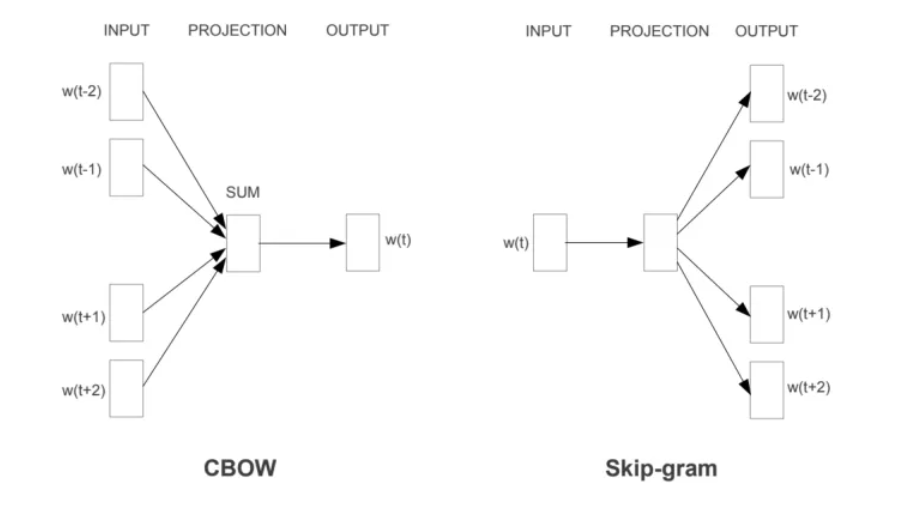
CBOW:根据中心词的上下文来预测输出中心词
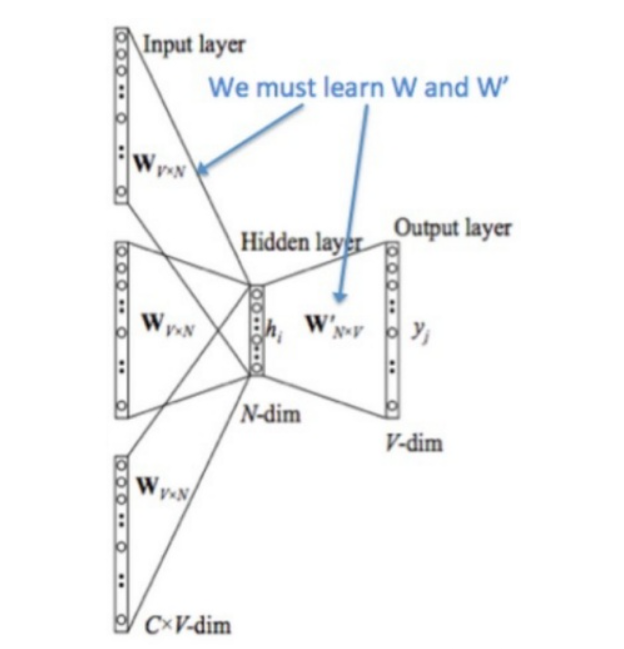
注意上图输入有C个,然后分别与W相乘:CBOW是根据上下文预测本词,所以上下文的个数为C,这C个词的one-hot分别与W相乘,相加取平均再与输出矩阵W’相乘获得输出进行loss计算。这里的矩阵W、即是生成的word的vector,也即我们需要的词向量。
训练过程:
1、输入:上下文单词的one-hot向量,假设单词向量空间为V,上下文单词个数为C;
2、所有one-hot分别乘以共享的输入权重矩阵W,维度V*N,N为个人指定维度,W为初始化权重矩阵;
3、所得所有向量相加求和取平均作为隐层向量,维度为1*N;
4、乘以输出权重矩阵W’ (N*V维度)
5、得到输出向量1*V,经softmax函数输出概率分布,概率最大的index即为预测的中间词;
6、损失函数,交叉熵损失,与true label 越相近越好。
为了更好的了解模型深处的原理,我们先从一个最简单的CBOW model(仅输入一个词,输出一个词)框架说起。
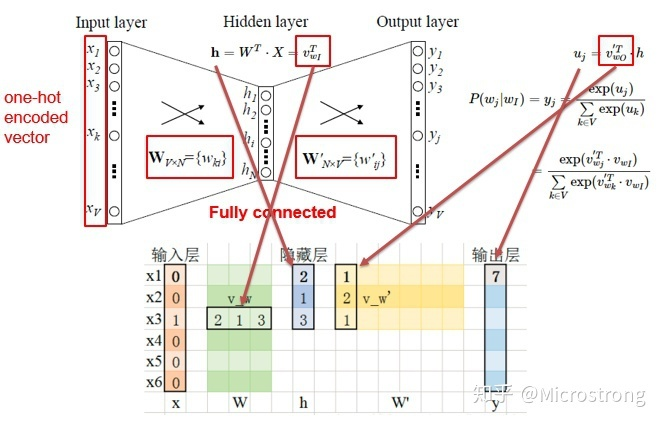
如上图所示:
- input layer输入的X是单词的one-hot representation(考虑一个词表V,里面的每一个词 都有一个编号i∈{1,…,|V|},那么词 的one-hot表示就是一个维度为|V|的向量,其中第i个元素值非零,其余元素全为0,例如:w2=[0,1,0,0,…,0]T);
- 输入层到隐藏层之间有一个权重矩阵W,隐藏层得到的值是由输入X乘上权重矩阵得到的(会发现,0-1向量乘上一个矩阵,就相当于选择了权重矩阵的某一行,如图:输入的向量X是[0,0,1,0,0,0],W的转置乘上X就相当于从矩阵中选择第3行[2,1,3]作为隐藏层的值);
- 隐藏层到输出层也有一个权重矩阵W’,因此,输出层向量y的每一个值,其实就是隐藏层的向量点乘权重向量W’的每一列,比如输出层的第一个数7,就是向量[2,1,3]和列向量[1,2,1]点乘之后的结果;
- 最终的输出需要经过softmax函数,将输出向量中的每一个元素归一化到0-1之间的概率,概率最大的,就是预测的词。
了解了Simple CBOW model之后,扩展到CBOW就很容易了,只是把单个输入换成多个输入罢了
