Listen、Attention、Spell模型
LAS是一个做语音识别的经典seq2seq模型,主要分为三个部分Listen、Attention、Spell
Listen
Listen部分就是一个encoder。
输入声学特征向量,提取信息、消除噪声,输出向量。
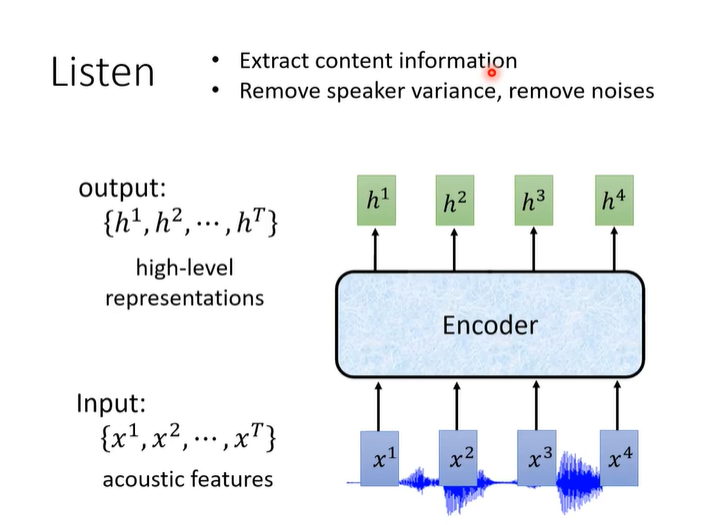
encoder可以是RNN
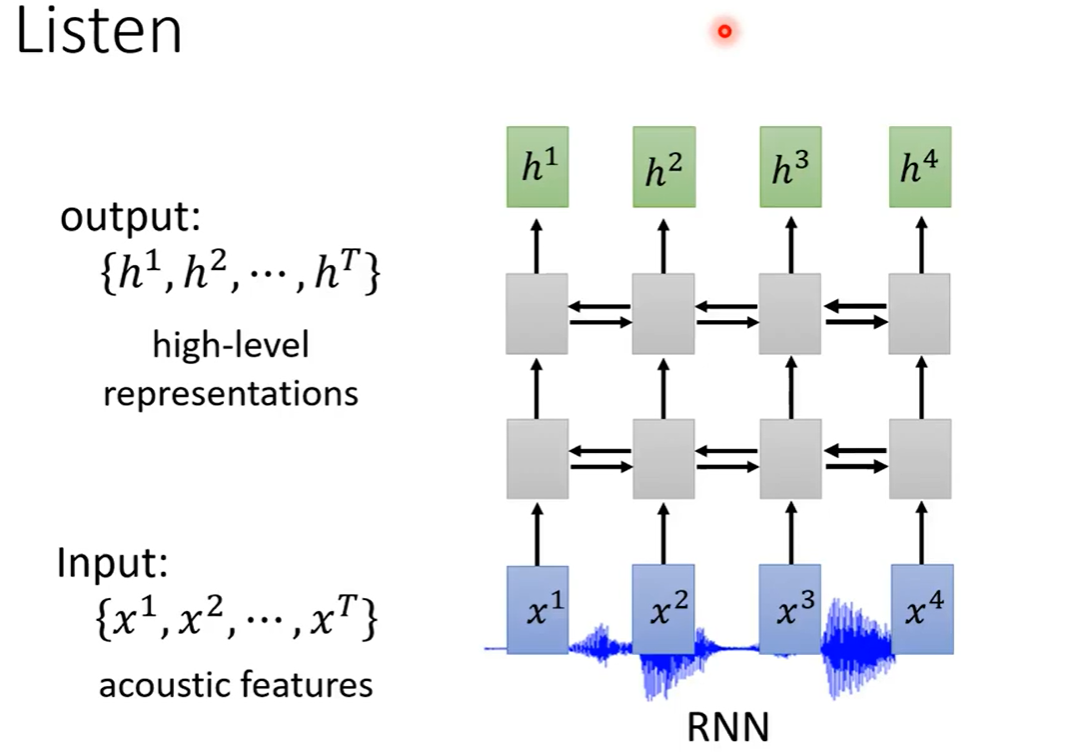
