SimCLS: A Simple Framework forContrastive Learning of Abstractive Summarization
摘要
本文提出了一个概念上简单但是强大的抽象摘要框架,SimCLS。它通过对比学习的方式,缓解了Seq2Seq框架固有的目标函数和评价指标不一致的问题,从而可以从模型生成的候选摘要中筛选出真实的评价指标(ROUGE)打分更高的摘要。将它用于当前的SOTA模型,比如BART,PEGASUS,会使它们的表现更好。
介绍
当前的Seq2Seq模型通常在极大似然估计(MLE)的框架下以teacher-forcing的方式得到训练。这会导致一个问题:目标函数计算是局部的,基于token级别的预测,然而评价指标(通常是ROUGE)是比较输出的摘要和参考摘要的整体相似度,这就存在着目标函数与评价指标不一致的问题。另外,Seq2Seq模型本身的训练和预测阶段也是不一致的,在预测阶段,模型需要以自回归的方式生成摘要,因此生成过程存在错误累加的问题,这个问题也被广泛地称为曝光偏差(exposure bias) 问题。
针对这些问题,前人的一些解决办法:
- 强化学习....
- Minimum risk training
- 将MLE框架扩展到句子级别
在本文中,作者提出使用一种两阶段的抽象摘要模型:Seq2Seq模型首先通过MLE loss被训练,生成候选摘要,然后用一个参数化的评估模型通过对比学习被训练,把生成的候选摘要进行排序。通过监督学习来训练这两个模型,在不同阶段分别优化生成模型和评估模型。
Contrastive Learning Framework for Abstractive Summarization
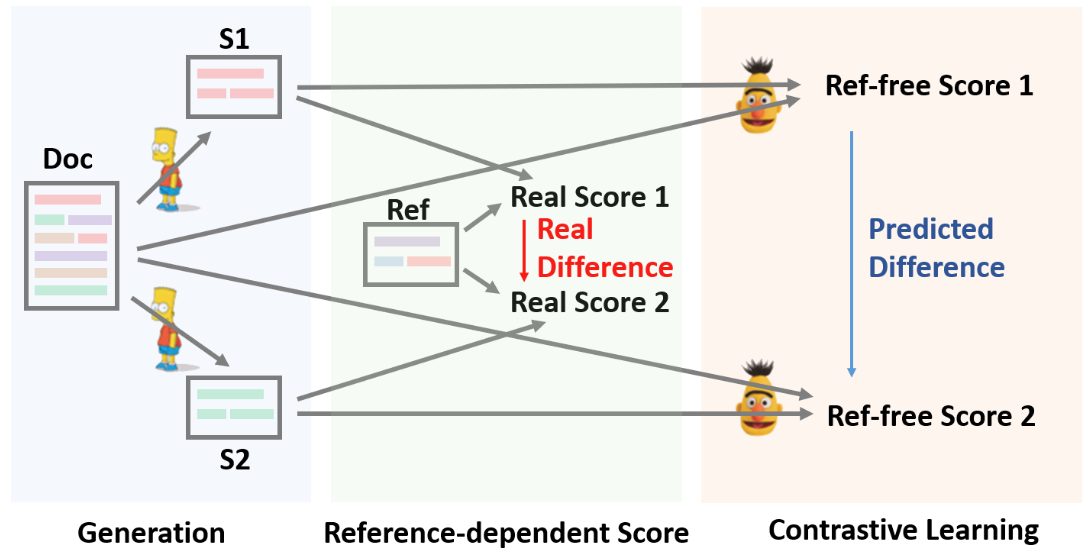
Doc, S, Ref分别表示文档,生成的摘要,参考摘要。第一阶段,Seq2Seq(BART)生成候选摘要。第二阶段,打分模型(RoBERTa)基于源文档预测候选摘要的表现。打分模型通过对比学习训练,训练样本由Seq2Seq模型提供。
给定原文档和对应的参考摘要
,生成式摘要模型
的目标是生成候选摘要,
使得评价指标
给出的分数
尽可能高。在这个过程中,我们将模型分解成两部分:生成模型
和评价模型
,前者负责生成候选摘要,后者负责打分并选择最优候选摘要。
阶段一:候选摘要生成
生成模型是一个Seq2Seq模型,基于给定源文档
,通过训练得到最大可能的参考摘要
。然后预训练模型
被用于生成多个候选摘要
,抽样策略可以使用Beam Search,
是被采样的候选摘要的数量。
阶段二:无参考评估
针对文档,越好的候选摘要
应该得到越高的分数。我们通过对比学习,并且定义一个评价函数
,旨在根据源文档
和候选摘要
的相似度,对候选摘要打分
。
。最终输出的摘要
是最高分数的候选摘要。
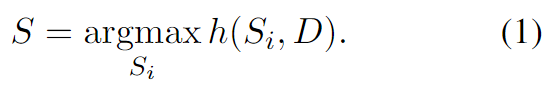
在这里,我们实例化为一个大型预训练自注意模型RoBERTa。它分别给
和
编码,编码器的第一个token的余弦相似度作为相似度分数
。
对比训练
这里的contrastiveness在由模型生成的摘要的不同质量中被反映。我们给
引进了一个ranking loss:
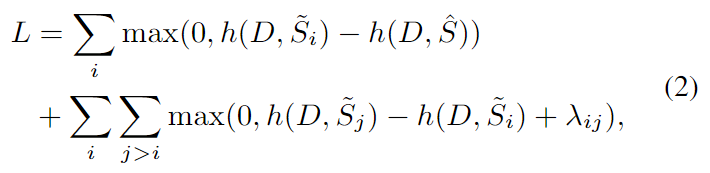
基于分数
按降序排列。在这里,
,
是超参数,
可以是任何自动评估指标或人为判断,在本文中使用ROUGE。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号