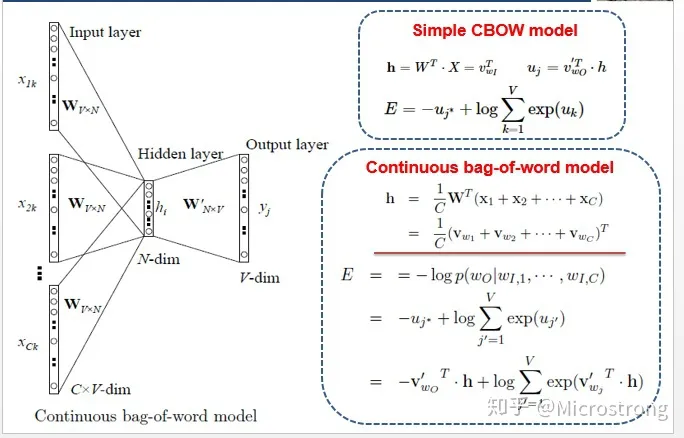
输入由1个词变成了C个词,每个输入Xik到达隐藏层都会经过相同的权重矩阵W,隐藏层h的值变成了多个词乘上权重矩阵之后加和求平均值。
CBOW模型流程举例
假设我们现在的语料是这一个简单的只有四个单词的句子:
{I drink coffee everyday}
我们选coffee作为中心词,window size设为2,也就是说,我们要根据单词 “I”, “drink” 和 “everyday” 来预测一个单词,并且我们希望这个单词是coffee。
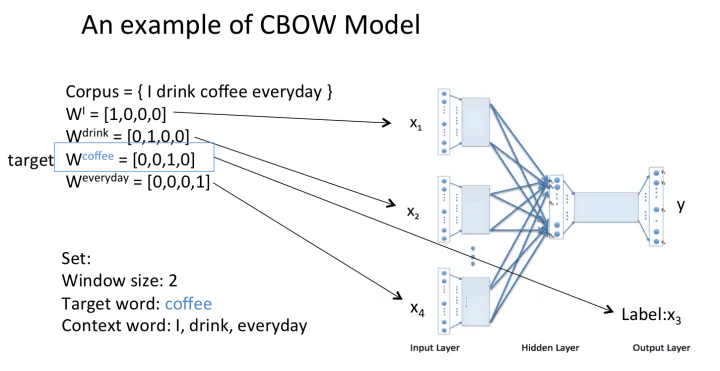
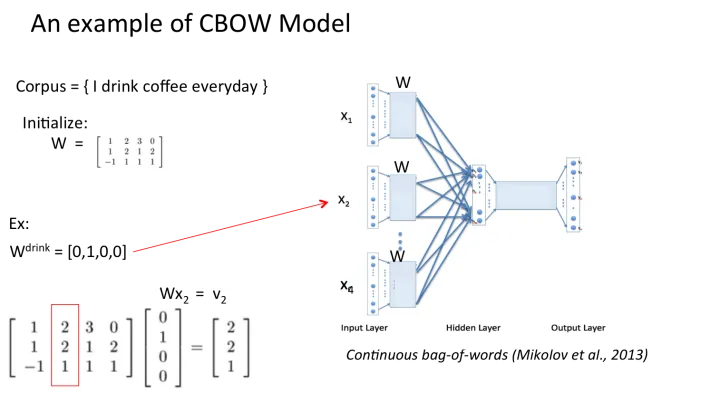
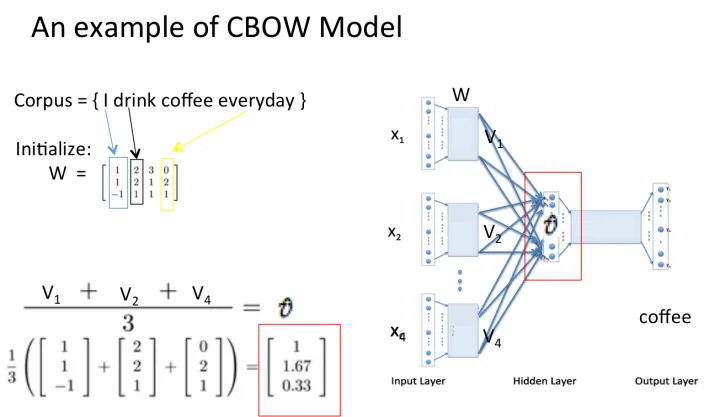
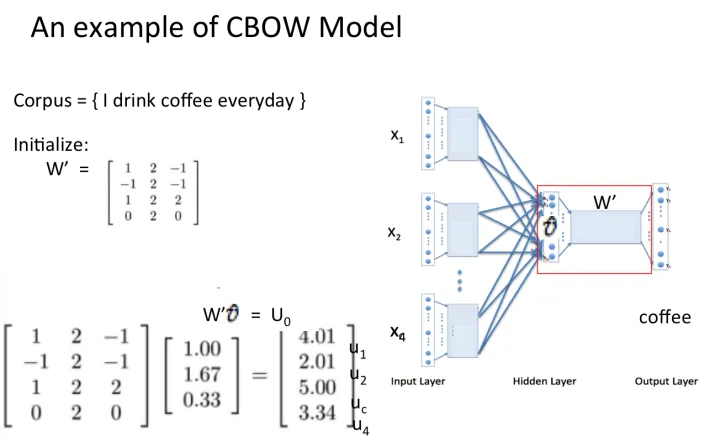
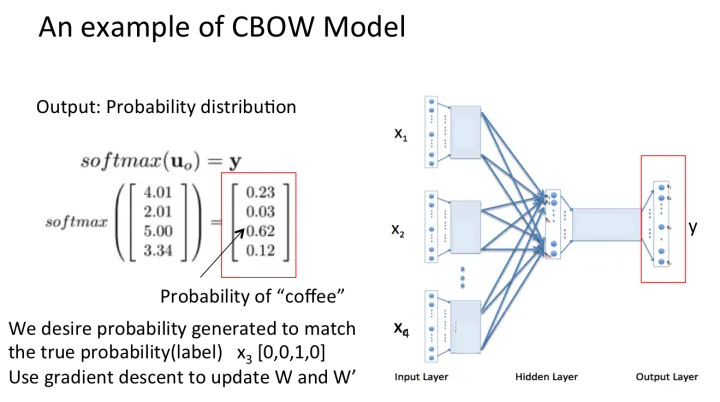
假设我们此时得到的概率分布已经达到了设定的迭代次数,那么现在我们训练出来的look up table应该为矩阵W。即,任何一个单词的one-hot表示乘以这个矩阵都将得到自己的word embedding。
Skip-gram Model:通过中心词,预测周围的词
Skip-gram model是通过输入一个词去预测多个词的概率。输入层到隐藏层的原理和simple CBOW一样,不同的是隐藏层到输出层,损失函数变成了C个词损失函数的总和,权重矩阵W’还是共享的。
一般神经网络语言模型在预测的时候,输出的是预测目标词的概率,也就是说我每一次预测都要基于全部的数据集进行计算,这无疑会带来很大的时间开销。不同于其他神经网络,Word2Vec提出两种加快训练速度的方式,一种是Hierarchical softmax,另一种是Negative Sampling…(未完)
Glove
word2vector在学习词与词间的关系上有了大进步,但是它有很明显的缺点:只能利用一定窗长的上下文环境,即利用局部信息,没法利用整个语料库的全局信息。鉴于此,GloVe诞生了,它的全称是global vector,很明显它是要改进word2vector,成功利用语料库的全局信息。
GloVe的全称叫Global Vectors for Word Representation,它是根据统计全局语料的词频来得到词向量。
如何实现?