也可以是CNN。比较常见的是先用CNN,再用RNN
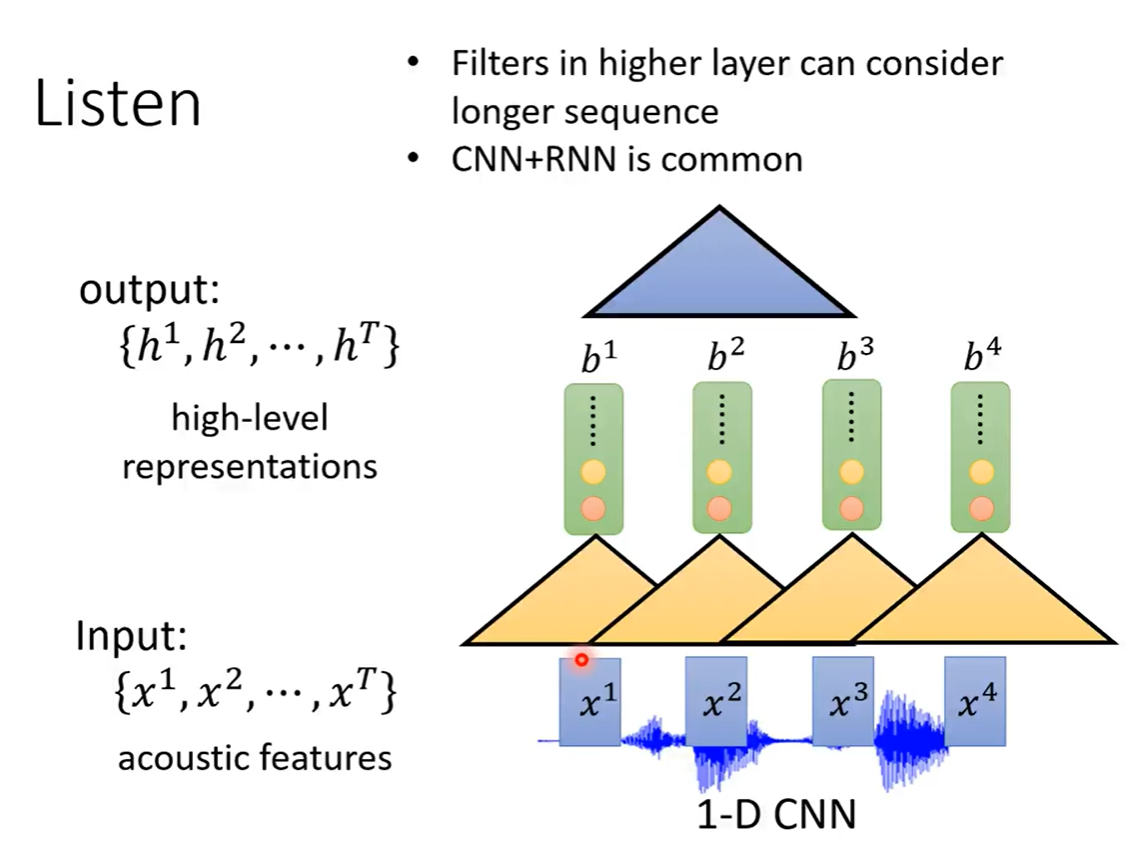
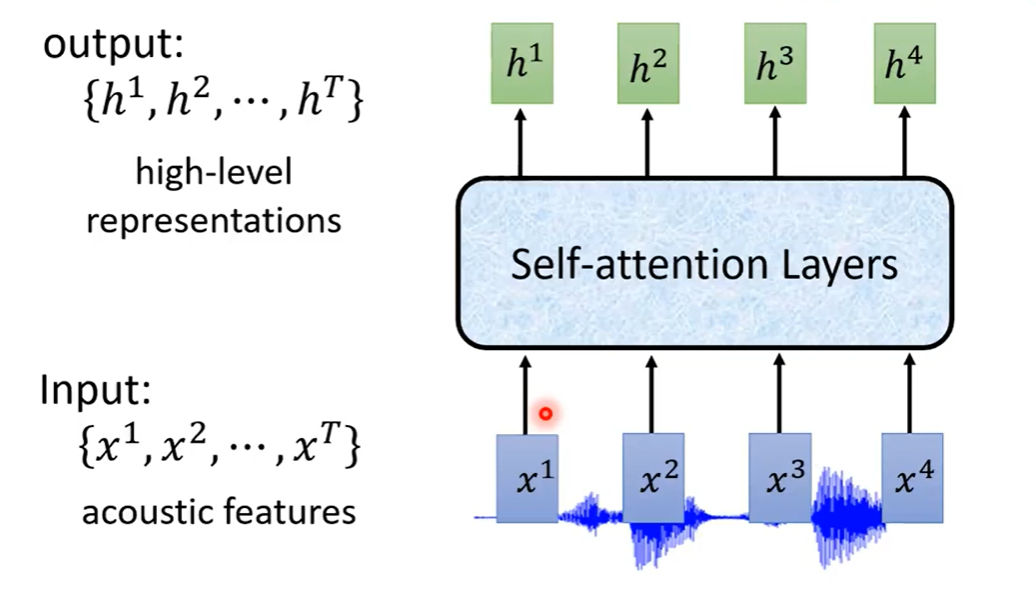
还有一种趋势是使用Self-Attention
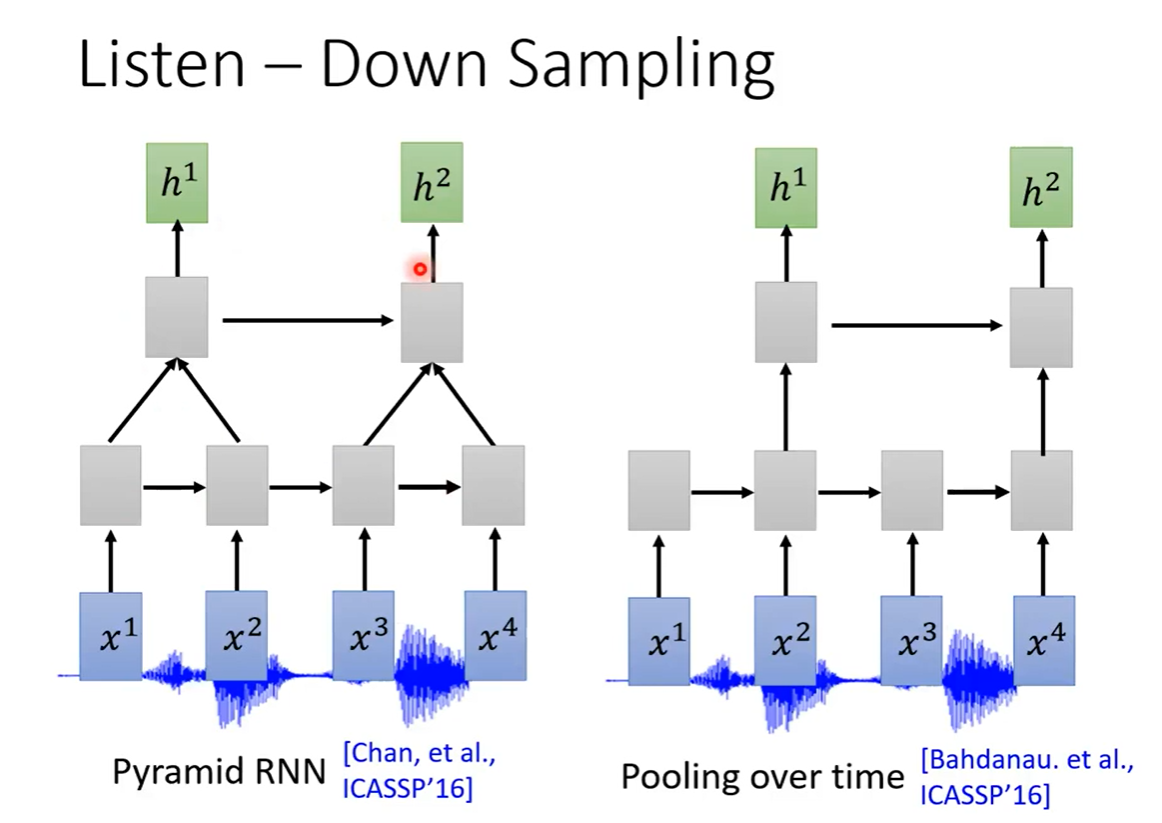
Down Sampling减少取样
