Bringing Order to Abstractive Summarization

介绍
当前在文本摘要抽取领域,利用深度模型的监督学习方式表现的最好,这类方法基本都是将摘要抽取看做seq2seq自回归的生成任务,训练时基于极大似然估计,让模型预测的序列的概率最大近似标注的参考序列。
这类方法存在一个明显的问题就是:exposure bias (曝光偏差),即模型在预测时候上一个token并不都跟参考序列中的一样,这样造成模型训练与预测时输入不一致性问题,从而使得模型在预测时出现性能衰退的问题。
训练阶段和训练完之后的推理阶段,在一个时间步解码时所依赖的上一个token的分布是不一样的。
在训练时这个token是百分百正确的,而在推理阶段这个token是有可能错误的。这样便会造成模型训练与推理时输入不一致性问题,从而使得模型在推理时出现性能衰退的问题
在MLE方式下训练时,模型只鼓励将高概率分配给参考摘要,而非参考摘要之间的相对好坏是不能够确定的。
但是在推理阶段,模型生成的摘要并不一定是参考摘要,而可能出现很多错误,当我们通过beam search生成多个作为候选摘要的非参考摘要时,模型是没有足够的能力去区分这些生成的多个候选摘要之间的相对好坏的,这是因为我们在训练阶段就没有刻意的去训练模型评价不同候选摘要的能力,根据生成概率来判断候选摘要的相对好坏是没有足够信服力的。
在训练时,模型只关注最优的参考摘要而不关注别的可能摘要的相对好坏。
在推理时,模型并不能生成最优的参考摘要,而是使用 beam search生成多个候选摘要,而又要求模型具备有判断候选摘要相对好坏的能力从而能够选出最优的候选摘要。
基于对这种训练和推理阶段的差异性的认识,论文提出一个新的训练范式,即在常见的seq2seq框架下,增加一个评分模型(Evaluation Model)来让整个模型能够更为准确的估计生成的候选摘要的质量。虽无法例举可能生成的所有候选摘要,然只需要能对产生的最可能的候选摘要(如来自beam search)进行准确的排序就可以缓解这种曝光偏差所带来的影响。
模型
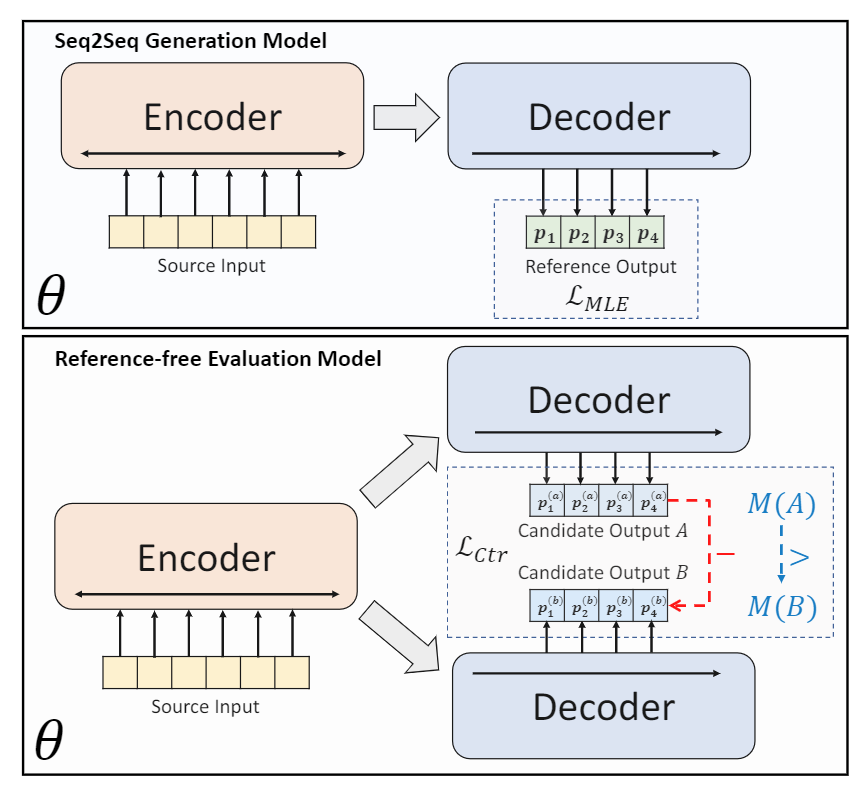
在seq2seq下abstractive summarization的学习范式。其学习目标是,在给定一篇文档
D
D
D下,训练一个模型
g
g
g ,生成一个合适的摘要序列
S
S
S ,即:
S ← g ( D ) S←g(D) S←g(D)
模型
g
g
g在预测阶段,采用自回归(auto regressive)产生候选摘要序列,因例举出所有可能的候选结果是很困难的,因此在实践中使用beam search减少搜索空间,其中搜索中最重要的就是根据前面预测的序列,来估计下一个token出现的概率。
由于预测下一个token时,使用的是之前预测的序列替代参考序列,这就导致exposure bias问题:即使模型训练拟合的很好,但是一旦在预测过程中之前的预测序列出现偏移,跟参考序列不一致,模型的预测性能就会衰退、下降。
合并模型
摘要抽取模型 g g g应该具备给更好的候选摘要序列分配更高的概率,然而在MLE训练方式下,是达不到的。其反例就是:当一个模型获得MLE loss为0的时候,那应该在推测时,跟参考序列不一样的候选序列的概率应该都为0,然而实际中是不存在的(因为exposure bias的存在)。
因此有一种想法:候选摘要出现的概率应该与它的一个度量指标M密切相关。虽然无法列举可能生成的所有候选摘要,然而只需要能对产生的最可能的候选摘要(如来自beam search)进行准确的排序就可以。