- 首先根据语料库构建一个共现矩阵X,矩阵中的每个元素Xij代表整个语料库中,单词i和单词j共同出现在一个窗口中的次数。
- 构建词向量和矩阵之间的关系,论文的作者提出以下的公式可以近似地表达两者之间的关系:
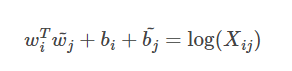

具体公式怎么实现见下文 - 有了公式就可以构造损失函数
- 不断迭代训练得到词向量
1.构建共现矩阵
- 首先构建一个空矩阵,大小为V × V ,即词汇表×词汇表,值全为0。矩阵中的元素坐标记为( i , j )
- 确定一个滑动窗口的大小(滑动窗口内中心词 i 两边的单词就是上下文环境)
- 从语料库的第一个单词开始,以1的步长滑动该窗口。中心词 i 从第一个单词开始
- 在窗口内,统计上下文环境中单词 j 出现的次数,并将该值累计到( i , j )位置上
- 不断滑动窗口进行统计即可得到共现矩阵
举例说明:
假设有语料库:i love you but you love him i am sad
这语料库只有1个句子,涉及到7个单词:i、love、you、but、him、am、sad。
如果我们采用一个窗口半径为2(窗口大小为5)的统计窗口,那么就有以下窗口内容:
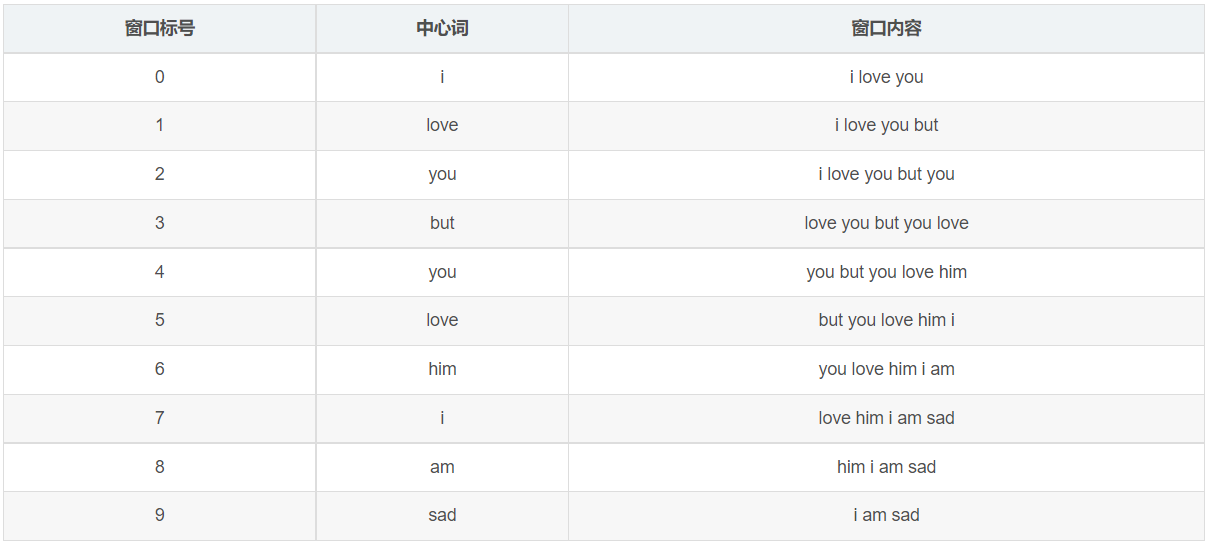 窗口0、1长度小于5是因为中心词左侧内容少于2个,同理窗口8、9长度也小于5。
窗口0、1长度小于5是因为中心词左侧内容少于2个,同理窗口8、9长度也小于5。
以窗口5为例说明如何构造共现矩阵:
中心词为love,语境词为but、you、him、i;则执行:
X love,but += 1
X love,you += 1
X love,him += 1
X love,i += 1
2-3.构建词向量和共现矩阵之间的公式关系,以及损失函数
首先了解一下什么是叫共现概率:我们定义 X 为共现矩阵,共现矩阵的元素 Xij 为词 j 出现在词 i 环境的次数,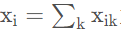](https://img-blog.csdnimg.cn/91b75afdbfc045d0a66b50bf1b97a6ea.png)
那么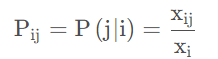 为词 j 出现在词 i 环境中的概率(这里以频率表概率),这一概率被称为词i和词 j 的共现概率。共现概率是指在给定的环境下出现(共现)某一个词的概率。
为词 j 出现在词 i 环境中的概率(这里以频率表概率),这一概率被称为词i和词 j 的共现概率。共现概率是指在给定的环境下出现(共现)某一个词的概率。
接下来阐述为啥要提共现概率和共现概率比这一概念。下面是论文中给的一组数据:
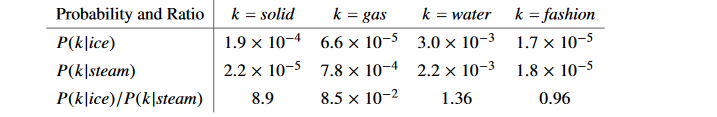
第一行,ice出现时,water出现的概率是0.003,大于ice出现时solid、gas、fashion词出现的概率。显然这是符合逻辑常理的。
第二行也是如此。
第三行:
当ice的语境下出现solid的概率应该很大,当steam的语境下共现solid的概率应当很小,那么比值就>>1。
当ice的语境下出现gas的概率应该很小,当steam的语境下出现gas的概率应该很大,那么比值<<1
当ice的语境下出现water的概率应该很大,当steam的语境下出现water的概率应该也很大,那么比值约等于1.