由于声音的采集通常都是很大数据量的。比如采样率为16KHz需要在一秒钟采集16000个采样点,所以通常需要对声音的特征向量进行Down Sampling,减少样本数。
对于RNN,
方法一是通过使用两层RNN,4个向量通过第一层RNN输出4个向量,通过第二个RNN输出2个向量
方法二是把通过RNN输出的四个向量中,每隔一个输出向量
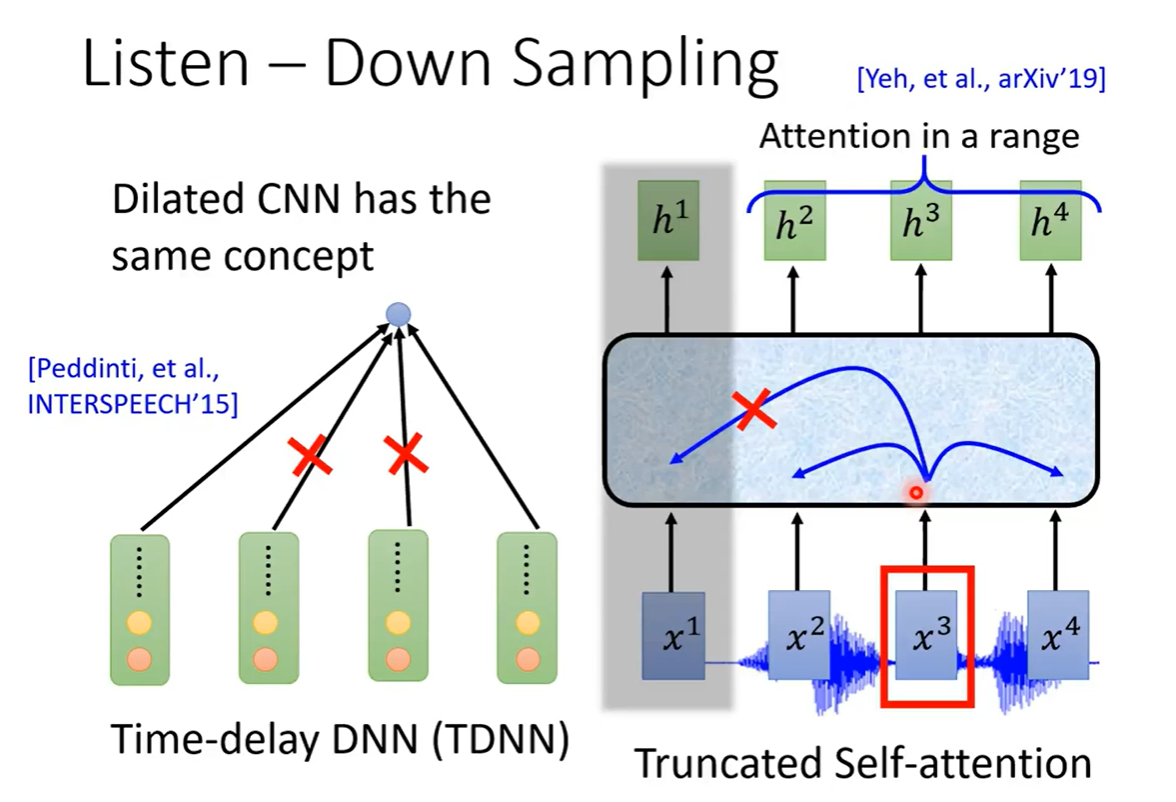
对于CNN,使用TDNN的方法,可以认为一段附近的几个特征向量差不多,采取使用第一个和最后一个向量,减少样本参数。