想法实现:按照label smoothing的思想给每个候选序列赋予一个概率值,且候选序列的概率值的大小与其在评价指标M下是一致的,而论文采用ROUGE作为M评价指标的一种形式,来评估候选摘要与参考摘要相似分数。这样有了对生成的候选摘要进行排序的方法与目标,那么训练模型也朝这个方向优化。论文引入对比损失,将排序后的候选摘要形成对比样本,参与目标优化。
具体来说,模型分为两个部分,即Seq2Seq生成模型(Seq2Seq Generation Model)以及无参考评分模型(Reference-fredd Evaluation Model),前者通过自回归的方式和Diverse Beam Search生成候选摘要,后者针对生成的候选摘要进行评分。生成模型和评分模型的结构是一致的,采用的是相同的预训练语言模型BART或PEGASUS,但生成模型的训练是使用的是标准的MLE损失,而评分模型的训练主要使用的是对比损失(contrastive loss),对比损失的计算基于生成模型生成的多个候选摘要。
生成模型的训练使用的是MLE损失针对预训练模型进行微调,该过程并没有什么特殊之处。而评分模型的训练是基于一个多任务学习框架,对应的模型称为BRIO-Mul,该框架采用的是一个一个多任务损失 L m u l L_{mul} Lmul ,分别由对比损失和普通的交叉熵损失和构成,由于对比损失是定义在序列级别的,所以这里token级别的交叉熵损失可以起到标准化的辅助作用,以确保评分模型可以在整个序列上分配相对平衡的概率。实际上,直接去除这里的交叉熵损失也不会产生太大的影响,评分模型的关键只在于这个对比损失。
多任务损失 L m u l L_{mul} Lmul公式如下:
L
m
u
l
=
L
x
e
n
t
+
γ
L
c
t
r
L_{mul} = L_{xent}+γL_{ctr}
Lmul=Lxent+γLctr
其中,
L
x
e
n
t
L_{xent}
Lxent表示普通的交叉熵损失,
L
c
t
r
L_{ctr}
Lctr表示对比损失,
γ
γ
γ表示对比损失的比重,通常需要设置为较大的数效果才比较好(如100)。
对比损失
L
c
t
r
L_{ctr}
Lctr被用来训练模型作为无参考评分模型的能力。典型的对比学习中的对比损失需要显式的构造正样本和样本,但这里没有采用这种方式,而是采用排序损失(ranking loss)来实现对比损失,标题中的Bring Order正源于此。也就是说,论文通过引入排序损失这种对比学习方式,来把评价指标M(通常为Rouge)引入到了评分函数,从而让整体模型在训练过程中不再仅仅依赖于token级别的损失,而能够直接拥有感知序列级别的差异的能力。

MLE假设了一个确定性(单点)分布,在这个分布中参考摘要接收所有概率质量。而对比损失假设了一个非确定性分布,它让生成模型生成的摘要也根据其实际好坏接收概率质量。也就是说,对比损失鼓励模型对候选摘要之间相对好坏的预测与实际评价指标(ROUGE)一致。在推理阶段生成的序列可能存在错误的情况下,模型要想保持良好的性能,模型需要具备准确评估不同生成候选摘要相对质量的能力,这样一来在推理时通过beam seach生成多个候选摘要后,模型便可以做出正确的选择。
参考文章
盘点文本摘要模型
BRIO:给文本摘要抽取带来排序

 浙公网安备 33010602011771号
浙公网安备 33010602011771号