当ice的语境下出现fashion的概率应该很小,当steam的语境下出现fashion的概率应该也很小,那么比值约等于1.
| P(i,k)与P(j,k)的比值 | 单词j,k相关 | 单词j,k不相关 |
|---|---|---|
| 单词i,k相关 | 趋近1 | 很大 |
| 单词i,k不相关 | 很小 | 趋近1 |
所以说,P(i,k)与P(j,k)的比值能够反映词之间的相关性
明确一下,glove模型的目标是获取每个词的向量表示v。
不妨设我们现在已经得到了词i ,j,k的词向量Wi,Wj,Wk。通过上述推断,我们认为这三个向量通过函数的作用后,呈现出的规律与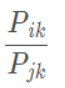 具有一致性。
具有一致性。
假设这个函数是F,则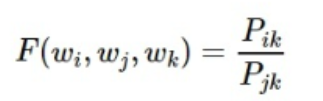
公式右边 Pik 和 Pjk 可以通过统计求得,公式左边Wi,Wj,Wk是我们模型要求的量,同时函数F是未知的
如果能够把函数F的形式确定下来,就可以通过优化算法求得词向量了。
论文的作者是怎么把F确定下来的呢:


另一篇作者的说明:

于是,glove模型的学习策略就是通过将两个词的词向量经过内积操作和平移变换去趋于两个词共现次数的对数值,这是一个回归问题。于是作者这样设计损失函数:
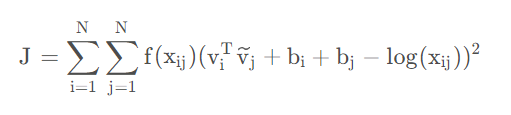
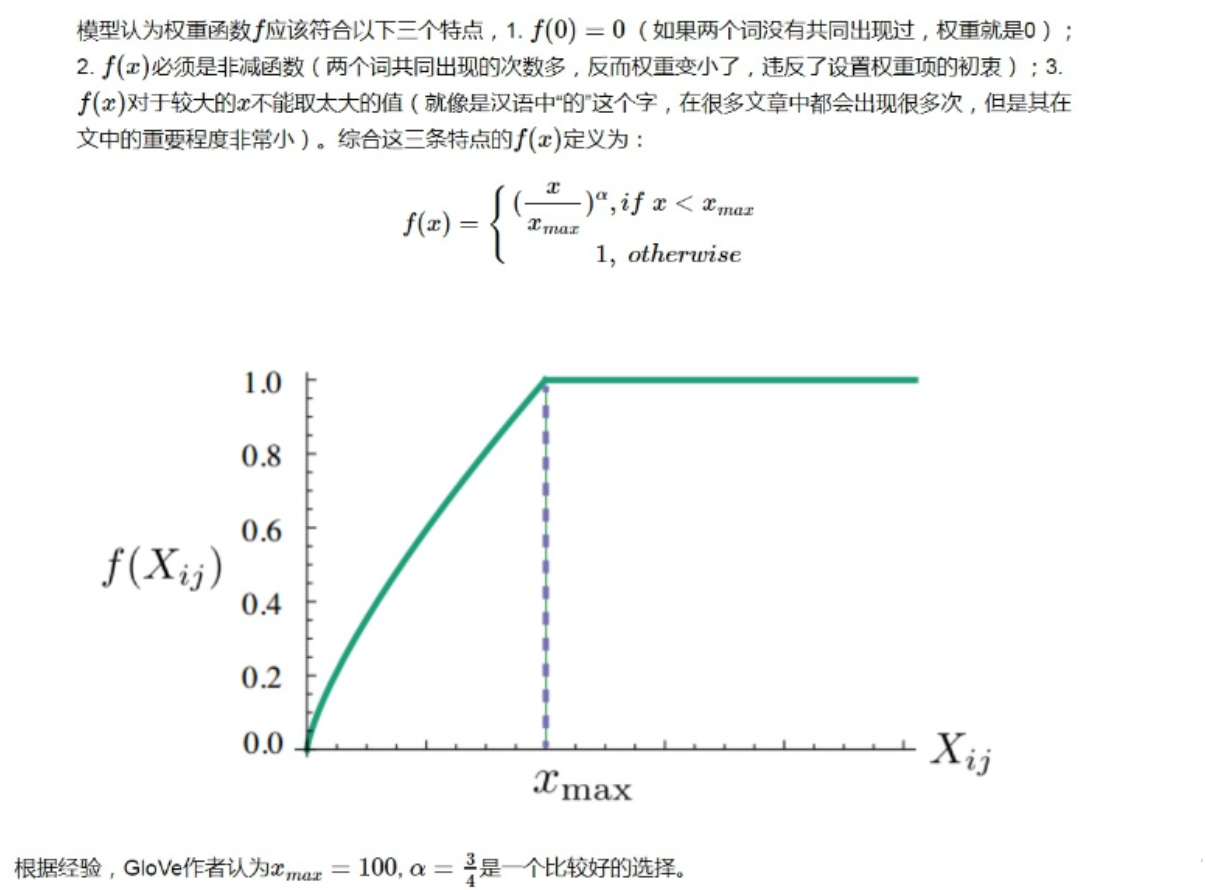
这里用的是误差平方和作为损失值,其中N表示语料库词典单词数。这里在误差平方前给了一个权重函数 f(Xij) ,这个权重是用来控制不同大小的共现次数 Xij 对结果的影响的。
为什么要添加这个函数呢?我们知道在一个语料库中,肯定存在很多单词他们在一起出现的次数是很多的(frequent co-occurrences),那么我们希望:
- 这些单词的权重要大于那些很少在一起出现的单词(rare co-occurrences),所以这个函数要是非递减函数(non-decreasing)
- 但也不希望这个权重过大(overweighted),当到达一定程度之后应该不再增加
- 如果两个单词没有在一起出现,也就是
Xij = 0,那么他们应该不参与到loss function的计算当中去,也就是f(x) 要满足 f(0) = 0
作者是这么设计这个权重函数的:
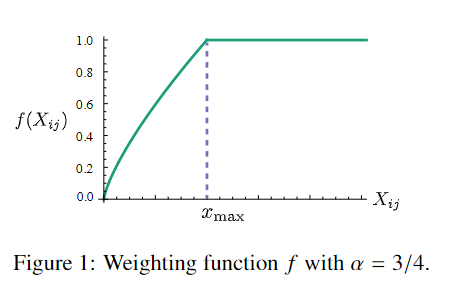
也就是说两个词共现次数越多,它占有更大的权重,损失值被放大,将被惩罚得更厉害些。两个词共现次数少的,占有更小的权重,损失值被缩小,将被惩罚得轻一些。这样就可以使得不常共现的一对词对结果的贡献不会太小,而不会过分偏向于常共现的一对词。
4.迭代训练,得到词向量
关于glove模型训练,大致是这样的:从共现矩阵中随机采集一批非零词对作为一个mini-batch的训练数据;随机初始化这些训练数据的词向量以及随机初始化两个偏置;然后进行内积和平移操作并与 logXik 计算损失值,计算梯度值;然后反向传播更新词向量和两个偏置;循环以上过程直到结束条件。
