翻译ESSumm: Extractive Speech Summarization from Untranscribed Meeting
ESSumm: Extractive Speech Summarization from Untranscribed Meeting
从非转录会议中提取语音摘要(非转录:原音频,没有转化为文本或者其他格式)
论文地址 https://arxiv.org/abs/2209.06913
摘要
在本文中,我们为直接提取语音到语音的摘要提出了一种新颖的体系结构Essumm,它是一个无监督的模型,而无需依赖中间文本。与之前的文本表示的方法不同,我们旨在直接从语音中生成摘要,而无需转录。
首先,根据语音信号的声学特征提取一组较小的语音序列。对于每个候选语音段,基于距离的概括置信度得分是为潜在的语音代表度量而设计的。具体来说,我们利用现成的自我监督卷积神经网络来提取原始音频的深层语音特征。我们的方法会自动预测具有目标摘要长度的关键信息的最佳语音段序列。在两个著名的会议数据集(AMI和ICSI Corpora)上的广泛结果显示了我们基于语音的直接方法通过未转录的数据提高汇总质量的有效性。我们还观察到,我们的基于语音的无监督方法在关于最近基于笔录的需要额外的语音识别的汇总方法依然起作用
介绍
言语是人类之间交流的首选手段,自动语音摘要是语音理解研究中的一项非平凡而开放的任务。它具有广泛的现实应用程序,包括广播新闻总结[2],播客摘要[3],临床对话摘要[4]和自动会议摘要[5,6]。例如,自动会议摘要为我们提供了一个摘要,以准备即将举行的会议或回顾以前开会所做出的的决定[5]。鉴于原始的人类语音作为输入,语音摘要是生成语音或文本提出的摘要以捕获要点和亮点而不会丢失重要信息的任务。
我们提出的方法旨在以无监督的方式直接从原始演讲中产生典型的摘要,尤其是在未转录的会议上。当前的文献专注于基于转录的摘要,然而直接从语音中开发有效的方法来利用深层的语音特征尚未探索。具体而言,它在三个方面都受到动机和启发。首先,我们的模型是直接语音摘要方法。大多数自动语音摘要框架都在自动语音识别(ASR)输出之上使用文本总和技术,因此它们在很大程度上依赖于自动语音识别ASR工程的可用性和质量。因为自动语音识别(ASR)在多人对话或者训练受限制的语言资源上不是能很好的工作,我们的方法通过直接处理语音信号而不是转录文本来缓解这个问题。这样,我们的方法适用于开放式自发对话以及对ASR可能出现的错误有鲁棒性。此外,ASR系统应用在不同的语言时涉及不同语言的注释数据(当数据以多种不同形式可用时,会被注释或标记,以使其易于阅读和理解),因此,它不像现实世界中的有关声音的特征一样。其次,我们的模型是一种基于提取的方法。摘要技术通常分为两类,提取性的和抽象性的。虽然抽象性摘要可以更简洁,灵活,但提取性摘要可以保留原始格式,并且通常更流畅。此外,原始话语摘要语音比语音转录数据更容易理解[14]。因此,我们的框架能够自然而动态地操纵生成的语音摘要的长度,即,最近有一个挑战[15],从Spotify播客中选择了一分钟的持续时间,让用户了解播客听起来像讲的什么。最重要的是,当通过语音而不是文本提出所需的摘要结果时,我们的方法会有所帮助。这为那些包括现场直播广播等应用打开了大门。最后,我们的方法是完全无监督的。与监督方法[10]相比,不需要其他注释数据来构建语音摘要模型。
为此,我们设计了一个简单而有效的语音到语音摘要框架Essumm,该框架旨在自动有效地汇总无需转录数据的原始语音输入。我们的主要贡献是在以下三个方面:
- 据我们所知,Essumm是第一个探索和结合潜在语义分析并将其结合到讲话摘要的任务的架构。
- ESsumm是一种以完全无监督的方式自适应的语音到语音会议摘要框架.