对于Self-Attention,计算当前向量和所有向量(1秒16K)计算量太大,只计算一个范围内的注意力。
Attention
我们可以直接编码解码之后直接输出,但是我们当前的编码解码不仅限于这一个编码向量,还取决于周围的编码向量,所以要做attention。
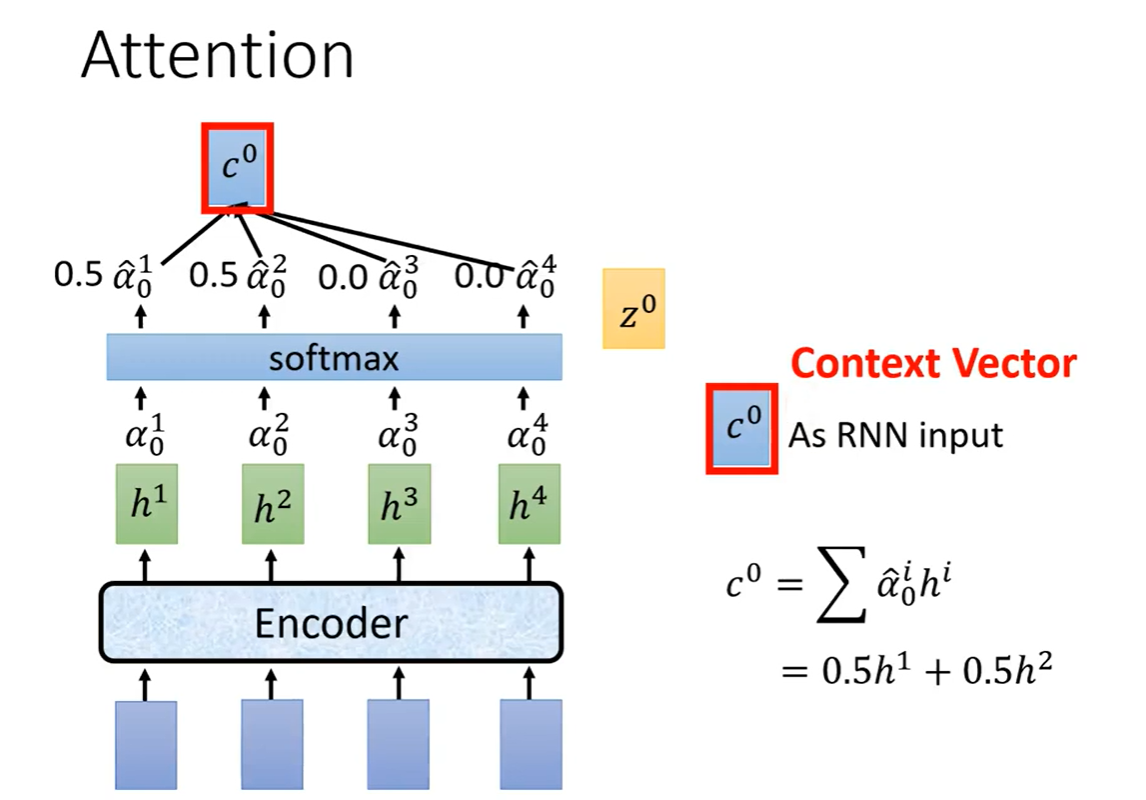
注意力机制如下图所示。
z
z