公式中的Wi 和 Wj 是我们要得到的向量,也是训练中要不断更新的参数。具体地,这篇论文里的实验是这么做的:采用了AdaGrad的梯度下降算法,对共现矩阵X中的所有非零元素进行随机采样,学习曲率(learning rate)设为0.05,在向量维度(vector size)小于300的情况下迭代了50次,其他大小的vectors上迭代了100次,直至收敛。最终学习得到的是两个vector是Wi 和 Wj。因为共现矩阵X是对称的,所以从原理上讲,Wi 和 Wj 也是相等的,他们唯一的区别是初始化时的值不一样,导致最终的值不一样。所以这两者其实是等价的,都可以当成最终的结果来使用。但是为了提高鲁棒性,我们最终会选择两者之和Wi + Wj 作为最终的vector(两者的初始化不同相当于加了不同的随机噪声,所以能提高鲁棒性)。
fastText
详细讲解请看fastText原理及实践
fastText 设计之初是为了解决文本分类问题的,只不过在解决分类问题的同时 fastText 也能产生词向量,因此后来也被用来生成词向量。
word2vec把语料库中的每个单词当成原子的,它会为每个单词生成一个向量。这忽略了单词内部的形态特征,比如:“apple” 和“apples”,两个单词有较多公共字符,即它们的内部形态类似,但是在传统的word2vec中,这种单词内部形态信息因为它们被转换成不同的id丢失了。
为了克服这个问题,fastText使用了字符级别的n-grams来表示一个单词。对于单词“apple”,假设n的取值为3,则它的trigram有
“<ap”, “app”, “ppl”, “ple”, “le>”
其中,<表示前缀,>表示后缀。于是,我们可以用这些trigram来表示“apple”这个单词,进一步,我们可以用这5个trigram的向量叠加来表示“apple”的词向量。
这带来两点好处:
-
对于低频词生成的词向量效果会更好。因为它们的n-gram可以和其它词共享。
-
对于训练词库之外的单词,仍然可以构建它们的词向量。我们可以叠加它们的字符级n-gram向量。
模型架构
fastText模型架构和word2vec的CBOW模型架构非常相似。下面是fastText模型架构图:
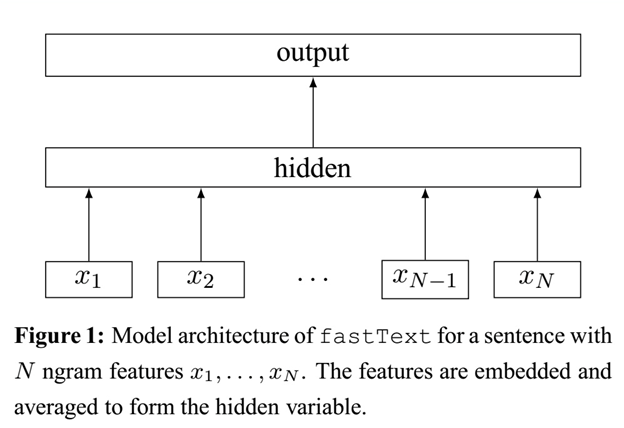
注意:此架构图没有展示词向量的训练过程。
可以看到,和CBOW一样,fastText模型也只有三层:输入层、隐含层、输出层(Hierarchical Softmax),输入都是多个经过向量表示的单词,输出都是一个特定的target,隐含层都是对多个词向量的叠加平均。
不同的是,CBOW的输入是目标单词的上下文,fastText的输入是多个单词及其n-gram特征,这些特征用来表示单个文档;CBOW的输入单词被onehot编码过,fastText的输入特征是被embedding过;CBOW的输出是目标词汇,fastText的输出是文档对应的类标。
值得注意的是,fastText在输入时,将单词的字符级别的n-gram向量作为额外的特征。在输出时,fastText采用了分层Softmax,大大降低了模型训练时间。
核心思想
观察模型的后半部分,即从隐含层输出到输出层输出,它是一个softmax线性多类别分类器,分类器的输入是一个用来表征当前文档的向量;
模型的前半部分,即从输入层输入到隐含层输出部分,主要在做一件事情:生成用来表征文档的向量。那么它是如何做的呢?叠加构成这篇文档的所有词及n-gram的词向量,然后取平均。叠加词向量背后的思想就是传统的词袋法,即将文档看成一个由词构成的集合。
(输入是每个词的one-hot吗,还是一个文本的n-gram?n-gram怎么加进去??如果从得到词向量的角度看,输入层到隐藏层中间的权重矩阵就是要得到的词向量,那么输入应该是每个词的one-hot,那么n-gram怎么加进去的??)
词、字、字符级n-gram?