- Essumm可以轻松地将提取的关键语音段串在一起,并在没有其他ASR和语音合成步骤的情况下制作简短的音频摘要
2.相关工作
2.1基于声音的语音摘要
直接语音摘要方法已在文献中进行了探讨。有限数量的先前工作直接处理语音输入,以进行自动语音摘要而无需转录[7、17、18、19、20]。Maskey等[17]查验了关于声学和韵律特征的隐藏的马尔可夫模型,以选择口语文档的细分,而Flamary等 [7]搜索经常性语音模式的重复 [[19]通过识别经常性的基于声学的模式来总结多个口语文档。[18]利用计算机视觉技术以检测可能的重复。最近,[20]调查了转弯功能,以检查会议段是否包含提取性摘要对话行为。但是,这些先前的作品主要集中于识别重复性模式或使用手工制作的特征。取而代之的是,我们的方法从提取的深层语音特征中以基于距离的方式总结了会议。
2.2基于笔录的语音摘要
现有工作[21、11、12、10、22、9、23]通常将语音摘要问题在两个阶段的过程中作为文本摘要问题,因为事实上文本摘要的任务已经有很多工作和快速的进展[24,25,26]。具体而言,他们首先使用ASR engines从音频输入(即单词级信息)生成笔录,然后应用现有的成熟文本摘要方法来产生摘要。在基于笔录的模型中,先锋最大边缘相关(MMR)[21]迭代选择与整个文档相似的最相关句子。Textrank [11]是一种基于图形的关键字提取算法,其中每个关键字由图中的节点表示。Clusterrank [12]通过包括噪声和冗余的措施来扩展Textrank [11]。HMNET [10]实现了基于transformers的编码器-解码器网络。[22]设计了一个目标函数,该目标函数是由贪婪算法优化的,用于会议域中的提取性摘要。[9]采用一种基于图的方法以无监督的方式实现基于文本的抽象摘要。[23]扩展到从各种方式中建模概念。但是,所有上述转录和摘要工作的重点主要局限于容易出错的副本进行。在这项工作中,我们旨在以语音到语音的方式实现摘要,而无需转录。
2.3表示语音学习
最近,有几项工作重点是利用与语音相关的任务进行预训练的语音表述,包括语音识别[27,28]和语音增强[29]。与传统的手工特征相比,包括暂停,持续时间,基本频率(F0)和MEL频率曲线系数(MFCC),各种预训练的表示可以在语音识别任务中得到显着改善[27]。特别是最近的WAV2VEC2.0[28],它是一个基于transformers的语音框架,可以通过预测语音掩盖部分的语音单元来训练。建立在Wav2Vec2.0的深度语音表示基础上,我们的摘要框架捕获了语音段之间的丰富关系并生成了有效的摘要。
3.我们的方法