z是待训练的向量,初始时随机初始化,
z
z
z与每个
h
h
h做match得到注意力分数
α
α
α。
match的方法有两种,一种是Dot-product,另一种是Addictive。
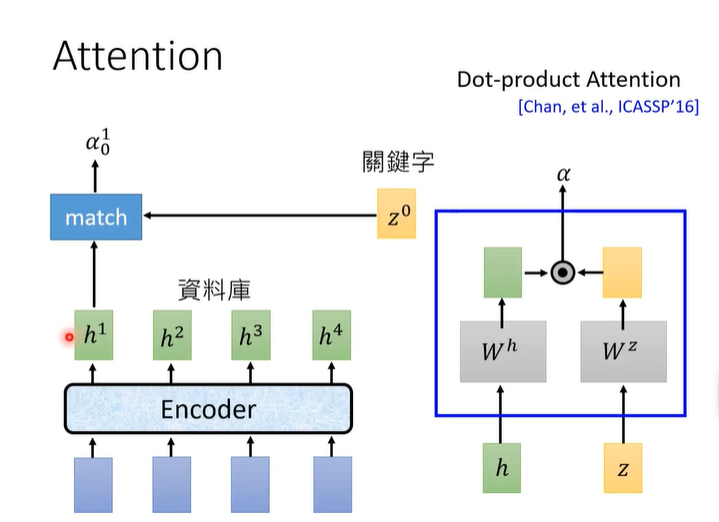
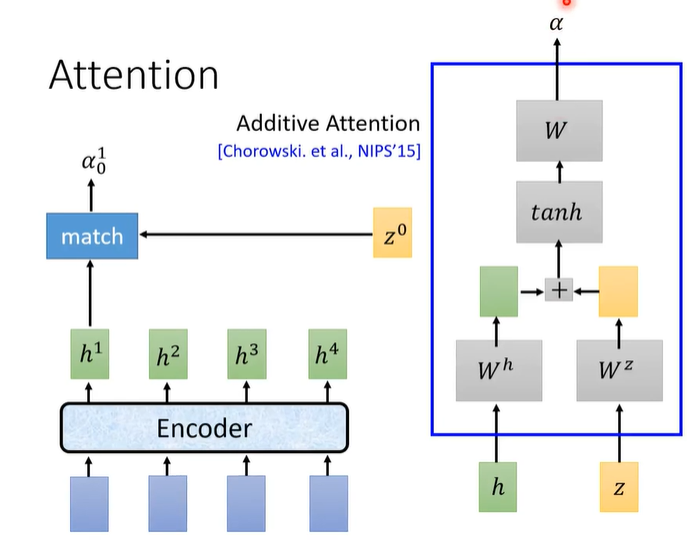
做完match之后,每个
h
h
h的注意力分数
α
α
α做softmax,然后对应比例的h相乘相加,得到向量