一个单词如果从字符级n-gram工作,例如对单个单词matter来说,假设采用3-gram特征,那么matter可以表示成【<ma,mat,att,tte,ter,er>】五个3-gram特征,这五个特征都有各自的词向量,五个特征的词向量和即为matter这个词的n-gram词向量?,这样说,一个单词的n-gram词向量与单词本身的词向量区分开来
于是fastText的核心思想就是:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。这中间涉及到两个技巧:字符级n-gram特征的引入以及分层Softmax分类。
与word2vec比较
fastText 和 word2vec 类似,也是通过训练一个神经网络,然后提取神经网络中的参数作为词语的词向量,只不过 fastText 训练网络的方法是对文本进行分类。
此外 word2vec 的输入是多个词语的 noe-hot 编码,fastText的输入是多个单词及其n-gram特征;同时fastText为了解决类别过多导致的softmax函数计算量过大的问题,使用了层次softmax代替标准的softmax
fastText 和 word2vec 最主要的区别如下:
- 输入增加了n-gram特征
- 使用层次softmax做多分类
- 通过文本分类的方式来训练模型
ELMO
2013年的word2vec及2014年的GloVe的工作中,每个词对应一个vector,对于多义词无能为力。ELMo的工作对于此,提出了一个较好的解决方案。不同于以往的一个词对应一个向量,是固定的。在ELMo世界里,预训练好的模型不再只是向量对应关系,而是一个训练好的模型。使用时,将一句话或一段话输入模型,模型会根据上下文来推断每个词对应的词向量。这样做之后明显的好处之一就是对于多义词,可以结合前后语境对多义词进行理解。比如apple,可以根据前后文语境理解为公司或水果。
ELMO的本质思想是:事先用语言模型训练好每一个单词的Word Embedding,此时多义词无法区分。在实际使用Word Embedding的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义去调整单词的Word Embedding表示,这样经过调整后的Word Embedding更能表达在这个上下文中的具体含义。
ELMO结构
通过上述ELMO的本质思想,它可以分为两个阶段
- 第一个阶段是:利用语言模型进行预训练。
- 第二个阶段是:在做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。
第一阶段:预训练
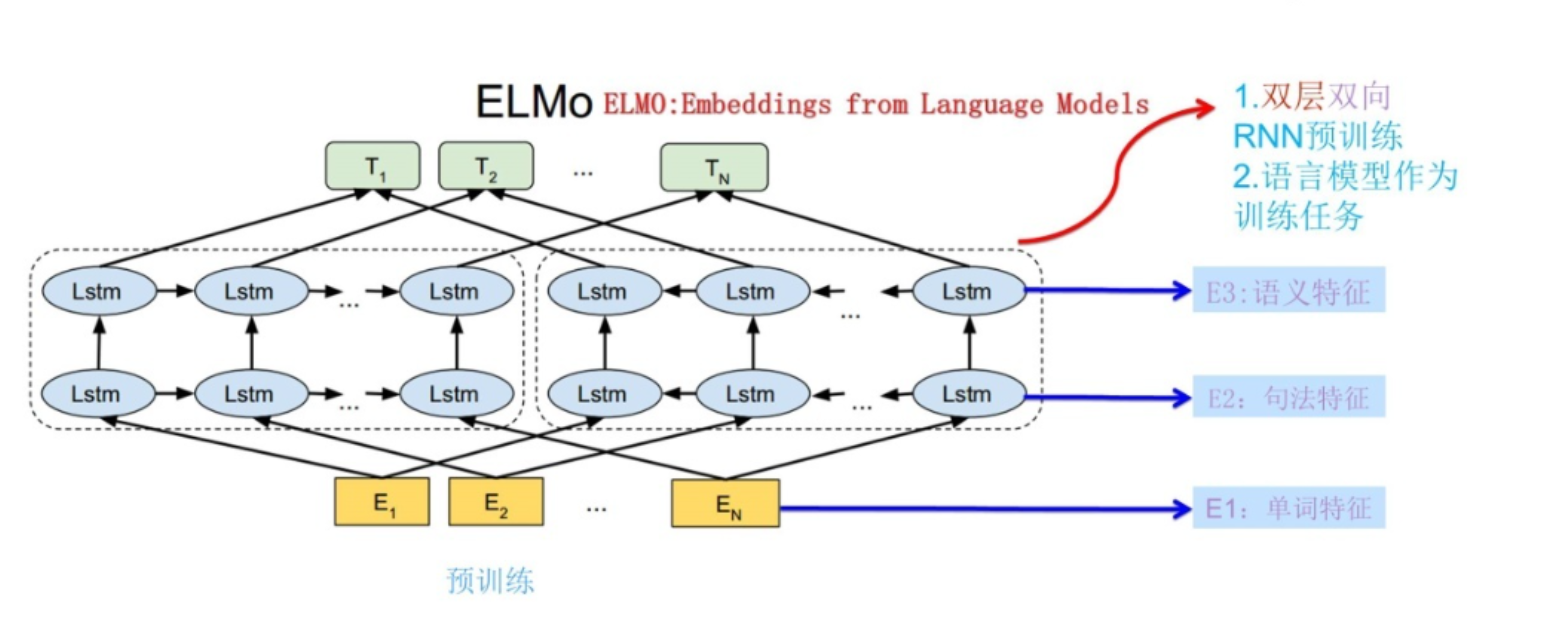
上图展示的是其预训练过程,它的网络结构采用了双层双向LSTM,目前语言模型训练的任务目标是:根据单词 W i W_{i} Wi 的上下文去正确预测单词 W i W_{i} Wi 。
关于LSTM、ELMO原理等的知识参考[13~16]
图中左端的前向双层LSTM代表正方向编码器,输入的是从左到右顺序的除了预测单词 W i W_{i} Wi 外的上文(Context-before);右端的逆向双层LSTM代表反方向编码器,输入的是从右到左的逆序的句子下文(Context-after);每个编码器的深度都是两层LSTM叠加。
使用这个网络结构利用大量语料做语言模型任务就能预先训练好这个网络,如果训练好这个网络后,输入一个新句子 Snew ,句子中每个单词都能得到对应的三个Embedding:
- 最底层是单词的Word Embedding
- 往上走是第一层双向LSTM中对应单词位置的Embedding,这层编码单词的句法信息更多一些
- 再往上走是第二层LSTM中对应单词位置的Embedding,这层编码单词的语义信息更多一些
所以说,ELMO的预训练过程不仅得到了单词的Word Embedding,还得到了一个双层双向的LSTM网络结构,而这两者后面都有用。