在这项工作中,我们专注于提取性摘要的任务。Essumm将原始语音作为输入,并生成一个涵盖最重要信息的摘要。我们的目标是执行语音摘要并生成一个无抄录文本的提取性摘要,我们能够保留诸如说话者的声音,演示风格,幽默类型和生产质量之类的属性。我们的任务主要有两个挑战。首先,所有重要的关键段应涵盖并包含在输出摘要中。其次,被生成的摘要应进行排序和组织。
如图1所示,体系结构中有三个主要步骤,包括段生成,关键段提取和关键段串联。为了应对第一个挑战,Essumm在最近的工作中建立了提取深层语音特征的表示形式。具体而言,我们使用预训练的Wav2Vec2.0 [28]提取深层语音特征表示,然后将其投射到高维的音素可能性中,并使用K-Means群集聚类算法,对在欧几里得距离上使用潜在语义分析的基于段的重要性进行评分和排名。为了解决第二个挑战,我们将关键段共同结合在一起,以形成有长度约束的语音摘要输出。
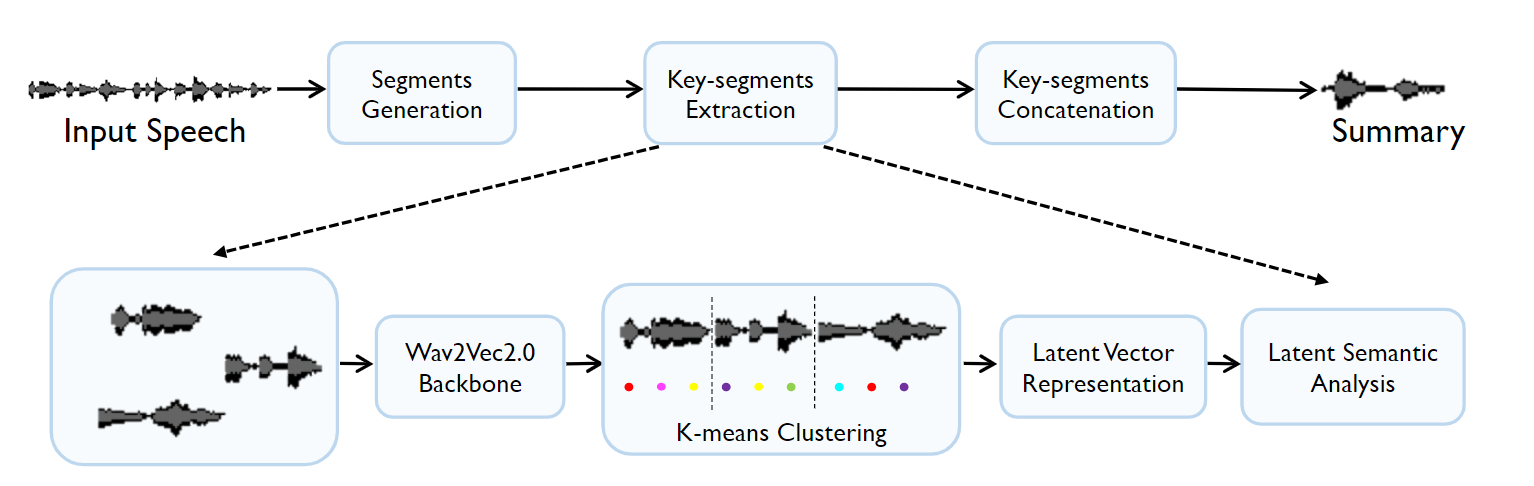
ESSumm架构概述。它由三个阶段组成。首先,根据声学信息将整个语音输入划分为较小的片段。然后,执行关键片段提取,具体而言,我们使用预训练的WAV2VEC2.0提取深层语音特征表示,然后使用K均值聚类算法将其投射到高维音素概率上,并使用潜在语义分析对基于欧几里得距离的片段的重要性进行评分和排名。最后,我们将关键片段连接在一起,以形成有长度约束的语音摘要输出。
3.1片段生成
语音音频是一个连续的信号,可捕获录音的许多方面,而没有明确的分段单词或其他单元[28]。鉴于原始的输入语音,大多数现有的摘要性工作倾向于基于语音识别技术转录本生成语音片段,本质上还是进行文本预处理以获取句子级分段 [3, 10, 9, 23]。另外,我们基于沉默区域的声学信息(使用“spurt”通过至少500毫秒的沉默将输入划分)[20]把整个输入语音划分为许多较小的片段。通过这种方式,我们基于语音的沉默间隔提取片段,而不依赖可用和有效的语音识别技术(在不利于声学的情况下,它通常不是最优的[8])。
3.2关键片段抽取
除了第一阶段的单个语音片段,我们还执行了片段评分和片段选择。简单地说,我们能够根据“转弯”信息来检测关键片段,例如,每个语音片段的平均音高的绝对差异[20]。另外,我们建议利用预训练的Wav2Vec2.0 [28]来提取语音段的深层语音特征。然后,我们根据语音表示的度量距离使用潜在的语义分析来评分并对候选片段的重要性进行排名。Wav2Vec2.0促进了高水平上下文表示的学习并且展示了它在提高语音识别任务上的潜力,因此我们使用预训练的Wav2Vec2.0来提取每个片段的深层语音特征。每个语音片段都由与语音相关的深层特征表示来编码,而不是手工制作的声学特征。在我们的语音摘要案例中,预训练的Wav2Vec2.0模型使我们能够编码强大的潜在语音表示。