c
c
c,
c
0
c^{0}
c0作为decoder(Spell)的输入。
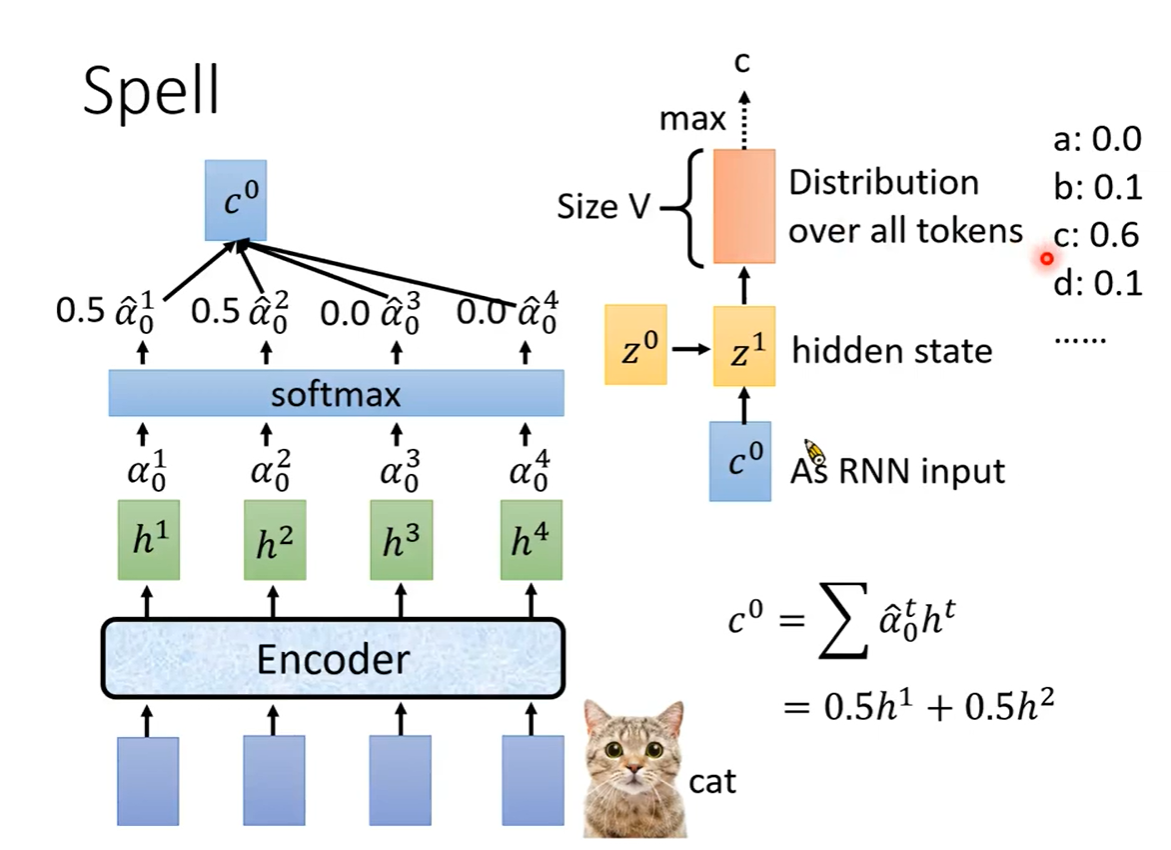
Spell
c
0
c^{0}
c0作为decoder的输入
随机初始化的
z
0
z^{0}
z0经过训练之后得到
z
1
z^{1}
z1,
z
1
z^{1}
z1作为RNN的隐状态输入
通过RNN,输出|V|维向量经过Softmax,输出最大概率的token。