第二阶段:使用预训练好的特征做下游任务
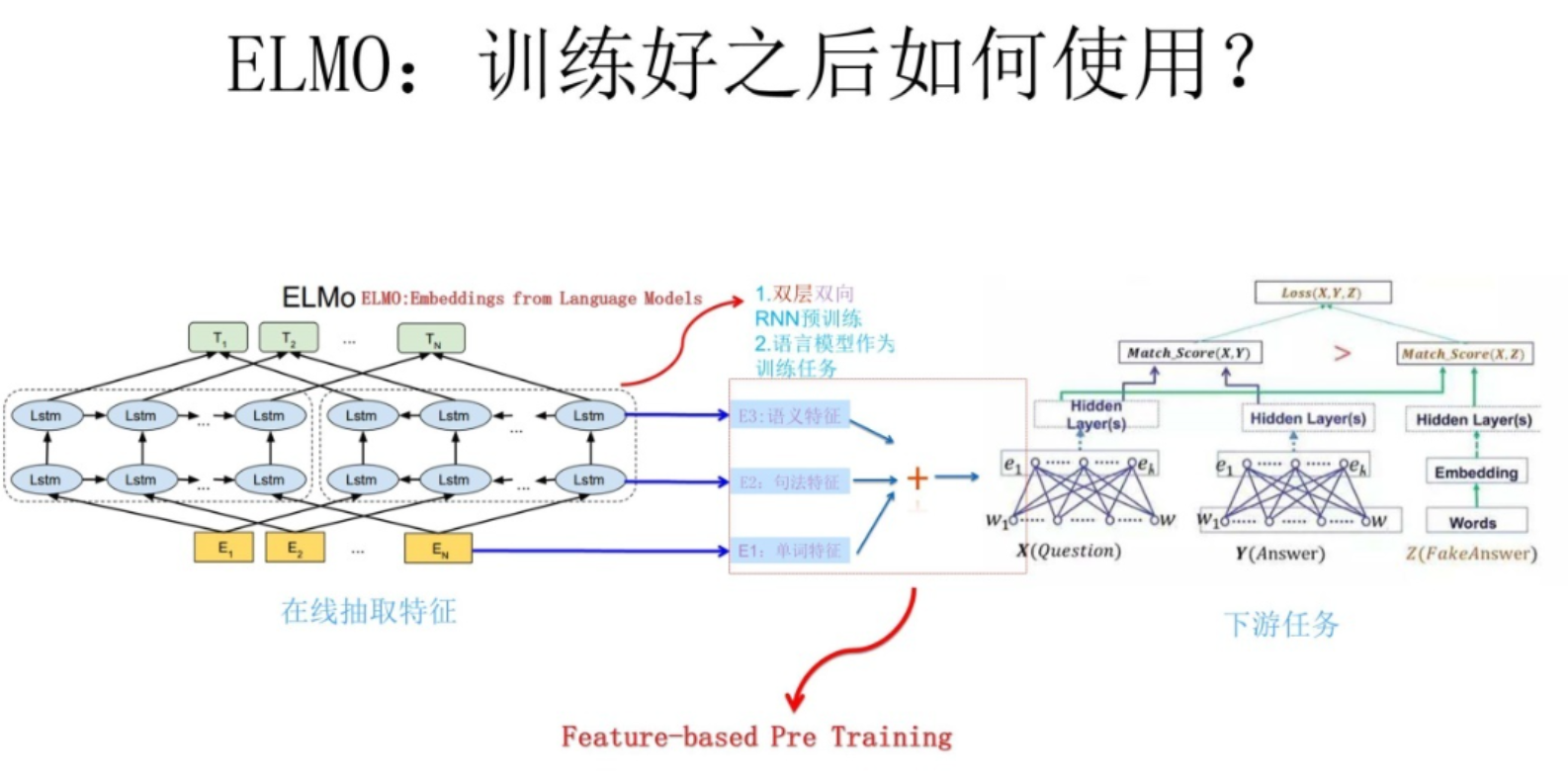
上图展示了下游任务的使用过程,比如我们的下游任务仍然是QA问题,此时对于问句X:
- 先将句子X作为预训练好的ELMO网络的输入,这样句子X中每个单词在ELMO网络中都能获得对应的三个Embedding。
- 之后给这三个Embedding中的每一个Embedding一个权重a,这个权重可以学习得来,根据各自权重累加求和,将三个Embedding整合成一个。
- 然后将整合后的这个Embedding作为X句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。
对于上图所示下游任务QA中的回答句子Y来说也是如此处理。因为ELMO给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为“Feature-based Pre-Training”。
GPT
现实世界中,无标签的文本语料库非常巨大,而带有标签的数据则显得十分匮乏,如何有效利用无标签的原始文本,对缓解自然语言处理相关任务对有监督学习方式的依赖显得至关重要。
论文中提出了半监督的方式来做语言理解,也就是无监督的pre-train,和有监督的fine-tune。该方法首先利用无监督的pre−train模型,学习到更加普遍、更适用的表征,然后模型以很小的微调迁移到众多特定的有监督学习任务上。
GPT 训练过程分为两个阶段:第一个阶段是 Pre-training 阶段,主要利用大型语料库完成非监督学习;第二阶段是 Fine-tuning,针对特定任务在相应数据集中进行监督学习,通过 Fine-tuning 技术来适配具体任务。
模型结构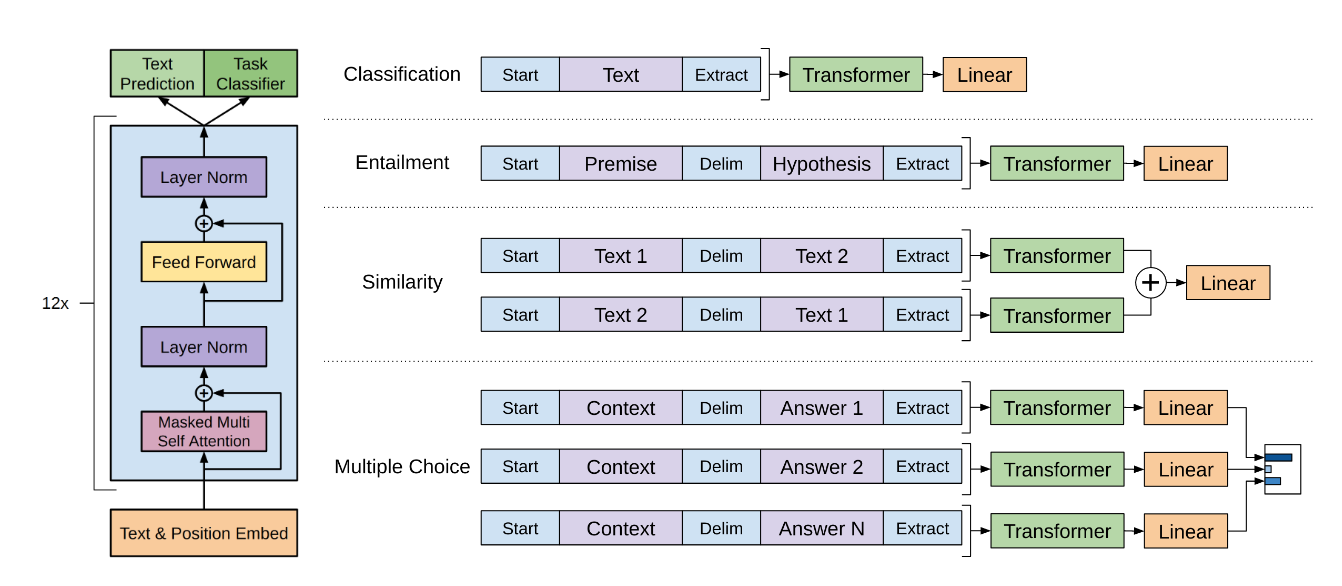
从上图我们可以看出,GPT 采用 Transformer 作为特征提取器,并基于语言模型进行训练。这里只使用了 Transformer 的 Decoder 部分,并且每个子层只有一个 Masked Multi Self-Attention(768 维向量和 12 个 Attention Head)和一个 Feed Forward,共叠加使用了 12 层的 Decoder。
这里简单解释下为什么没有用decoder中的encoder-decoder attention:语言模型是利用上文预测下一个单词的,因为 Decoder 使用了 Masked Multi Self-Attention 屏蔽了单词的后面内容,所以 Decoder 是现成的语言模型。又因为没有使用 Encoder,所以也就不需要 encoder-decoder attention 了。
- 第一阶段,在大型文本语料库上学习高能力的语言模型
- 第二阶段,用带有标签数据的判别任务对模型进行微调
无监督的预训练任务:基于 k k k个历史词 x i − k . . . x i − 1 x_{i-k}...x_{i-1} xi−k...xi−1,预测当前时刻的词 x i x_{i} xi
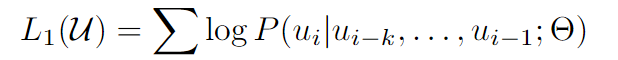
实验中使用多层transformers decoder层训练语言模型
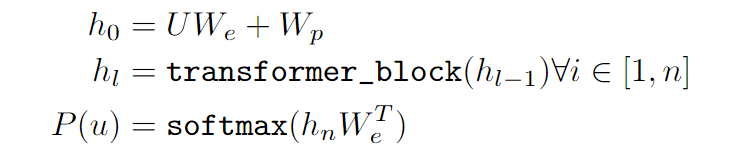
- U = ( x i − k . . . x i − 1 ) U=(x_{i-k}...x_{i-1}) U=(xi−k...xi−1)是前k个词token后的one-hot向量 --> k k k X |V|
- W e W_{e} We是token Embedding矩阵( ∣ V ∣ |V| ∣V∣ X d d d,d为词向量维度), W p W_{p} Wp是position embedding矩阵
- n n n是transformers的层数
有监督的微调