另一方面,我们在这项工作中利用了潜在的语义分析。首先,将语音表示形式投影到高维音素概率中。启发性地,我们在提取的深层语音特征代表上应用K-均值聚类,以获取每个片段的音素群集ID的顺序。通过这种方式,我们使用矢量语音模型表示形式来表示每个具有一系列群集ID的片段。如图1中的K-均值聚类模块所示,每个语音段的不同圆圈是指其投影向量。具体而言,不同的颜色对应于不同的群集ID。然后,我们根据音素的TF-IDF表示每个语音段。IDF [30]是经典信息检索模型中广泛使用的词汇统计功能。在我们的情况下,TF-IDF向量能够捕获音素的意义。详细的说,我们采用TF-IDF值来测量每个语音片段的冗余和相关性,其中TF在片段级别计算,IDF在整个输入音频中计算。在基于TF-IDF获得每个段的向量表示后,我们利用主成分分析(PCA)表示整个输入语音,我们将欧几里得距离用于整个音频输入的特征向量作为置信度分数。具体而言,整个语音输入的每个段和特征向量的TF-IDF向量之间的欧几里得距离与置信分数成反比。
作为Essumm的关键部分,Wav2Vec2.0深层语音特征提取模块提供了高效而有效的语音特征模型。因为wav2vec2.0学习了几种语言共有的语音单元,所以我们的框架从中受益,并且对多种不同语言是普遍适用的。此外,与其他有监督的会议摘要方法相比,不需要昂贵且耗时的注释。为此,我们相信基于WAV2VEC2.0的特征与潜在的语义分析相结合,能够直接预测语音段的相对重要性。
3.3关键片段串联
最后,我们提取得分最高的几个片段,以形成原始输入语音音频的提取性摘要。我们通过预定义摘要的时间长度或者通过预定义的单词数量,(我们只是生成所有基于重要性的语音段的顺序,然后计算长度直至达到目标摘要长度)来指定生成的摘要的长度。大多数先前的工作都是基于单词计数生成目标摘要。但是,最近的挑战[15]旨在从原始播客中产生一分钟的摘要。在我们的情况下,由于目标长度是按照时间长度,而不是单词数量,因此Essumm自然地满足了需求,而无需额外的语音合成器步骤。
为此,可以在两个方面提高生成的语音摘要质量。首先,最先进的自监督神经网络wav2vec2.0 [28]准确地捕获了来自原始输入音频的语音单元特征,并从语音段中学习了强大的语音表示。据我们所知,Essumm是第一项直接在语音摘要任务上直接采用自监督神经网络的工作。其次,Essumm可以轻松地将提取的关键语音片段连接在一起,并在没有其他ASR和语音合成器步骤的情况下产生简短的音频摘要。
WAV2VEC2.0
一种用原始音频进行自监督学习的框架。方法是通过多层卷积神经网络编码语音音频,然后由此产生的潜在语音表示,类似于掩码语言模型。潜在表示被送到一个Transformers网络中构建上下文表示,然后通过对比任务(区分真正的潜在语音和干扰物)对模型进行训练。
