whisper
Robust Speech Recognition via Large-Scale Weak Supervision
介绍
大规模弱监督的训练。先前的方法都是通过大量的无监督学习训练(无监督的数据容易收集,所以通过大量无监督的学习可以训练出一个质量较好的encoder)。但是用的时候还需要找一些有监督的数据进行微调。作者觉得微调是一个比较复杂的过程,而且微调的时候,很容易对特定的数据集过拟合,使得模型的泛化能力不强。作者认为一个真正的语音识别系统,应该是拿去就可以直接用,而不用进行微调。
方法
数据处理
whisper模型直接预测原始抄录文本,没有进行任何标准化。系统直接输出自然抄录文本,而不需要一个额外的反向文本归一化的步骤(开头字母大写、加上标点符号、缩写形式等)。
做文本归一化的好处是,可以让训练更加简单一点。但是这样事后需要基于规则等做文本归一化
意思说,只要我的数据足够大,所有的文本归一化的情况都会出现,不需要额外做文本归一化。
构建了来自网络上的不同环境(不同录音状态、说话人、使用的语言)下的【音频转录文本数据对】。这样能使得模型更加健壮。
网络上爬取下来的音频是原始的,但是文本的质量不一定好。所以说做了一个文本过滤器,过滤掉那些不好的文本。很多文本不是人为标注的,而是用ASR系统生成的,研究表明这些数据会让模型变得更差。所有需要把用ASR系统的文本过滤掉。用ASR系统生成的文本有一些特点,比如说没有复杂的标点符号(冒号、问号等),没有格式化的一些字符,比如换行字符,或者全部是大写或者全部是小写。
同时使用了音频语言检测器(2021年的一个prototype模型)和CLD2工具,检测说的是哪种语言,如果这两个检测出来的语言不一样,那么就把【音频转录文本对】数据删除。
把音频文件分为30秒的【音频文本对】。训练所有音频片段,包括那些没有人说话的音频(作为sub-sampled),使用这些片段区分有没有在说话。
模型
由于我们的工作重点是研究大规模监督预训练的语音识别能力,因此我们使用现成的架构来避免将我们的发现与模型改进混淆。
模型使用2017年的encoder-decoder Transformer。
声音输入到Transformer:所有音频采样16K Hz,变为80通道的 logmagnitude Mel spectrogram(每个时间点抽取了80维度的特征),每个时间窗口是25ms,每次窗口滑动10ms。
切30s的音频,每次滑动10ms,长为30s的音频变成了3000个数据点,每个数据点的维度是80
(一个段落3000个词,每个词的词嵌入长度是80)
在输入之前,经过两个卷积层,它的宽度是3,使用GELU激活函数,第二个卷积层的步幅是2
步幅为2,把3000个数据点变为1500
然后把正弦位置编码加到卷积层的输出中,一块送到encoder进行训练。
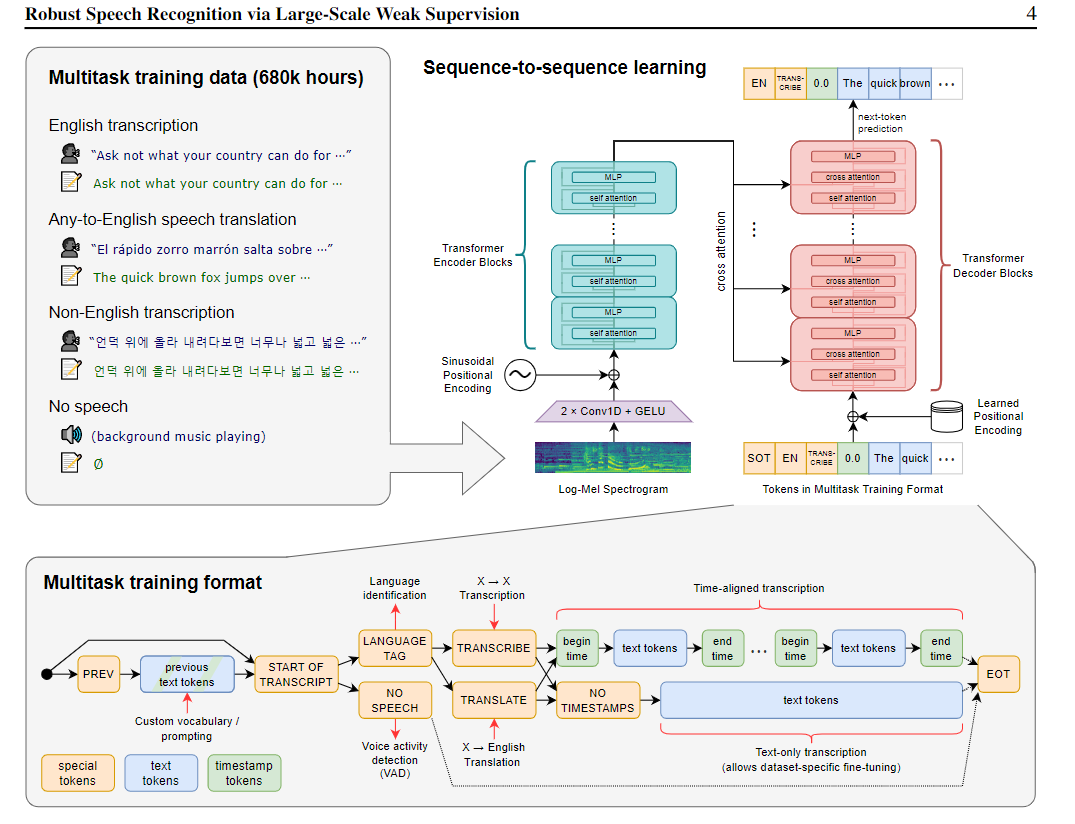
多任务格式
虽然语音识别模型的核心部分是预测说的一段话的单词,但这不是唯一的部分。对于一个完整特征的ASR系统来说,包括许多额外的部分,比如说检测是不是有人在说话,谁在说话,识别出来的文字归一化。这些部分通常是分别处理,然后把它们合起来,成为一个复杂完整的语音识别模型。为了减少复杂度,作者想要用一个模型执行所有的任务。可以在相同的输入音频信号上执行许多不同的任务:转录,翻译,语音活动检测等等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号