假设我们有一个数据集 C C C,每个实例由 x 1 , x 2 , . . . , x m x_{1},x_{2},...,x_{m} x1,x2,...,xm token序列和一个标签 y y y组成。
token序列通过我们预训练的模型,得到最后的transformers块
h
l
m
h_{l}^{m}
hlm ,然后用
W
y
W_{y}
Wy将它加到线性层进行输出,并预测标签
y
y
y。
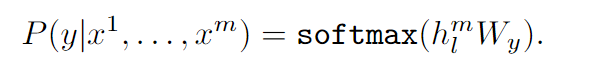
也就是要最大化目标:
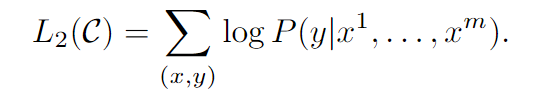
另外发现,把预训练好的语言模型作为微调的辅助目标,不仅可以使模型更具有泛化性,而且可以加速收敛。具体而言,优化下面目标:
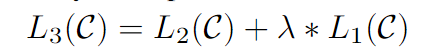
BERT
在GPT中,语言模型是单向的,每个token只能注意到前面的token。这样对于句子级任务不是最优的,对于微调的token级任务 (比如问答任务)是不利的,因为来自两个方向的上下文信息很重要。??
作者提出了改进方案:使用双向transformers编码层(在解码器中的self attention 层与编码器中的稍有不同,在解码器中,self-attention 层仅仅允许关注早于当前输出的位置。在softmax之前,通过遮挡未来位置(将它们设置为-inf)来实现)
预训练过程
训练任务:
- masked language model:随机mask输入中的一些tokens,然后在预训练中对它们进行预测。这样做的好处是学习到的表征能够融合两个方向上的context。
作者在他的实现中随机选择了句子中15%的 token 作为要mask的词。这样的缺点是缺点是 如果总是把一些词mask起来,未来的fine tuning过程中模型有可能没见过这些词。为了解决这个问题,作者在做mask的时候,
80%的时间真的用[MASK]取代被选中的词。比如 my dog is hairy -> my dog is [MASK]
10%的时间用一个随机词取代它:my dog is hairy -> my dog is apple
10%的时间保持不变: my dog is hairy -> my dog is hairy
为什么要以一定的概率保持不变呢? 这是因为刚才说了,如果100%的时间都用[MASK]来取代被选中的词,那么在fine tuning的时候模型会有一些没见过的词。那么为啥要以一定的概率使用随机词呢?这是因为Transformer要保持对每个输入token分布式的表征,否则Transformer很可能会记住这个[MASK]就是"hairy"。至于使用随机词带来的负面影响,文章中说了,所有其他的token(即非"hairy"的token)共享15%*10% = 1.5%的概率,其影响是可以忽略不计的
- next sentence prediction:选择一些句子对A与B,判断B是否是A的下一条句子。添加这样的预训练的目的是目前很多NLP的任务比如QA和NLI都需要理解两个句子之间的关系,从而能让预训练的模型更好的适应这样的任务。
输入
bert的输入可以是单一的一个句子或者是句子对,实际的输入值是三个词向量的相加
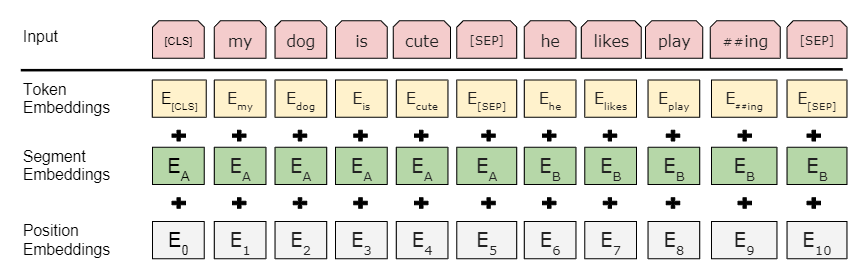
- Token Embedding:WordPiece tokenization subword词向量。
- Segment Embedding:表明这个词属于哪个句子(NSP需要两个句子)。
- Position Embedding:学习出来的embedding向量。这与Transformer不同,Transformer中是预先设定好的值。
微调Bert
微调很简单,因为transformers的self-attention机制可以建模很多下游任务,无论是单文本还是文本对…

 浙公网安备 33010602011771号
浙公网安备 33010602011771号