模型
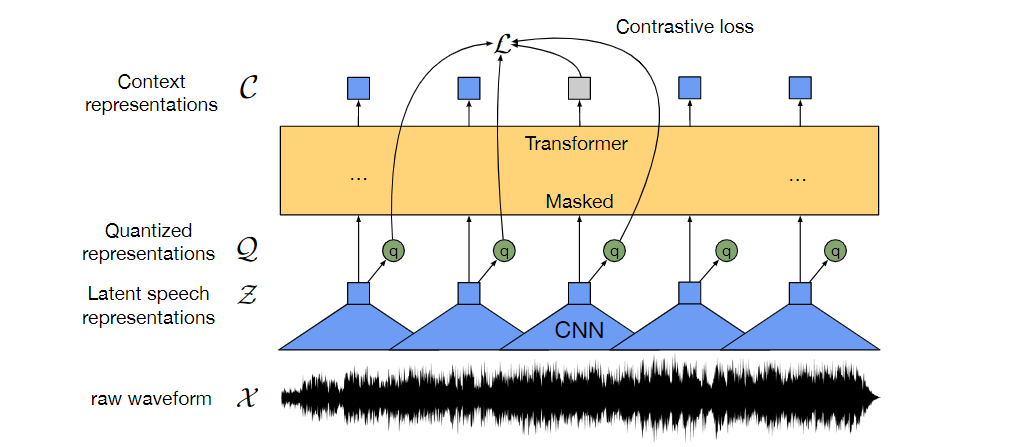
模型是由由多层卷积神经网络的特征编码层组成:输入原始音频 X X X,输出 T T T个时间步长的潜在语音表示 z 1 , z 2 . . . , z T z_{1},z_{2}...,z_{T} z1,z2...,zT。
然后送到一个Transformers g g g: Z → C Z→C Z→C 来构建从整个序列中捕获信息的表示 c 1 , c 2 , . . . , c T c_{1},c_{2},...,c_{T} c1,c2,...,cT
特征编码层的输出通过量化模块被离散化为 q T q_{T} qT Z → Q Z→Q Z→Q来表示自监督学习的目标。
特征编码器
编码器由几个块组成,其中包含由层归一化和GELU激活函数的时间卷积。将编码器的原始波形输入标准化为零均值和单位方差。编码器的总步幅(stride)确定输入Transformers的时间步长 T T T的数量
用Transformers的上下文表示
特征编码器的输出被送到一个遵循Transformers结构的网络中。与原始Transformers不同的是,使用了一个卷积层代替原始的绝对位置编码嵌入。我们将卷积的输出添加到输入中,然后应用层归一化。
量化模块
对于自监督训练,我们通过量化模块把特征编码器 z z z的输出离散为一组有限的语音表示。这种选择在先前的工作中取得了良好的结果,该工作在第一步中学习离散单元,然后学习上下文表示。
乘积量化模块的作用是将FeatureEncoder的输出离散化成为了一组数量有限的语音表示,对于乘积量化的解释:
乘积量化,是指笛卡尔积(Cartesian product),意思是指把原来的向量空间分解为若干个低维向量空间的笛卡尔积,并对分解得到的低维向量空间分别做量化(quantization)。这样每个向量就能由多个低维空间的量化code组合表示。这里的量化不是将float量化成int,而是把连续空间量化成有限空间。
1、乘积量化的原理
通俗说就是
- 把原来连续的特征空间假设是d维,拆分成G个子空间(codebook),每个子空间维度是d/G。
- 然后分别在每个子空间里面聚类(K-mean什么的),一共获得V个中心和其中心特征。
- 每个类别的特征用其中心特征代替。
结果就是,原来d维的连续空间(有无限种特征表达形式),坍缩成了有限离线的空间[GxV],其可能的特征种类数就只有G*V个。
2、乘积量化巧妙在哪儿
乘积量化操作通过将无限的特征表达空间坍缩成有限的离散空间,让特征的鲁棒性更强,不会受少量扰动的影响(只要还在某一类里面,特征都由中心特征来代替)。这个聚类过程也是一个特征提取的过程,让特征的表征能力更强了。