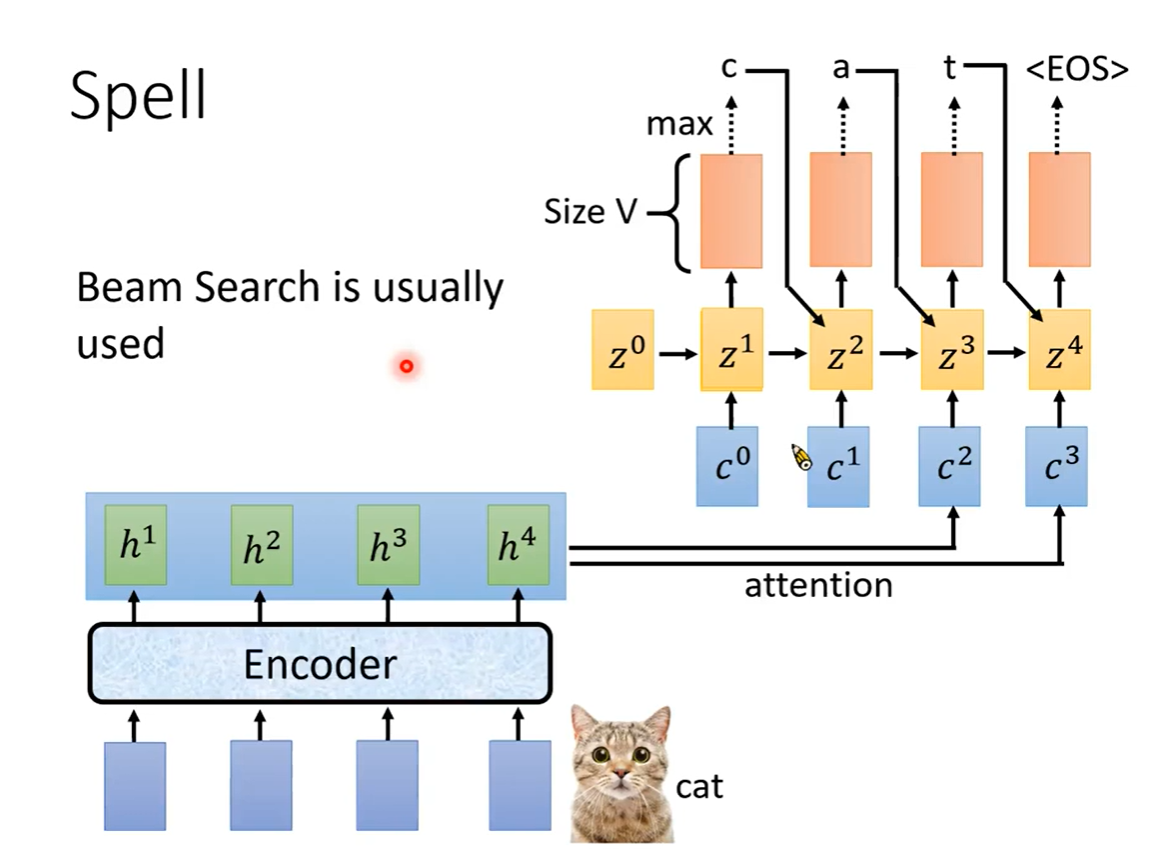
z
1
z^{1}
z1作为待训练的向量,与每个
h
h
h做attention,得到
c
1
c^{1}
c1作为输入
把得到的Token加入RNN网络,
z
1
z^{1}
z1训练后得到的
z
2
z^{2}
z2作为隐状态,训练得到下一个Token

 浙公网安备 33010602011771号
浙公网安备 33010602011771号