损失函数
CPC
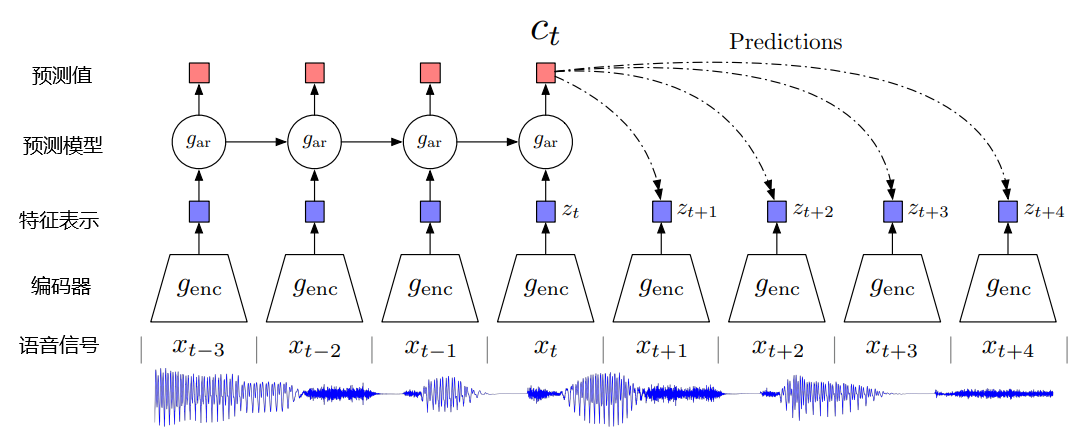
基本结构
- 输入,使用一维音频信号作为输入,而非FFT或者Fbank特征
- 编码器encoder,用于对一维信号进行编码,提取特征,一般是一维卷积。
- 潜在特征z(t),输入音频通过encoder卷积之后得到的输出。
- 预测模型ar,将t时刻及之前的特征输入预测模型中,预测接下来几帧特征的值,一般为LSTM/RNN。
- 上下文特征c(t),预测模型的输出,也是最终用于微调下游任务的特征。
损失函数
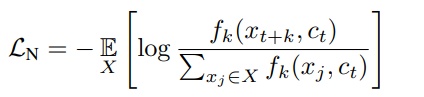
相似度函数
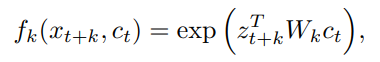
f
k
f_{k}
fk是
z
t
+
k
z_{t+k}
zt+k和
c
t
c_{t}
ct的相似性度量函数,可以是函数形式、可以是内积、也可以是余弦距离。
z
t
+
k
z_{t+k}
zt+k是t时刻起,未来第k帧的潜在特征,每一个k都对应了一个
f
k
(
x
)
f_{k}(x)
fk(x)。xj∈Xn(n=1,2,3…N)参与loss计算的这个N个样本中,有1个正样本
z
t
+
k
z_{t+k}
zt+k,和N-1个负样本,其中负样本是随机从其他时刻采样的值。整个损失函数的目的是使
z
t
+
k
z_{t+k}
zt+k 跟
W
k
c
t
W_{k}c_{t}
Wkct 的相似度尽量的高,跟其他负样本的相似度尽量的低,这样loss才能尽可能的小。
参考文章
wav2vec 2.0的损失函数由两部分构成,对抗性损失
L
m
L_{m}
Lm和多样性损失
L
d
L_{d}
Ld
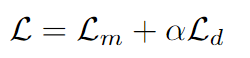
L m L_{m} Lm的形式和CPC是相似的,区别在于使用余弦距离sim代替原来的linear映射层,同时用乘积量化的结果qt代替原来zt(表征能力更强)。
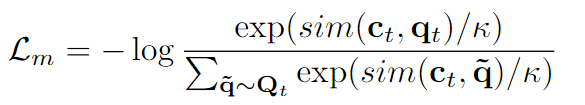
L
d
L_{d}
Ld是新引入的多样性损失,其目的是监督乘积量化中的聚类过程,期望每个中心点尽量的远。其中G是codebook数量,V是聚类中心的数量,p是某个特征在某个(g,v)子空间的概率值,其具体表达式就是gumble softmax的表达式。
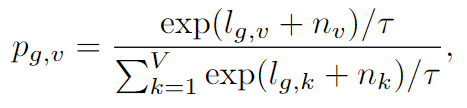

 浙公网安备 33010602011771号
浙公网安备 33010602011771号